
第二讲 中医药研究中统计分析应遵循的基本思路
2023-05-25 07:19姚应水
现代中药研究与实践 2023年2期
姚应水
(1.皖南医学院 公共卫生学院/慢性病防制研究所,安徽 芜湖 241002;2.安徽中医药高等专科学校临床医学系,安徽 芜湖 241002)
在中医药科学研究中,统计分析的正确选择是得到可靠结论的基本保证。不同的统计分析方法有各自的应用条件和适用范围,实际应用时,必须根据研究目的、资料的性质、设计方案以及样本含量大小等选择适当的统计分析方法,以期达到统计分析为科学研究服务的目的[1]。研究者的统计学知识和分析策略对保障科研工作的科学性与严谨性具有重要作用。在中医药科学研究中,统计分析方法的选择可遵循以下的基本原则:(1)研究分析的目的及意义;(2)反应变量是单变量、双变量还是多变量;(3)欲分析的资料是属于计量资料、无序分类资料、有序分类资料中的哪种类型;(4)欲分析的资料所属的设计方案,是完全随机设计、配对设计、随机区组设计、析因设计及其他的设计类型;(5)自变量(影响因素)是一个还是多个;(6)分类变量是几个水平,即是一组、两组、多组样本;(7)欲分析的资料样本量是否较大;(8)样本量较小时,判断资料是否满足所选用的统计分析方法的应用条件。
1 单变量计量资料的分析思路
1.1 样本均数与已知总体均数比较
该类资料的统计分析步骤为:单变量分析;资料为计量资料;样本均数与已知总体均数比较;先看样本量大小,若样本足够大,则选用单样本t/Z 检验(样本均数与总体均数比较的t/Z 检验);若样本较小(n < 50),则需要先判断该资料是否符合正态分布,若资料符合正态分布,选用单样本t检验;若不符合正态分布,则考虑变量变换或者选用非参数检验方法,即单样本与总体中位数比较的Wilcoxon 符号秩和检验。样本均数与已知总体均数比较的分析思路可参见图1。
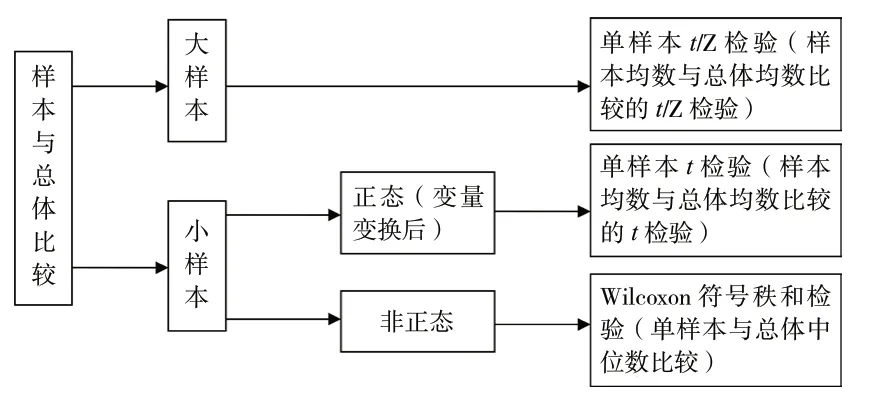
图1 样本均数与已知总体均数比较的分析思路示意图
1.2 两样本均数比较
1.2.1 完全随机设计/成组设计的两样本均数比较资料 先判断资料是否满足正态性和方差齐性的条件,若资料符合正态分布和方差齐性,则选用两样本比较的t检验;若不满足正态性或方差齐性的条件,则考虑变量变换,也可以选用两样本比较的Wilcoxon秩和检验。
1.2.2 配对设计样本均数比较资料 需先求差值,判断差值是否符合正态分布;若符合正态分布,则选用配对t检验;若不符合正态分布,则考虑变量变换或者选用Wilcoxon 符号秩和检验。两样本均数比较的分析思路可参见图2。
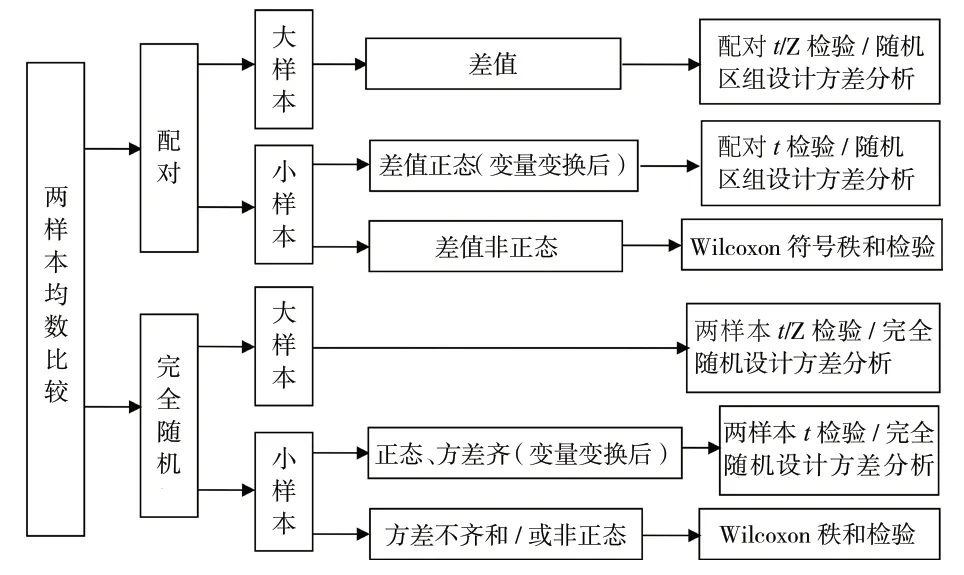
图2 两样本均数/配对样本均数比较的分析思路示意图
