
基于多峰标签分布学习的多任务年龄估计方法
2023-05-24 03:19何建辉胡春龙
计算机应用 2023年5期
何建辉,胡春龙,束 鑫
(江苏科技大学 计算机学院,江苏 镇江 212100)
0 引言
面部年龄估计指通过人脸面部图像对人的真实年龄进行预测,是目前计算机视觉、生物特征识别领域的一个热点课题。现实中年龄信息的获取难度较高,且普遍依赖于个人隐私信息的读取,面部年龄识别技术能够避免这一敏感问题,并且扩展应用在各种服务领域[1]。面部年龄估计过程主要包含两个部分:特征提取和估计方法。基于深度学习的特征提取方法能够在像素级上捕捉人脸图像中的特征信息,相比传统的手工特征提取方法更具鲁棒性,因此深度卷积神经网络(Convolutional Neural Network,CNN)已经在年龄估计任务中的特征提取部分占据绝对位置。年龄估计任务的关键在于如何提取年龄标签间的顺序性和模糊性,即年龄标签间存在着明显的序数关系,并且标签越近,人脸特征越相似。在分类和回归方法中常用的年龄标签表示方式如one-hot 编码和回归值难以体现出复杂的类间关系,因此将年龄估计任务简单地划分为分类任务或者回归任务的研究方法并不严谨。标签分布学习(Label Distribution Learning,LDL)的目标是预测一组年龄分布,通过标签的概率表示重新表达标签,这种方式不仅能够准确地表示标签,同时可以建立起标签间的关系,从而更好地利用标签的模糊性。
标签的分布方式是LDL 的一个重要组成部分,要获取真实的标签分布,理论上需要对同类样本进行大量的标记,然而目前绝大部分年龄数据集的样本数量都不具备上述条件,因此通常使用特殊的分布函数对目标分布进行拟合。高斯分布被广泛应用在许多基于标签分布的年龄估计任务[2-3]中,概率整体分布在均值μ附近,并且大约99.73%的分布集中在(μ-3σ,μ+3σ)区间。因此通过调整标准差σ,可以获得大量不同模糊程度的年龄分布。然而高斯年龄分布同样存在部分问题,因为高斯函数的曲线具有明显的对称性,而距离相等的其他标签对真实标签的贡献并非完全一致。而且研究[1]表明,人脸的老化趋势具有阶段性,因此各个年龄阶段的老化模式可能对真实的年龄分布产生不同的影响。
基于以上思想,本文设计了一种多峰分布(Multi-Peak Distribution,MPD)年龄编码,并基于MPD 年龄编码提出了一个多任务年龄估计方法MPDNet(MPD Network),主要工作如下:
1)为提取年龄标签的相关性和模糊性,并拟合真实年龄分布的集中性、多阶段和非对称等特性,提出一种MPD 年龄编码;
2)将LDL 和回归学习相结合提出一种深度多任务方法。多任务学习的共享信息表征有助于缓解LDL 训练目标与测试目标不一致的影响,同时减少训练数据不平衡对年龄回归的影响;
