
基于参数联合优化VMD-SVM的工业机器人旋转部件故障诊断方法
2023-06-02 06:46:44王晓蓥李帅永
计算机测量与控制 2023年5期
王晓蓥,李帅永
(1.河海大学 物联网工程学院,江苏 常州 213022;2.重庆邮电大学 工业物联网与网络化控制教育部重点实验室,重庆 400065)
0 引言
在工业4.0的进程中,智能制造是各国工业重点发展的核心技术[1],而工业机器人则是智能制造业最具有代表性的设备[2],但其精度退化和设备故障问题[3]却仍然突出,尤其是工业机器人的旋转部件的性能在长期工作下会逐渐下降,导致故障,直接影响着整个机械设备的运行和生产安全[4]。因此,研究工业机器人旋转部件的故障诊断问题,对于保障工业生产安全、促进智能制造产业的发展具有重要意义。近年来,随着工业物联网和大数据的发展,针对工业机器人的数据驱动的轴承故障诊断方法逐渐成为研究热点[5]。这类方法包含了信号预处理、特征提取和故障诊断3个步骤。
在信号预处理方面,文献[6]在计算经验模态分解(EMD,empirical mode decomposition)分解得到的本征模态函数(IMF,intrinsic mode function)的两种熵值后,利用核主元分析(KPCA,kernel principal component analysis)对提取的状态特征进行信息融合完成了滚动轴承故障信号的特征提取。为改善EMD的模态混叠问题,许凡等[6]利用了一种EMD的改进版本,即总体平均经验模态分解(EEMD,ensemble empirical mode decomposition),进行滚动轴承的故障诊断。石志伟等[7]则利用EEMD的改进版本——自适应噪声完备集合经验模态分解(CEEMDAN,a complete ensemble empirical mode decomposition with adaptive noise),以分解降噪信号,再对IMF分量作包络谱分析,实现滚动轴承的故障诊断。EEMD、CEEMDAN等EMD的改进方法通过在原信号中加入辅助噪声的方法以改变信号的极值点特性,能够在一定程度上抑制EMD的模态混叠问题,但效果有限,且没有解决EMD对噪声敏感、缺乏数学理论支撑等问题。杜冬梅等[8]利用了Smith等[9]提出的一种解调幅度和频率调制信号的新迭代方法——局部均值分解(LMD,local mean decomposition),结合峭度-歪度筛选准则实现了滚动轴承故障信号的降噪。然而LMD和EMD均是通过对信号局部极值点进行提取以计算IMF的,而极值点的分布又易受环境噪声的影响[10],故该类方法无法从根本上改善模态混淆的问题。为此,Dragomiretskiy等[11]提出了一种完全非递归的、模式可同时提取的变分模态分解(VMD,variational mode decomposition)方法。VMD 具有完善的数学理论,能有效避免边界问题、抑制模态混叠,获得高信噪比的信号分量,目前已广泛应用于地质、医学、工业等多个领域。不过,VMD需要指定模态个数和惩罚因子两大参数,但现有方法难以自适应确定VMD的最优参数组合,从而导致其可能出现欠分解或过分解的问题。
在故障信号特征提取方面,可利用熵对重构信号进行筛选。Pincus等[12]于1991年提出了近似熵的概念,用以衡量时间序列在维数变化时产生新模式的概率的大小,产生新模式的概率越大,近似熵越大,时间序列越复杂。样本熵是在2000年被提出的,其计算方式与近似熵相近,但在短序列上表现更佳、相对一致性更强[13],具有更好的抗干扰能力[14]。然而,刘建昌等[15]在使用样本熵在衡量滚动轴承振动信号的复杂度时发现,样本熵的值并不总是和信号的复杂度相关。基于此,文献[16]提出了一种基于滚动轴承的故障机理的改进样本熵,提高了滚动轴承的故障诊断准确率。
