
基于分治和边缘缓存机制实现海量数据采集
2023-05-30 09:14王伟李均毅郭威
信息化建设 2023年2期
王伟 李均毅 郭威

为满足供应商多元评估要求,完成海量评估数据的采集,通过使用采集、预处理分治和数据边缘缓存机制,实现以最小资源代价完成供应商海量数据的采集,同时支持采集工具的动态管理,具备良好的扩展性,能够适应供应商评估体系的动态变化
近年来,电力企业采购的物资类别和数量都呈现快速增长趋势,与之相对应的产品质量、违约等问题也随之呈现增长趋势。电网作为保障社会经济民生发展的重要基础,一旦出现供应商履约和质量问题,将给工程建设进度和电网安全带来极大影响。因此,对供应商绩效评估指标体系优化、评估方法的改进一直是研究的热点。与此同时,为了更加准确地对供应商进行绩效评估,实现评估的立体多元化,对供应商的数据采集提出了更高要求,数据采集从原有的物资供应过程数据采集变成全方位供应商数据的采集,包括但不限于供应商的财务状况、风险评估、产品质量、运行效果、法律风险等,并且评估要求会随着时间和时长环境的变化不断新增,采集的数据类型和数据量级都出现了巨大的变化,传统的数据采集模式已经无法满足要求,对数据采集的时效性和数据量级都提出了更高的要求。
海量供应商评价数据所面临的采集问题
采集来源和方式更加复杂。供应商现有的评估方式是根据采集物资供应过程中招标采购、质量监督、交付过程、历史违约等记录,采集来源为电力公司内各个业务系统的数据。要想对供应商进行多元立体化的评估,数据采集的策略需由原来的选择性采集变成全采集,采集内容也从单纯的物资供应流程扩展到供应商的各个方面,不仅包含供应商的工商、股东及人员、投资等信息,还包括知识产权、司法风险、企业发展、经营状态等所有产品质量相关信息;数据来源也从各个业务系统扩展到互联网,不仅类型更加丰富,采集方式也涉及各项数据类型及平台使用接口、文件、推送、爬取等方式。
采集数据量级增长且需要支持动态扩展。数据采集策略的转变,导致采集过程中数据呈现量级增长,特别是针对反映产品實际质量的一些运行过程数据,不仅量大又实时性要求高,且如果丢失可能会影响最终评估精度。同时对供应商多元评估的要求,使得评估体系处于动态变化的过程,对应的采集内容也是一个动态变化的过程,所以采集的吞吐能力需要支持动态扩展。
评估分析数据量化并做好清洗和预处理工作。绩效评价的过程中,基于多角度的评价要求,采集的供应商数据会被反复使用,例如使用TOPSIS进行分析,所有代入的数据都是经过规则量化的数值数据。而实际的数据采集过程中,数据来源广泛且经常会面临多源异构数据结构、数据价值密度低等问题,数据无法被后续评估直接使用,所以采集的数据在进行评估计算分析之前,需要提前做好数据采集后的清洗和预处理工作,增加供应商评估分析的效率。
多元采集系统的设计架构与思路
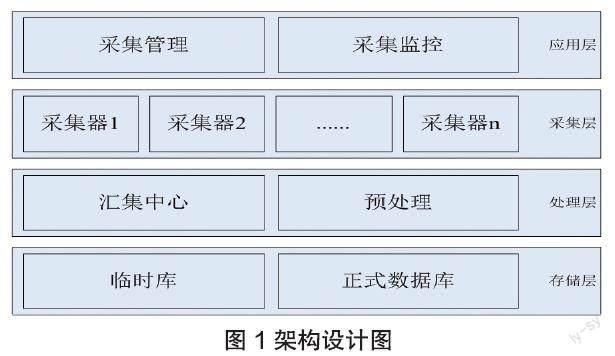
综合分析当前供应商多元评价采集系统的要求,并考虑到在实际的使用过程中,供应商评估是一个后置过程,没有实时性要求。所以整个采集过程对数据接收有实时性要求,但是对于数据的预处理没有实时性要求。为了以最小资源代价完成海量数据的采集,采集系统设计应遵循可扩展的采集框架、采集和预处理分治、汇集处理边缘缓存的思路。
可扩展的采集框架就是对每个采集数据来源设定采集和预处理工具,工具的生命周期和运行管理由系统统一管理,同时采集系统建立统一规则,支持采集和预处理工具动态扩展新增和修改。采集和预处理分治是基于数据的采集需要实时处理,但是对预处理没有实时性要求,所以为提高采集的吞吐量,从整体上把数据的处理分成两个阶段,汇集处理阶段和预处理阶段。汇集处理阶段只需把采集的数据存入临时数据库,业务逻辑简单,便于分布式设计和部署;预处理则负责后续的数据的整理、清洗和正式存储过程。汇集处理边缘缓存是由于汇集处理阶段业务逻辑统一,只需要在收到数据后存入临时数据库,而整个汇集处理过程耗时最长的为存入临时数据库,为提高吞吐量,设计边缘缓存机制,对采集数据存入缓存,延迟处理以提高采集速率,用内存空间换取处理时间。其架构设计图如图1所示。