1.3 多个样本均数比较
单变量的多个样本均数比较,完全随机设计和随机区组设计两种情况较为常见。
1.3.1 完全随机设计/成组设计的多个样本均数比较 若各组样本服从正态分布,且方差齐性,则选用完全随机设计的单因素方差分析(one-way ANOVA)。其检验结果若有统计学意义,则还需进行两两比较。可根据研究目的在SNK-q检验、LSD-t检验、Dunnett-t检验等两两比较方法中选择。若资料不满足正态性与方差齐性的条件,则选用Kruskal-Wallis 秩和检验。同样,检验结果有统计学意义时,通常需进一步两两比较(可参考相关书籍)[2]。
1.3.2 随机区组设计的的多个样本均数比较 该类资料为单变量的比较,但涉及两个分组因素,一个为处理因素,另一个为区组因素,也称作配伍组。如果资料满足正态性的条件,则采用随机区组设计的双因素方差分析,如果不满足上述条件,则采用随机区组设计资料的Friedman 秩和检验。
1.3.3 其他类型资料的方差分析 主要有析因设计、重复测量资料的方差分析等。析因设计中最简单的是两因素两水平的方差分析,此时观察两个因素,每个因素两个水平,共有2×2 即4 种不同的因素水平组合,要分别计算两个因素的效应及因素间的交互作用效应。而对于重复测量的资料,由于同一受试对象在不同时点的观察值之间彼此不独立,因此,这类资料的方差分析具有一定的特殊性,可进行单变量的方差分析,也可视不同时间点的观测值为多个反应变量,进行多变量分析(可参考相关书籍)[3-4]。
单变量计量资料多样本均数比较的分析思路参见图3。
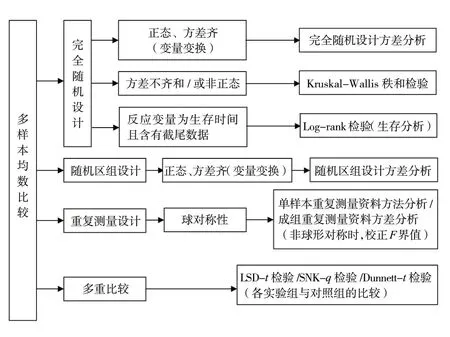
图3 多样本均数比较的分析思路示意图
2 单变量计数资料的分析思路
2.1 两个率比较2×2 表资料的分析思路
(1)完全随机设计两样本率的比较时,首先是考虑样本含量n和理论频数T,若n<40 或T <1,选择Fisher 精确概率法;如果n≥40,T ≥5 时选择卡方检验;如果n≥40,出现1 ≤T <5 的情况,则选择校正卡方检验。
(2)调查设计两变量关联性分析时,分析方法选择同两样本率的比较一样,不同的是要同时计算列联系数,以考察关联的密切程度。
(3)配对设计资料两个率比较时,选择McNemar 检验,变量关联性选列联系数分析。
2×2 表资料的分析思路参见图4。
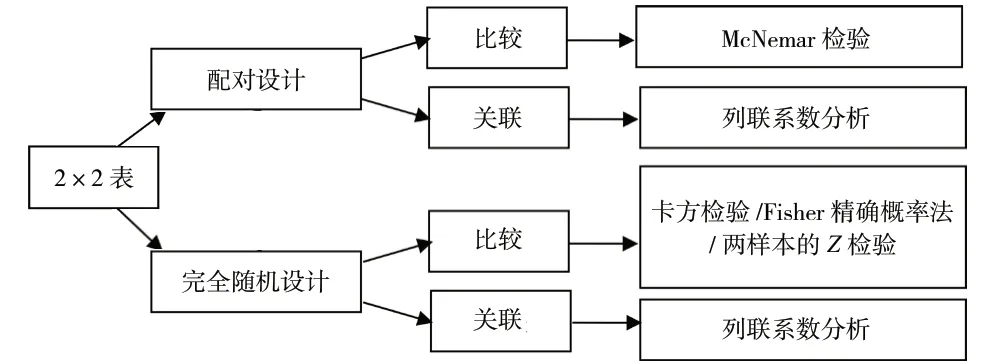
图4 两个率比较的分析思路示意图
2.2 多个率或构成比R×C 表格资料的分析思路
R×C 表资料可以分为双向无序、单向有序、双向有序属性相同和双向有序属性不同四类。