在故障诊断方面,故障信号的正确分类诊断依赖于合适的诊断模型。近年来,深度学习以其强大的泛化能力被逐步应用到了众多领域,其最大的优势在于可以实现从原始数据到故障标签的端到端的学习,而无需人为提取特征。李世维等[17]采用离散小波变换(DWT,discrete wavelet transform)和长短期记忆(LSTM,long short-term memory)网络来诊断移动机器人电机轴承。文献[18]通过分析齿轮箱振动数据,提出一种基于组合特征矩阵和改进深度信念网络(DBN,deep belief nets)的齿轮故障诊断算法。然而,通过深度学习提取的特征不具有可解释性,这导致了故障溯源的不确定性;而且,深度神经网络结构复杂,训练时需要更多的数据,而在工业机器人旋转部件故障诊断领域,由于故障机器人只占少部分,且故障机器人通常会被及时关停,因而海量的故障样本难以获取。相比之下,支持向量机(SVM,support vector machine)在小样本和非线性问题上表现较佳,不会像深度神经网络出现因样本量过小而导致的过拟合问题。Long等[19]通过学习故障信息姿态数据集,提出了一种混合稀疏自编码器(SAE,stacked autoencoder)结合SVM方法,以实现多关节工业机器人的故障诊断。Muhammad等[20]利用DWT和EMD从轴承振动信号中提取出特征,然后采用线性、二次、立方等多种SVM对特征进行故障诊断,发现绝大多数类型的SVM都达到了很高的准确率。Konar[21]在研究感应电机的故障时,在提取特征向量后分别应用了多层感知机、SVM和径向基函数对故障进行分类,发现SVM的性能与另外两种神经网络相比更优。虽然SVM适用于工业设备振动信号的故障诊断,但其惩罚因子与核函数参数两个参数的组合的最优值难以根据不同样本自适应确定,从而制约了其分类表现。
因此,针对VMD和SVM的参数难以自适应优化而导致机器人旋转部件故障诊断准确率不高的问题,提出了一种利用改进灰狼算法对VMD和SVM的参数进行联合优化的故障诊断方法。首先,将遗传变异策略引入灰狼算法,提出了一种改进灰狼算法;然后,通过该算法对VMD和SVM进行联合参数优化;其次,利用参数优化的VMD和一种基于故障机理的改进样本熵构建特征向量,输入至参数优化的SVM完成对工业机器人旋转部件故障的最终诊断。最后,通过仿真与实验对本文提出的故障诊断模型进行验证。
1 变分模态分解原理及其参数影响
1.1 变分模态分解的原理
VMD是一种能够同时自适应确定相关频带和估计相应模态的新型信号处理技术。其求解各模态的大体思路为:在傅里叶频域内对各模态进行迭代更新的同时,利用与当前所估计的模态中心频率对应的窄带维纳滤波器,去预测其余各模态的信号估计残差,再将当前的中心频率重新估计为模态功率谱的重心。
VMD方法定义了分解后的第k个IMF分量的表达式为:
u(k)=Akcos(φk(t))
(1)
式中,相位函数φk(t)非递减且φk(t)′≥0;包络函数Ak(t)恒为正;并且不可忽视的一点是:Ak(t)和ω(t):=φk(t)′相较于φk(t)是缓变的。
考虑如下信号降噪问题:
f=f+η
(2)
式中,f是包含了噪声的原信号,f0是去噪后的原信号,η是噪声。这是一个不适定问题
(ill-posed problem)[1],应用正则化方法:
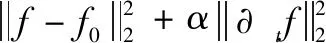
(3)
对式(3)使用傅里叶变换,将该问题转化至频域解决。再将其转化为泛函并求导后可以得到:
(4)
可见,f相当于对f0在频率段过滤掉高频部分后的结果。
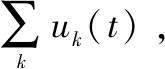
(5)
经过一系列变换,最终得到的约束变分模型为:
min{uk},{ωk}
(6)
式中,{ωk}表示各IMF分量的中心频率;f表示原始信号。
根据文献[12],可同时引入二次惩罚项α与拉格朗日乘子λ以重建上述约束模型,使得重建后的模型既能具有有限权值下二次惩罚的良好收敛性,也受益于拉格朗日乘子对约束的严格执行。重建后的非约束VMD模型如下:
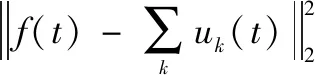
(7)
(8)
利用Parseval/Plancherel Fourier 在L2范数下的等距变换式,可将(8)转换至频域:
(9)
将式(9)中第 1 项中的变量ω替换为ω-ωk,并利用Hermitian对称将式子化成积分形式,得到:
(10)
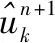
(11)
中心频率的更新问题如下:
