
改进YOLOv3的多尺度高分辨率特征增强图像目标检测
2023-05-23 14:46杨文姬王映龙
小型微型计算机系统 2023年6期
杨文姬,李 浩,2,王映龙,梅 梦
1(江西农业大学 软件学院,南昌 330045)
2(江西农业大学 农业信息技术重点实验室,南昌 330045)
3(江西农业大学 计算机与信息工程学院,南昌 330045)
4(江西省商务学校,南昌 330100)
1 引 言
目标检测[1-5]是计算机视觉中最重要的研究内容之一,也是实例分割,目标跟踪及行为分析的重要基石.随着深度学习的飞速发展,模型的特征提取能力和学习能力显著增强,目标检测算法的精度和效率大幅提升.近年来,目标检测现已广泛运用于各个领域,包括无人驾驶[6]、行人检测[7]、生物识别[8]和智能安防等方面.
目标检测的目的就是检测图像或视频中是否存在物品并把物品的位置和类别标记在图片中.目标检测在实际场景中容易存在严重的遮挡问题.其次,同一类物品在形状上也会存在差异,同一物品在不同的图片中相对大小也不一致,增大类内差异性,存在多尺度的问题.因此,物品遮挡严重和尺度不一成为图像目标检测的难点.
针对以上难点,本文在一阶段目标检测网络YOLOv3的基础上进行一系列改进,提出一种高分辨率多尺度特征融合的目标检测网络.在backbone和neck之间添加空间金字塔池化结构(SPP)模块,将语义信息丰富的高层特征与位置信息丰富的底层特征相融合,提高了尺度不一物品的检测率,在预测阶段添加一个分辨率更高位置信息更加丰富的预测层,提高小目标物品的识别精度,将损失函数改为CIoU,提高目标检测框回归的效率,降低目标漏检率.
2 相关工作
2.1 基于机器学习的目标检测算法的发展
近年来,计算机视觉和深度学习的快速发展,目标检测也成为研究热点之一.传统的目标检测算法分为3个阶段,首先通过滑动窗口在图片中选出候选区域,然后根据人工经验进行手工特征提取,最后利用分类器进行分类.传统目标检测算法存在提取特征浅,鲁棒性差,实时性无法保证的问题.然而深度学习网络层数较深,能够提取更加丰富的不同层次的特征,从而有利于目标物品的准确检测.
基于卷积神经网络的目标检测算法主要分为一阶段(one-stage)算法和二阶段(two-stage)算法:一阶段目标检测算法主要包括:SSD,DSSD,YOLOv1,YOLOv2,YOLOv3,RetinaNet,FCOS算法等;二阶段目标检测算法主要包括:R-CNN,SPP-Net,Fast R-CNN,Faster R-CNN和Mask RCNN算法等.2013年,Girshick等人提出了R-CNN算法[9],利用选择性搜索算法提取2000个类别独立的候选区域,再将这些候选区域送入CNN抽取固定长度的特征向量,最后利用支持向量机(SVM)进行目标分类,取代了传统目标检测滑动窗口和手工特征提取的过程,对目标检测算法具有重大意义.随后,SPP-Net算法发布[10],提出了空间金字塔池化(spatial pyramid pooling)的策略,突破了传统卷积神经网络对输入图像尺寸的限制.2015年,Fast R-CNN 和Faster R-CNN算法提出[11,12],引入多任务损失函数和提出候选区域网络(RPN),提高了特征提取的效率,降低了时间和空间成本,如图1所示.二阶段(two-stage)目标检测算法分为利用目标候选网络来提取候选区域和利用检测网络完成候选区域目标的定位和分类,所以这类算法进行目标检测任务时平均识别率较高但实时性较差.
