
基于改进YOLOv5s 的火灾烟雾检测算法研究
2023-05-24 09:06冉光金李良荣
智能计算机与应用 2023年5期
蔡 静,张 讚,冉光金,李 震,李良荣
(贵州大学 大数据与信息工程学院,贵阳 550025)
0 引言
火灾是造成环境问题、人员伤亡和经济损失的重大灾害之一。在国外许多地方,火灾的面积和强度都以惊人的速度增加。这不仅仅是火灾数量在增加,火灾的性质也在发生变化,尤其是在巴西和澳大利亚。例如,“地球之肺”亚马逊雨林发生的大火,已烧毁了总计4920 平方公里的雨林,面积超过50万个足球场,给人类和自然环境带来了难以估量的破坏。因此,为了有效控制和减轻火灾,对火灾的萌发进行预警尤为重要。对于火灾的预警,与火灾火焰相比,烟雾出现时间更早,传播速度更快,体积更大,更易于识别。
传统的烟雾检测主要是基于对纹理、温度、颜色、运动特征和空气透明度的分析[1],最常见的烟雾探测器是基于红外/紫外摄像头。基于此,Deldjoo Y 等人[2]使用稳健的烟雾特征评估方法区分烟雾和非烟雾运动对象,利用模糊推理系统,以模糊化的方式将烟雾特征结合起来进行最终评估,并决定何时发出火灾警报。J Qian 等人[3]利用延时参数改进高斯混合模型提取候选烟雾区域,通过烟雾的面积变化率和运动方式等运动特征,从候选区域中选择烟雾区域。Yuan F 等人[4]利用Gabor 网络对烟雾图像进行识别以及对其纹理信息进行分类。殷梦霞等人[5]利用烟雾图像块的HSV(Hue、Saturation、Value)颜色特征、能量特征等物理特征,提出了基于多特征融合的自适应烟雾检测算法。刘长春等人[6]根据可见光视频图像处理原理,以及烟雾块的纹理特征、HSV 颜色空间等物理特征,提出了一种基于局部区域图像动态特征的林火视频烟雾检测方法。王伟刚等人[7]提出一种TDFF(Triple Multi Feature Local Binary Patterns and Derivative Gabor Feature Fusion)的烟雾检测算法,采用T-MFLBP(Triple Multi-Feature Local Binary Patterns)算法获得烟雾的纹理特征,利用高斯核函数进一步优化图像边缘灰度信息,最后对融合后的特征进行训练,对烟雾区域进行识别。
但是,当背景复杂以及影响因数较多时,传统的检测算法会受到限制。由于烟雾为非刚性物体,其形状、颜色和纹理等物理特征容易随时间变化,导致无法提取烟雾的最本质特征[8],且传统的烟雾检测传感器大多用于室内,难以在森林和草原等户外场景中发挥有效作用,有时也会有较高的错检率以及误警率[9]。
