
面向用户需求的生成对抗网络多样性推荐方法
2023-05-23 14:45王嵘冰徐红艳张永刚
小型微型计算机系统 2023年6期
冯 勇,刘 洋,王嵘冰,徐红艳,张永刚
1(辽宁大学 信息学院,沈阳 110036)
2(吉林大学 符号计算与知识工程教育部重点实验室,长春 130012)
1 引 言
随着移动互联和大数据技术的飞速发展,网购行业日渐成熟,电子商务作为新兴产业在我国迅速崛起,从经济体系的占比来看,电商产业已经成为了我国的一大经济支柱.为了使电商产业健壮发展,大多数平台采取融合推荐算法的方式,形成电商推荐系统,从而更好地服务消费者.然而,现有电商推荐系统过多注重推荐的准确性而缺少对多样性的深入思考,使得推荐结果过于冗余、用户体验感较差,无法进一步激起消费者购物欲望.其实,相比于准确性,多样性对于用户和商家拥有更大的意义和价值.对于用户来说,多样性推荐使得推荐列表足够丰富,节省用户检索时间并拓宽了用户的视野.对于商家来说,多样性推荐不仅能使更多产品得到推荐,而且能够深层挖掘用户兴趣,增加用户粘性,提升交易率从而获取更多利益.
在多样性研究中,有学者认为商品的分布服从长尾分布,推荐的商品多数集中于热门商品,而冷门商品鲜少有被推荐,适当提升冷门商品的推荐比例可以很好地解决推荐样式过于单一的问题[1-3].邓明通等人定义受长尾分布约束的商品疲劳函数,并引入时间衰减函数调整用户评分,最终将矩阵分解和商品疲劳函数结合,有效提升了冷门商品的推荐占比[4].Zheng等人认为多样性推荐列表内的商品应该存在较低的相似性,引入DRN网络学习用户偏好及新闻动态特征,根据用户反馈实时更新,使得推荐的新闻均反映不同的事件[5].
关于商品多样性推荐,现有研究通过推荐更多冷门商品或是降低推荐列表内商品的相似度来提升推荐的多样性,并未考虑用户的偏好和具体需求,导致推荐的多样性与准确性相矛盾.本文认为深入分析具有多样性需求用户的偏好,从商品的多个属性层面满足用户的需求可以实现推荐多样性和准确性的统一.为此,本文提出了一种面向用户需求的生成对抗网络多样性推荐方法(UR-GAN,Generative Adversarial Network Diversity Recommendation Method Oriented to User Requirement),该方法由生成模型和判别模型组成,其中,生成模型由四层结构组成,同时结合用户需求,生成多样性商品表示;判别模型判定生成商品是否为真实商品,反馈给生成模型.最后,计算各商品与多样性商品表示的相似度,产生推荐列表.经对比实验验证,本文所提方法由于采用多生成器网络结构,能够处理商品的多个属性特征以实现多样性推荐,并且结合用户需求使推荐结果既具有多样性,又带来准确性的提升.
2 相关工作
在推荐算法中,矩阵分解作为最经典的算法,被广泛应用于电商领域,后续大量的研究以此为基础进行多样性的改进[6].李卫疆等人通过核密度估计的方式找到相同兴趣的用户,用兴趣用户的评分扩充评分矩阵,之后进行矩阵分解,得到的推荐列表包含了兴趣用户的商品从而实现多样性[7].Gogna等人基于低秩矩阵分解算法,引入电影类别元数据,通过添加正则项作为约束,使得不同类别的平均评分服从均匀分布以实现电影类别的多样性[8].
有学者将用户-商品二部图引入到多样性推荐研究,通过将用户和商品抽象成图中的点,点间连线代表两者之间存在关系,通过连线进行资源的分配,最终用户得到资源完成推荐.An等人利用活跃性提取虚拟专家,为专家分配更多的资源,然后专家将更多的资源转移到更大范围的商品中从而完成多样性推荐[9].Yu等人通过信任者的能力和用户对信任者的确定性定义信任度,之后用新颖性需求和多样性需求量化用户总体需求,通过信任度控制资源转移的数量实现多样性推荐[10].