3)提出一个高度精简的轻量化特征提取网络,在保证特征提取能力的同时减少了网络参数,使得网络的训练时间大幅缩短,在一定程度上减少了网络对大样本数据集的依赖。
1 相关工作
1.1 面部特征提取
随着大量训练数据集的出现和计算能力的提高,近年来CNN在图像分类、语义分割、目标检测等各个领域中都展现出了最先进的性能。在年龄估计任务上,CNN 所学习到的年龄特征相较于传统手工制作的特征描述符更具鲁棒性,因此在非受限环境下,CNN 的准确率更高。大多最先进的年龄估计方法都采用如VGGNets(Visual Geometry Group Networks)[4]和残差网络(Residual Network,ResNet)[5]等大规模CNN 架构作为基础进行特征提取。Rothe 等[6]在数据增强后的大规模数据集IMDB-WIKI 上训练了20 个VGG-16 网络集合,并计算出预测的平均值作为估计年龄,该方法在第一届ChaLearn LAP挑战赛上获得了第一名。第二年的ChaLearn LAP 挑战赛冠军发现特定年龄组的个性化特征提取才是提高预测精度的关键,于是集成了两个VGG-16 网络,其中一个仅用于估计[0,12]岁儿童的表观年龄[7]。Zhang 等[8]基于多任务的思想,将性别作为辅助信息引入年龄估计,并采用了RoR(Residual network of Residual network)进行特征提取,实验结果表明层次更深的RoR 效果比VGGNets 更好。虽然这些网络在年龄估计中取得了较好的效果,但也具有庞大的网络和大量的参数。随着移动端和嵌入式设备需求的不断增加,一些小内存的轻量级网络被提出,例如采用深度可分离卷积代替标准卷积从而减少参数和计算量的DenseNet[9]和MobileNet[10]等。但减少网络参数并不意味着必须使用更轻量的卷积方式,大量的研究表明,在年龄估计任务中使用标准卷积设计的轻量化网络同样可以达到良好的性能[11-14]。
1.2 年龄估计方法
根据年龄标签的处理方式不同可以将年龄估计方法划分为分类、回归、排序和分布学习四种。传统方法将年龄估计视为分类或回归问题。Liu 等[15]提出了AgeNet,该网络采用一个22 层的GoogLeNet[16]作为特征提取器,分别进行分类和回归的端到端训练,最后通过融合两个网络的预测结果进行表观年龄的估计,测试精度超过分类或回归的单一任务。李大湘等[17]关注到年龄估计中存在的代价敏感问题,通过为每个年龄类设置不同的误分类代价,进一步优化了年龄估计的分类方法。而在基于排序的方法中,研究的重心在于提取年龄标签间的序数关系。Niu 等[18]将年龄估计问题转化为一系列二分类子问题,并构建了一个多输出CNN 来集中解决这些分类子问题。为了提取不同标签样本的判别性特征,Chen 等[19]训练了一系列基础网络,然后聚合所有基础网络的二进制输出,完成最终的年龄预测。