(12)
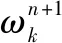
(13)
易求解得到中心频率的更新公式:
(14)
类似可得到λn+1的更新公式:
(15)
1.2 变分模态分解的参数对其分解效果的影响
对信号进行VMD分解时,需要确定的参数包括:模态个数K、惩罚因子α、终止条件ε,噪声容限τ等。其中,只有K和α对VMD的分解效果影响较大,其余参数一般设置为经验值。下面分析K和α对VMD分解效果的具体影响。
故障轴承部件的振动信号往往包含大量的调幅-调频信号,因而在仿真实验中选取如下的调幅-调频电压信号:
x(t)=(1+0.5cos(9πt))cos(200πt+2cos(10πt))
(16)
图1为在1 kHz采样频率下的x(t)的频谱图,其横纵坐标分别表示x(t)的中心频率和幅值。由图1中的6个局部极值点可知,x(t)可以被分解成6个主要的频率成分,分别为:85 Hz,90 Hz,95 Hz,100 Hz,105 Hz和110 Hz。

图1 x(t)的频谱图
1)K对分解效果的影响:
使用VMD方法分解式(16)的信号,保持α= 2 000,让K分别取[3,8]的每个整数值,得到如图2所示的实验结果。图中横坐标n表示当前VMD的迭代次数,纵坐标f表示分解出的各模态中心频率。
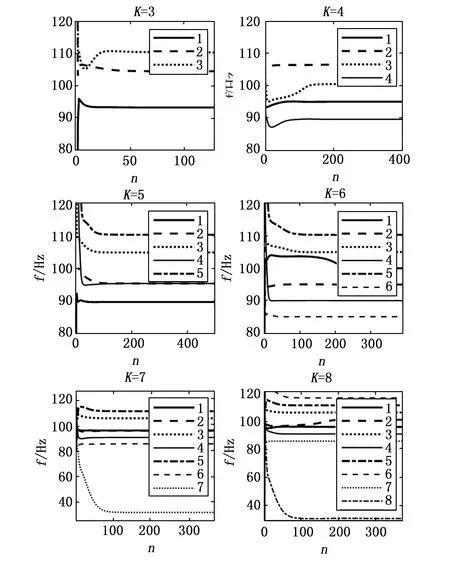
图2 K对IMF中心频率的影响
图2中每幅子图对应着一个K的取值,每幅子图中的若干条线表示信号被VMD分解出的IMF,横坐标表示VMD的迭代次数,纵、坐标表示IMF中心频率,因而通过该图可清晰地看出VMD的分解过程。
由图2可看出,随着K取值的增大,VMD分解得到的模态个数逐渐增加。当3≤K≤5时,VMD出现欠分解现象,没能将6个主要频率成分全部分解出来。在K取5时还出现了频率混叠的现象;当K取6时,VMD能够分解出所有的主要频率成分;当K取7时,VMD分解出了32 Hz的虚假分量,且在95 Hz处出现了混叠现象,没有分解出100 Hz的成分,即同时出现了过分解和欠分解;当K取8时,VMD能够分解出所有主要的频率成分,但多分解出了两个虚假分量,属于过分解。
可见K是VMD的重要参数,其在很大程度上决定了VMD是欠分解、过分解,还是正确分解。
2)α对分解效果的影响:
保持K= 6,让α分别取[500,4 000]中的多个整数值,得到如图3所示的实验结果。
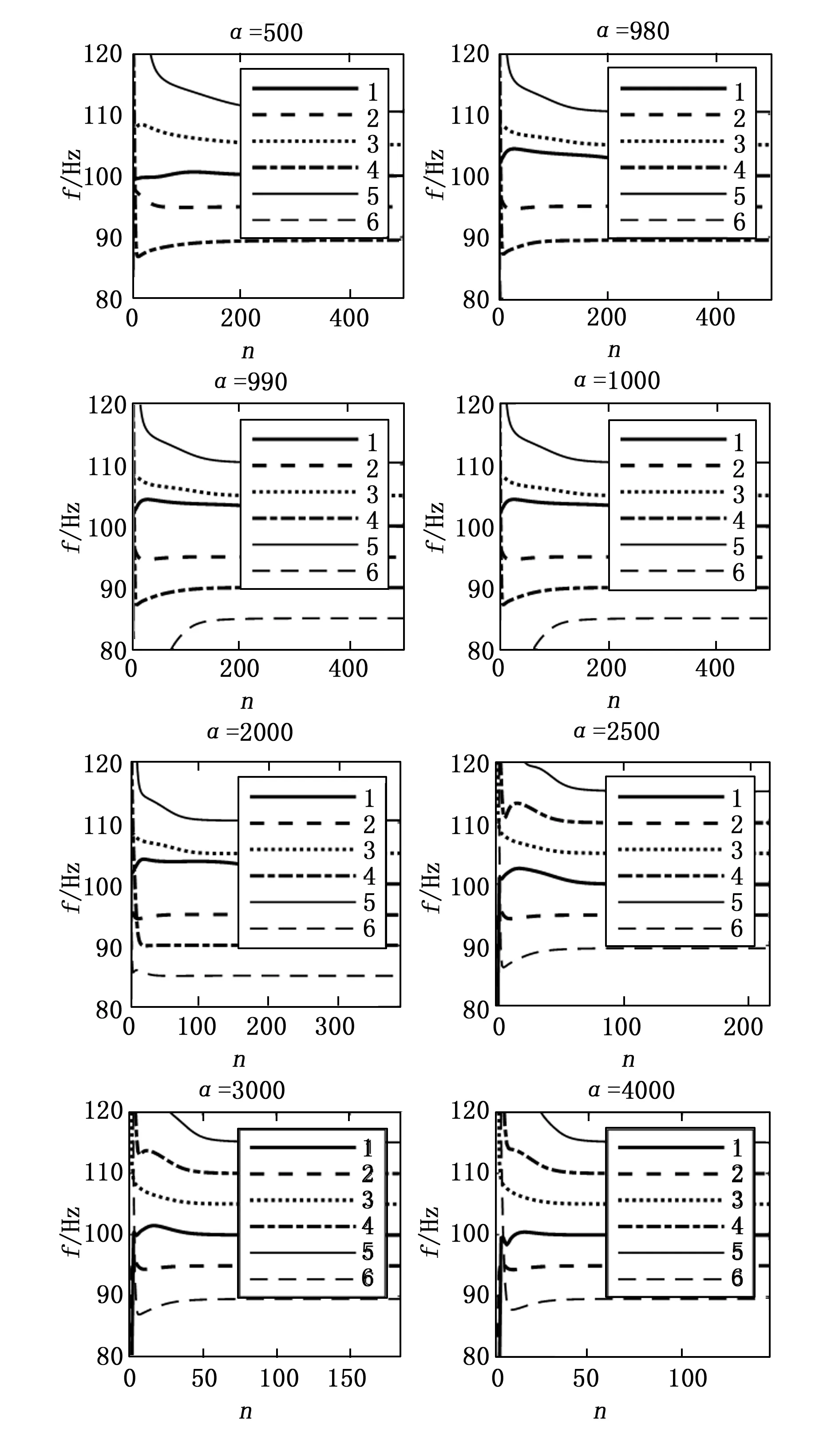
图3 α对IMF中心频率的影响
由图3可知,当α取500时,没有分解出85 Hz的频率成分,处于欠分解状态;当α取1 000时,能够分解出所有主要的频率成分,但所需的迭代次数较长;当α取2 000时,能够分解出所有主要的频率成分,所需迭代次数为较短,分解效果优秀;当α取2 500时,虽然此时迭代次数已减至100左右,但没能正确地分解出85 Hz的频率成分,而是多分解出了115 Hz的频率成分;当α取3 000和4 000时,所需迭代次数继续减小,但分解效果仍与2 500时相同。可见,当K固定时,随着α的变化,VMD的分解效果呈现出不规律性;并且,当中心频率-迭代次数曲线走势相近时,α取值越大,所需迭代次数就越小。
此外,当α取980时,在前100次迭代时分解出了70 Hz左右的频率,但其后又迅速回落到了在40 Hz以下;但当α取990时,85 Hz已经能成功分解出来了,只是所需迭代次数较长。在仅20单位的区间内,α的取值导致了相差甚远的两种结果,可见α的精确取值对于VMD分解效果的重要性。
综上,参数K和α的选取会对IMF的中心频率及VMD的迭代情况产生较大影响,且难以确定一个特定的参数组合[K,α],使其具有最优的VMD分解效果。因此,有必要使用算法对VMD进行参数优化,本文采用一种基于遗传变异的改进灰狼优化算法进行参数优化。
2 基于遗传变异的改进灰狼优化算法
灰狼优化算法(GWO,grey wolf optimizer)由Mirjalili等[1]提出,是一种模拟了灰狼的领导等级和捕猎行为的元启发式算法。GWO具有收敛性强、结构简单等优势,但也同时也容易早熟收敛,陷入局部最优。故本文对传统的灰狼算法进行改进,首先采用logistic混沌映射的方法初始化狼群,然后在位置更新过程中采用了非线性的策略,并且与遗传变异机制相结合,用以改善算法陷入局部最优时的停滞现象。