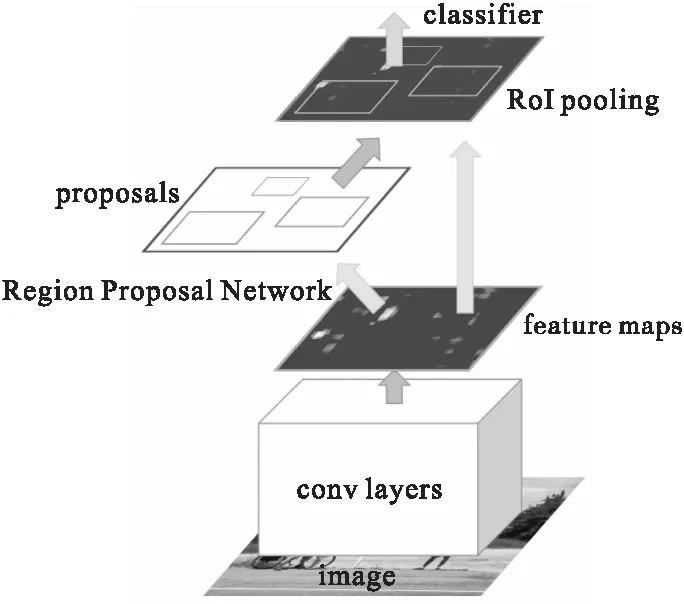
图1 Faster R-CNN网络结构
2016年,Redmon 等人提出了YOLOv1算法[13],跳过提取候选区域的步骤,直接通过回归运算得出预测目标框和类别,提高了算法的检测速度.YOLOv2提出了新的特征提取器Darknet-19[14],增强了特征提取的效果且计算量却减少约33%.同年,Liu W等人提出了SSD算法[15],在网络中融入了Faster R-CNN中的anchors思想,并且做了特征分层提取并依次进行边框回归和分类操作,由此可以适应多种尺度目标的训练和检测任务,但是在小目标的识别效果上还是不理想.2018年,Facebook AI团队发布了RetinaNet算法[16],主要贡献为提出一个新的损失函数,在解决类别不均衡问题上比之前的方法更有效,在COCO数据集上识别精度媲美MASK R-CNN,如图2所示.Redmon等人提出了YOLOv3算法[17],其主干网络换成网络深度更深的Darknet-53且添加了类特征金字塔(Feature Pyramid Network)模块将位置信息丰富的浅层特征图和语义信息丰富的深层特征图融合得到3个不同尺度的特征图,并在这些特征图上独立预测目标框和类别,在COCO数据集上mAP高达57.9%.
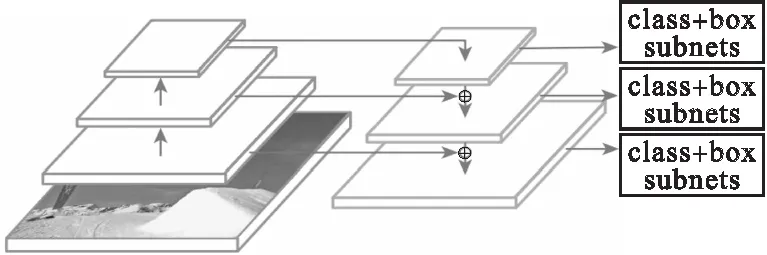
图2 RetinaNet网络结构
2.2 基于深度学习的小目标检测算法的发展
小目标检测[18-22]是计算机视觉的难点之一,其目的在于检测出图像中特征极少的小目标.随着深度学习的发展,小目标检测在自动驾驶、缺陷检测、军事智能感知和遥感图像分析等领域发挥着重要作用.小目标的定义有两种,一种是相对尺寸大小,如目标尺寸的长宽是原图像尺寸的0.1,即可认为是小目标,另外一种是绝对尺寸的定义,即尺寸小于32×32像素的目标即可认为是小目标.Tsung-Yi Lin等[23]首次采用了多尺度特征融合的方式,将低层位置信息丰富的特征层和高层语义信息丰富的特征层进行融合之后的结果来做预测,小目标检测效果提升明显.Z Cai等[24]提出多阶段网络Cascade R-CNN,在检测头不断提高IoU的阈值同时保证了样本的数量和质量,小目标识别精度提高了8.1%.W Liu等[25]在SSD网络基础上提出渐进定位拟合模块调整阈值来提高网络性能,行人目标检测精度提高了5.5%.Deng等[26]针对不同尺度的特征耦合会影响小目标检测性能的问题提出了扩展特征金字塔网络,小目标检测性能有效提高.在国内,潘昕晖等[27]在YOLOv3网络的基础上添加非对称卷积并修改激活函数为Swish,在COCO数据集的小目标检测中提升了6.9%,但该算法精度还有待提高.程凯强等[28]通过在SSD模型的特征后添加通道和空间自适应权重网络提取更加重要的特征信息,在VOC2007数据集上比原模型提高了31.3%,但仍存在目标重复检测的问题.王芳等[29]提出了一种可以提高特征图不同通道相关性的特征融合模块用于红外小目标检测,平均精度高达87.8%.王胜科等[30]在CenterNet网络的基础上引入可变行双重注意力机制和LogoNet卷积单元,在专业的无人机检测数据集上检测精度提高了10%,但该网络仅限于特定的无人机检测任务中.