得益于各种人工智能领域的进步,图像处理和计算机视觉等基于视觉的研究领域已经取得了一定的成果,基于计算机视觉的火灾烟雾检测模型也通过这些技术得到了改进。与传统的检测模型相比,基于计算机视觉的火灾检测模型在成本、准确性、鲁棒性和可靠性等方面都具有许多优势。Zhang[10]和张倩[11]等人利用Faster R-CNN 对烟雾图像进行识别检测。Lee Y 等人[12]利用三帧差分算法和均方误差获得输入帧图像,通过Faster R-CNN 提取火焰和烟雾候选区域,最后利用局部HSV 和RGB 颜色直方图,确定最终的火灾和烟雾区域。谢书翰等人[13]通过改进YOLOv4 模型对火灾烟雾图片进行了检测识别。Saponara S 等人[14]提出了一个非常轻量级的神经网络FireNet,开发了一个物联网(IoT)火灾探测单元取代当前基于物理传感器的火灾探测器,在Raspberry Pi 3B 等嵌入式设备上进行训练;联合物联网功能允许探测单元在发生火灾紧急情况时,向用户提供实时视觉反馈和火灾警报。刘丽娟等人[15]通过改进SSD 算法对火灾烟雾图像进行识别。叶寒雨等人[16]将光流估计与YOLOv4 算法结合,提出了SmokeNet 算法对烟雾进行检测。
基于计算机视觉的检测算法虽然在精度和速度上都有所提高,但是当背景复杂、检测目标距离较远时,仍然存在漏检以及错检等问题。针对以上问题,本文提出一种基于改进的YOLOv5s 的火灾烟雾检测算法,在 YOLOv5s 的 骨干网上引 入 Vision Transformer 模块,增强其特征提取能力;使用Ghost Block 卷积代替常规卷积,减少模型参数和计算量。实验结果表明,该算法的检测性能均提高且模型参数显著减少。
1 相关工作
根据型号的大小,YOLOv5 分为YOLOv5s、YOLOv5m、YOLOv5l 和YOLOv5x 4 个版本。模型越大,单个图像的精度越高,检测时间越长。由于4 种版本只是在其模型宽度和深度的不同,且对于火灾烟雾检测而言,不仅对检测精度有极高的要求,对检测速度也要求实现实时检测,所以选用YOLOv5s 作为本文的基本检测模型。YOLOv5s 在数据输入端使用了Mosaic 数据增强[17]、自适应锚计算和自适应图像缩放等技术,来提高对小目标的检测。主干使用了跨阶段局部网络(CSP)[18]结构,提取输入图像特征,头部主要解决从主干提取特征映射的定位问题,并执行类概率预测。Neck 结构由特征金字塔网络(FPN)[19]和路径聚合网络(PAN)[20]组成,Neck 结构是连接主干和头部的部分,主要是对特征图进行细化和重构。此外YOLOv5s 的Neck 结构中,还借鉴了CSPNet 中设计的CSP2_X 结构,加强网络特征融合的能力[21]。YOLOv5s 的网络结构如图1 所示,YOLOv5s 结构中的组件结构如图2 所示。
