
利用多语言线索进行事件检测的混合注意力网络
2023-05-23 14:45黄培馨冉旭东肖卫东
小型微型计算机系统 2023年6期
黄培馨,赵 翔,方 阳,冉旭东,谭 真,肖卫东
1(国防科技大学 信息系统工程重点实验室,长沙 410073)
2(国防科技大学 大数据与决策实验室,长沙 410073)
3(西北核技术研究所,西安 710024)
1 引 言
随着网络大数据的迅猛发展,信息检索和信息抽取等领域大放异彩.事件抽取作为NLP(Natural Language Processing)领域经典的信息抽取任务,在商业、军事等领域的新闻、情报工作中应用非常广泛[1,2].事件抽取要求用自动的方法,从半结构化、非结构化数据中,将与目标相关的事件以及事件的重要元素识别出来.事件检测,作为事件抽取的关键步骤,直接影响到事件以及事件相关要素的抽取.
事件检测任务的目的是从纯文本中识别出具有特定类型的事件实例.给定输入文本,事件检测任务需要确定这个文本中包含的触发词以及触发词所描述的事件类型.事件的触发词(即event trigger),指在一个事件指称中最能指示事件发生的词,是决定事件类别的重要特征.事件检测包含事件触发词识别和事件触发词分类两个子任务.事件检测不仅需要从文本中正确地检测事件以保证任务的精确率,而且要求尽可能全面地检测出文本中的全部事件以保证任务的召回率.
尽管当前事件检测的研究已经取得了比较大的进展,但是仍然存在两个问题会严重限制当前方法的性能:一是数据稀疏导致的低召回率问题.在训练数据有限的情况下,事件类型呈现长尾分布,有些事件类型的训练样例出现频率极低,从这些训练样例中学习出来的模型,要从某一事件类型的不同表达形式中识别出低频事件类型是具有挑战性的;二是自然语言的歧义性导致的低精确率.自然语言中存在着多义现象,很多事件触发词也是多义词.模型从具有多种含义的触发词中辨别出符合上下文语境的正确含义也是十分困难的.鉴于此,本研究寻求利用来自多语言的丰富信息用于事件检测.在考虑利用多种语言的信息进行事件检测之前,需要思考:是否利用多种语言信息有助于事件检测.首先就一个例子进行讨论.图1展示了语料库中一条英文的输入文本,以及翻译得到的目标语言分别为西班牙语和中文的文本.其中,源语言文本的触发词为“took out”.然而,“took out′”具有多种含义,如“get rid of”,“invite(sb.)out”或者“vent”,这种歧义会干扰模型正确确定文本的事件类型.若有西班牙语文本(即target language 1)作为补充,源文本事件类型的范围能够被缩小.这是因为对应的触发词“acabaron”在西班牙语中具有的含义有“dismantle(the old buildings,etc.)”或者“finish(the work,etc.)”.然而,这仍然不足以确定事件类型.通过额外的中文文本(即target language 2)的补充,事件类型才能够被确定为Execute.因为对应的触发词 “Chaichu”在中文中具有确切的含义“tear down(a building,etc.)”.

图1 利用多种目标语言文本的实例
由此看出,一个文本在不同语言中的表达是具有相似的语义成分和语义结构的.利用额外的语言信息能够缓解数据稀疏.另外,不同语言通常有不同的语法特征,一种语言中的歧义词在其他语言中可能是无歧义的,尤其是对于不同语族的语言.利用多语言文本,用于训练事件分类器的监督信号更容易捕获.
因此本研究提出在事件检测任务上充分利用多种语言提供的线索.具体地,提出混合注意力网络模型(Hybrid Attention Network,HAN),上下文注意力模块首先分别关注每种语言文本中的重要词(如触发词或者对识别触发词有益的词),并给予它们较高的注意力;接着多语言注意力模块进行跨语言的注意力计算,使得不同语言中的无歧义信息能够以监督的方式传递至源文本,缓解源文本的歧义.在两个基准数据集上进行充分的实验证实了:1)额外的目标语言提升了HAN模型的性能;2)相比于现有的最优的模型,HAN在诸多性能指标上取得了最优的结果.