综上所述,图像物品检测存在背景复杂,遮挡严重,尺度大小不一的问题,本文基于YOLOv3进行改进,在backbone和neck之间添加空间金字塔池化结构(Spatial Pyramid Pooling),三尺度检测层增加为四尺度检测层,将YOLOv3损失函数改为CIoU,提出了一种多尺度高分辨率的特征融合网络YOLOv3-F用于图像目标检测.
3 YOLOv3算法
3.1 基本结构
YOLOv3是典型的一阶段目标检测网络,由特征提取网络Darknet-53,类特征金字塔(Feature Pyramid Network)和独立的3个不同尺度的预测层3部分构成.Darknet-53采用全卷积结构,共有53个卷积层,其网络结构如图3所示.其借鉴ResNet的残差模块思想,减小了梯度爆炸的风险,加强了网络的学习能力.该网络的backbone由5个残差模块组成,每个残差模块由两个卷积批归一化激活层CBL和一个快捷链路组成.卷积批归一化激活层CBL则由卷积层、批归一化层及Leaky ReLU层组成.
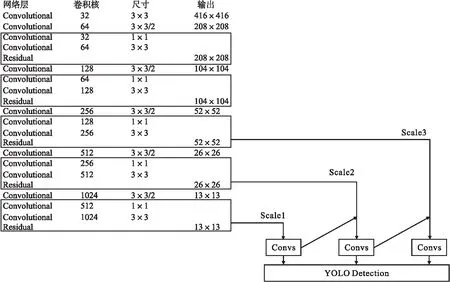
图3 YOLOv3网络结构
3.2 损失函数
YOLOv3的损失函数由目标定位损失Lossa、置信度损失Lossb和目标类别Lossc3部分组成,如式(1)所示:
Loss=Lossa+Lossb+Lossc
(1)
目标定位损失Lossa的目标函数为均方误差(MSE),如式(2)所示:
(2)
式中chance表示预测框中包含目标的概率,x,y,w,h依次为目标预测区域中心点横坐标,纵坐标,以及区域的宽和高的值.i表示第i个预测框,n表示预测框的总个数,d表示对应预测层的个数,p表示预测框的下标,t表示目标预测框的下标.
4 YOLOv3-F算法
由于成像角度不同,导致同一物品成像大小不一且存在遮挡问题.不同物品例如打火机和压力喷罐成像大小差异大,造成成像尺度大小不一的问题.为解决以上问题,本文在YOLOv3的基础上添加了空间金字塔池化结构(Spatial Pyramid Pooling),添加了新的预测层以及修改目标定位损失函数为CIoU,构建了有利于小目标物品检测的目标检测网络YOLOv3-F,如图4所示.
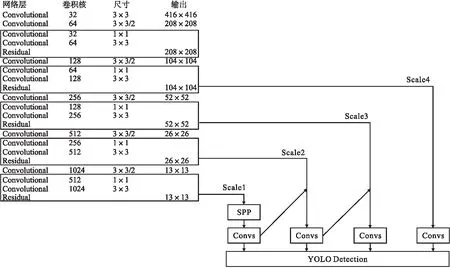
图4 YOLOv3-F网络结构
4.1 网络结构的改进
YOLOv3-F的主干网络Darknet-53以416×416大小的图片作为输入,经过CBL模块5次下采样后,特征图的大小变为原来的一半,依次变为208×208、104×104、52×52、26×26、13×13.将backbone第5次下采样的大小为13×13特征图输入检测大目标的YOLOv3-F-1层;将 YOLOv3-F 网络中第1个尺度的大小为13×13特征图实现上采样,然后与 backbone中第4 次下采样特征图融合,将其输入检测中目标的大小为26×26的YOLOv3-F-2层;将 YOLOv3-F 网络中第2个尺度的大小为26×26特征融合图实现上采样,然后与 backbone中第3 次下采样特征图融合,将其输入检测小目标的大小52×52为YOLOv3-F-3层;将 YOLOv3-F 网络中第3个尺度的大小为26×26特征融合图实现上采样,然后与 backbone中第2次下采样特征图融合,将其输入检测较小目标的大小104×104为YOLOv3-F-4层.浅层的特征图包含丰富定位信息,深层的特征图包含丰富的语义信息.
