
成都区域气象站自动分型方法设计及应用
2023-06-01 08:40:40王冬萌
成都信息工程大学学报 2023年3期
夏 昕, 王冬萌, 贺 南
(1.成都市气象局,四川 成都 611130;2.成都信息工程大学通信工程学院,四川 成都 610225;3.成都温江国家观象台,四川 成都 610225)
0 引言
为提供精细化气象服务,提升气象减灾防灾能力,中国陆续建设了大量区域气象自动站,其中成都地区自动气象站的总量已超过500 个。为满足社会对气象服务工作提出的更高要求,气象监测网格将进一步加密,台站数量还将继续增长,台站管理和数据应用面临全新压力:尽管区域站连续监测的雨量、风速等实时数据已在防灾减灾等气象服务工作中发挥了重要作用,但由于气温测量数据受局部环境条件的影响很大[1-2],同时数量巨大的区域自动站并不适宜沿用国家级站点(大监站)的建设和维护标准,区域自动站监测数据的可比性、代表性和数据序列的连续性受到不同程度局限,使区域自动站的数据在精细化预报与服务等领域的应用价值未能充分体现;尤其设置在市区内的站点受场地限制,因道路、公园水体等外部环境受到的影响显著[3-10],自动站测量值的精细化应用更需要准确匹配站点的背景环境条件,但这对环境变动频繁的区域站而言有一定难度。
在站点数量迅速增长和城市建设发展的背景下,如何从大量建成站点中快速筛选出观测环境已发生较大变化、观测数据质量下降的站点,为站点迁址、优化布局、数据精细化管理等提供参考依据方面进行了研究。通过气象大数据的聚类分析有益于实现站点自动化分型[11-12],但气象数据的聚类还需注重物理机理[13]以便于应用解析。贺南等[14]在对成都地区气温极小值的站间空间差值序列的频数分析中注意到,较高的频率与两个站观测条件的一致性有关联,并同阴晴等天气条件也有关联[15-19],频率与站间距离等客观因素也联系密切,因此可考虑使用分析温差的频率特点这种技术线路,实现区域站点依照观测环境条件聚类分型,以解决区域自动站数据应用中的实际环境背景的主动识别问题[20]。
1 区域气象站自动分型方法
1.1 资料
数据资料来源于成都地区14 个国家气象站近10年逐日历史资料和252 个建站时间较长区域自动站近5年逐小时资料,区域站小时数据剔除异常值后计算得到逐日最低气温。气象站自动分型方法中采用聚类方法对分型量化因子做进一步处理,从而实现聚类分型。
1.2 数据处理
分型运算使用的数据为通过两个站点日最低气温的差值生成的温差位/频率序列{Xi,fi},整理时将站A 的日气温极小值与站B 的日气温极小值一一对应求差,该差值记为ΔTmin,此时ΔTmin∈{…、-0.2 ℃、-0.1 ℃、0 ℃、 +0.1 ℃、 +0.2 ℃、…}。通常ΔTmin<5 ℃且ΔTmin>-5 ℃,在这个值域内,用0.1 ℃为步长,按照温差值的高低,顺序排列温差,温差的档位值记为“Xi”,令Xi=0.1i℃,i=…,-4,-3,-2,-1,0,+1,+2,+3,+4,…。单个由两个站点生成的ΔTmin会对位某个档位的Xi值一次,即ΔTmin=Xi时,计数Pi=1;取一个时段共M天,将可以用M个ΔTmin构成ΔTmin的时间序列{ΔTminj},(j=1,2,3,…,M),在这个序列中,统计出各档Xi温差值上ΔTmin出现的频数f(xi):
即可以得到反映某个温差位Xi拥有多少样本量的频次分析序列{Xi,f(xi)}。观察不同长度的时间序列时,需将频次量转化为归一化的频率值F,数据处理流程见图1。