数据的采集过程为确定需要采集的数据来源后,定制开发采集器和预处理工具,采集器采集完数据后,把采集的数据经过负载均衡分给各个汇集中心,汇集中心负责数据存入临时数据库,预处理工具从临时数据库拿出对应的数据源的数据,经过清洗和预处理后存入正式数据库。整个过程中,汇集中心以负载均衡结合分布式的方式运行,负责承载整个数据采集压力,采集器和预处理器则只需要专注业务逻辑即可,具体采集过程如图2所示:
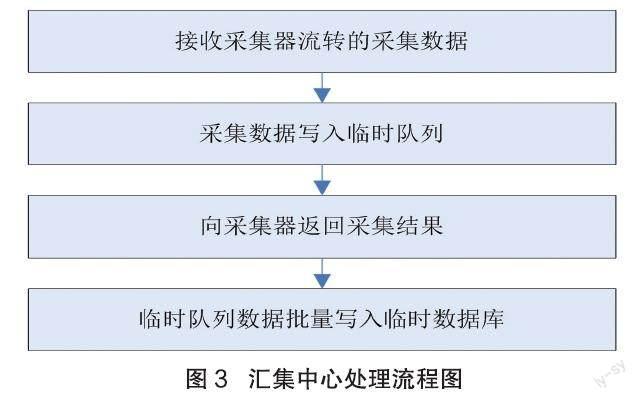
在采集过程中,采集器把采集的数据通过负载均衡流转到汇集中心,汇集中心作为采集数据吞吐的核心组件,对数据处理能力将影响到整个系统处理能力。因为汇集中心整个处理过程中以存储这个操作最为耗时,所以为提高吞吐量,需要建立分布式模型、异步消息队列和批量处理相结合方式,完成采集数据快速入库。其中,汇集中心处理流程如图3所示。
此外,系统对采集器和预处理工具进行统一管理,不同的数据来源采集使用一组采集器和预处理工具进行处理,采集器和预处理工具的运行方式由平台指定,具体的运行方式有单次运行、定时运行和连续运行。其中,单次运行主要针对导入类型的数据来源;定时运行主要针对数据来源定时更新的情况,一般约定与数据来源更新的时间一致,以每天、每周、每月或每年运行;连续运行主要针对设备运行过程中各类实时采集的运行情况。平台负责按照配置执行各项工具的运行。
采集器的主要工作是作为数据采集的适配器,采集数据并转发到汇集中心,根据采集数据来源要求,使用主动拉取或订阅等方式。采集器需要根据数据来源要求具体开发,完成后不需要做过多处理,指定临时表后直接按照通用方式转发给汇集中心即可。
预处理工具的设计需要与采集器一一对应。预处理工具主要完成三项工作,一是对采集器存到临时表的数据进行清洗和整理,二是把处理后的结构化数据存储到正式数据库,三是清除已处理的临时数据。其中预处理工具在处理过程中,为减少数据库操作次数,对临时数据的获取和清除均采用批量模式,提高处理效率。
供应商多元立体化评价是电网物资供应快速发展过程的必然要求,为了能够完成供应商的整体画像,供应商评估数据采集的方式由原来的定向采集转变为全采集的方式,采集维度从物资供应维度扩展到供应商的各个方面,相应的供应商评估数据的采集面更加广泛,采集数据总量呈现量级增长。因此通过分析数据来源和采集要求,设计电网海量供应商评估数据采集系统,在整体架构上支持采集工具的发布和管理,具有良好的扩展性,运用异步分治和边缘缓存的方法,以最小的资源代价解决数据采集问题,为后续供应商的多元评估提供了有效的数据支撑。
(作者单位:国网浙江省电力有限公司物资分公司。本文系浙江省基于人工智能技术的供应商全息多元评价体系解决方案研究项目成果,项目编号B311WF221002)
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
学苑创造·A版(2022年5期)2022-05-19
汉字汉语研究(2019年2期)2019-08-27
当代陕西(2019年14期)2019-08-26
计算机测量与控制(2017年6期)2017-07-01
计算机测量与控制(2017年6期)2017-07-01
电子设计工程(2014年12期)2014-02-27
测绘科学与工程(2014年2期)2014-02-27
对联(2011年10期)2011-09-18