在backbone和neck之间添加空间金字塔池化结构(Spatial Pyramid Pooling).SPP 模块由4个并行的分支构成,分别是kernel size为 5×5,9×9,13×13的最大池化和一个跳跃连接.如图5所示,在检测层前面的第5和第6卷积层之间集成SPP模块来获得YOLOv3-SPP,在特征图经过SPP 模块池化后的特征图重concat起来传到下一层预测层中.该模块借鉴了空间金字塔的思想,通过SPP模块实现了局部特征和全局特征的融合,这也是SPP模块中最大的池化核大小要尽可能的接近或者等于需要池化的特征图的大小的原因,特征图经过局部特征与全局特征相融合后,丰富了特征图的表达能力,有利于待检测图像中目标大小差异较大的情况,尤其是对于这种复杂的多目标检测,所以对检测的精度上有了很大的提升.
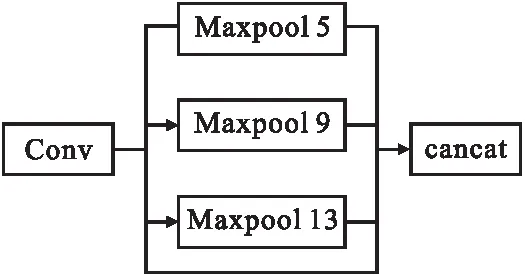
图5 空间金字塔池化结构
4.2 损失函数的改进
原始YOLOv3所用定位回归损失函数为MSE,但MSE损失函数对尺度比较敏感.它反映了目标预测框predict box和目标真实边框GT box之间的距离,即使距离相近的两个框,其IoU值可能会差别很大,因此它不适合用于YOLOv3预测边界框的回归.
针对以上问题,Hamid等提出了GIoU边界框回归损失函数[31],其具有尺度不变性,解决了检测框和真实框没有 重叠的问题,如式(3)所示:
(3)
上式中IoU是指目标预测框predict box和目标真实边框GT box的交并比,C是指能包含目标预测框predict box和目标真实边框GT box的最小矩形框,B是指目标预测框predict box的面积,Bgt是指目标真实边框GT box的面积.但是当检测框和真实框之间出现包含的现象的时候GIoU损失函数就和IoU损失函数是同样的效果.
CIoU损失函数要比GIoU损失函数更加符合目标框回归的机制[32],将目标与anchor之间的距离,重叠率以及尺度都考虑进去,使得目标框回归变得更加稳定,边界框回归的效率大大提升,如式(4)所示:
(4)
(5)
(6)
上式中IoU是指目标预测框predict box和目标真实边框GT box的交并比,ρ2是指目标预测框predict box和目标真实边框GT box中心点的距离的平方,而c2是指刚好能包含目标预测框predict box和目标真实边框GT box的最小矩形框的对角线长度平方.如式(4)中第4项所示,αv为惩罚项,v表示宽高比一致性参数,α表示trade-off参数,如式(5)和式(6)所示.CIoU将Bounding box的纵横比考虑进损失函数中,进一步提升了回归精度.综上所述,本文选择CIoU作为YOLOv3边界框回归损失函数.
5 实验结果及分析
5.1 实验环境配置
为验证算法的优越性建立了针对自建物品数据集的对比实验和消融实验,实验软硬件环境配置如表1所示.
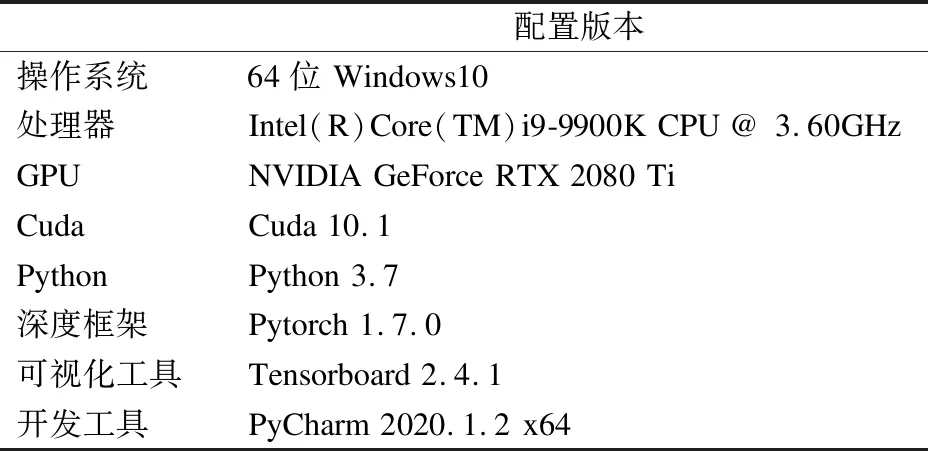
表1 实验软硬件环境配置
5.2 实验数据集
本文所用数据集为自制的COCO-CT6数据集.该数据集共4370张多类别物品图像,分别从围绕Z轴40度、100度、160度、220度、280度、640度、720度7个角度对行李箱进行成像拍摄,其中共包含液体、刀、工具、压力喷罐、打火机以及充电宝6种物品,图片大小均为800×800,图片中各类别物品均存在遮挡的情况,利于模拟真实场景中因搬运而导致的行李箱内物品堆积的情形.最终COCO-CT6数据集按6∶2∶2的比例划分训练集、测试集和验证集.