改进后的灰狼算法的流程图如图4所示。
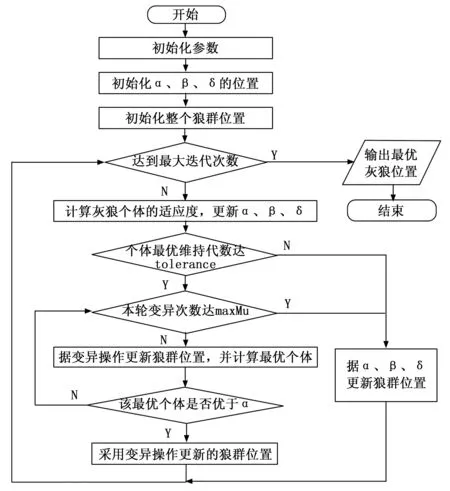
图4 基于遗传变异的改进灰狼算法流程图
实现步骤如下:记需要优化的参数个数为M,狼群为X,X由N只狼组成,即X=[X1,X2,...,XN],每只狼在搜索空间的位置可以用M维向量表示,即Xi=[Xi,1,Xi,1,...,Xi,M],迭代过程中所能容忍的最大个体最优保持代数为tolerance,变异概率为pm。
迭代开始前,采用Logistic混沌映射的方式初始化种群:
Xi,j=μXi-1,j(1-Xi-1,j)
(16)
其中:Xi,j为第i只狼位置的第j维向量,μ∈[0,4],为保证混沌特性,此处令μ= 4。
迭代过程中,当个体最优保持代数没有达到tolerance时,采用以下位置更新方式:定义狼群中适应度最高的三只狼分别为α、β、δ,其余狼根据α、β、δ进行位置更新:
Dα=|C1Xα-Xi|
(17)
Dβ=|C2Xβ-Xi|
(18)
Dδ=|C3Xδ-Xi|
(19)
X1=Xα-A1Dα
(20)
X2=Xβ-A2Dβ
(21)
X3=Xδ-A3Dδ
(22)
Xi(t+1)=(X1+X2+X3)/3
(23)
其中:Xi(t+1)为第i只狼更新后的位置;Xα、Xβ、Xδ分别为α、β、δ的位置;Xi为当前迭代中第i只狼的位置。A、C为随机系数,计算公式为:
A=2ar1-a
(24)
C=2r2
(25)
式中,r1、r2为[0,1]之间的随机数。a为控制因子,用以平衡算法探索和开发的能力,采用王伟等[1]提出的非线性策略计算:
a=2cos(kπ/2)+r
(26)
其中:k=t/T,t为当前迭代次数,T为最大迭代次数,r为[-1,1]之间的随机数,用于改变原有的平滑曲线。
而当个体最优保持代数达到tolerance时,说明灰狼位置可能已陷入局部最优,此时将遗传变异策略引入灰狼位置的更新过程。规定maxMu为每轮迭代中遗传变异的最大操作次数,若在maxMu次遗传变异操作内产生了新的个体最优,则进行下一次迭代;否则,对已变异的群体重复遗传变异操作;若该轮迭代的遗传变异操作已超过maxMu次,则采用灰狼算法进行位置更新。
本文将该算法用于VMD和SVM的参数优化中,适应度函数选取如下:在优化VMD参数时,选取VMD分解的各IMF的包络熵的最小值为适应度函数;在优化SVM参数时,选取SVM通过训练集得到的模型在测试集上的准确率为适应度函数。根据文献[25],包络熵的计算公式如下:
(27)
(28)
3 基于改进样本熵的特征提取与参数优化SVM故障分类方法
3.1 基于改进样本熵的特征提取
由于样本熵在短序列上表现更佳、相对一致性更强,故可在VMD将信号分解为若干IMF后,计算IMF的样本熵作为下一步分类所需的特征向量。
计算样本熵需要确定模板匹配长度m和阈值r,通常设置m为1或2,设置阈值r为信号的标准差的0.1到0.2倍。
然而,文献[16]指出,故障信号中存在的周期性冲击幅值会使r变大,使得计算得出的熵值变小,从而导致样本熵赋予正常信号更大的熵值,而赋予故障状态更小的熵值的问题。为减小故障状态下振动冲击幅值对计算结果的影响,该文基于故障机理提出了一种改进的样本熵,其实质是在传统的样本熵的基础上,改变了标准差SD的计算方法:先对振动信号进行一阶差分操作,再计算差分后信号的SD,并令阈值r= 0.2 SD,最后根据r计算振动信号的样本熵。振动信号的样本熵的具体计算过程如下:
1)由原始信号构建m维向量
Xm(i)=
{x(i),x(i+1),…,x(i+m-1)},1≤i≤N-m+1
(29)
2)定义向量Xm(i)与Xm(j)之间的距离为两者对应元素中最大差值的绝对值,即:
d[Xm(i),Xm(j)]=
maxk=0,…,m-1(|x(i+k)-x(j+k)|)
(30)

(31)
4)定义Bm(r)为:
(32)
5)将维数增加为m+1,重复式(31),得到所有满足d[Xm+1(i),Xm+1(j)]≤r的j的数目Ai。重复式(32),得到Aim(r):
(33)