随着深度学习技术的发展,多样性推荐的研究也逐渐融入各种深层网络,如CNN、RNN、GAN等[11-13].傅魁等人利用LSTM建模用户的正、负反馈,对深度Q网络进行改进,保证了推荐的稳定性[14].秦婧等人针对长尾物品构建了CNN模型,通过将长尾物品替换热门物品来实现长尾推荐[15].Wu等人通过DPP概率用模型得到核矩阵获取不同商品的共现,之后运用GAN通过一组物品学习用户的多样性偏好[16].
尽管上述方法在多样性推荐上都有不同程度的改善,但都仅关注单一层面的多样性,缺少对商品多属性层面的深入分析,并且未考虑用户的多样性需求.综上,本文运用深度学习技术对商品多样性推荐开展研究,改进传统生成对抗网络结构,将单个生成器扩展为多个,使其能够处理不同的商品属性,从而实现多属性层面上的多样性推荐.
3 UR-GAN方法
给定一个推荐系统,包含用户集U={u1,u2,u3,…,um}和商品集V={v1,v2,v3,…,vn},每个商品vi∈V由属性Ci={ci1,ci2,ci3,…,cik}构成,其中k表示属性的数量.UR-GAN方法由生成模型和判别模型两部分组成,其中,生成模型包括输入层、嵌入层、交互层和隐藏层,最终生成多样性商品表示vc.判别模型判定生成商品是否为真实商品,并反馈给生成模型.该方法的框架如图1所示.

图1 UR-GAN方法框架
3.1 方法描述
图1中可以看到,UR-GAN方法由生成模型(G model)和判别模型(D model)组成,其中生成模型以多样性推荐为目标,生成符合用户需求的商品表示,判别模型区分真实商品与生成商品,并反馈给生成模型,促使生成模型生成的商品无限接近真实商品且足以欺骗判别模型.
3.1.1 生成模型
生成模型的输入为用户交互商品的属性信息,即用户-属性交互向量,输出为多样性商品表示,该商品表示从多个属性方面生成,能充分反映用户需求.
1)输入层
输入为用户-属性交互向量,每个向量代表不同的属性,cij为商品vi的第j个属性.在每个交互向量中,1代表用户与该属性的特定值产生交互,0代表用户与该属性的特定值无交互.其中,每个属性都拥有多个特定值,如公式(1)所示,l表示特定值的个数,其由具体商品及其属性决定,如手机的品牌属性,拥有苹果、华为、三星等多个特定值.
(1)
2)嵌入层
由多个生成器组成,其中每个生成器对应一个商品属性,并且每个生成器均以多样性推荐为目标,使得推荐的商品覆盖更多不同的属性.这样,每个生成器都能从不同属性角度生成潜在商品特征.同时,考虑用户需求,引入的思想是每个属性都包含不同的特定值,而每个特定值并不应该是均等的,如面对不同的用户及不同的场景时应赋予不同的权重,以区分不同特征值的重要性.最后,将每个生成器基于不用属性生成的商品特征组合,构成该用户u偏好商品的总体特征eu,如公式(2)所示:
eu={g1(ci1),g2(ci2),…,gk(cik)}
(2)
3)交互层
生成的商品特征由不同的属性组成,而不同的属性之间并非独立而是存在关联的,比如品牌属性和价格属性之间就存在联系,高端品牌的商品价格要略高于大众品牌的商品价格.因此采用交互操作建立属性之间的关系,如公式(3)所示,⊗代表元素级别的交互,即对应元素相乘,eui、euj为eu的一阶特征,xi、xj为eu的二阶特征.最终得到所有属性之间两两进行特征交互的结果.
(3)
4)隐藏层
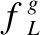
(4)
3.1.2 判别模型
在生成对抗网络中,为了训练更加健壮的生成器,需要判别器不断促进生成器迭代训练.判别模型试图区分生成商品与真实商品,并将结果反馈给生成模型,促使生成模型生成的商品表示更加趋近于真实商品.