简言之,本研究的主要贡献是在事件检测任务上充分利用多语言线索,并设计了混合注意力网络模型HAN,以充分捕获多语言的上下文信息和多语言之间的互补信息,利用这些信息来缓解事件检测任务上的数据稀疏和自然语言歧义问题.
2 研究现状
基于特征工程的事件检测最初的事件检测工作基于特征工程,通常由人工设计一系列特征,如词汇特征和WordNet特征用于事件识别.接着,一些语义更加丰富的特征,如跨事件特征(Cross-Event)[3]被用于在整个文档层提升事件检测性能.一些工作利用全局特征进行触发词和事件论元的联合检测(MaxEnt)[4],或者采用概率软逻辑机制来同时利用局部和全局特征(PSL)[5].为了克服数据稀疏问题,有工作利用事件要素的特征来学习事件要素与事件触发词之间的相互关系,用于事件检测[6].尽管复杂的特征工程能够取得较好的事件检测效果,但是这些模型往往依赖人工特征设计,耗时费力、成本比较高,并且均没有利用多语言的特征去进一步提高模型的效果.
基于神经网络的事件检测随着神经网络的发展,许多研究用神经网络模型自动抽取文本中的潜在特征,避免了复杂的特征设计.DMCNN模型引入卷积神经网络(Convolutional Neural Networks,CNN)来学习用于事件分类的隐藏特征表示[7].在DMCNN模型的基础上,Skip-CNN通过建模非连续的skip-grams来进行事件检测,取得了更好的效果[8].之后,JRNN结合了循环神经网络(Recurrent Neural Networks,RNN)和特征工程来自动抽取有效的特征[9].然而,数据稀疏问题仍然会限制这些模型效果进一步的提升.
基于远程监督的事件检测为了缓解训练数据稀疏的问题,一些研究使用外部数据资源例如Freebase、Frame-Net和 WordNet作为监督数据进行监督学习.DMCNN+FB利用来自FreeBase的大量知识来自动标注数据用于模型训练[10].DMBERT+Boot通过对抗训练自动构建多样的训练数据用于远程监督的事件检测[11].PLMEE使用预训练的语言模型来做事件抽取,效果超越了目前大部分的事件抽取方法[12].CLEVE利用来自大规模无监督数据的信息,进行预训练来学习事件知识[13].OntoED使用的额外的本体知识,学习本体表示用于事件检测[14].
多语言方法多语言线索被用在过如情感分析[15]和命名实体识别[16]等任务中,并且被证实有价值.为了应对数据稀疏的问题,Cross-Lingual利用双语对照语料库将低置信度的谓词替换为高置信度的事件触发词[17].LEX+TARNS通过人工设计字符特征等基本特征来利用多语言信息[18].不同于上面两种方法通过复杂的特征工程来利用语言资源,GMLATT使用神经网络模型来捕获来自一种额外语言的信息作为补充[19].不限于融合一种语言,本文提出了一种神经网络模型,通过混合注意力机制和改进的预测机制来充分利用多种语言的信息,并且在实验中用多种语言来评估模型效果;不同于LEX+TARNS受限于只能在字符特征层面使用来自多种语言的离散特征,本文使用HAN模型来自动地从多语言的整个文本中学习特征,实现了多语言的充分利用.
3 HAN模型
模型结构如图2所示.HAN模型首先在多语言表示层获取多种目标语言文本,进行文本的对齐,并将多语言文本转化为句子序列的向量表示;然后在混合注意力层对多语言文本并行进行上下文注意力的学习,后通过多语言注意力机制进行跨多种语言的信息融合;接着,在分类层进行事件类型的预测分类;最后介绍模型的训练方法.下面将对这些部分进行详细介绍.