另一种流行的年龄编码方式为标签分布学习,为了提取标签间的模糊性,它将年龄标签值转化为一组概率分布并通过优化它与真实分布间的差异进行年龄预测。Gao 等[20-21]预先对每个年龄标签进行高斯分布编码,然后使用KL(Kullback-Leibler)散度度量网络预测的年龄分布与先验高斯分布之间的差异。年龄估计任务的最终目标是预测一个具体的年龄值,为了解决标签分布学习中训练目标和测试目标不一致的问题,Gao 等[21]对标签分布的结果进行回归学习,提出了DLDL(Deep Label Distribution Learning)框架。为了获得更精确的年龄分布,Zhang 等[14]则通过减小标签分布的范围,仅采用两点分布将年龄标签转化为两个节点的概率表示,同时使用级联网络对多尺度的图片进行训练,充分利用了人脸的上下文信息。李睿钰等[22]认为基于先验的分布学习在正确刻画标签相关性上可能存在误差,于是提出在训练阶段调整假设空间使网络自动生成具有特征约束的年龄分布。Pan 等[23]则从损失函数的设计出发,提出了一种新的损失函数Mean-Variance Loss。该损失函数通过均值损失来惩罚估计的年龄分布与真实年龄的差值,通过方差损失惩罚估计的年龄分布方差,确保分布集中。最后将均值方差损失和Softmax 损失联合嵌入到CNN 中进行年龄估计,并在多个数据集上验证了该方法优于最先进的年龄估计方法。
1.3 多任务学习相关理论
多任务学习[24-27]的目的是利用多个相关任务中的有用信息来帮助提高所有任务的泛化性能,与标签分布学习中常用的级联网络不同,多任务学习的子网络只共享部分结构,并且单个任务的预测结果不会相互干扰。Niu 等[18]和Tan等[28]选择将有序回归问题转化为一系列二值分类子问题,并使用多个CNN 分别进行解决,其中每个CNN 输出对应一个二分类任务,所有子任务共享相同的特征层。不同之处在于Tan 等[28]在年龄分组中编码了相邻年龄之间的关系,即相邻年龄被分组为同一组。此类方法只修改单个CNN 的输出层构建多输出网络,其中每个输出判断输入图像是否属于相应年龄组,因此这类多任务学习网络更像一个整体的回归模型,仍然存在训练数据不均衡和数据分布异构的问题。为了获取更丰富的年龄特征,Xing 等[29]和Yi 等[30]将性别和种族等额外信息引入年龄估计任务,迫使网络学习更细粒度的年龄特征表示。但实验结果表明,引入性别、种族等其他标签与单任务网络相比,精度的提高并不显著。原因是只有当多个任务紧密相关时,深度多任务学习才能带来多个任务性能的共同提升。
2 MPDNet
2.1 多峰年龄分布
基于标签分布学习的年龄估计方法[21,23,31]采用单高斯分布生成真实标签对应的概率分布,高斯分布的概率密度函数定义为:
在上述方法中,通常将参数μ设置为标签值yn,将标准差σ设置为分布模糊程度的可调参数。
单高斯分布的概率密度函数曲线具有对称性,但不同年龄段人脸的衰老过程显然不符合这一性质,并且受后天因素(如环境、化妆等)影响,样本的真实年龄和图像呈现的表观年龄间存在偏差,人脸相比真实年龄会显得更年轻或者更老。因此,为了减小真实年龄标签转化为年龄分布的误差,本文首先针对样本标签的表观年龄分布进行建模。
为了约束表观年龄偏移的区间,本文以K为单位将年龄轴划分为若干年龄组,定义真实标签所在年龄组的第一个标签值为峰值gi(i表示第i个年龄组),并作为该年龄组更年轻的表观年龄代表:
因此gi+1则为该年龄组更老偏向的表观年龄代表,结合两种偏移模式的综合表达,构造了特定标签的表观年龄分布,称为双峰年龄分布Gd:
α为其中一个偏移模式对整体分布的影响因子,由两个峰值点到标签的距离决定:
可以证明Gd仍然满足分布的性质:
最后引入以真实标签值为峰值点的基本分布,构成了具有原始标签相关性和标签个性化的多峰分布Gt:
其中:β是用于控制单个高斯分布权重的可调整参数。为了使分布集中在标签值附近,对于两个分布,本文采用了不同的方差值。
对Gt分布中每个年龄组进行积分,可以获得具有阶段信息的真实年龄概率分布,其中i表示第i个年龄组:
2.2 多任务学习框架
式(8)中,本文按照年龄组对年龄标签进行了粒度为K的粗略分布,这种粗粒度的分布能够尽可能多地提取类间信息,但同时对标签的精确表达具有一定的影响,因此本文引入回归学习,并构建了一个多任务学习框架,如图1 所示。

图1 多任务学习网络Fig.1 Multi-task learning network
在分布学习任务流中,人脸图像通过表1 所示的轻量级网络进行多阶段的特征提取,然后采用一个全连接层构建的分布层输出预测分布,通过缩小和MPD 转化的先验分布间的差异来确保预测分布的准确性。
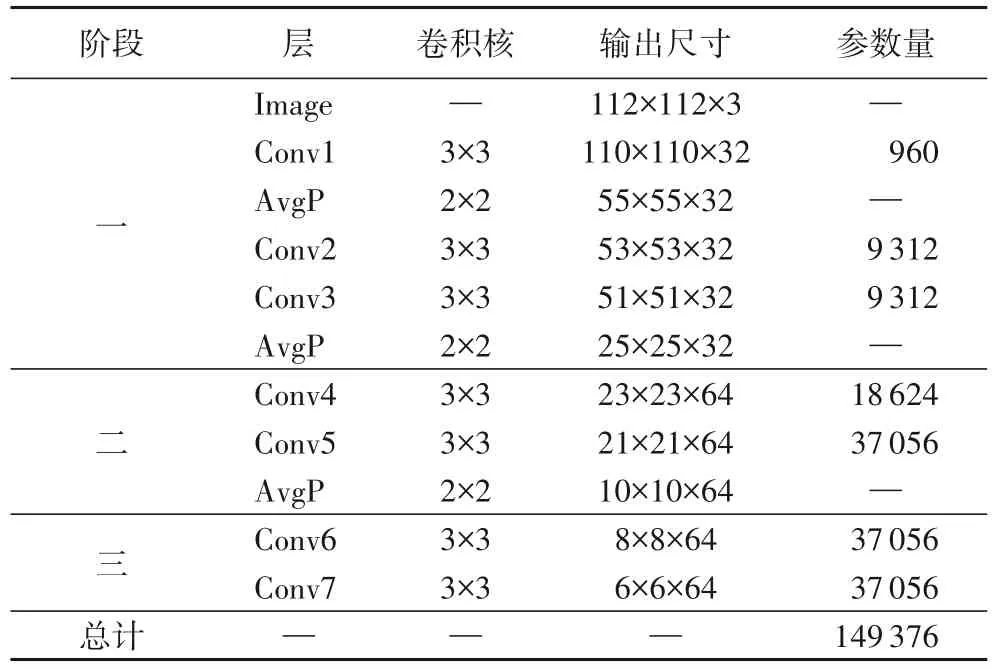
表1 轻量级特征提取网络结构Tab.1 Lightweight feature extraction network structure
本文采用KL 散度作为两个分布间差异的度量。KL 散度的计算公式为:
在回归任务流中,本文使用了多阶段年龄回归,采用由粗到细的回归策略,通过3 个全连接层构成的回归层分别计算特征提取网络每个阶段下的预测概率pi。最后结合3 个阶段的预测计算最终的预测年龄值:
其中:V表示整个年龄段;S表示粗粒度的阶段数;F表示每个粗粒度下细粒度的组数表示阶段s下第f组的概率。对于回归任务的损失函数,本文采用最常用的评估指标平均绝对误差(Mean Absolute Error,MAE),确保训练目标与测试目标一致:
多任务学习框架下完整的损失函数如下:
其中:λ是一个平衡两个任务权重的超参数,通过调整λ可进一步促进多任务学习的互补效果。