判别模型的输入为真实商品、生成商品和相应用户,输出为用户与商品的匹配程度,用D(v|um)表示,如公式(5)所示:
(5)
其中σ为sigmoid函数,用于计算用户与商品匹配的概率.dφ为判别模型,与生成模型的隐藏层一致,由多个全连接层组成,具体如公式(6)所示:
(6)
3.2 模型训练
生成对抗训练通过生成器与判别器完成最大最小间的博弈来彼此完善,最终使生成器足以欺骗判别器.生成模型以用户-属性记录作为输入,以多样性推荐为目标,为每个属性对应一个生成器,从不同属性角度生成商品表示.判别模型区分真实商品与生成商品,促使生成模型生成趋近于真实并且与用户匹配的商品.综上,方法的总体目标函数见公式(7):
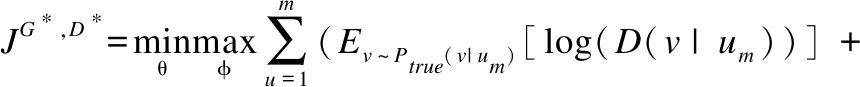
(7)
其中,Ptrue(v|um)为真实商品v的概率分布,Pθ(vc|um)为生成商品vc的概率分布.
1)优化生成模型
生成模型可以根据给定用户和商品属性信息,以多样性推荐为目标,学习生成商品表示.生成模型最小化总体目标函数以使生成商品与真实商品的差别足够小,可以欺骗判别器使其难以分出真实商品和生成商品.具体如公式(8)所示:
(8)
2)优化判别模型
与生成模型不同,判别模型旨在最大化总体目标函数,使得真实商品与生成商品之间的区别足够大.之后,将判别结果反馈给生成模型,促使生成模型训练调参,通过不断的迭代优化,最终生成最佳商品表示.具体如公式(9)所示:
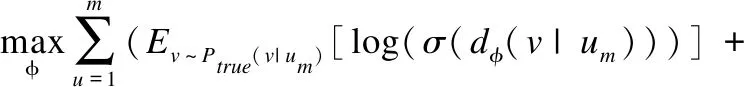
(9)
3)训练过程
模型的整体训练过程如算法1所示,首先根据数据集中的用户、商品、属性信息构建用户属性向量和商品属性向量.其中,用户属性向量需要先获取用户交互过的商品,之后根据商品对应的属性得到用户属性向量.对于交互过的属性值置为1,未交互的属性值置为0.然后,根据输入的用户属性向量,训练生成模型与判别模型.在训练生成模型参数时,固定判别模型参数,直到生成模型生成的商品向量可以被判别模型认定为真实向量.训练完生成模型后,固定生成模型参数训练判别模型,直到最终生成模型与判别模型都趋于收敛.最后,用训练完的生成器生成以多样性推荐为目标并且符合用户需求的商品表示,根据此商品表示,找到与其相似的N个商品组成最终的推荐列表L.
算法1.模型训练算法
输入:生成模型G,判别模型D,数据集S1、S2,生成模型迭代次数g-steps,判别模型迭代次数d-steps.
输出:推荐列表L
1.初始化G、D权重θ,φ.
2.foruinS1、S2do
3. 根据用户商品交互记录及商品属性建立用户向量
4.end for
5.forvinS2do
6. 根据商品属性建立商品向量
7.end for
8.Repeat
9. forg-stepsdo
10. for eachudo
11. 根据生成模型生成商品表示vc,如公式(4)
12. 基于公式(8)更新生成模型参数
13. end for
14. end for
15. ford-stepsdo
16. 获取真实商品v与用户u进行判别,如公式(5)
17. 基于公式(9)更新判别模型参数
18. end for
19.forvinS1do
20. 计算vc与S1内商品的相似度
21. 取相似度高的N个商品构成推荐列表L
22.end for
4 实验分析
本文所提方法根据用户购买记录内的商品属性信息,并结合用户需求预测用户多样性偏好商品,最终以商品列表的形式进行推荐.为了验证本文所提方法的综合性能,在准确性和多样性两类评价指标上进行对比实验.