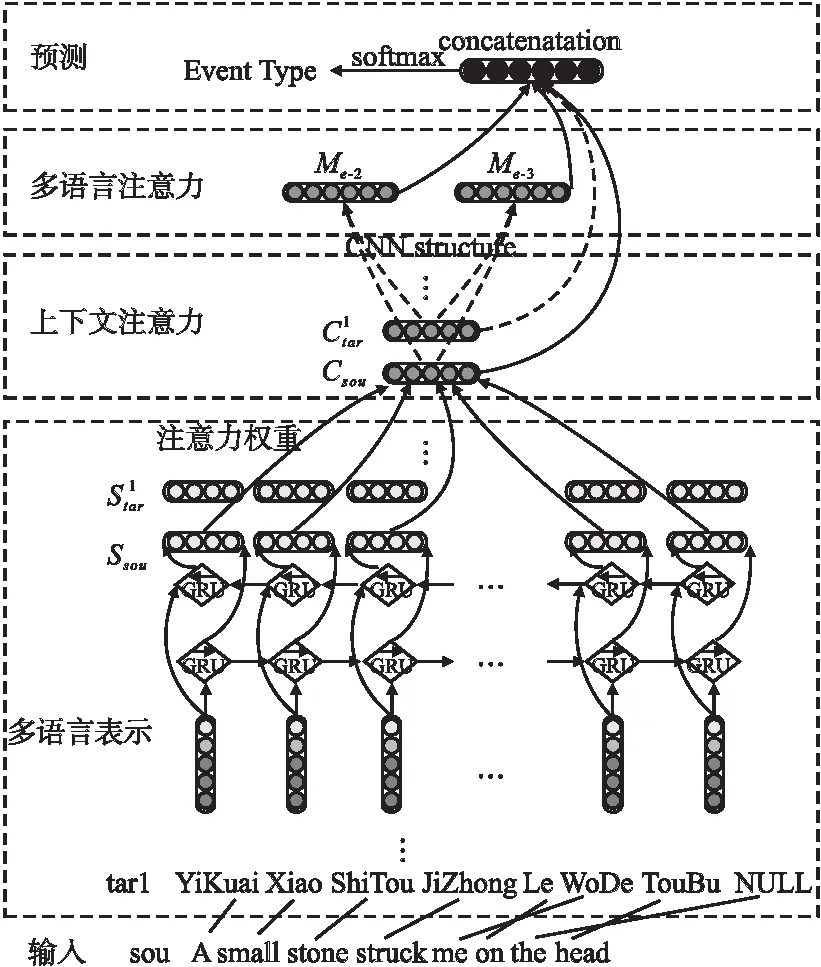
图2 混合注意力网络模型框架
3.1 多语言表示层
由于模型的输入是单一语言文本,首先用翻译工具(https://translate.google.com/)来处理每一条输入文本,获得多语言的目标文本.然后,用Giza++(http://www.fjoch.com/GIZA++.html)来对齐多语言文本.由于文本的对齐是单向的(从源语言对齐到目标语言或从目标语言对齐至源语言),因此Giza++组合对齐结果.
接着进行句子表示,将每个输入分词wi转化为一个实值向量xi,这个向量是3种特征表示的联结:1)词向量:词向量能够捕获文本中单词的语义信息,通常被用作各种任务的基本向量.本文使用典型的Skip-Gram模型预训练词向量;2)实体类型向量:使用标注好的实体信息作为额外特征,随机初始化每个实体类型的向量并且在训练过程中不断更新,不同语言共享实体向量表;3)位置向量:位置向量表示了上下文分词wn(即输入分词wi的上下文词)和输入分词wi之间的相对距离i-n,它通过查找一个随机初始化的位置向量表获得.由此,输入文本被转化为一个向量序列X=(x1,x2,…,xn),其中,每一个向量都是上述3种特征向量的联结.