2.2.1 双向无序R×C 表资料 R×C 表资料中两个分类变量皆为无序分类变量时,①若研究目的为多个样本率(或构成比)的比较,可用行×列表资料的χ2检验;②若研究目的为分析两个无序分类变量间是否存在关联,宜用行×列表资料χ2的检验并计算Pearson 列联系数,分析关联的密切程度。
2.2.2 单向有序R×C 表资料 单向有序R×C 表资料有两种形式。
(1)R×C 表资料中的分组变量是有序的(如年龄组),而应变量是无序的(如疾病的类型),其研究目的通常是分析有序分组变量间率或构成比的差别。例如:分析不同年龄组某病患病率的差别,此种单向有序R×C 表资料可用行×列表资料的χ2检验进行分析。
(2)R×C 表资料中的分组变量为无序的(如药物分甲、乙、丙三种),而应变量是有序的(如药物治疗效果是治愈、有效、无效、恶化、死亡的等级),其研究目的为比较不同对比组的有序等级是否有差别。例如:甲、乙、丙三种疗法的治疗效果比较,此种单向有序R×C 表资料宜用秩转换的非参数检验进行分析,即Kruskal-Wallis 秩和检验。
2.2.3 双向有序属性相同的R×C 表资料 R×C表资料中的两个分类变量皆为有序且属性相同。该种资料实际上是配对四格表资料的扩展,即水平数≥3的配伍资料,例如对同一批样品用两种检测方法同时进行检测,其检测结果为-、±、+、++、+++。其研究目的通常是分析两种检测方法的一致性,此时宜用一致性检验或称Kappa 检验。
2.2.4 双向有序属性不同的R×C 表资料 R×C表资料中两个分类变量皆为有序的,但属性不同。对于该资料分三种情况。
(1)研究目的为分析等级分组变量之间应变量有无差别时,例如分析不同年龄组(20 ~、30 ~、40 ~、50 及以上)患者疗效(治愈、有效、无效)之间有无差别,可把该资料视为单向有序R×C 表资料,而选用Kruskal-Wallis 秩和检验。
(2)研究目的为分析两个有序分类变量间是否存在相关关系,选用等级相关分析。
(3)研究目的为分析两个有序分类变量间是否存在线性变化趋势,宜用线性趋势检验。
R×C 表资料的分析思路可参见图5。
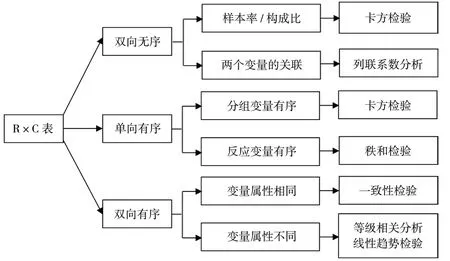
图5 R×C 表资料的分析思路示意图
3 单变量等级资料的分析思路
两组配对设计的资料比较,可选Wilcoxon 符号秩和检验;成组设计/完全随机设计的两样本等级资料比较,可选两样本比较的Wilcoxon 秩和检验或Mann-Whiney U 检验;若为成组设计/完全随机设计的多个样本等级资料比较,可选Kruskal-Wallis 秩和检验;随机区组设计的多个样本等级资料比较,选择Fridman 秩和检验。
单变量等级资料的分析思路参见图6。
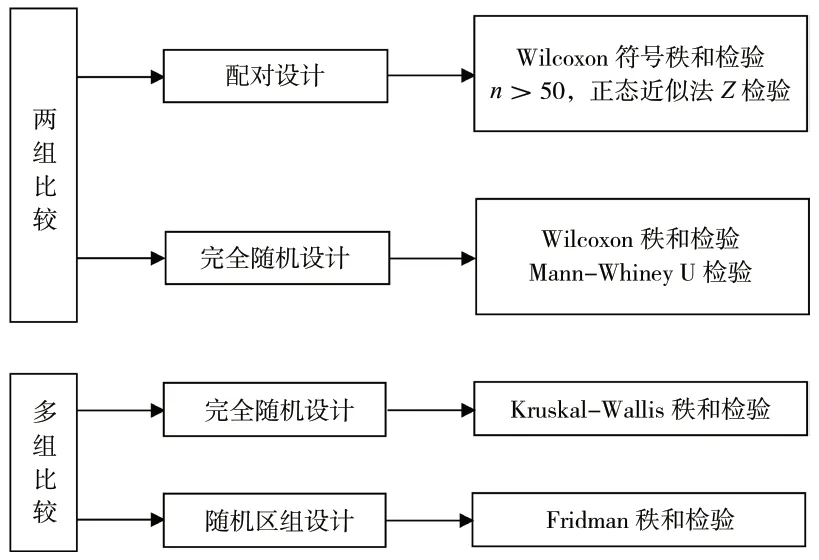
图6 等级资料的分析思路示意图
