
基于YOLOv5s的城市道路车辆检测方法的设计与实现
2023-05-30 01:03江子昂李小玉李洋罗力张泽世
电脑知识与技术 2023年3期
关键词:目标检测
江子昂 李小玉 李洋 罗力 张泽世


关键词:YOLOv5s;目标检测;车辆检测
中图分类号: TP311 文献标识码:A
文章编号:1009-3044(2023)03-0019-03
1 引言
截至2022年6月底,公安部已經官方宣布我国的车辆总量已经达到了4.06亿辆,与2021年底比较,新增加了1082 万辆汽车(扣除报废注销量),增长率为2.74%。其中,2022年6月之前新注册登记的车辆就有1657万辆。这说明了我国人民的生活质量处于不断上升的趋势中,对汽车的需求量也在持续的增加,这就导致道路交通拥堵现象越来越多。日益增加的汽车数量以及相对落后的道路交通管理系统是造成道路交通拥堵的最主要根源[1]。车辆目标检测在道路交通管理系统中扮演着十分关键的角色。车辆目标检测属于电脑视觉的典型任务,其目的就是从图片中找出物品的具体的位置,并检测出物品的具体类别是什么[2]。如果可以快速且准确地检测出车辆,就可以对车辆流动做出最及时的管理从而避免道路交通拥堵。
最近几年中卷积神经网络的研究获得了迅猛的成长,使得基于卷积神经网络的目标检测方法也受到了更多的重视与应用,其中比较典型的方法包括RCNN[3],Fast R-CNN[4],Faster R-CNN[5]等一些基于候选框的二层次方法,不过由于这一类方法在训练的时候需要相当大的空间且训练和检测的速度非常慢,因此这类二层次方法并不合适用在交通管理系统中来检测大批次的车辆。YOLO系列算法是当前比较流行的另外一种类型的算法,此算法的训练和检测速度非常快,因此广泛地被应用于工业上面。本文使用YOLOv5算法中的YOLOv5s模型来进行复杂情况下的车辆检测,用数据标记软件labelimg 对公共数据集StanfordCar Dataset[6]进行标记处理,得到用训练、测试和验证各150张汽车图片组成的数据集,基于得到的数据集进行YOLOv5s模型的训练测试和验证,最后利用互联网和实地拍摄的数据材料来实际验证模型的性能。
2 YOLOv5 模型概述
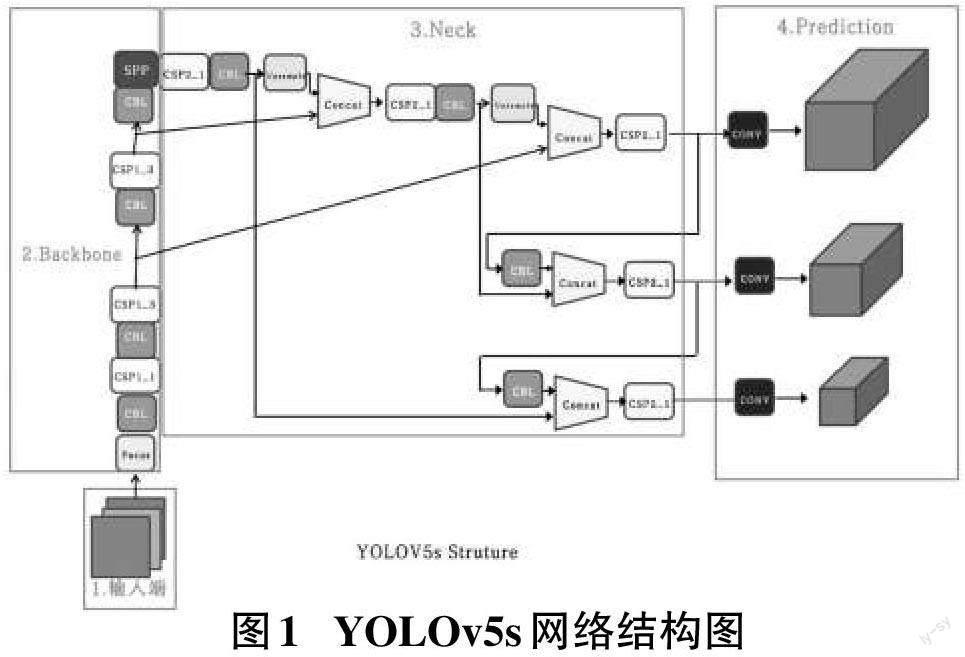
YOLO的意思就是you only look once(你只看一次),这类算法的创造性在于它把目标检测问题看待成回归问题,直接从图像元素开始,计算边框和分类的可能性。YOLO系列算法经过不断的升级更新出现了有YOLOv1[7],YOLOv2[8],YOLOv3[9],YOLOv4[10],YOLOv5 等算法,YOLOv5算法是由Ultralytics LLC有限公司于2020年6月发布的,在其官方的源码库中出现了4各不同的版本,分别是YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四个模型,其中YOLOv5s模型是所有4个模型中深度最少的,特征图的宽度也最小的一个模型,而其他的3种模型都是在YOLOv5s模型的基础上不断深化,并进一步加宽得到的。YOLOv5s 一般由输入端、Backbone、Neck和Prediction四个具有特殊功能的部分组成。图1为YOLOv5s网络结构图。