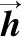
3.2 混合注意力层
上下文注意力机制上下文注意力的目的是生成上下文向量,挖掘多语言上下文的一致信息,以缓解数据稀疏问题.上下文注意力会在每种语言上分别进行,这里只阐述在源语言文本上的操作.
(1)
(2)
(3)
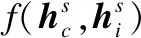
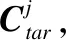
多语言注意力机制多语言注意力用于捕获多种目标语言之间的互补线索,并且控制从多种目标语言文本到源语言文本的信息传递.
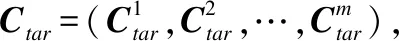
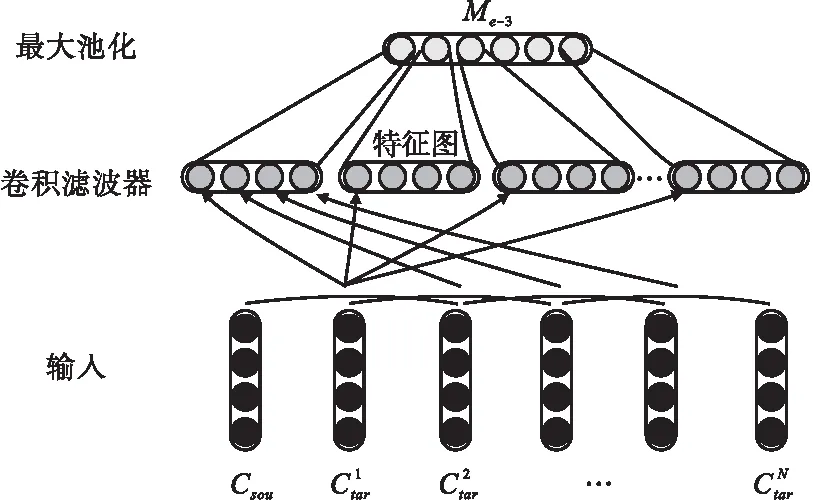
图3 宽度为3的卷积滤波器示意图
(4)
其中l表示经过宽度为3的卷积滤波操作后所提取的特征图维数.Me-2通过宽度为2的卷积滤波器经过类似操作获得.这种卷积可以看作是为不同种语言的句子分配权重的注意力机制,可以直接集成到现有的框架中,在不会引入过多参数的情况下有效提升多语言的信息集成.
3.3 事件类型预测
在进行事件类型预测时,把事件检测任务形式化为一个多类分类问题,采用一个SoftMax分类器来识别候选触发词,并且使用Csou,Ctar,Me-2和Me-3的联结作为分类器的输入:
S=softmax(tanh(Wae[Csou,Ctar,Me-2,Me-3]+bae))
(5)
其中,Wae是权重矩阵,bae是偏置项.
给定表示各种事件类型预测概率的实值向量S,候选触发词x属于事件类型y的概率为:
P(y|x,Θ)=Sy
(6)
其中,Θ表示参数集合,Sy是向量S的第y个元素.
3.4 模型训练
(7)
其中,λ是正则化参数.
训练使用随机梯度下降方法,并添加了dropout用于正则化.通过从训练集中随机选择小批次来迭代训练直至收敛.
4 实 验
4.1 实验设置
为评估HAN利用多语言线索提升事件检测效果的有效性,分别在两个事件检测基准数据集ACE2005和KBPEval2015上进行实验.对于ACE2005,采用标准数据集划分,即其中的529/30/40个文档被用作训练集/开发集/测试集.对于KBPEval2015数据集,在标准的评估数据集(LDC2015R26)上测试模型,使用RichERE标注数据集(LDC2015E73)作为训练集,其中随机采样的30个文档用作开发集.
评估使用官方评估标准,即1)若触发词的偏移量与参照触发词的偏移量匹配,则触发词识别正确(触发词识别,Trigger Identification);2)若一个触发词的事件类型和偏移量与参考触发词的事件类型和偏移量匹配,则触发词被正确分类(触发词分类,Trigger Classification).用准确率(Precision,P),召回率(Recall,R)和F1值(F1)作为评价指标.用双尾t检验来检测显著性提升,并且在实验结果表格种用加粗来标记HAN模型相对其他基准模型的显著提升(p<0.05).