4 双变量资料的分析思路
4.1 直线相关分析
分析两变量的相关关系时,先绘制散点图,如果图中提示两变量有线性趋势,且两变量满足双变量正态分布,可选Pearson 直线相关分析;若两变量不满足双变量的正态分布或是等级资料,可选Spearman秩相关分析。
4.2 直线回归分析
分析两变量的回归关系时,先绘制散点图,如果图中提示两变量有线性趋势,且应变量满足正态分布时,可选直线回归分析。
4.3 曲线回归分析
分析两变量的回归关系时,若散点图显示两变量的关系呈曲线趋势,可进行曲线直线化变换,也可按曲线类型作相应曲线回归分析,如指数曲线、多项式曲线、成长曲线等分析方法。双变量资料的分析思路参见图7。
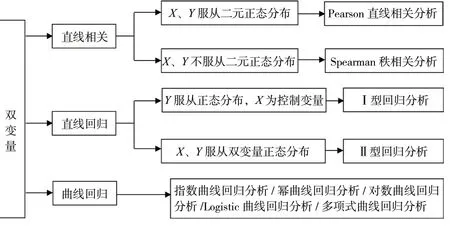
图7 双变量资料的分析思路示意图
5 多因素分析的分析思路
5.1 多元线性回归分析
多元线性回归是直线回归的扩展,研究的因变量只有一个,但是自变量却有多个。在中医药研究中,常被用来筛选危险因素、分析交互效应、控制混杂因素、预测与控制等。多元线性回归分析的前提假定条件是线性、独立、正态及方差齐性。在实际问题中,残差分析常被用来考察资料是否满足这四个前提条件。多元线性回归方程=b0+b1X1+b2X2+…+bmXm,bi(i= 1、2、…、m)称为因变量Y对自变量Xi的偏回归系数,表示除自变量Xi以外的其余m-1个自变量都固定不变时,自变量Xi每变化一个单位,因变量Y平均变化的单位数值,确切地说,当bi>0时,自变量Xi每增加一个单位,因变量Y平均增加bi个单位;当bi<0 时,自变量Xi每增加一个单位,因变量Y平均减少bi个单位。标准化偏回归系数常常用来比较各个自变量对反应变量的贡献大小。确定系数和调整的确定系数常常用于评价模型拟合效果的好坏。对整个回归模型的假设检验一般采用方差分析,对各总体偏回归系数是否为零的假设检验常采用t检验。当建模时存在多个自变量时,自变量之间可能会存在着较强的相关性,即多重共线性现象,这种情况下会使模型参数估计值不稳定或不易解释。逐步筛选变量时一定程度上解决此类问题的最简单的做法,其次可以利用主成分间的正交性即采用主成分回归方法来解决共线性问题。多重线性回归分析中筛选自变量的方法有前进法、后退法、逐步回归法和最优子集法等。用于筛选自变量的指标有残差平方和、残差均方、确定系数、调整的确定系数、Cp统计量等。
5.2 二分类Logistic 回归分析