5.3 模型训练和评价标准
实验使用在Imagenet 上训练好的 Darknet53的参数为模型特征提取网络的初始化参数,YOLOv3-F在网络初始化参数的基础上进行修改;采用随机翻转、随机裁剪、亮度调整等方法对数据集进行数据增强.部分网络超参数如表2所示.
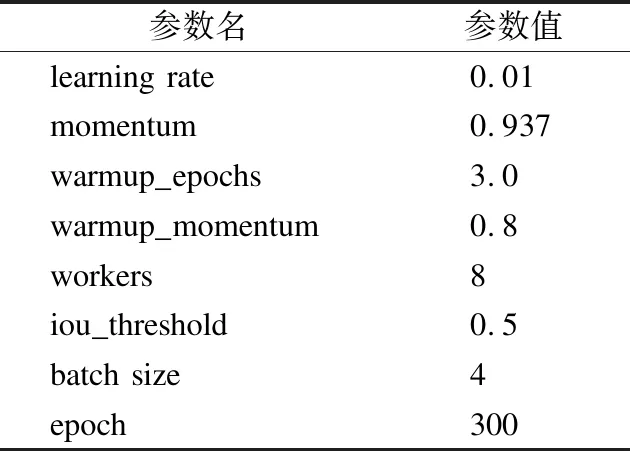
表2 网络超参数表
本文的评价指标为平均检测精度(mAP)、误检率(FPR)、每张图片检测用时(以ms为单位)等.首先需要计算其精确度(precision)和召回率(recall),公式如式(7)和式(8)所示:
(7)
(8)
式中TP为将正样本预测为正样本,FP为将负样本预测为正样本,FN为将正样本预测为负样本,TN为将负样本预测为负样本.将mAP式目标检测算法中最常用且最终要的评价指标,其公式如式(9)所示:
(9)
式中,APL是指每个类别的平均精度值,G(cla)是指所有类别的数目.误检率(FPR)即负样本被预测为正样本占总的负样本的比例,值越小,性能越好,如式(10)所示:
(10)
5.4 实验结果
为了验证GIoU和CIoU定位回归损失函数的有效性,本文将初始YOLOv3网络结构中的MSE损失函数分别换为GIoU和CIoU损失函数,实验结果如表3所示.

表3 不同损失函数实验结果对比表
实验结果表明,采用GIoU作为定位回归损失函数相比MSE,误检率降低了0.9%,mAP提高了2%,用IoU作为边界框损失衡量标准提高了检测的精度.采用CIoU作为定位回归损失函数相比GIoU,误检率降低了1.3%,mAP提高了0.4%,将边界预测框和目标真值框的中心点距离和纵横比考虑到损失函数中,进一步提高了物品识别的精度,降低了物品误检的概率.3组损失函数每张图片检测用时均符合实际应用场景.
表4和表5分别表示在原始YOLOv3网络结构上添加SPP模块和高分辨率检测层模块后,误检率都有小幅度下降,mAP都有小幅度增长,证明了这两个模块的有效性.