6)从而可计算信号的改进样本熵SampEn (m,r):
(34)
利用上述改进样本熵的计算方法,在VMD分解某故障信号后,先对所有IMF进行一阶差分,后计算差分后的各IMF的样本熵,一个IMF对应一个样本熵,所有样本熵组成一组特征向量,即完成特征提取步骤。在实际特征提取时,只需取前3个IMF计算样本熵。
3.2 基于参数优化的SVM的故障分类方法
3.2.1 SVM的原理
Corinna Cortes和Vapnik[1]于1995年提出了软间隔的非线性SVM,该模型能根据较少的样本信息获得最佳的模型泛化能力[1],提出后被广泛应用到了各个领域。如今SVM已经发展出了多种类型,本文选用的是最经典的C-SVC模型。

ωTx+b=0
(35)
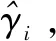
(36)
(37)
记γi的最小值为γ(,则目标问题可化为:
(38)
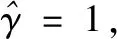
(39)
由于样本通常存在噪声,噪点会在正负样本之间相互渗透,因此可以适当放松约束,这便是软间隔SVM的思想。此时,优化问题变成了:
(40)
其中:ξi是松弛变量,表示训练样本的错分程度,C是惩罚因子,控制对错分样本的惩罚程度。
利用拉格朗日法可得判决函数:
(41)
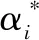
R(x,xi)=e-g|x-xi|2
(42)
其中:g为核函数参数。
由上述分析可知,SVM存在两个重要参数:惩罚因子C和核函数参数g。C控制对错分样本的惩罚程度,当C取值过大时,模型对错误的容忍度过高,会导致偏差过大;当C取值过小时,又可能导致模型过拟合。g则决定了高斯核函数对相似度的判断标准,当|x-xi|2保持不变,g越小,核函数值越大,意味着两者相似度的值越大,数据点更容易被简单的超平面划分;而在g很大时,两者只有在距离很接近的情况下才能拥有较大的相似度,这意味着在计算最佳决策面的过程中需要考虑到这些点各自的空间特征,故也更易出现过拟合的问题。因此,为提高SVM的分类性能,有必要对其进行参数优化。
3.2.2 利用改进灰狼算法优化SVM参数
利用上节提到的基于遗传变异的改进灰狼优化算法优化SVM的参数,步骤如下:
1)将带有故障标签的训练集划分为A、B两个组别,A组作为参数优化过程中的训练集,B组作为参数优化过程中的测试集。A、B两组容量占整个训练集的比例据文献[16]分别设置为0.6和0.4。
2)输入A组数据进行训练,得到SVM预测模型,再输入B组数据至该预测模型,将该预测模型在B组数据上的分类准确率作为SVM参数优化时选用的适应度函数。
3)根据不同SVM参数组合[C,g]的适应度函数值,利用改进灰狼算法不断更新α、β、δ,再由α、β、δ引领整个狼群的进化。当进化过程陷入局部最优时,算法采用遗传变异策略帮助狼群跳出局部最优,从而找到最优的SVM参数组合。
4 基于参数联合优化VMD-SVM的工业机器人旋转部件故障诊断步骤
针对因工业机器人旋转部件故障诊断模型最优参数难以自适应确定导致故障识别率低的问题,本文方法首先利用基于遗传变异的改进灰狼算法搜寻得 VMD 的最优参数组合[K0,α0];然后将VMD的参数设置为[K0,α0],并将不同状态的振动信号输入至该VMD中进行分解,得到相应的 IMF 分量;接着计算各 IMF 分量的改进样本熵输入至SVM ;最后再次利用基于遗传变异的改进灰狼算法搜索SVM的最佳参数组合[C0,g0],并利用参数优化SVM进行故障分类识别。流程如图5所示。
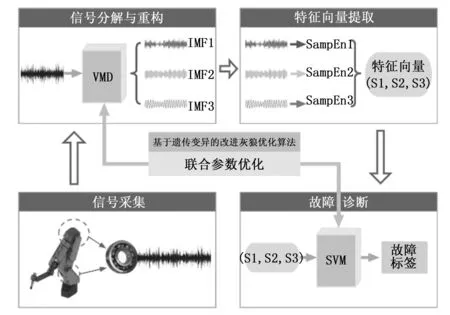
图5 基于参数联合优化VMD-SVM的工业机器人旋转部件故障诊断架构图
具体步骤如下:
1)采集工业机器人旋转部件在正常状态和不同故障状态下的振动信号,作为获取最终故障分类模型的训练样本。
2)初始化基于遗传变异的改进灰狼算法的参数,然后利用该算法搜索各个状态下振动信号的最佳VMD参数组合[K0,α0],适应度函数为信号的包络熵。
3)分别将VMD参数设置为步骤2)中得到的针对各状态的最佳参数组合,分解对应的各状态信号。