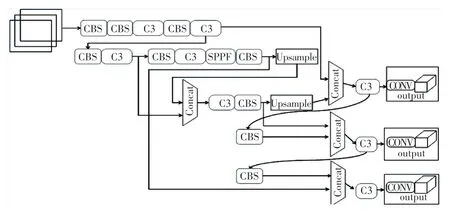
图1 YOLOv5s 结构Fig.1 YOLOv5s structure
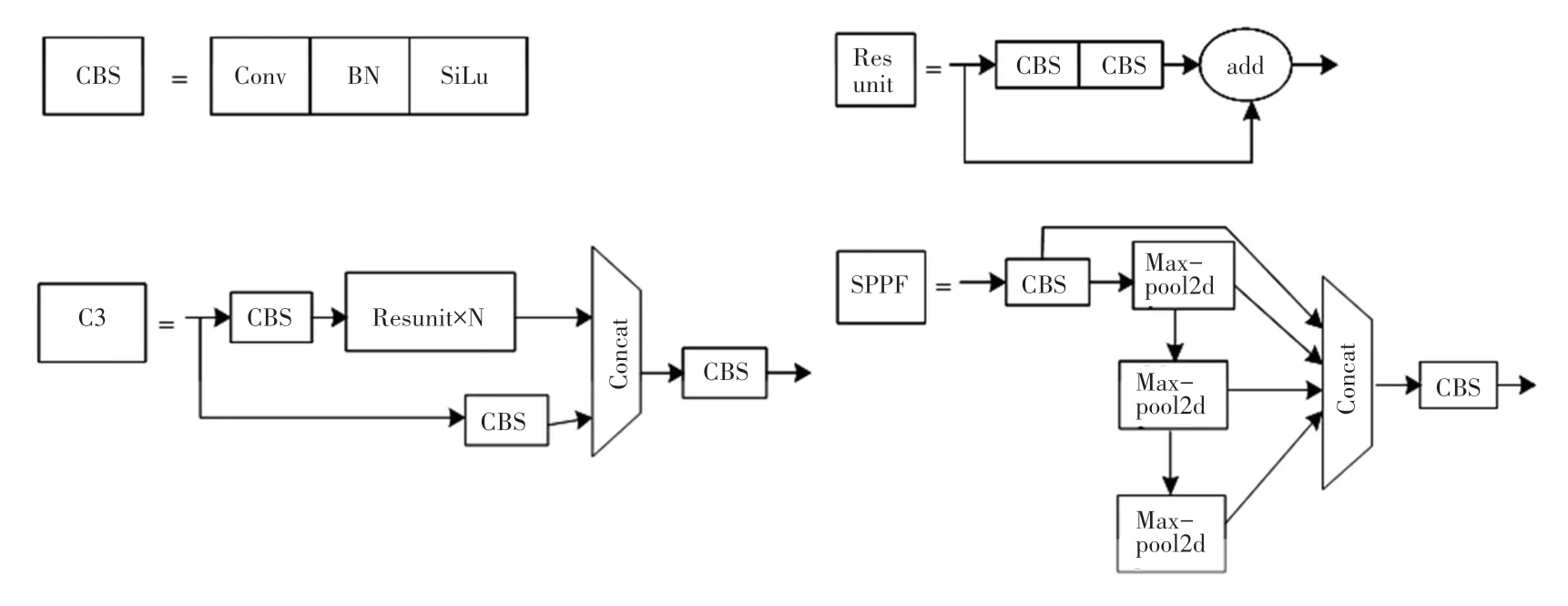
图2 YOLOv5s 组件图Fig.2 YOLOv5s component diagram
2 算法的改进
2.1 Ghost Convolution 模块
在深层网络中常规的特征提取方式会堆叠大量的卷积层,产生丰富的特征图,但是同时需要保存大量参数,占用其有限内存,不利于在嵌入式设备上部署网络模型。本文使用一种Ghost Convolution 模块[22]替换原网络中的常规卷积模块,可以通过较少的参数来提取特征。与常规卷积相比,在不改变输出特征映射大小的情况下,该Ghost Convolution 模块所需的参数和计算量都有所降低,其结构如图3 所示。

图3 Ghost Convolution 模块Fig.3 Ghost Convolution module
Ghost Convolution 模块通过常规卷积生成几个固有的特征映射,然后使用线性运算来扩展特征和增加通道。给定输入数据X∈Rc×h×w,其中c为输入通道数,h、w是X的高度和宽度,任意卷积层生成特征图的操作可表示为
式中:∗表示卷积运算,b表示偏差,Y∈是具有n个通道的输出特征图,f∈Rc×k×k×n是这一层中的卷积滤波器。此外,h'和w'表示输出特征图Y的高度和宽度,k × k表示f的核大小。
使用常规卷积生成m个固有特征图的操作可表示为
其中,f '∈Rc×k×k×m(m≤n)表示所用滤波器,滤波器的大小、填充、步幅等超参数与式(1)中的常规卷积相同。
对y中每个固有的特征图进行线性运算,生成s个Ghost 特征,其计算公式可表示为
由公式(3)得到n =m·s个特征图Y =y11,y12,…,yms作为Ghost 模块的输出数据。
2.2 网络改进
2.2.1 Vision Transformer 模块
在机器视觉领域中,为了改善卷积神经网络(Convolutional Neural Network,CNN)[23]在低层特征依赖关系范围较大时存在的局限性。Dosovitskiy A等人[24]在Transformer 的基础上提出了Vision Transformer。与CNN 网络不同,Vision Transformer在获取全局信息能力上很强大,将 Vision Transformer 与CNN 模型结合,通过自注意力机制改善底层特征提取。Vision Transformer 网络模块结构如图4 所示。