对于模型的参数设置,所有训练数据的迭代数设为15,神经网络的dropout率设为0.6,学习率初始化为0.001,mini-batch设为160,词向量、实体类型向量、位置向量的维度分别设为200、50、5.
4.2 多语言的效果验证
为验证多语言信息对事件检测有利,首先探索双语言的效果.这里选取一个基准模型设置BASE来进行实验比较,它仅用源语言而不加入任何目标语言的信息来进行事件类型的预测.图4展示了每种双语言的设置(源语言及一种不同的目标语言)下的模型在ACE2005和KBPEval2015的开发集上相对于BASE模型设置的表现提升.
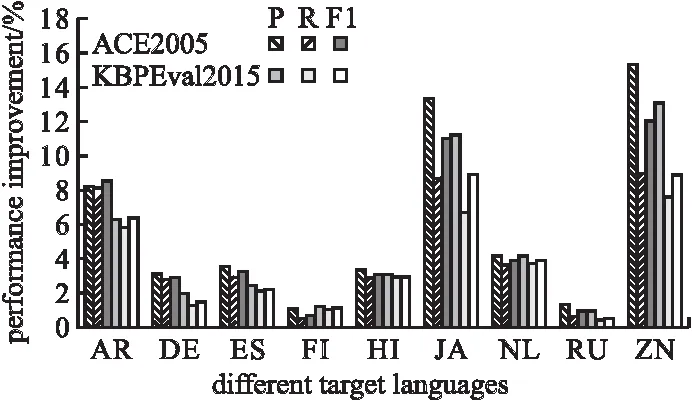
图4 不同种双语言设置下模型的性能相比于BASE模型设置在两个数据集上的提升(均使用英文作为源语言).AR:阿拉伯语,DE:德语,ES:西班牙语,FI:芬兰语,HI:北印度语,JA:日语,NL:荷兰语,RU:俄语,ZN:中文
注意到,所有的双语言设置下的模型效果都一致地优于只依赖一种源语言进行预测的BASE模型.在所有双语言设置的模型中,中文和日语作为目标语言的模型在两个基准数据集上性能提升最大,并且在两个数据集上相对于BASE分别有高达11.95%和8.91%的F1指标提升.分析原因,可能是这两种同一语系的语言都有书写和语义系统,便于更好地整合词语层和结构层的语义成分.并且,这两种语言与英语的语言体系不同,可以更充分地获得不同语言之间的互补信息.
接着验证多种语言能为模型带来进一步的提升.按照图4中增加单个目标语言获得的性能提升的降序来依次添加目标语言,每次多增加一种目标语言,在ACE2005和KBPE-val2015的开发集上进行实验.图5展示了实验的结果,可以观察到随着加入的目标语言的增加,F1指标单调上升.虽然使用更多的目标语言能够提升事件检测的效果,但是更多的目标语言在造成更大的计算成本情况下,带来的效果提升也趋于饱和.综合考虑模型效果与计算成本后选择了一个折衷的多语言组合,即使用英语作为源语言,中文和日语作为目标语言.这个折衷方案相比BASE 模型在ACE2005 和KBPEval2015 两个数据集上分别有15.4% 和11.7% 的F1指标的提升.之后的实验也均用这个组合来进行实验测评.