4)每个信号经过VMD分解后,得到若干IMF,取前3个IMF,分别计算改进样本熵(SampEn),组成一个三维特征向量(S1,S2,S3)。同种状态下的若干信号,对应一类特征向量。
5)利用基于遗传变异的改进灰狼算法搜索SVM的最佳参数组合[C0,g0]。将SVM参数设置为[C0,g0],得到参数优化SVM,将步骤4)中所有的(S1,S2,S3)输入至参数优化SVM中训练,得到最终的旋转部件故障状态分类模型。
6)获取工业机器人旋转部件的测试信号,使用步骤2)至 4)的方法得到该信号的一个特征向量,将该特征向量输入至SVM预测模型中,得到测试信号的故障分类结果。
5 实验与分析
本节利用美国凯斯西储大学轴承数据中心的数据集进行故障诊断分析,该数据集检测的轴承的损伤是用电火花加工的单点损伤,驱动端轴承型号为SKF6205。
5.1 VMD的参数优化前后的对比
为验证VMD参数优化的作用,利用基于遗传变异的改进灰狼算法,分别搜索数据集中正常状态、内圈故障、滚动体故障和外圈故障的驱动端轴承振动信号对应的VMD最佳参数组合。4种状态的驱动端轴承的负载、损伤直径、转速、采样频率均保持一致,分别取 0 kW、 0.177 8 mm、1 797 r/min、12 kHz。以轴承旋转两圈为一组样本,每种状态的信号各取三组,利用算法搜索到的VMD最佳参数组合如表1所示。

表1 4种状态信号对应的VMD最佳参数组合[K,α]
由表1可知,不同状态的轴承振动信号对应着不同的VMD最佳参数组合,并且多次实验得到的每种状态信号的最佳参数组合相近,说明了基于遗传变异的改进灰狼算法的优化作用是稳定的,不具有随机性。下面通过设置两种方案来对比探究VMD参数优化的作用。
方案1:以轴承旋转两圈为一组样本,4种状态(滚动体故障、内圈故障、外圈故障、正常状态)的振动信号各选取 140 组样本,其中训练样本 100 组、测试样本 40 组。使用默认参数的VMD(K=6,α=2 000)对4种状态信号进行分解,对每个被分解的信号计算前3个IMF的改进样本熵(即本文所使用的基于故障机理的样本熵),作为一个三维特征向量。将测试样本的特征向量输入使用改进灰狼算法优化的SVM(即参数优化SVM)进行分类。
方案2:将方案1中的默认参数VMD改为参数优化VMD,即采用表1的最佳参数组合去分解4种状态的信号,其余步骤不变。此即本文提出的方案。
两种方案的分类正确率如表2所示。

表2 方案1和方案2的分类正确率
由表2可知,使用改进灰狼算法优化VMD的参数后,故障诊断的准确率提升了6.25%。使用传统的参数组合固定的VMD虽然更加简便,但会影响分解效果,从而降低诊断的准确率。而参数优化VMD会针对不同的信号根据其IMF的包络熵选择最优的VMD参数组合,使得分解出的IMF更接近信号原本所包含的频率成分,因而在准确性上表现得更好。
方案1、方案2的具体分类结果分别如图6、图7所示。其中纵坐标为类别标签,类别1至4分别指代正常、内圈故障、滚动体故障、外圈故障;横坐标为样本序号,一个序号对应一组样本。
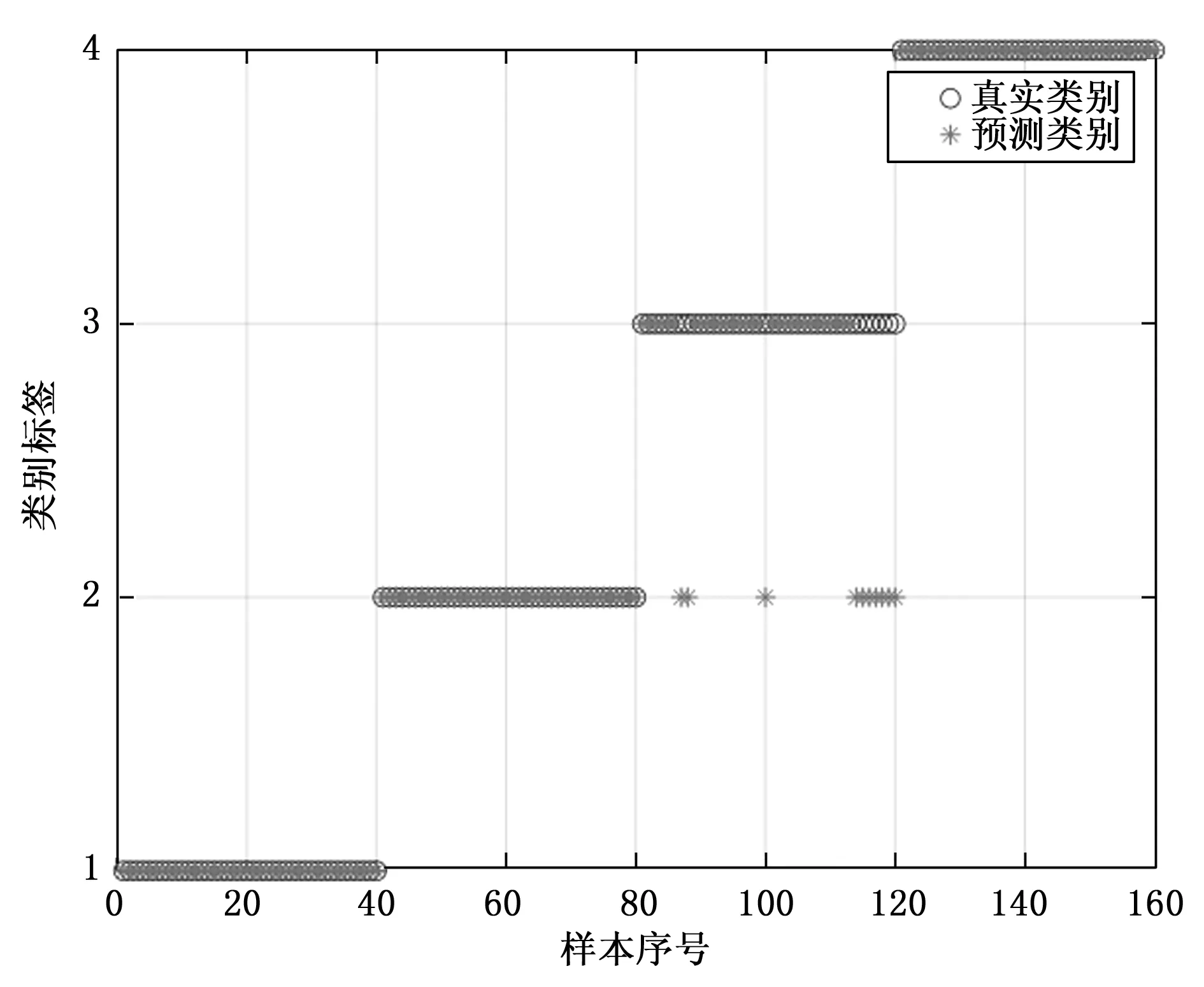
图6 方案1(使用默认参数VMD)分类结果
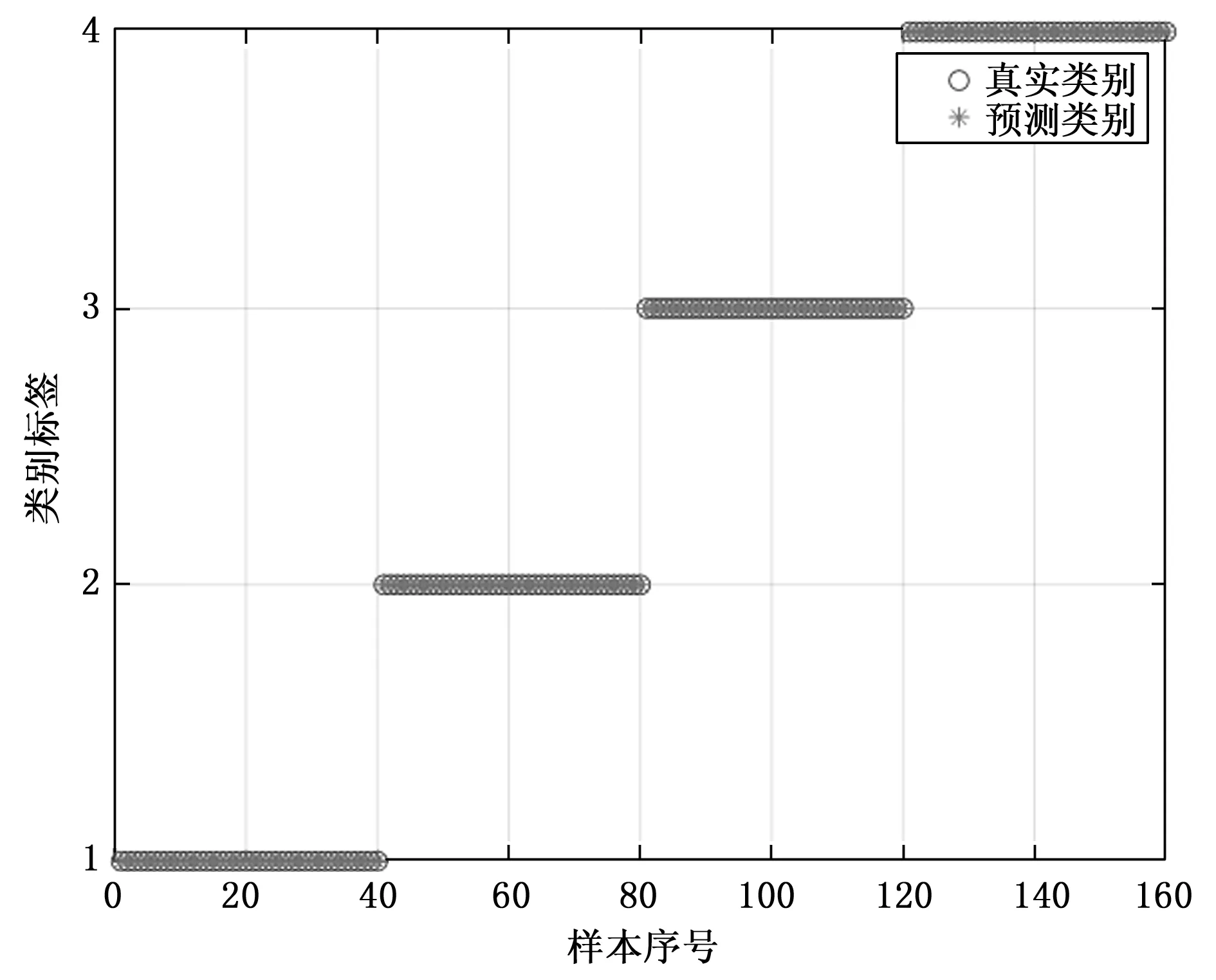
图7 方案2(使用参数优化VMD)分类结果
5.2 传统样本熵与改进样本熵的对比
采用与5.1节相同的4种状态信号样本,对每种状态的信号分别使用参数优化VMD分解,再计算前3个IMF的传统样本熵和改进样本熵(即本文所使用的基于故障机理的样本熵),所得结果如表3和表4所示。

表3 传统样本熵
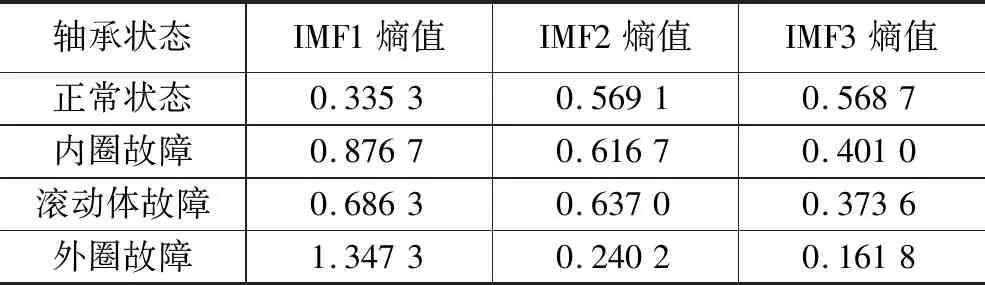
表4 改进样本熵
由表3和表4可见,相较于传统样本熵,改进样本熵的正常状态熵值变化不大,但3种故障状态的熵值大部分增大。这是因为改进样本熵剔除了故障信号的部分冲击幅值,使得其样本熵的阈值减小,模式匹配值变小,样本熵值变大。
可见,改进样本熵通过先对信号进行一阶差分的操作,剔除了部分冲击幅值,考虑了在周期性冲击幅值区间内的局域波动情况,更加符合故障机理下的信号复杂度。