4.1 数据集及评价指标
本文选取主流数据集Amazon 5-core 中的3个子数据集Automotive、Toys_and_Games、Digital_Music来评估算法的性能.每个数据集又由两部分组成,其中数据集S1包含用户、商品、评分等,数据集S2包含商品元数据信息,本文选取类别、价格、品牌作为商品的属性,如下所示{′asin′:′B00004W411′,′categories′:[[′Automotive′,′Interior Accessories′,′Steering Wheels &Accessories′,′Steering Accessories′]],′price′:19.99,′brand′:′Micro Innovations′,}.其中,类别属性由多个词语组成,通过观察发现,词语覆盖范围级别从大到小,选择第2级别作为最终类别属性,3个数据集的类别信息如表1所示.其中每个数据集中的数据,将80%用于训练,20%用于测试.
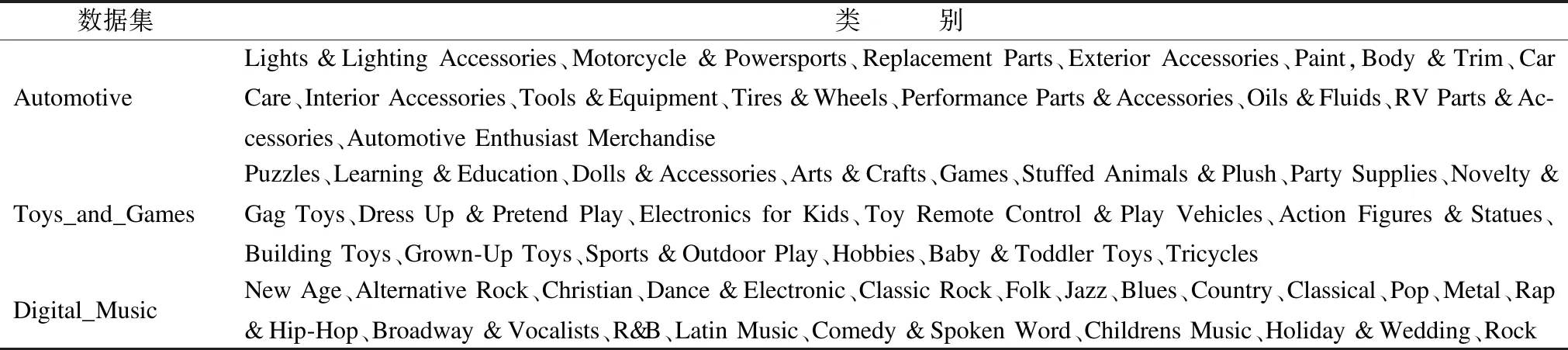
表1 数据集类别信息
为了充分验证本文所提方法的多样性推荐能力,选取内部多样性ILS(Intra-list Similarity)和总体多样性HD(Hamming Distance)作为评价指标.
内部多样性反映了单个用户推荐列表中商品间的不相似性,计算公式见公式(10),i、j为用户推荐列表中的商品,R(u)为用户u的推荐列表,sim()为相似度.
(10)
总体多样性反映了不同用户间推荐列表的不相似性,计算公式见公式(11),quv是用户u、v的两个长度为k的推荐列表的公共物品数.
(11)
同时,为了验证算法的准确性,选取Recall作为评价指标,计算公式见公式(12),其中,n1表示推荐列表中测试集中的商品数,n2表示测试集中的商品数.
(12)
4.2 对比方法与参数选取
选取以下方法作为对比方法进行对比实验,验证本文所提方法的性能优势.
1)DRMUD[4]:基于用户偏好和动态兴趣的多样性推荐方法,该方法改进传统的矩阵分解算法,引入时间衰减函数动态调整用户评分,将商品疲劳函数与矩阵分解融合,从而增加对冷门产品的推荐以提高多样性.
2)TrAd[10]:一种用户商品二部图的自适应信任感知推荐方法,利用用户间的信任关系量化用户多样性需求,使得在资源分配的过程中,减少流行商品的资源,增加信任用户的资源转移.
3)PD-GAN[16]:将DPP算法与生成对抗网络结合,同时学习用户对单个物品的偏好及对一组物品的多样性偏好,使得生成器生成的商品既符合相关性又体现多样性.