3 实验与结果分析
3.1 实验环境
所有实验均运行在NVIDIA A100 40 GB 平台上,内存共计16 GB。
本文采用以下两个人脸年龄数据集进行网络训练:
MORPH[32]:MORPH 是目前最受欢迎的年龄估计任务基准数据集之一,分为Album I 和Album Ⅱ两部分。Album I 包含1 724 张人脸图像,年龄范围为[15,68]岁,其中男性图像1 430 张,女性图像294 张;Album Ⅱ包含了在同一环境下拍摄的55 134 张人脸图像。本文将Album Ⅱ进行随机划分,其中80%作为训练集,20%作为测试集。
MegaAge-Asian[33]:该数据集收集了40 000 张亚洲人的面部图像,年龄范围为[0,70]岁。这些图像大多在非受限条件下拍摄,因此背景、光照、姿势、表情等差异较大。本文使用了3 945 张图像进行测试,其余图像用于训练。
3.2 评估指标
目前面部年龄估计研究通常使用平均绝对误差(MAE)和累积分数(Cumulative Score,CS)来评估方法的性能。MAE 定义为实际年龄与预测年龄之间的平均距离,数值越小表示预测性能越好:
其中:yi和分别表示真实标签和预测年龄值。
CS 指标主要关注方法在一定误差内的预测准确率,计算公式为:
其中:Ne≤j表示估计绝对误差不超过j的测试图像的数量,N是测试图像的总数,年龄估计任务中常用的阈值j主要为3 和5。
3.3 实验内容及结果分析
实验中,本文将输入的图像与人脸对齐并裁剪,将其大小调整为112×112,然后在将图像输入到网络之前对图像进行翻转、旋转和随机擦除等预处理。初始学习率设为0.002,动量和权重衰减分别为0.9 和0.000 1,batchsize 设为128。学习率每80 个epoch 下降到原来的1/10,共训练240 个epoch。年龄组长度K=10,MPD 中的σ1=5,σ2=2.5。
3.3.1 MORPH数据集上的定量实验
为了评估网络的预测精确度,本文选择目前主流的年龄估计方法在多个方面进行对比,并根据方法中的网络参数量划分为轻量级和重量级,实验结果如表2 所示。可以看到,本文方法的MAE 达到2.67,在轻量级方法中仅弱于CEN(Coupled Evolutionary Network)[34]的1.91 和LRN(Label Refinement Network)[35]的1.90;然而CEN 和LRN 均采用知识蒸馏技术,将上一个网络作为新的学习对象,这需要大量的额外训 练。ORCNN(Ordinal Regression CNN)[18]、SSR-Net(Soft Stagewise Regression Network)[13]、C3AE[14]等方法都采用了一个轻量级网络进行特征提取,然而ORCNN 仅关注年龄特征间的序数关系,SSR-Net 和C3AE 则注重年龄特征的模糊性,都没有将两种特性联系起来。