下面通过对比实验来探究改进样本熵算法的作用,设置如下两种方案:方案3:采用与5.1节相同的方法选定140 组样本,使用参数优化VMD+传统样本熵+默认参数SVM(C=50、g=2)进行故障诊断;方案4:将方案3中的传统样本熵改为改进样本熵,其余部分不变。
两种方案的准确率如表5所示。

表5 方案3和方案4的分类正确率
由表5可见,使用传统样本熵的方案3对于滚动体故障的诊断正确率较低,而选用改进样本熵的方案4则达到了100%的正确率,说明选用改进样本熵能够提升故障分类的准确率。
图8、图9分别为方案3、4的具体分类结果。

图8 方案3(使用传统样本熵)分类结果
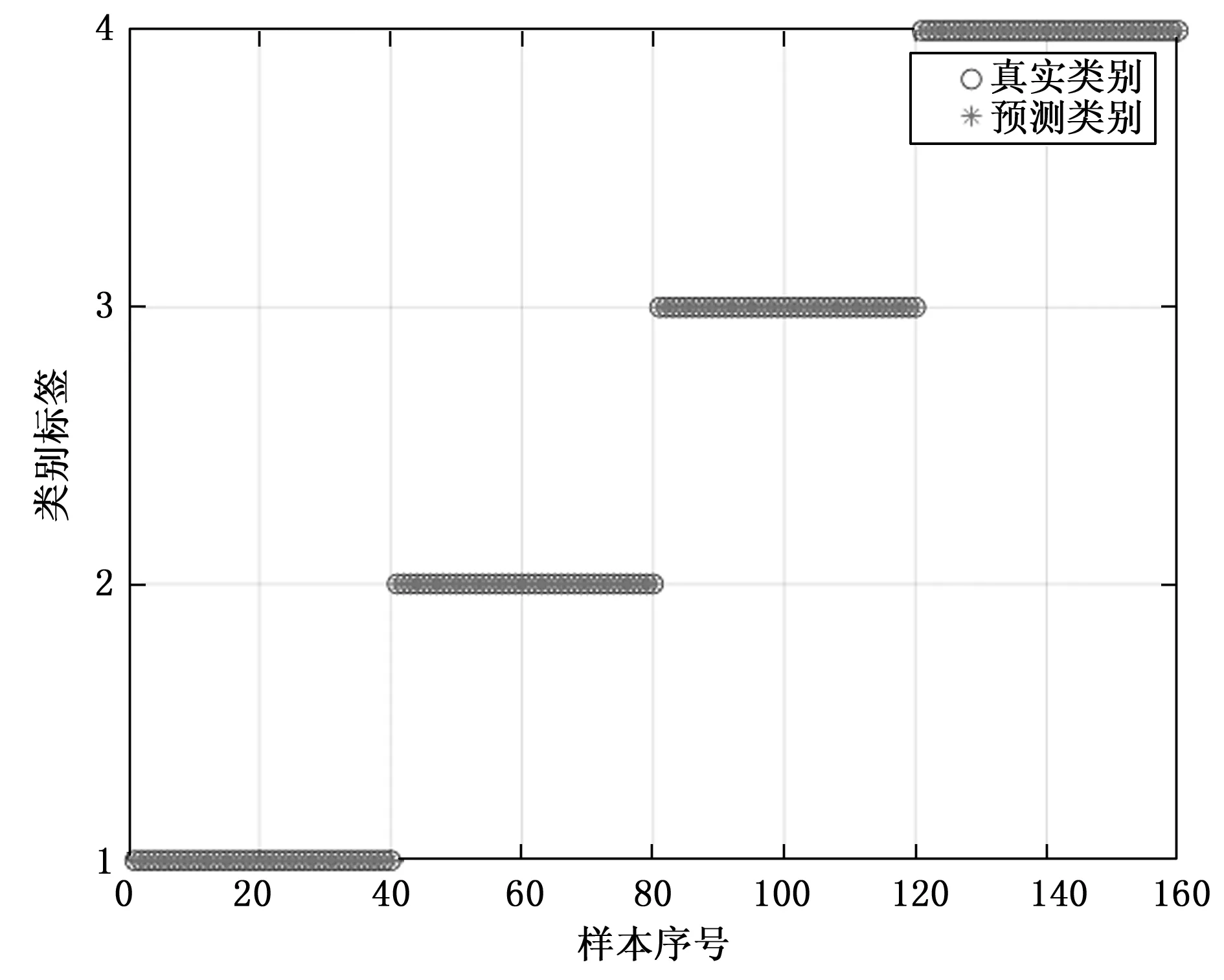
图9 方案4(使用改进样本熵)分类结果
5.3 SVM参数优化前后的对比
设置如下两种方案:方案5:采用与5.1节相同的方法选定140 组样本,使用默认参数VMD(K=6,α=2 000)+传统样本熵+默认参数SVM(C=50、g=2)进行故障诊断。方案6:将方案5的默认参数SVM改为参数优化SVM,其余部分不变。
两种方案的准确率如表6所示;实验中采用基于遗传变异的改进灰狼算法进行SVM的参数优化,多次实验得到的参数组合如表7所示。

表6 方案5和方案6的分类正确率

表7 方案6中多次搜索到的SVM最佳参数组合[C,g]
表6显示使用默认参数和参数优化的SVM的方案5和方案6的准确率分别为90.625%和95%。由图10和图11可知两种方案都存在误将滚动体故障判断为内圈故障的情况,这是由于两种方案都没有对VMD和样本熵进行优化,故障诊断存在偏差。然而在未对VMD和样本熵进行优化的条件下,参数优化的SVM还能将平均准确率提升近5%,减少了将滚动体故障判断为内圈故障的错误,这说明对SVM进行参数优化能够改善SVM的分类性能。
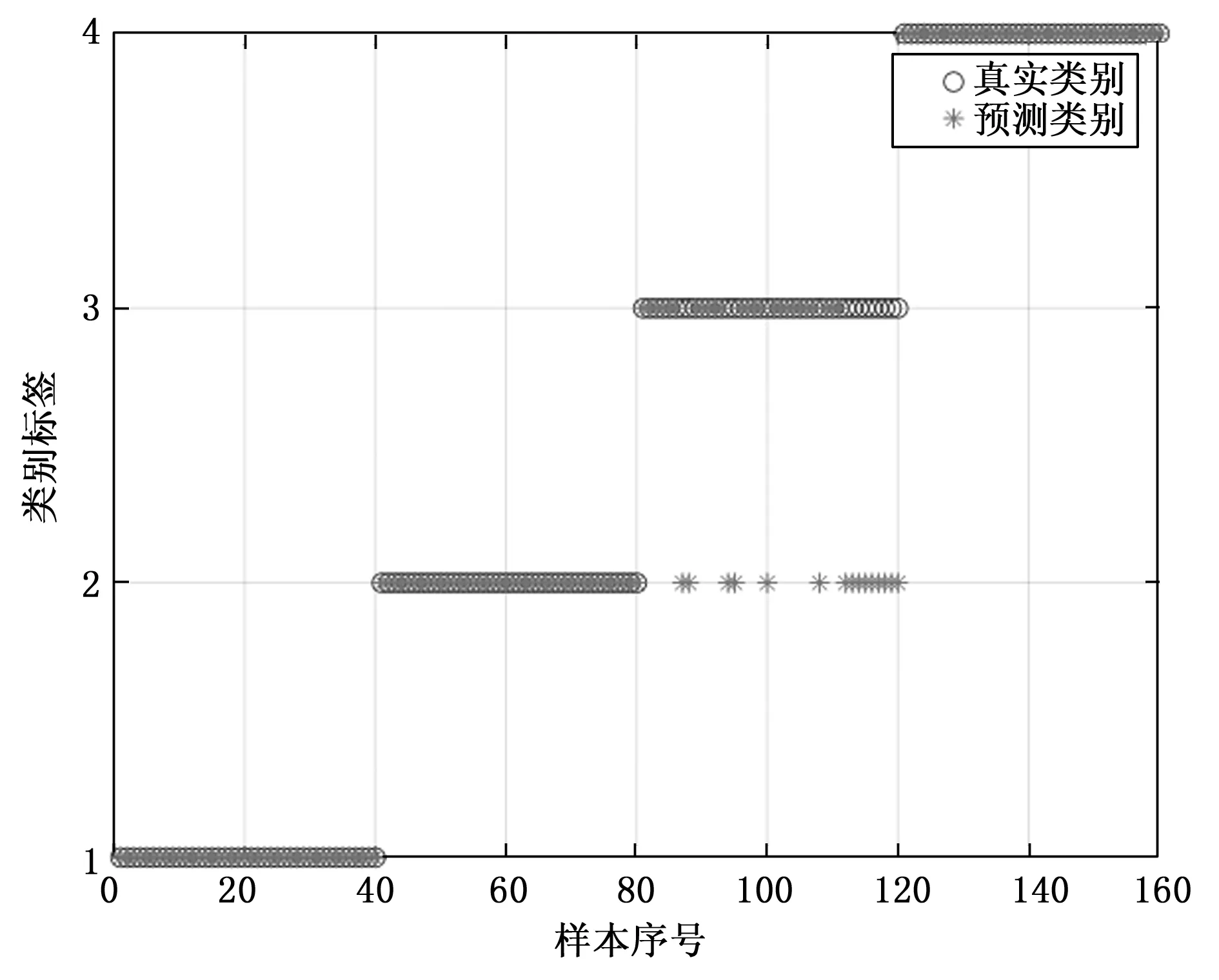
图10 方案5(使用默认参数SVM)分类结果
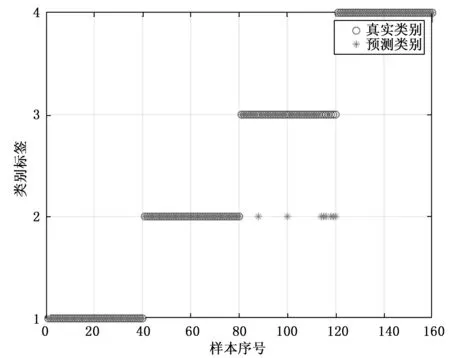
图11 方案6(使用参数优化SVM)分类结果
综合表6和表7可知,方案6中使用算法针对使用传统样本熵得到的特征向量多次搜索到的SVM最佳参数组合相差不大,进一步证明了该算法的优化作用是稳定的。
图10、11分别为方案5、6的具体分类结果。
5.4 无噪条件下本文方案与其他传统方案的对比
针对5.1节提及的4种状态信号,以轴承旋转两圈为一组样本,每种状态的信号各选取 120 组样本,其中训练样本和测试样本的比例为2:1,在不对信号加入额外噪声的情况下,设置如下5种方案对比它们的故障分类准确率:1)EMD+传统样本熵+SVM;2)LMD+传统样本熵+SVM 3)二元树复小波变换 (DTCWT,dual-tree complex wavelets)+传统样本熵+SVM;4)VMD(K=6,α=2 000)+传统样本熵+SVM 5)本文方法(参数优化VMD+改进样本熵+参数优化SVM),实验结果如表8所示。
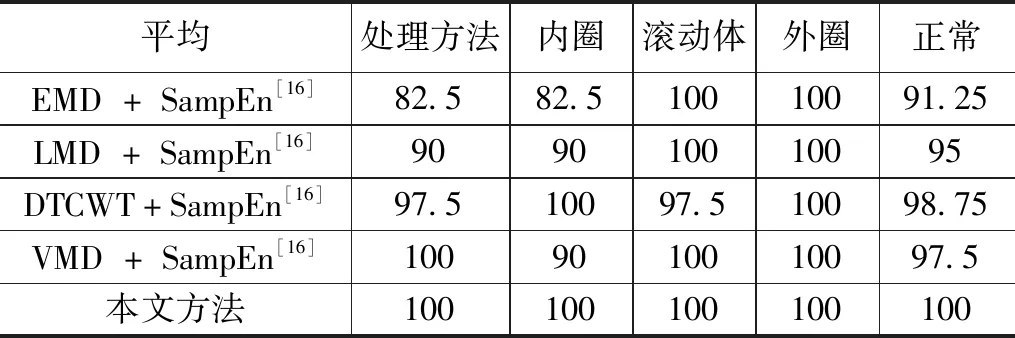
表8 不同方法在无噪信号上的准确率 %
其中方案1)~4)的数据均来自于文献[16],其SVM的核函数为poly核函数与径向基函数的线性组合,权重比为7:3,核函数参数d=1.43,σ=0.35,惩罚参数C=23.67。
可以看到,相比于EMD、LMD、DTCWT、默认参数VMD分别配合传统样本熵与默认参数SVM的4种传统方法,本文方法的准确率分别提高了8.75%、5%、1.25%、2.5%,由此证明了本文提出的优化方法在故障诊断准确率上的优越性。
5.5 含噪条件下本文方案与其他传统方案的对比
为进一步验证本文方法的有效性,现选用NOISE-x92噪声库中的工业噪声,给4种状态信号加入信噪比(SNR,signal to noise ratio)分别为50 dB、20 dB、10 dB的工业噪声,再应用本文方法进行故障诊断。使用本文提出的改进灰狼算法,针对无噪信号和不同信噪比的加噪信号搜索到的最佳VMD参数组合[K,α]和对应的分类准确率如表9所示。

表9 不同级别噪声下的最佳VMD参数组合及相应的故障分类准确率