由于商品属性选取了类别、价格、品牌,生成器与商品属性对应,所以生成器的个数设置为3.对于方法中的权重项和偏执项以及生成器和判别器中的初始化权重,均采用随机初始化方法.生成器和判别器的隐藏层数选取范围{1、2、3、4、5},隐藏层内的神经元数目为{100、200、300、400、500},其中每个神经网络的激活函数使用sigmoid函数.由于生成模型的输入用户-属性向量为离散值,所以每个生成器设置为可训练的嵌入矩阵.每次训练的批量大小选取{128、256、512、1024},学习率使用{1E-05、1E-04、1E-03、1E-02、1E-01}.
4.3 实验结果分析
实验1.多样性分析
所有的生成器均以多样性推荐为目标,使得推荐列表内的商品尽可能的多样化.对于类别生成器,其关注所有的商品类别,使得最终推荐的商品覆盖种类足够丰富.对于品牌生成器,考虑用户需求,将未交互过的品牌占比设置为α,交互过的品牌占比设置为1-α.最后,对于价格生成器,首先计算每个类别下商品的价格均值,对于大于均值的商品定义为高价格商品,对于小于等于均值的商品定义为低价格商品.之后,统计用户所有交互商品的价格,计算高价格商品和低价格商品的比例作为价格生成器所关注的价格比重.
为了选择品牌生成器中合适的α值,选取推荐列表长度为10进行实验,在内部多样性和总体多样性上的结果如图2(a)和图2(b)所示.按理α值越大,最终推荐的商品越多样化,但是发现当α>0.7后多样性指标反而不再上升.通过分析数据集发现,每个品牌均包含多种类别的商品,对于新的品牌,它所包括的商品类别已经在之前的品牌中出现了,所以并不会造成多样性的进一步提升.同时,用户交互过的品牌也代表用户的品牌偏好,应在最终的推荐品牌中有所体现.
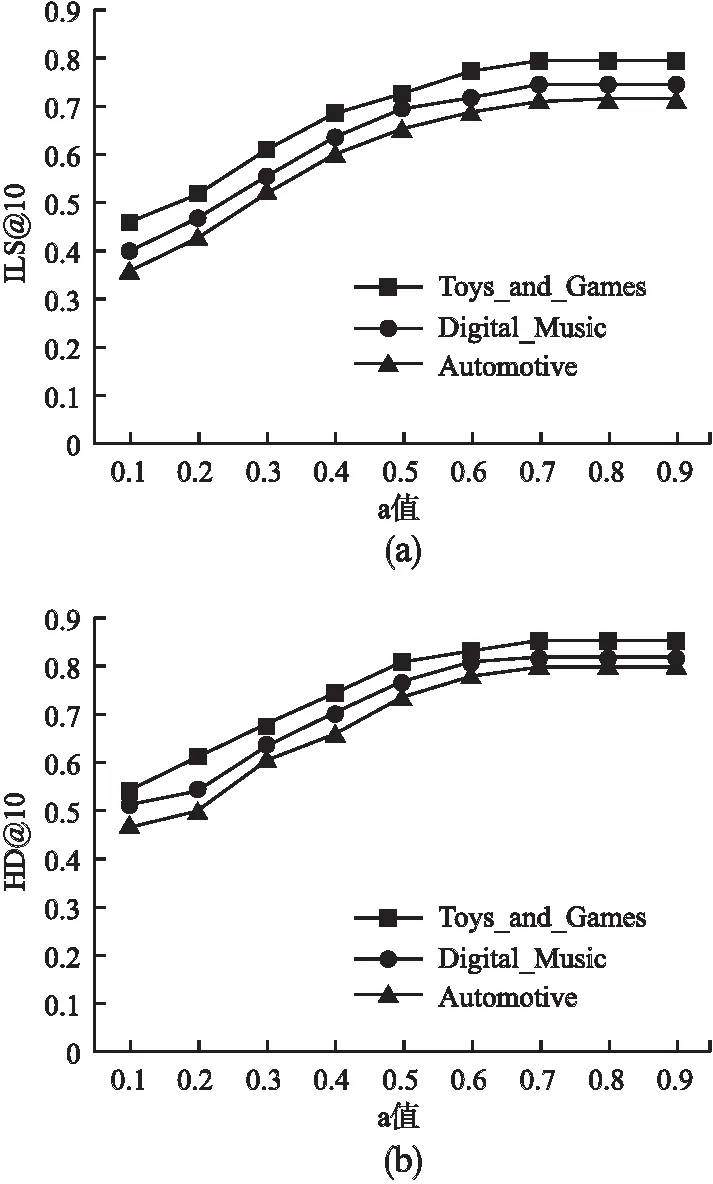
图2 品牌生成器α值分析