图5 融合不同数量的语言的模型在两个数据集上的表现
4.3 与其他事件检测方法的比较
本节将HAN 与现有的事件检测模型进行比较.这里选取了一系列先进模型用于比较,对于基于特征工程的事件检测模型,选择MaxEnt[4],Cross-Event[3]和PSL[5];对于基于神经网络的事件检测模型,选择DMCNN[7],JRNN[9]和Skip-CNN[8];同时也选择了一些基于监督学习的模型,有DMCNN+FB[10],DMBERT+Boot[11]和PLMEE[12];对于多语言的方法,选择了3个模型Cross-Lingual[17],LEX+TARNS[18]和GMLATT[19],分别为基于特征的双语言方法,基于特征的多语言方法和基于神经网络的双语言方法.以上模型的信息在章节2中有详细介绍,实验直接应用这些模型原本的参数设置.为了进行公平的比较,也额外添加了一个HAN 的一个变体模型BASE+ZN,该变体是图4中效果最好的双语言设置的模型.KBP2015Best[20]是Hong 等人使用的半监督学习的事件抽取方法,在KBP2015评测中取得最好的结果.表1给出了上述模型在ACE2005和KBPEval2015两个数据集的测试集上的实验结果.
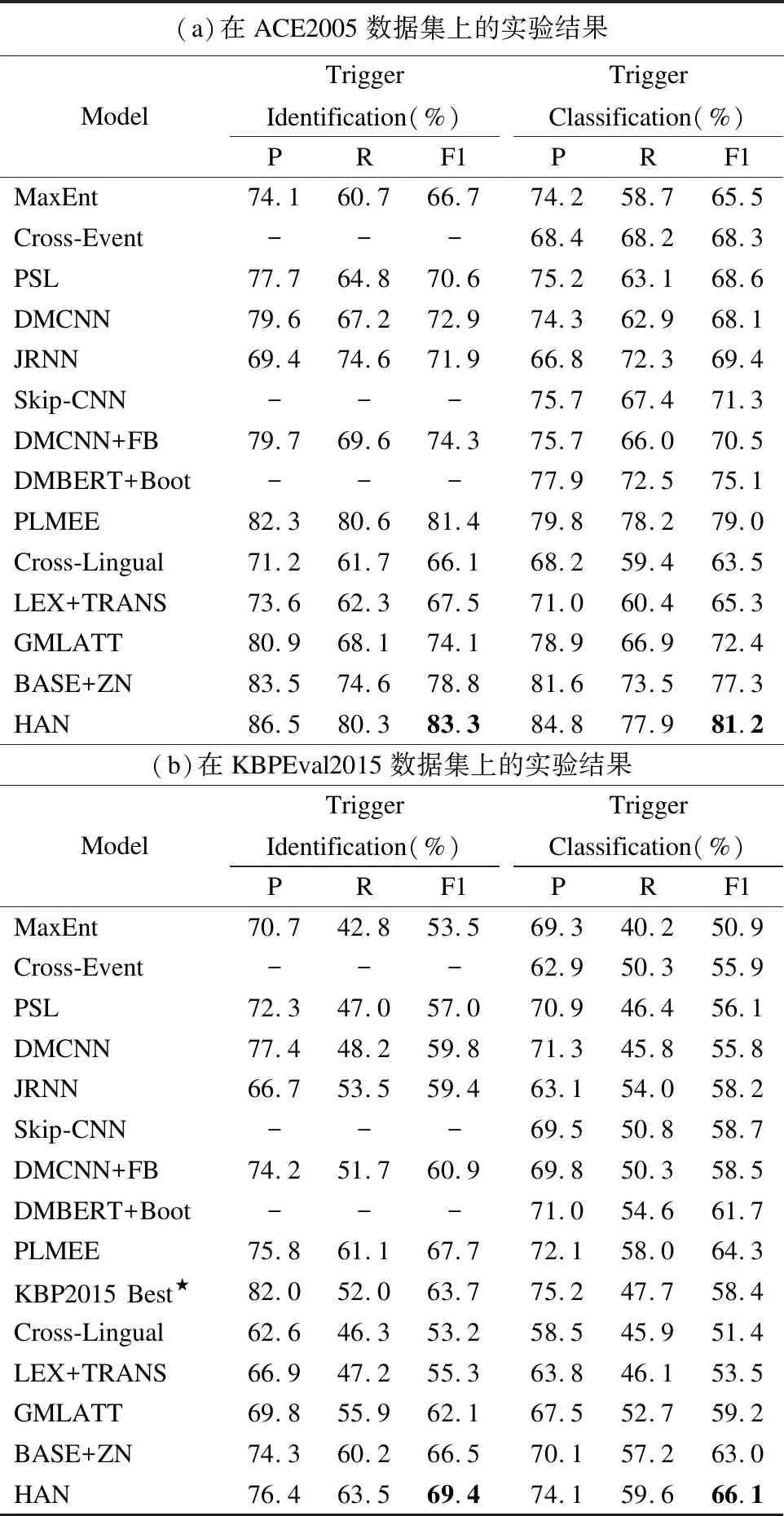
表1 不同模型在事件检测任务上在两个基准数据集上的结果.★表示模型结果来自于原文章
可以发现,HAN 在两个数据集上的效果都显著地优于现有的基准模型.与这些模型相比,HAN 在触发词识别任务上在两个数据集分别获得至少1.9% 和1.7%的F1分数提升,在触发词分类任务上在两个数据集分别获得2.2%和1.8%的F1分数提升.另外,也能观察到如下的一些信息:1)基于神经网络的方法普遍比基于特征工程的方法表现更好.这可能是因为基于神经网络的方法能够自动地从训练数据中学习综合的特征.而基于监督学习的神经网络方法获得了更多的效果提升因为这些方法能够利用监督信息以在一定程度上缓解数据稀疏的问题;2)GMLATT,BASE+ZN和HAN这3种模型都比Cross-Lingual 和LEX+TARNS在事件检测任务上表现的更好.