由上表可见,不论输入信号是无噪还是有噪,信噪比是高还是低,利用本文提出的算法搜索到的不同故障状态下的VMD最佳参数组合都比较接近,且本文方法最终都能达到100%的诊断准确率。这说明该算法在有噪声的环境下也能得到较准确的最佳VMD参数组合,证明该算法具有较强的鲁棒性。由表8可知,即使在无噪的条件下,4种传统方法都无法达到100%的准确率,因此可见本文方法具有良好的抗噪性能。
5.6 不同负载的同类故障诊断
为了进一步检验本文方法的有效性,在内圈故障的驱动端轴承振动信号中选取负载分别为 0 kW,0.75 kW,1.5 kW 和 2.25 kW 的4种信号,其他参数与6.1节提及的一致。每种信号各选取120组样本,其中训练样本和测试样本的比例为2:1。使用默认参数VMD(K=6,α=2 000)+传统样本熵方法+默认参数SVM(C=50,g=2)和本文方法对比,对不同负载的故障信号分类准确率如表10所示。

表10 两种方法的负载分类准确率
由上表可见,与负载为0时相比,在负载不为0的情况下,默认参数VMD-SVM+传统样本熵的方案对滚动轴承负载情况的识别率大幅降低,分别只有70%、67.5%和82.5%。而面对同样的测试样本,使用本文方法对滚动轴承负载状况的平均分类准确率达到了98%以上,相比于该传统方案的平均正确率提升了近20%。
由此可见,在对不同工况下的滚动轴承的分类问题中,本文方法也能达到较高的准确率,说明了本文对VMD-SVM和样本熵进行的优化措施是有效的。
6 结束语
针对因工业机器人旋转部件故障诊断模型最优参数难以自适应确定导致故障识别率低的问题,本文提出了一种参数联合优化的VMD-SVM的工业机器人旋转部件故障诊断方法。经过仿真实验,得到如下结论:
1)VMD的模态个数参数K和惩罚因子α会影响其对故障信号的分解效果。 若K取值过大或过小,会直接导致VMD出现过分解或欠分解的现象;α会影响VMD分解的迭代次数,K不变时α越大,迭代次数通常越小,并且若α取值不当,也会导致VMD过分解或欠分解。 SVM的惩罚因子C和核函数参数g的取值对故障的分类效果有直接影响,若C过大或g过小,会导致分类时的较大偏差,反之则会导致SVM过拟合。VMD和SVM各自的参数组合均会影响其性能,而最优参数的选择又是不规律的,现有方法难以自适应确定,最终导致了VMD-SVM的故障诊断准确率不高的问题。
2)本文提出了基于遗传变异的改进的灰狼优化算法,该算法在轴承振动信号无噪和含有不同级别噪声的情况下,能稳定地搜索到VMD的最佳参数组合[K,α];在优化SVM的参数组合[C,g]后,也使SVM的分类性能得到了提高。 针对VMD-SVM参数进行联合优化的方法,能够得到VMD和SVM 的最佳参数组合,因而在特征提取和故障分类两个步骤上都实现了优化,是一种较为完善的故障诊断方法。
3)在信号无噪的情况下,本文提出的参数联合优化的VMD-SVM+改进样本熵的故障诊断方法,与传统的EMD、LMD、DTCWT、默认参数VMD+传统样本熵+默认参数SVM四种方法相比,准确率分别提高了8.75%、5%、1.25%和2.5%;在信噪比分别为50 dB、20 dB、10 dB的情况下,本文方法依旧能保持100%的准确率;对于不同负载的同类故障信号,本文方法的平均分类准确率为98.125%,相比于默认参数VMD-SVM+传统样本熵的方法提升了18.125%。
虽然本文提出参数联合优化的VMD-SVM与改进样本熵的故障诊断模型具有较高的准确率,但是仍存在实时性不强、改进样本熵优化效果不明显等问题,这些问题将是未来的重要研究方向。
猜你喜欢
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
小太阳画报(2019年1期)2019-06-11 10:29:48
数学大王·低年级(2018年5期)2018-11-01 10:34:06
中国交通信息化(2018年5期)2018-08-21 03:37:40
快乐语文(2016年15期)2016-11-07 09:46:31
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28 07:43:58
读写算(中)(2015年6期)2015-02-27 08:47:14
振动、测试与诊断(2014年5期)2014-03-01 01:14:21