输入端口YOLOv5s,主要应用了Mosaic图像增强的技术、自适应锚框方法,以及自适应图像缩放方法。Mosaic数据增强是YOLOv5团队成员提出来的,这种方法可以丰富数据集,可以增加很多的小目标,增强网络的稳健性,在小目标的检测过程中效果还是很可观的。另外在YOLOv3、YOLOv4算法中,不同的数据集在进行训练的时候,初始锚框值都是采用单独的程序计算得到的,但官方给出的YOLOv5算法的源码中增加了自适应锚框方法和自适应图像缩放方法,使得在每一次训练过程中,此算法都会自适应的计算不同数据集中的最佳锚框值,并在原始图片中自适应的使用最小的黑边,提升了模型推理能力。
Backbone主要包括Focus结构和CSP结构。如图2所示,Focus结构的主要核心就是切片功能[11],在此模型中原始的608×608的3通道图像输入到Focus结构中,使用切片功能,先变成304×304具有12通道的特征信息图,再经过一次由32个卷积核组成的卷积操作,最终变成304×304具有32通道的特征信息图。此算法中还设计了两种CSP结构,CSP1_X结构在Back?bone主干网络被采用,而另一种CSP2_X结构则使用于Neck部分中。CSP结构首先会将基础层的特征信息映射划分为两个部分,最后通过跨阶段层次结构将它们合并,这种结构不但可以增强网络的学习能力还可以降低计算瓶颈,使模型变得轻量的同时识别准确性不会改变。
Neck部分主要使用了FPN+PAN结构,FPN是将上层的特性信息特点利用向上采样的方法传递融合,传达强语义特征并得以提供进行预测的特征图,PAN则从底向上传达强定位特性信息,这样FPN+PAN结构就可以从不同的主干层对不同的检测层进行特征聚合。YO?LOv5在Neck这一部分并没有按部就班地使用YOLOv4 中的普通卷积操作,而是把CSP2_X结构加入到了Neck 部分,从而提高了对网络特殊信息的整合能力。
Prediction部分YOLOv5也使用了与YOLOv4相似的损失函数,采用了CIOU_Loss 作为目标Boundingbox的损失函数。CIOU_Loss可使预测框回归的速率和准确性都更高一些。CIOU_Loss为公式(1) ,其中v 是度量长宽比一致性的参数,应该确定为公式(2):
3 实验与结果分析
本节首先会介绍实验所用到的数据集及其处理的方法,然后是实验的运行环境及依赖库的版本,再然后是实验的过程,最后是重点分析YOLOv5s模型的性能和实际的检测效果。
3.1 数据集介绍和处理
该实验使用的是公共数据集Stanford Car Dataset。这个数据集是由stanford所建立,是一个汽车资料集合,数据集中包括了16185张汽车图像,汽车的种类也非常的丰富,足足有196种汽车。基本上现实生活中所有的车辆的图像在数据集中都可以找到。数据集被分为有8144个训练图片的训练集和8041个试验图片的测试集,而其中的各个车辆分类都已大致分成了50-50个分割。类通常指品牌,型号,生产日期等级别,2012的特斯拉Model S或者是2012 的BMW M3 coupe。
在处理数据集阶段使用labelimg对数据集进行标记,labelimg是一款给图形标注类别的工具,它是基于python開发的,图形界面则采用QT开发,用此工具可以使标记的图片保存成各种网络模型训练时所需要的文件格式。使用labelimg对数据集中的图像进行处理,指明识别对象为car类别,保存文件格式调整为yolo_txt格式,如图3所示,经过labelimg标记处理后得到数据集的带标签的yolo_txt文件,只有得到了带标签的yolo_txt文件才可以训练模型。分别对训练集、测试集和验证集各150图片进行标记操作,得到最终的数据集。用这些数据集来进行模型的训练。