这也是在预料之中,因为前3种模型利用神经网络学习更深层特征;3)模型BASE+ZN和GMLATT都是利用英语作为源语言,中文作为目标语言,融合来自这两种语言的多语言线索,模型BASE+ZN比模型GMLATT 在事件检测上有更好的表现.分析原因,可能是BASE+ZN中基于CNN的多语言注意力模块能够更好地从源语言和多种目标语言中捕获显著的语义特征;4)模型LEX+TARNS比Cross-Lingual表现更好,HAN比BASE+ZN表现更好,这也说明基于神经网络的模型和基于特征工程的模型都能在一定程度上从多语言线索中获得补充信息,帮助改进事件检测.
4.4 消融分析
为探索混合注意力模块效果,本节进行消融分析,观察混合注意力模块中两个注意力机制对模型效果的改善.为此设计3个HAN的变体模型:HAN-Mul去掉多语言注意力模块,仅使用多种语言文本的上下文表示进行预测;HAN-Con去掉上下文注意力模块,仅使用多语言的表示进行多语言注意力以及预测;HAN-Hybrid去掉混合注意力模块,直接用多语言表示来预测.在两个数据集的测试集上进行评估,表2中展示了模型变体在事件触发词分类任务上的表现.
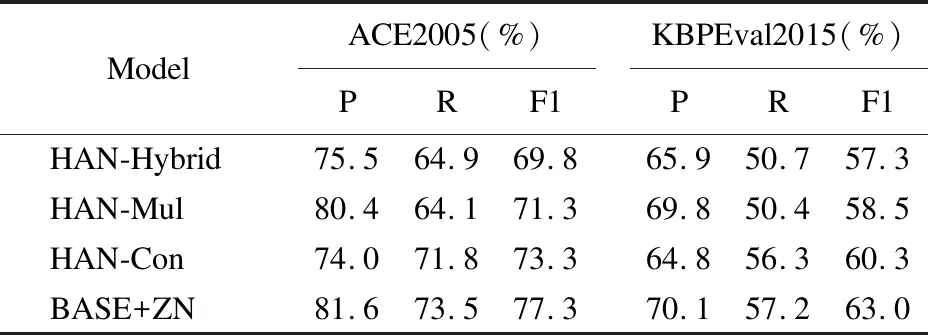
表2 对混合注意力模块做消融实验的实验结果
从表中结果可以观察到:1)不论是HAN-Mul还是HAN-Con,两者表现地都比HAN-Hybrid要好,这说明上下文注意力机制和多语言注意力机制对集成多语言线索用于事件检测都是有效的;2)与HAN-Hybrid相比,HAN-Mul获得更高的准确率但是稍低的召回率,HAN-Con获得了相反的结果.分析原因可能是由于HAN-Mul利用上下文注意力捕获上下文中显著的综合信息,使得检测结果更加精确;HAN-Con使用多语言注意力集成来自多种语言的互补信息,缓解数据稀疏,使得召回率相对更高;3)HAN在两个基准数据集上在准确率和召回率上的效果比HAN-Mul和HAN-Con都要好,这说明上下文注意力和多语言注意力两者能够为事件检测带来互补的效果提升.