图1 F 值计算流程
1.3 客观基础
分析所选用的特征频率反映一段时间内两个站点日气温极小值的差值的分布特征,差值集中时特征频率较高,差值分散时特征频率较低,由于以往对这类频次/温差位数据序列进行系统分析的理论文献够不丰富,因此对于分型方法的客观依据的阐述,以常识性规律的归纳为主,包括:
(1)如果一个站点环境干燥,另一个站点环境湿润,它们之间的气温差值分布相较于两个湿润的站点间的气温差值分布要分散一些;两个荒漠环境下干燥站点间的气温差值分布比两个临海环境下湿润的站点间的气温差值分布分散,这说明地面观测站点的环境条件,与两个站点的气温空间差值的分散程度存在关联,进而也就与特征频率有关联。
(2)即使下垫面条件相近,相对干燥的冬春季,与水汽充分的夏秋季相比较,站点之间产生的气温差值也会相对分散,再次说明观测环境中的含水量等因素与特征频率有关联。
(3)受地形等地理条件影响,对天气系统能同步响应的站点之间产生的温差值会相对集中一些,说明两个站点的地形系数差异对特征频率会有影响。
(4)在众多无风的安静夜晚,空气团的热交换形式主要是长波辐射散热,日气温极小值形成的机理较单一,便于更稳定地提取下垫面的特征信息,同时,日气温极小值对环境敏感,如通常城市中测得的日气温极小值会高于郊外,因此气温极小值为基础的数据序列中隐含有可以用于提取分析观测环境的信息。
(5)天气背景条件为阴天时,站间的日最低气温差值更为集中。使用阴天较多的成都地区国家站30 a的74710 组有日照背景的站间最低气温差值样本,同45828 组两站均无日照条件的站间最低气温差值样本相比较,后者的温差值分布更集中(参考频次中位数对应的温差位的绝对离差值小30%),这显示出站间日最低气温差值的分布方式,以及特征频率还会附带有天气背景条件的波动量。但特征频率中的环境影响量却是比较稳定的值,因而可以通过对较长时间序列的观察削弱天气背景影响,突出特征频率中的环境影响量。
(6)间距小的站点间,温差值的分布要集中很多,距离对特征频率的影响强势并且恒定,因此,要突出观测环境量的影响必须消除距离影响因素,这是方法的运算基础。
1.4 实验设计
成都地区气候平和,有很多无风和寡照的天气,有较多日最低气温是在绝热环境下的昼夜日周期背景下形成[15],站间的气温差值分布集中并且比较稳定,有利于提取下垫面的差异信息。当使用一定时间长度序列,平均化天气条件对特征频率F的影响使其稳定,再设置量化因子Kf,量化距离影响因素Kf=∂F/∂D(式中F指特征频率,D指站间距离),进而下垫面一致性的影响就可以用Kf体现。通过选用观测条件一致的站点组合的Kf值作为判断两个站下垫面一致性的参照指标,再对本地国家站、区域站间的大量温差数据组合的排序计算,就可以实现区域自动站以足够的一致性指标Kf值聚类分型。
通过统计成都地区站点间组合的距离D与特征频率F,可以粗略得到F随D的渐变关系F=K×D+11.3,如图2 所示。

图2 成都地区国家站呈现的频率与距离的关系
图2 中,如果F值在距离增加时急速衰减,说明两个站点不容易重叠出现固定气温差异值,联系不稳定,即关系式中K对一致性有所反映。但斜率k不方便观察,Kf将斜率k的变动量转化为便于比对的指标化倍率值,整理成都本地样本的实际数据可以得到K2f=((K×D)2+23×K×D+128)×D。由此这些样本的Kf提取式为
指标值Kf中和了距离权重后,不再随距离变化,图3为成都地区国家站间形成的Kf值。

图3 国家站之间呈现的Kf 指标与距离的关系
Kf指标量不随距离变化的特点,为观察特征频率中的其他影响因素提供了基础,图4 中的A,B,C 3 个站点,A,B 站点为环境理想的站点(国家站),C 为观测环境遭受干扰的站点(国家站),在同一时段,A,B站点间的Kf值达到45,但A,C 之间Kf值为35,B,C之间Kf值只有32,这组样本中,C 站的观测环境异样对Kf的影响很明显。

图4 3 个样本站的环境影像(1 ∶2256)