3.2 实验环境
YOLOv5是利用Python所编写所以运行环境中需要安装Python,训练YOLOv5s模型所需要的依赖库之间的版本对应是非常严格的,版本之间的不对应会导致模型无法训练的结果,此实验是严格按照表1所示的版本进行模型训练的。其中IDE是集成的开发环境,是提供程序开发环境的工具,包含了代码编辑器、编译器、调试器和图形用户界面等工具;依赖库numpy是一种数字计算扩展,对于大型矩阵的运算是非常方便的;依赖库pandas是在数据分析阶段所使用的库;依赖库pillow是图像处理库,具有对图像进行裁剪、调整大小和颜色处理等功能;依赖库scipy是用来进行计算大多数函数运算的库;依赖库Pytorch是运行环境中最重要的库,它是由Facebook(脸书)的人工智能研究院开发的,是一个用Python开发的可续计算包,主要有两个功能:1) 具有强大的张量计算。2) 包含自动求导系统的深度神经网络。
3.3 实验结果
根据搭建的环境和标注处理好的数据集来训练模型,训练weights(权重)设置为YOLOv5s.pt,batchsize(每批次样本的数量)调整为4,增加模型的泛化力,经过100次迭代最终得到训练好的模型文件YO?LOv5s.pt,模型性能如表2所示,其中Precision是查准率的意思,表达式为公式(3) ,其中TP为正样本正确分类的个数,FN为正样本未分类的个数,训练曲线图如图4所示,图中Precision的数值趋于平稳缓和并数值上接近1,说明模型的准确度已经很高了;Recall是查全率的意思,表达式为公式(4) ,其中FP为没有正确分类的个数,训练曲线图如图5所示,图中Recall的数值最后维持在0.8 左右,说明模型的失误检测率低;mAp@0.5和mAp@0.5:0.95:mAp是用Precision和Re?call作为两坐标轴作图所围成的范围,越靠近1,模型精度就越高[12]。根据以上数据可以得出实验训练出来的模型在车辆识别的正确率是非常高的。
3.4 实际检测
为了实际检测训练好的YOLOv5s.pt模型的识别准确度,使用训练好的YOLOv5s.pt模型检测在互联网上找到的一张带有汽车的图片所需要的时间为11.1ms,结果如6所示,为了具体的验证模型的识别准确性,采用实地拍摄图片和视频用YOLOv5s.pt模型进行检测,结果如图7所示。
根据图6和图7可以看出,无论是互联网上的图片还是实地拍摄的图片模型,都准确地检测出图片中的车辆可以准确地把图片中的车辆用红色的方框标记出来,并没有出现错误,准确度都在90%左右,这说明模型已经训练得比较好了。
4 结束语
本文把YOLOv5算法中的YOLOv5s模型运用到车辆检测中,使用Stanford Car Dataset数据集训练、测试和验证模型,得到YOLOv5s.pt模型文件,使用训练好的模型文件进行检测,结果表明识别的准确率非常高,可以对车辆进行高准确度的检测,实现了城市道路车辆的有效检测,这对城市道路管理有着非常大的意义,可以提高城市道路车辆管理的效率,有效地避免道路交通拥堵。
猜你喜欢
科技创新与应用(2016年36期)2017-02-21
科学与财富(2016年28期)2016-10-14
哈尔滨理工大学学报(2015年5期)2016-01-19
湖南大学学报·自然科学版(2015年10期)2015-11-30
现代电子技术(2015年20期)2015-10-26
现代电子技术(2015年14期)2015-07-22