图4 Vision Transformer 模块Fig.4 Vision Transformer module
为了将图片转换为标准的Transformer 编码器,用于处理序列数据,将输入二维图像x∈RH×W×C分割成固定大小的图片xp∈。其中(H,W)是原始图像的分辨率,C表示通道数,(P,P)是每个图片块(patch)的分辨率,N =HW/P表示获得的图片块总数,其也用作变换器的有效输入序列长度;然后线性嵌入每个面片,添加位置嵌入,并将生成的矢量序列提供给标准的Transformer 编码器;再将Transformer 的第一个输出送入MLP Head 得到预测结果。此外,在输入的序列数据之前添加了一个分类标志位(class),可以更好地表示全局信息。
2.2.2 嵌入Coordinate Attention 注意力
在某些情况下,摄像头捕捉到的物体图像较小,而Yolov5s 模型对小目标的检测效果欠佳,此时模型预测易受颜色、亮度等因素的影响。因此,本文引入Coordinate Attention 注意力机制[25],可以有效地提高骨干网络的特征提取能力,进一步提升准确率。
Coordinate Attention 模块可以视为一个计算单元,有效提升网络的表达能力,并且可以充分利用捕获的位置信息,从而准确地定位感兴趣的区域。Coordinate Attention 注意力的实现过程如图5所示。
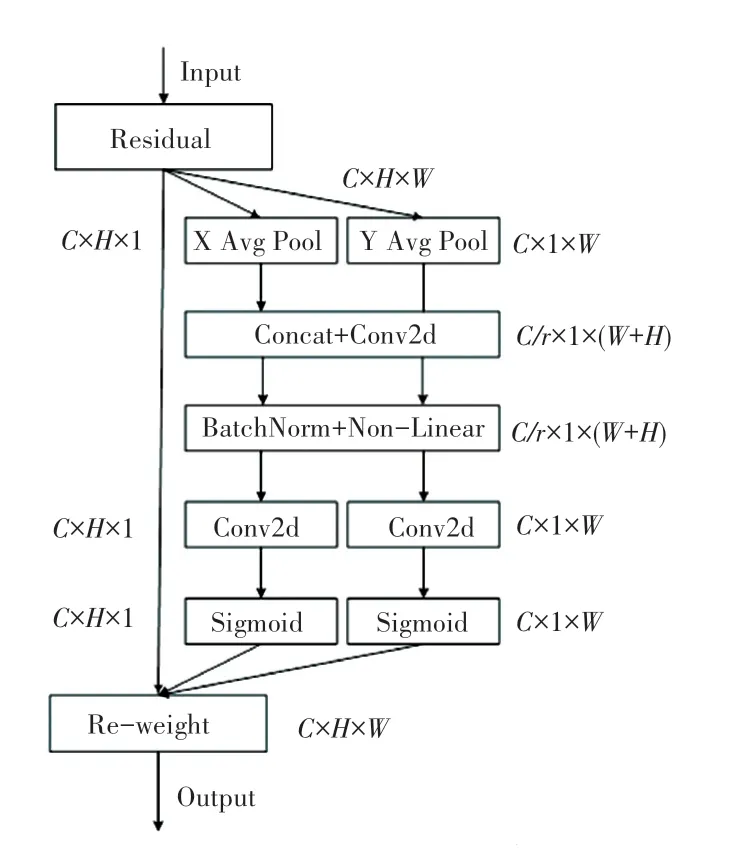
图5 CA 模块结构图Fig.5 CA module structure diagram
Coordinate Attention 注意力为了获取输入图像全局上的注意力,并对每个通道信息进行编码。首先将输入特征图分为宽度和高度两个方向进行全局平均池化,获得在宽度和高度两个方向的特征图。其中,分别逐通道使用两个大小为(H,1)和(W,1)池化核,在高度为h的第c个通道的输出可表示为
通过式(4)、式(5)获得全局感受野并编码精确的位置信息,两种变换分别沿空间两个方向聚合特征,生成一对特征映射张量,这有助于网络更准确地定位感兴趣的对象。
随后将两个方向的特征图进行融合,使用大小为1×1 的卷积模块,把维度降低为原来的C/r,再通过批量归一化处理送入非线性激活函数中获得输出特征图,如式(6):
其中,[·,·]表示沿空间维度的融合操作,F1为1×1 卷积,f∈表示在水平方向和垂直方向上编码空间信息的中间特征图,δ是非线性激活函数,r表示下采样比例。然后沿着空间维度将f分解成两个独立的张量f h∈和f w∈,再使用两个1×1 卷积Fh和Fw将特征图变换为与输入X相同数量的通道。得到结果如式(7)、式(8):