图5 分型计算流程
Kf指标整合了F值与站间距离的关系,同一间距上F越高两个站点的环境相似度会越高;不同间距则Kf越大,两个站点的环境相似度会越高, 因此Kf可用于设置站点间的比对阀值[21]。成都地区国家站间的Kf值主要在30 ~48,区域站与国家站间Kf值分布在8 ~48。以国家站间的下限值30 为参考阀值,聚类分型的实现的方法流程如图4。主要流程步骤包括:基础数据导入与{Xi,fi}序列生成;站点地理信息导入与Kf计算;Kf排序;Kf值聚类分型及后续分型特征解析。
2 结论与讨论
使用成都地区14 个大监站(国家站)和252 个区域站的大样本验证,用大监站间的Kf为参考标准,经运算分型,站点被自动分为3 个大群。第一大群(A群)包含全部大监站和125 个区域站,该群观测环境条件的主要特点是乡村站点,农田下垫面为主,市区内没有站点入群,地理位置分布见图6(a);第二大群(B群)包含79 个区域站,该群观测环境条件的主要特点是较大面积的公园绿地、山区森林等,自然下垫面为主,地理位置分布见图6(b);第三大群(C 群)包含48个区域站点并形成6 个子群,其中站点数量最多的是32 个城镇站点,地理位置分布见图6(c)、图6(d)。
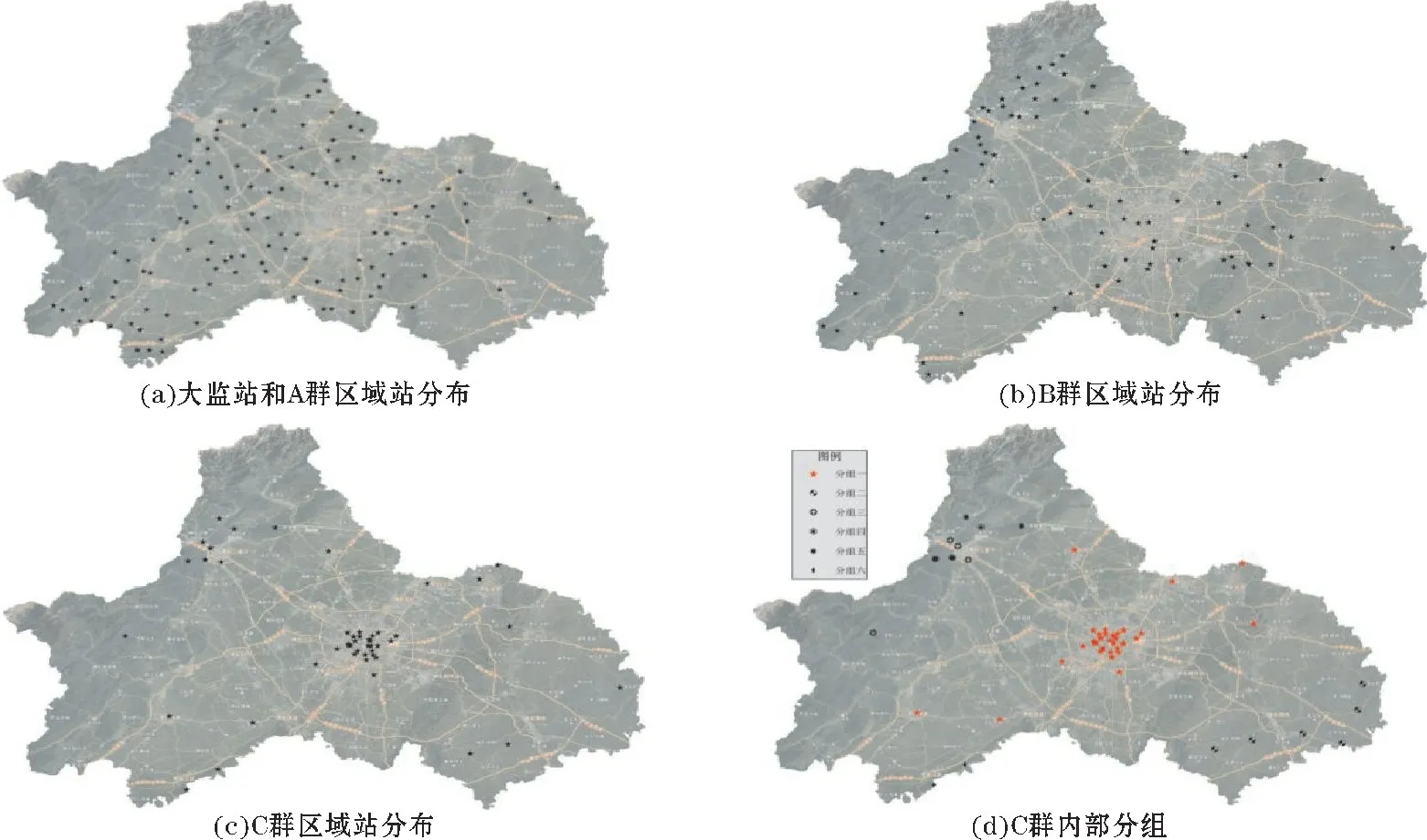
图6 分群站点位置分布
从图6(a)、图6(c)对比看出,通过聚类分型,城镇型站点与乡村型站点在地理分布上被清晰地自动区分,同时这两类站点在观测数据上也有显著差异:图7对比了所有站点在2008年2-4月的平均相对湿度和平均最低温度,可见A 群相对湿度明显高于C 群,A群最低气温明显低于C 群。