本文所提方法与对比方法在多样性指标上的表现如表2所示,分别选取Top-N列表长度为10和20,在3个数据集上进行试验.结果显示,本文所提方法的多样性推荐性能均优于其他方法,其中,由于Toys_and_Games数据集商品种类最多,所以取得了最佳的效果.对比发现,对于改进传统矩阵分解算法的DRMUD,在多样性推荐性能上效果整体不佳,由于其仅仅是提升冷门商品的推荐比重,而对于总体推荐列表的类别多样性上帮助不大.物质扩散算法是目前大多数多样性推荐算法选取的基础方法,TrAd通过建立信任用户从而提升信任用户所分配的资源以达到多样性推荐的目的,其过程就是资源从用户到商品再到用户的转移,而通过提升某一步的资源转移权重来提升多样性存在片面性,不足以适用于每个用户.PD-GAN方法将GAN的博弈思想引入多样性推荐领域,通过DPP概率模型使得推荐的商品不相似的概率最大化,从而达到多样性的目的,但是多样性不应仅包括商品间的不相似性,还应该包括属性多样性等.本文所提方法,通过不同的生成器关注不同的商品属性,每个生成器均以多样性为目标,不仅实现了类别多样性还能实现品牌多样性,同时分析用户价格需求满足用户消费水平,使得最终的推荐列表不仅满足用户需求,而且推荐的商品种类丰富,无论是针对个人还是用户之间,推荐的商品都能达到多样性的目的.
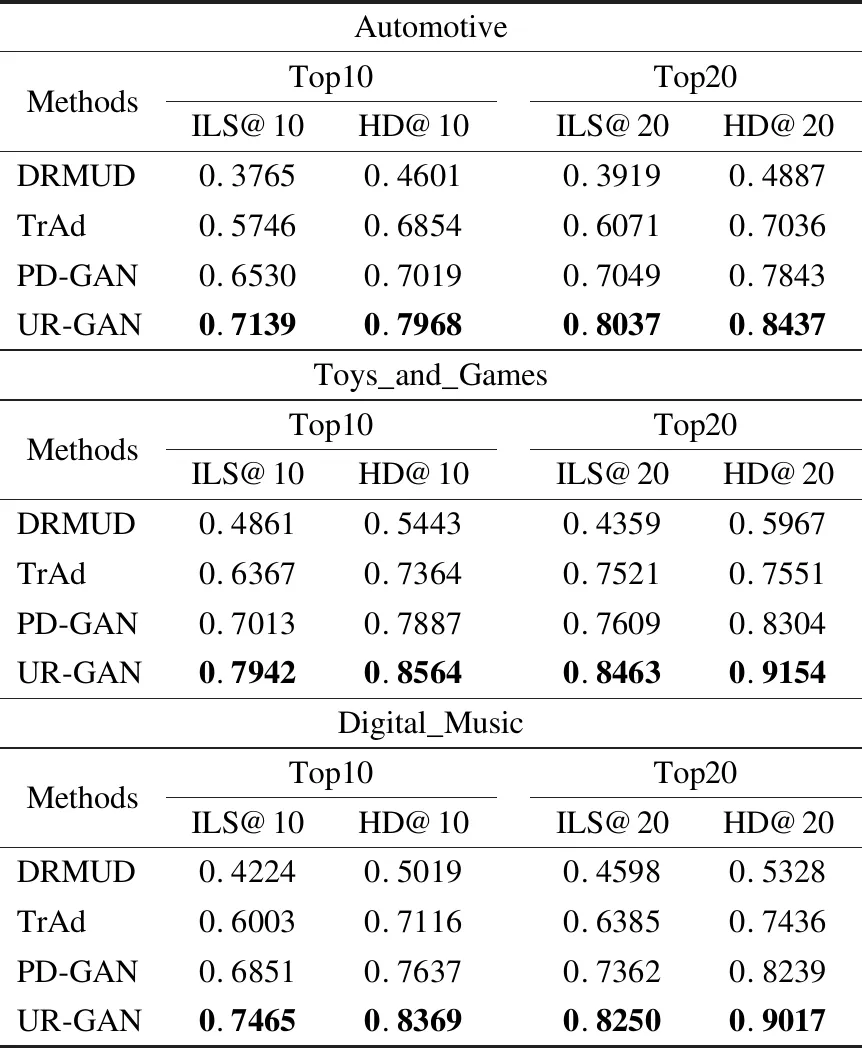
表2 方法多样性对比
实验2.准确性分析
本文所提方法以多样性推荐为目标并兼顾准确性,为了在提升推荐结果多样性的同时不降低准确性,考虑结合用户需求.本文所提方法在品牌生成器和价格生成器上,充分考虑用户在多样性和准确性上的需求.对于品牌生成器,同时分析用户购买过商品的品牌和未购买过商品的品牌,使其按照最佳比例推荐.对于价格生成器,按商品类别进行划分,分析用户所购买该类别商品中高价商品与低价商品的比例,使最终推荐商品的价格符合用户的消费习惯.