式中:δ为Sigmoid 函数,gh、gw分别用作两个空间上注意力的权重。最后在原始特征图上通过乘法加权计算,将得到在宽度和高度方向上带有注意力权重的特征图,如式(9):
2.3 改进算法结构
本文将改进模块加入到YOLOv5s 模型中,优化结构如图6 所示。
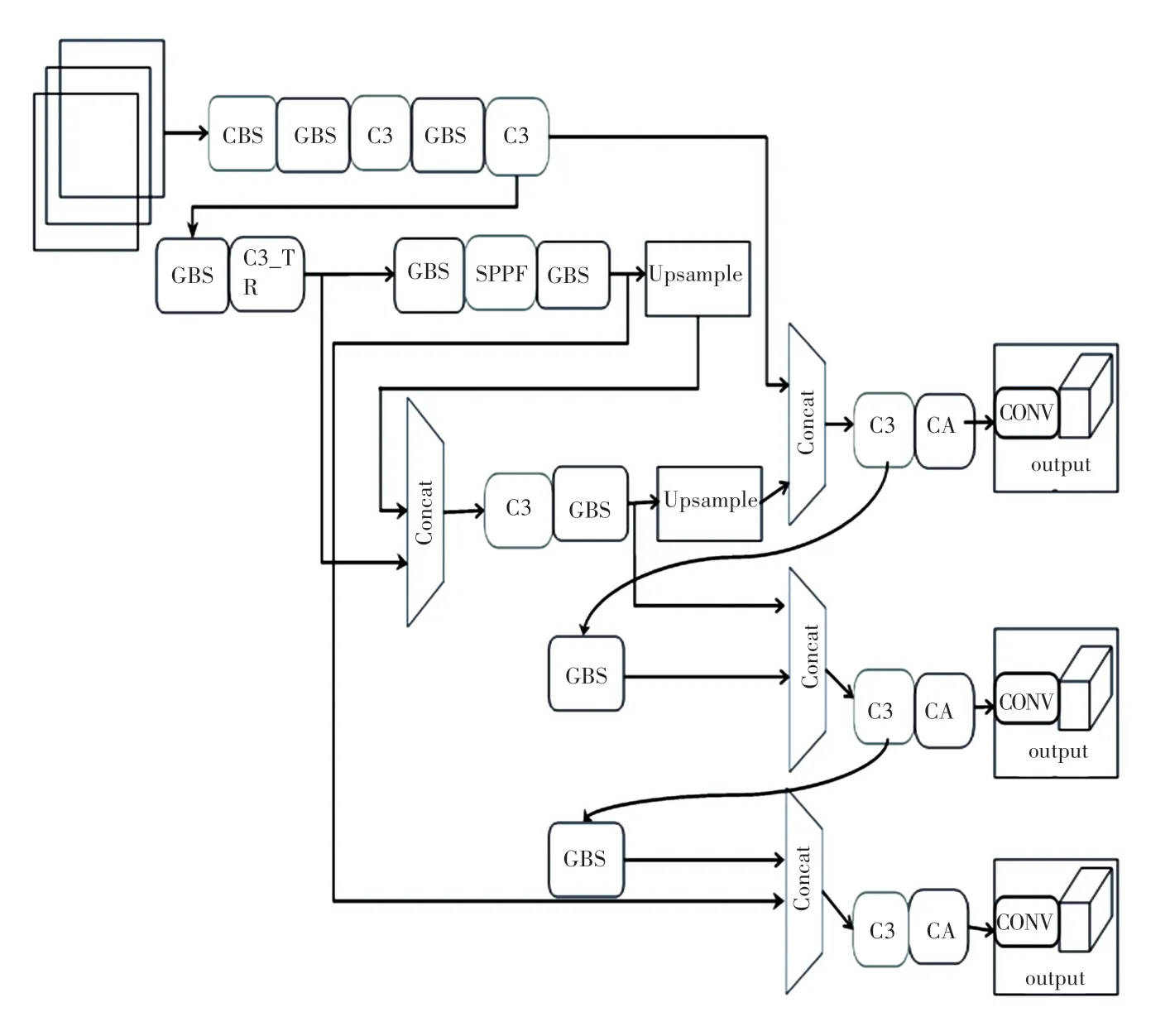
图6 改进后的结构Fig.6 Improved structure diagram
图7 中,GBS 表示使用Ghost Convolution 模块替换原网络中的常规卷积模块的结构图,C3_TR 表示使用Transformer 替换原CSP 结构中的Resunit 模块的结构图。

图7 改进结构图的组件图Fig.7 Component diagram of improved structure diagram
3 实验对比
3.1 实验环境
实验的操作系统为windows7 系统,训练框架为PyTorch1.7.1。CPU 为8 GB RAM 的Intel(R)Core(TM)i7 -6700k @ 4.00 GHz,GPU 为NVIDIA GeForce GTX 970。
3.2 火灾烟雾数据集
由于公开的火灾烟雾数据集较少,通过互联网采集数据,最终经过清洗获得20 114张图片,随机选取18 287张作为训练集,1 827张作为测试集。数据集图像包含建筑、草原、森林、车辆起火4 种场景,并且涵盖白天、黑夜以及其它背景干扰因素。数据集中部分火灾烟雾如图8 所示。

图8 部分数据集Fig.8 Partial Dataset
3.3 评价指标
实验使用召回率(Recall)、精准率(Precision)、平均精度AP(Average Precision)、平均精度均值mAP(mean Average Precision)来评价检测模型准确性。评价指标计算公式如下:
其中,m表示样本类别数;p(r)表示Precision以recall为参数的一个函数;TP(True Positives)是指被正确识别的正样本;TN(True Negatives)为被正确识别的负样本;FP(False Positives)表示负样本被错误识别为正样本;FN(False Negatives)表示正样本被错误识别为负样本。
3.4 实验结果与分析
本文主要从实际检测结果图进行对比分析,检测对比数据见表1,实际检测结果如图9、图10 所示。

图9 YOLOv5s 检测结果Fig.9 Yolov5s test result chart

图10 改进YOLOv5s 检测结果Fig.10 Image of improved YOLOv5s test results