表4 添加SPP模块前后实验对比表
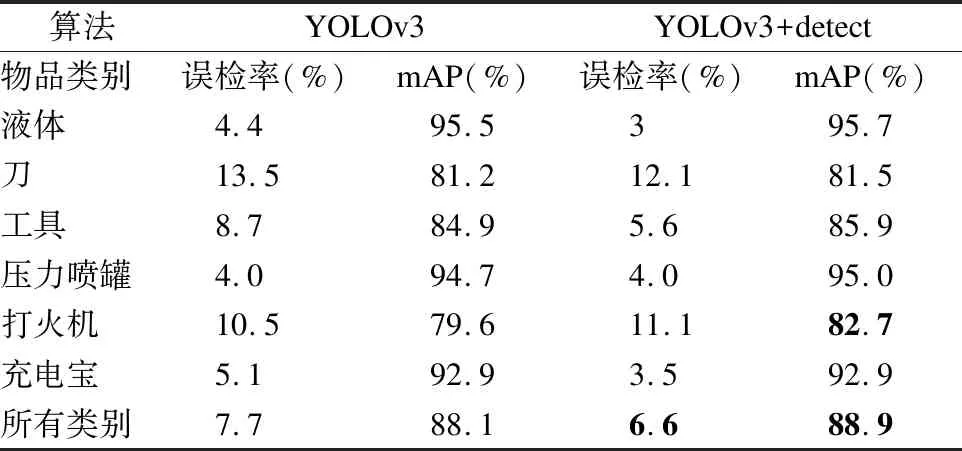
表5 添加高分辨率检测层模块前后实验对比表
本节以YOLOv3网络为基础模型进行消融实验,添加不同模块后对其模型检测效果的影响进行对比.由表6可以看出添加SPP模块后,误检率降低0.4%,mAP提高0.3%,检测用时增加0.2ms.添加SPP模块和高分辨率检测层模块后,误检率降低1.2%,mAP提高3%,检测用时增加0.4 ms.添加SPP模块和高分辨率检测层模块且定位损失函数改为CIoU后,误检率降低1.8%,mAP提高3.6%,检测用时增加1.3ms,训练用时增加了0.6个小时.实验结果进一步证明了在合理的时间范围内,本文设计的模块有利于物品检测性能的提升.
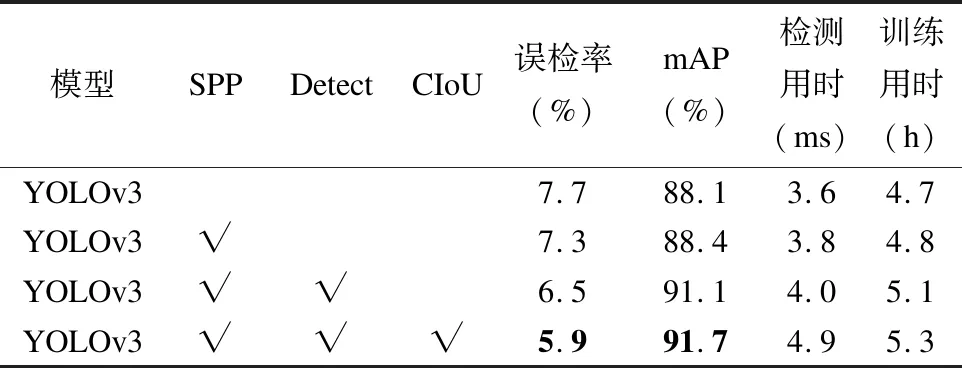
表6 在数据集COCO-CT6上对YOLOv3-F进行消融实验
为了更好地评估YOLOv3-F模型,将其与其他模型进行性能对比,结果如表7所示.

表7 不同算法的测试结果对比表
由表7可知,和Faster R-CNN、SSD、YOLOv3算法相比,本文提出的YOLOv3-F算法误检率最低,mAP最高.虽然时间成本有所增加,但仍然满足智能目标检测中对时间的要求.
6 结束语
本文提出一种基于YOLOv3进行改进的多尺度高分辨率特征增强目标检测的算法YOLOv3-F.在主干网络之后添加空间金字塔池化结构,实现了局部特征和全局特征的融合,丰富了特征图的表达能力,有利于待检测图像中物品目标大小差异较大的情况,提升网络检测精度.同时将第3个尺度的特征融合图上采样的特征图与主干网络第2次下采样的特征图进行融合,形成第4个位置信息丰富的预测层,有利于打火机等小目标物品的检测.最后,将定位回归函数由MSE改为CIoU,提高了定位能力.实验结果表明,新算法可以在目标检测任务中有效降低漏检率和提高识别精度,且有利于小目标物品的检测.尽管本文算法有很多优点,但仍存在检测速度略微下降的问题,下一阶段的工作就是在不降低识别精度的情况下,简化网络结构,降低参数量和运算量.
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
数学小灵通·3-4年级(2021年5期)2021-07-16
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
今日农业(2019年15期)2019-01-03
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
太空探索(2016年5期)2016-07-12
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