轻量级方法中没有对年龄标签进行任何处理的DenseNet[9]和MobileNet[10]效果表现不佳,这说明年龄估计的精确度关键在于构建更符合年龄老化模式的估计方法。同时和参数多达几百倍的重量级方法相比,MPDNet 甚至超过了DEX(Deep EXpectation)[6]和RankingCNN(Ranking CNN)[19]。Posterior[33]、MV(Mean-Variance)[23]、DLDL[21]、BridgeNet[36]、DORFs(Deep Ordinal Regression Forests)[37]等方法虽然精度更高,但存在网络参数庞大、训练时间长、存储空间消耗大等缺点,而本文方法训练时间短、占用空间小,更易部署在移动端,因此同样具有竞争力。
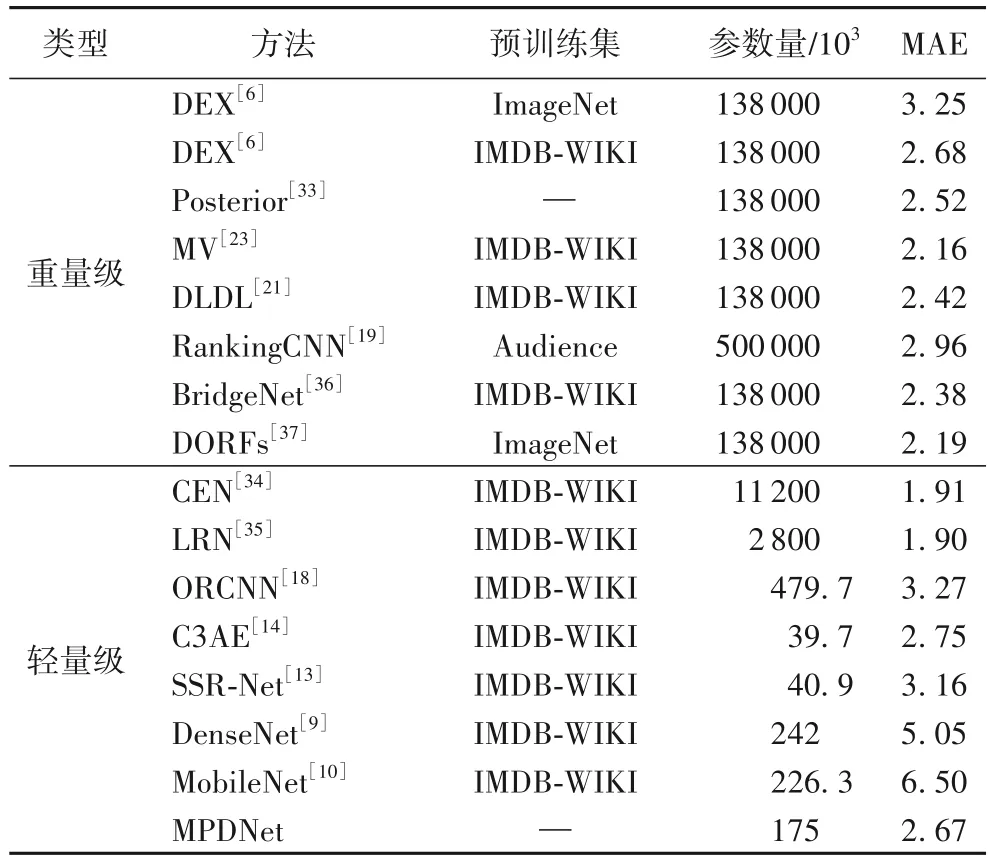
表2 在MORPH Ⅱ数据集上的实验结果对比Tab.2 Comparison of experimental results on MORPH Ⅱ dataset
为进一步验证多任务学习下多峰分布的有效性,针对式(7)和(12)中的参数β和λ进行消融实验,实验结果如图2 和表3 所示。
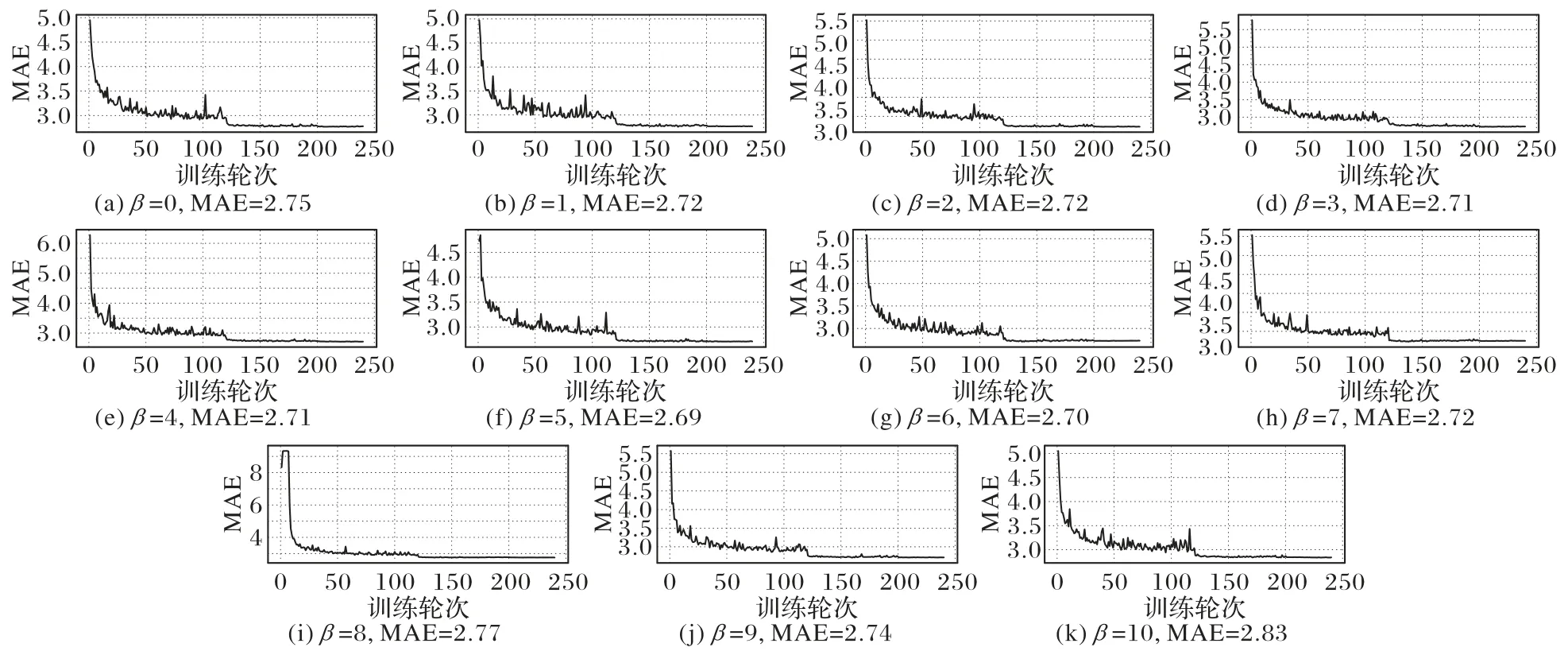
图2 参数β的消融实验结果Fig.2 Ablation experimental results of parameter β

表3 参数λ的消融实验结果Tab.3 Ablation experimental results of parameter λ
图2 中,β=0 和10 分别代表双峰分布和高斯分布,其余均为不同模糊程度的多峰分布。可以看出,仅使用高斯分布时的表现较差,当引入多阶段分布后,增强了目标重要特征的准确表达,网络能提取到更丰富的年龄类间信息,由图2(k)、(a)和(f)可知,MAE 从2.83 分别下降到了2.75 和2.69,测试误差下降了2.83%和4.95%。并且随着多峰分布中单高斯分布比重在一定范围内增加,MAE 的曲线波动逐渐减弱。在多个不同参数值下的MAE 测试结果波动较小,这体现了多峰分布具有较强的稳定性。
在表3 所示消融实验结果中,当λ=0 时,网络仅执行回归任务,受到标签信息不足的限制,网络学习到的特征有限,因此性能明显下降。而当λ为空,仅执行高斯分布学习任务并将分布对应期望值作为预测值时,虽然引入了更多的标签类间信息,但模糊化的分布并非精准的数值,本身存在一定的误差,因此预测性能同样下降明显。相反,多任务学习下的MPDNet 性能始终优于分布学习和回归学习,同时进行回归任务能够有效降低年龄分布的期望值与真实年龄的差值,确保分布学习中训练目标与测试目标一致从而提高分布的准确性。