图7 分群站点平均相对湿度与最低温度对比
表1 ~4 对A 群和C 群数据进行了抽样检查。

表1 2008年2-4月阶段平均值数据对比
表1 中的数据反映本地样本在季均值方面,C 群(城镇站)的最高气温略高于A 群(乡村站)点,最低气温明显高于A 群;C 群的相对湿度明显低于A 群,同时日较差也低于A 群。说明分型算法区分出的这两类站点,在气温、湿度数据上有明显的整体差异。
统计在表2 中的数据反映本地样本最高气温时段的相对湿度逐日对比结果,城市站点多数低于乡村站点。说明分型算法区分出的乡村站点的湿度明显整体高于城市站点,分型运算有效。

表2 样本90 d 数据里日气温极大值时段城市站点与乡村站点相对湿度的统计比较
统计在表3 中的数据反映,本地样本最低气温时段的相对湿度逐日对比结果,城市站点绝大多数情况下低于乡村站点。再次说明分型算法区分出的乡村站点的湿度,在最低气温发生时段显著整体高于城市站点,乡村站点会有更多的霜、雾、露,分型运算符合客观存在。

表3 样本90 d 数据里日气温极小值时段城市站点与乡村站点相对湿度的统计比较
表4 的数据反映出,绝大多数情况下,分型归类为城市站点(C)的样本站点的日气温极小值要高于归类为乡村型的站点,这种结果符合常识,再次说明分型算法准确有效。

表4 样本90 d 数据里日气温极小值(Tmin)城市站点与乡村站点的统计比较
特别说明的是,在这组随机抽取的6 个数据样本站点中,3 个城市型站点间距10 ~15 km;3 个乡村型站点中,S1018 距3 个城市型站点间距20 ~30 km,距另外两个乡村型站点间距为55 km和65 km。
3 结束语
提出一种区域气象站自动分型的方法,分型算法能够综合反映站点下垫面差异,算法输出的结果在气象观测台站管理应用、结论的物理机制解析以及相关理论的建立完善等方面都有实质意义。方法采用的观测数据为一个空间区域内的气温差异量,是很重要的热动力基础值,但这个量的演化规律在以往台站管理中很少被发掘应用,根据算法输出结论的精细程度,利用这种方法可以解决的问题包括:对大量区域自动站的观测环境异常变动的自动化在线识别;对站点的布局进行客观研判和优化;与测量数据配套的精细化地形系数的自动生成;分布式观测系统的构建;以高精度监控阀值改善数据质量等。其中分布式观测系统架构下站点的互补替代与数据的平行应用较为常见,如解决成都站数据的替代与延续需求。
猜你喜欢
高师理科学刊(2020年2期)2020-11-26 06:01:32
科技创新与应用(2020年4期)2020-02-25 13:31:25
光学仪器(2019年3期)2019-02-21 09:31:55
制造技术与机床(2018年12期)2018-12-23 02:41:22
铁道通信信号(2018年3期)2018-04-19 02:32:44
湖北农业科学(2017年12期)2017-07-15 20:45:34
中成药(2017年6期)2017-06-13 07:30:35
铁道通信信号(2016年6期)2016-06-01 12:10:20
铁道通信信号(2016年3期)2016-06-01 12:10:18
中国铁道科学(2015年1期)2015-06-26 08:33:56