为了验证用户需求的考虑是否对提升推荐的准确性有所帮助,实验2选取Automotive数据集在准确性指标Recall上进行对比实验,推荐列表长度选取10和20.结果如图3所示,结合用户需求的推荐结果与其他方法相比,在准确性上确实有所提升.因为用户需求的考虑可以使推荐结果更加迎合用户喜好,无论是用户在商品品牌上的选择还是在价格上的消费习惯,都能够做到因人而异,满足不同用户的各项需求,实现兼顾准确性与多样性的推荐.
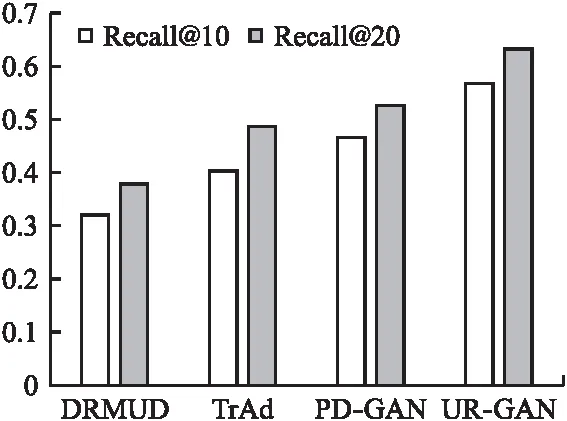
图3 方法准确性对比
5 结束语
针对当前商品推荐方法在多样性方面存在的不足,本文提出了一种基于生成对抗网络的商品多样性推荐方法.该方法由生成模型和判别模型两部分构成,其中生成模型设置为多生成器结构,每个生成器关注一个商品属性,同时结合用户需求,生成符合用户兴趣的多样性商品表示;判别模型用于区分真实商品与生成商品,将结果反馈给生成模型使其不断优化稳定.最后基于生成的商品找到与其相似的商品进行推荐.实验表明,本文所提方法有助于分析用户在多属性层次上的多样性,且用户需求的融入在满足推荐多样性的同时,会进一步提升推荐的准确性.接下来,将进一步考虑跨领域多样性分析,实现跨领域的多样性推荐.
猜你喜欢
建材发展导向(2021年10期)2021-07-16
小学生学习指导(中年级)(2021年4期)2021-04-27
课堂内外(初中版)(2020年5期)2020-06-19
疯狂英语(双语世界)(2016年3期)2016-02-27
管理现代化(2016年5期)2016-01-23
新校长(2016年8期)2016-01-10
中学生数理化·中考版(2015年10期)2015-09-10
商事法论集(2014年1期)2014-06-27
安徽医药(2014年4期)2014-03-20
华东师范大学学报(自然科学版)(2014年3期)2014-03-11