表1 改进前后算法测试结果对比表Tab.1 Comparison of test results before and after the improvement
表1 中,mAP为mAP@0.5 值。通过测试结果可以得出,改进后mAP提高了0.73%,检测速度提高了22.5%,模型参数比原网络参数减少了17%。
通过图9、图10 对比结果可知,改进后的YOLOv5s 模型在不同场景中对烟雾、火焰目标算法都可以有效地解决原YOLOv5s 存在的漏检、错检。
在相同的运算环境下,将深度学习算法YOLOv4-Tiny、传统单阶段算法SSD、原网络YOLOv5s 同本文算法进行比较分析。算法的对比结果见表2。

表2 检测算法测试结果对比表Tab.2 Comparison table of test results of detection algorithm
由表2 可见,在检测精度和检测速度上,YOLOv4-tiny 检测算法相对本文改进的模型有一定的优势,而检测速度的快慢与算法的模型参数量等因素成反比,即模型参数量越小,检测速度则越快。YOLOv4-tiny 是YOLOv4 的轻量化网络架构,极大地减少了模型参数量以及降低了模型的计算量,提高了检测速度,但是该算法的总体性能略低。
通过对比实验可以看出,本文算法总体上优于其它几种算法,该检测算法在实际工程应用中更具优势。
4 结束语
本文提出了一种基于YOLOv5s 的火灾烟雾检测模型,在YOLOv5s 模型的基础上进行优化,并引入注意力机制、Vision Transformer 模块提高检测精度,解决目标漏检和错检等问题;引入Ghost Convolution 模块,减少模型参数,提高火灾烟雾检测算法的性能。与同一环境下的其他检测模型相比,改进后的模型在识别精度和速度上都有良好优势。
但是,本文的召回率还有很大的进步空间,在之后的工作中,在保证准确率的条件下,提升召回率;其次,还应扩充火灾烟雾数据集,丰富火灾烟雾检测场景,增强火灾烟雾图片质量。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
小学阅读指南·低年级版(2021年3期)2021-03-19
华人时刊(2019年13期)2019-11-26
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
当代陕西(2017年12期)2018-01-19
文理导航·趣味课堂(2016年6期)2016-09-09
科学启蒙(2014年12期)2014-12-09
电视技术(2014年19期)2014-03-11
故事作文·高年级(2009年7期)2009-08-20