综上可知,采用多峰分布对年龄标签进行重编码,再结合标签分布学习和回归学习所构成的多任务学习网络增强特征提取能力和类间信息交互,能够有效提升网络在MORPH Ⅱ数据集上的预测精度。
3.3.2 MegaAge-Asian数据集上的定量实验
现有的大多数年龄估计数据集主要采集白人和黑人的人脸图像,然而每个种族的人脸年龄特征并不完全相同,因此网络提取的年龄特征可能并不完整。本文在Megaage-Asian 数据集上进行了补充实验,以证明MPDNet 的鲁棒性,实验结果如表4 所示。可以看到,MPDNet 在CS(3)和CS(5)指标上分别达到了61.1%和81.2%。由于MegaAge-Asian 数据集来源于网络爬取,人脸背景和光照都存在较大差异,因此对网络特征提取能力要求更高,不同于MORPH Ⅱ数据集上的结果,参数更多的重量级方法显然更具优势。在轻量级方法中,MPDNet 与CEN 和LRN 在精度上同样具有竞争力,并且MPDNet 在参数量上更具优势。同时与重量级方法Posterior 相比,MPDNet 也获得了与之相当的性能,这说明MPDNet 所提取的人脸年龄特征和类间相关信息在不同环境下同样有效。
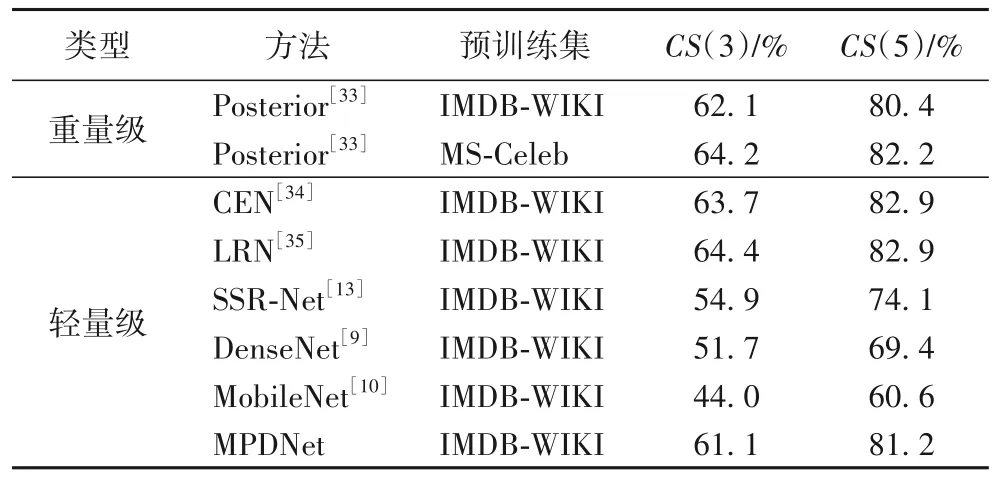
表4 在MegaAge-Asian数据集上的实验结果对比Tab.4 Comparison of experimental results on MegaAge-Asian dataset
4 结语
本文提出了一种用于年龄估计的多任务分布学习方法MPDNet,包含标签分布拟合和回归细化两个过程。所提出的多峰分布年龄编码拟合了年龄标签特有的阶段性和模糊性特征,有助于模拟真实标签的准确分布。同时本文提出的轻量级网络弥补了重量级网络难以在移动端或嵌入式设备上部署的缺陷。在Moprh Ⅱ和Megaage-Asian 上的实验结果验证了MPDNet 的优越性,但该方法仍有改进的空间,例如在处理非受限条件(如背景、姿态、表情等)的人脸图像时精度有所下降,我们未来将对此作一步的研究与讨论。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
数字通信世界(2021年3期)2021-04-09
湖北理工学院学报(2020年4期)2020-08-22
中国生物医学工程学报(2019年6期)2019-07-16
动漫星空(2018年9期)2018-10-26
计算机应用与软件(2017年4期)2017-04-24
自动化学报(2016年3期)2016-08-23
电测与仪表(2016年5期)2016-04-22
发明与创新(2015年33期)2015-02-27
奇闻怪事(2014年5期)2014-05-13