Logistic 回归模型分析是多变量统计方法中的重要内容,根据设计类型和构建似然函数模型的不同,可分为非条件模型和条件模型两类。自变量X1,X2,…,Xm可以是连续型变量,也可以是离散型变量,因变量是分类变量。该方法可以筛选危险因素、校正混杂因素、预测与判别。Logistic 回归模型的参数估计常采用最大似然法,求得Logistic 回归方程后,仍需对回归方程和每个回归系数进行假设检验。回归方程的检验一般可用似然比检验、Wald 卡方检验、记分检验等,回归系数的假设检验常用Wald 卡方检验。为使建立的Logistic 回归模型更为稳定,需要对回归自变量进行筛选,根据自变量的作用大小来决定是否将其引入回归方程。Logistic 回归模型的参数β和OR值有联系:当某自变量的回归系数β>0 时,其OR>1,该因素为危险因素;当β<0 时,其OR<1,该因素为保护因素;当β=0 时,其OR=1,该因素对结果不起作用。Logistic 回归分析结果报告应包括:危险因素、相应的检验统计量、P值、各因素的β、标准误(SE)、各因素OR值及OR值的95%可信区间。
5.3 生存分析
生存分析是将终点事件的出现与否和达到终点所经历的时间相结合起来进行分析的方法,其主要特点是考虑了每个观察对象达到终点所经历的时间长短。终点可以是死亡,也可以是疾病的发生,或者是药物的治疗效果等。生存率的估计有寿命表法和Kaplan-Meier 法,前者适用于大样本资料,后者适用于小样本。Cox 模型属于比例风险模型。模型中回归系数βj的含义是变量Xj每改变一个单位,风险函数增加exp (βj)倍。Cox 回归分析可用于影响因素分析、校正混杂因素后的组间比较以及生存预测等[5]。
上述三种回归模型形式比较相似,不同之处在于因变量的资料类型,若Y为数值变量资料,可考虑选用多元线性回归分析;若Y为分类变量资料,特别是二分类变量,考虑选用Logistic 回归分析;若Y为时间变量资料,则优先选用Cox 比例风险模型。这三种多因素分析模型中,对自变量未进行特别规定,既可以是数值变量,也可以是分类变量,但是当自变量为无序多分类资料时,分析前要进行哑变量设置,以有利于结果的正确分析和解释。
6 结论
数据管理和分析贯穿整个中医药研究过程中,不同类型的研究,数据管理和统计分析的方法及指标选择不同,应掌握每种具体方法的应用条件,科学合理地选用,对中医药研究的顺利实施至关重要。
猜你喜欢
小学生学习指导(低年级)(2021年3期)2021-07-21
考试与评价·八年级版(2020年4期)2020-10-26
考试与评价·八年级版(2020年1期)2020-10-26
考试与评价·八年级版(2020年1期)2020-10-26
小学生学习指导(低年级)(2018年3期)2018-01-31
数学小灵通(1-2年级)(2017年10期)2017-11-08
农家科技中旬版(2016年12期)2016-04-16
系统医学(2016年8期)2016-02-20
中国现代医生(2014年10期)2014-04-23
软件工程(2009年10期)2009-01-12