此外,也探索了第3.1节中不同的特征组合输入的影响.为此测试了以下几个仅仅改变混合注意力模块输入的特征组合的变体:WE指保留词向量,去掉实体类型向量和位置向量;WE+ETE指保留词向量和实体类型向量,去掉位置向量;WE+PE指保留词向量和位置向量,去掉实体类型向量;ALL表示原有的特征组合模型.为了消除多语言数据的影响,使用HAN-Mul作为模型,然后在单语验证集上验证特征组合的效果.表3展示了不同特征组合在事件触发词分类上的结果.
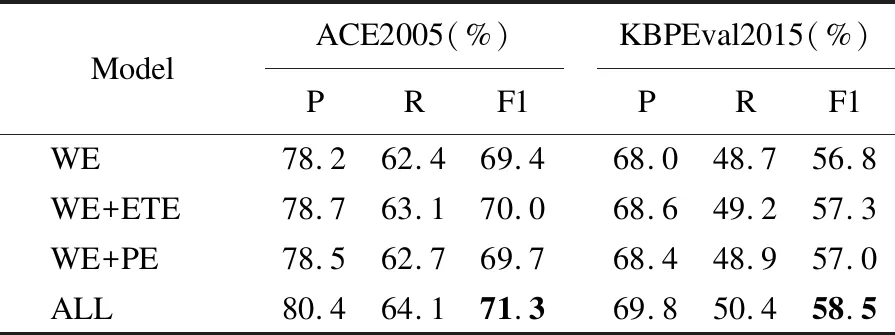
表3 对不同的特征组合做消融实验的实验结果
从表中可以观察到ALL在所有指标上表现得都比WE+EE和WE+PE要好,这表明实体类型向量和位置向量两者对于事件检测都是有益得,两者能够对最终事件检测结果产生互补的效果.
5 结束语
事件检测作为事件抽取任务的关键一环,在自然语言处理相关领域的研究工作,如自动文摘、自动问答、信息检索等领域发挥着重要作用.本研究从事件检测任务面临的数据稀疏和自然语言歧义这两个挑战出发,提出挖掘利用多语言线索来提升事件检测的效果.研究提出的HAN模型通过上下文注意力挖掘多语言上下文的一致信息,以缓解数据稀疏问题;通过多语言注意力获得多种目标语言之间的互补线索,传递至源语言以缓解自然语言歧义的问题.在两个基准数据集上进行的综合性实验证实了使用多语言线索的有效性.HAN模型在事件触发词识别和分类任务上在两个基准数据集上的表现均显著提升.
多语言线索以及混合注意力网络同样可以应用到其他的信息抽取相关任务例如关系抽取或事件要素抽取等任务上.如何在降低计算成本的要求下,高效且充分地利用多语言的信息也是未来工作中有待进一步考虑的问题.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
教育教学论坛(2019年18期)2019-06-17
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
华南师范大学学报(社会科学版)(2013年1期)2013-12-02
疯狂英语·中学版(2013年7期)2013-08-01
