
基于Stacking特征增强多粒度联级Logistic的个人信用评估
2023-05-23 08:52:22侯天宝王爱银
河南师范大学学报(自然科学版) 2023年3期
侯天宝,王爱银
(新疆财经大学 统计与数据科学学院,乌鲁木齐 830012)
在“互联网金融”的快速发展背景下,P2P网贷近几年来发展规模日益壮大,其业务涉及领域也层出不穷.该模式下借贷方式是个人对个人进行信贷,P2P平台作为中介实现借款人想要借款和贷款人放贷进行投资的需求.其典型的运行模式是借款人和贷款人在平台上自由竞价,每次借贷双方达成交易,平台收取相应的中介费.P2P网贷平台具有投资门槛低、成本代价小并且交易更加便捷等优势.但万物具有两面性,P2P不断发展的同时潜在的信用风险问题也日益凸显,不少借款人因违约未按期还款给平台以及行业造成了不利的影响.据有利网在官方微信公众号发布严重失信借款人信息,每周都有失信人信息公布,且人数都在2 000人左右.由此可见,个人信用评估在P2P平台的重要性.
针对个人信用评估问题,提出一种基于Stacking特征增强多粒度联级Logistic模型,该模型的构建主要包括两部分:第一部分,基于Stacking集成的多粒度扫描器的构建,利用网格搜索技术进行调优,以准确率为指标,选出合适的基评估器作为Stacking框架的初级学习器,并用Logistic模型作为次级学习器.第二部分,多层联级Logistic模型的构建,为防止整个模型的过拟合现象,在每一层中的Logistic模型进行交叉检验,同时在训练过程中用模型的惩罚系数去自适应调节优化整个联级Logistic模型的预测性能,以此提升模型准确率.
1 相关工作
信用评估是指评估机构利用相关权威专家的判断或者数学建模方式,结合融资者所提供的财务信息、经营相关信息以及历史还款信息等各类指标综合进行分析,对融资者是否如期按照约定偿还债务本息的能力以及意愿进行评估,并按照其违约概率的不同以划分等级或分数的形式给出评估结论的行为.
在个人信用评估研究领域,评估的方式有三大类:一类是基于统计学方法,运用统计方面的性质来分析数据的分布及规律并进行建模,常见的方法有逻辑回归(Logistic Regression)和线性判别分析(Linear Discriminant Analysis).如OHLSON[1]首次将逻辑回归模型应用到信用评估问题中,WIGINTON[2]在研究模型信用评估问题上,将逻辑回归与线性判别分析法加以对比,实验结果表明逻辑回归评估效果优于线性判别分析.STEENACKERS等[3]结合逻辑回归模型与极大似然估计建立了信用评估模型,将数据划分为好贷款、坏贷款以及拒绝贷款等三大类,用极大似然估计法去迭代逻辑回归模型,从而找出最接近真实值的最优参数.虽然统计学方法可以建立各种分类问题模型,但由于需要较为严格的假设条件,并且缺少对数据特征的学习,导致预测准确率不高.第二类,继统计学方法之后,随着机器学习的兴起,不少学者将机器学习方法引入到信用评估研究领域,无须刻意找寻数据中存在的规律,重点在于通过对数据特征的学习来提高预测精度,打破了统计学方法中建立模型的局限性.如YEH等[4]建立K近邻(K-nearest neighbor)、逻辑回归、神经网络(Neural networks)、朴素贝叶斯(Naive Bayesian)和判别分析等模型来进行信用评估,发现K近邻、神经网络以及朴素贝叶斯模型都优于逻辑回归与判别分析.随着研究的不断深入,影响信用评估的因素不断被探索出来,数据的维度也呈现爆炸式增长,单一的机器学习器评估性能受限,HANSEN等[5]研究发现构建多个模型并按一定的规则结合起来,能显著提高整个模型的泛化性能,准确率有所提高,说明集成模型比单一模型预测性能更好.TWALA[6]通过实验发现,集成算法能有效提高信用评估的准确度.集成学习在信用评估中的应用主要分为装袋法(Bagging)、提升法(Boosting)和堆叠法(Stacking),装袋法的主要思想是从原始数据集中抽取训练集,每轮从原始样本中使用自助采样法抽取多个训练样本,并用多个基评估器进行训练,对于分类问题,采取投票的方式获得最终结果;对于回归问题,则以均值的方式获得最终结果,如经典的随机森林[7](Random Forest,RF)算法.提升法的主要思想是每次使用全部的样本,每轮训练减小上一轮的预测正确的样本权重,增大预测错误样本的权重,通过自动调节权重来提升模型的预测性能,如类别型提升[8](Categorical Boosting,CatBoost)、自适应提升[9](Adaptive Boosting,AdaBoost)、梯度提升树[10](Gradient Boosting Decision Tree,GBDT)、极端梯度提升[11](eXtreme Gradient Boosting,XGBoost)、轻量级梯度提升机[12](Light Gradient Boosting Machine,LightGBM),其中XGBoost和LightGBM运算速度快、准确度高常在Kaggle竞赛中被使用,各类集成算法被广泛应用于信用评估研究领域.Stacking的主要思想是通过组合多种评估器来提升模型泛化性,分为初级学习器和次级学习器两层,将初级学习器的预测结果作为元特征来构建次级学习器模型,以提高预测性能.丁岚等[13]以logistic回归、决策树(Decision Tree)、支持向量机(SVM)作为初级学习器,以SVM作为次级学习器来搭建Stacking集成框架违约风险评估模型,与单一学习器进行比较,发现集成Stacking框架预测性能更好.随着对深度学习的不断深入研究,发现神经网络结构具有良好的特征学习能力以及优化性能,如刘伟江等[14]通过数据成像技术,将个人违约数据转化成图像,应用LeNet-5 模型进行信用评估识别,有着较高的识别精确度;王重仁等[15]将原始数据集进行编码形成包含时间维度和行为维度的灰度图像,并构建具有注意力机制的长短期神经网络(Long Short-term Memory,LSTM)与卷积神经网络(Convolutional Neural Network,CNN)融合模型进行信用评估,并与集成模型进行对比,具有较优的预测性能.第三类,近年来不少学者将机器学习方法与统计学方法相结合应用于信用评估领域,比起单一的学习器预测性能更好,如陈倩等[16]构建基于随机森林的弹性网络回归模型(RF-ElasticNet-Logistic),并与RF-Lasso回归进行对比,实验结果表明RF-ElasticNet-Logistic模型具有较强的预测性能;李佳欣[17]通过应用逐步Logistic回归依据AIC准则对数据进行特征选择,并分别与决策树、条件推荐树、随机森林和支持向量机模型进行对比,发现选择较少特征的模型在验证集上的误差比全变量模型要低,并且基于逐步Logistic回归的随机森林预测准确率最优;曹再辉等[18]以支持向量机、随机森林、人工神经网络(ANN)及梯度提升树作为初级学习器,逻辑回归作为次级学习器来搭建Stacking集成框架违约风险评估模型,与单一学习器、投票集成方法以及人工神经网络进行对比,预测性能最优.
综上所述,本文提出基于Stacking特征增强多粒度联级Logistic模型(Deep_Logistic),该结构类似于深度神经网络(Deep Neural Network,DNN),由于Logistic模型缺少对于数据的特征学习,造成预测准确度下降,通过用Stacking集成获取元特征来增强每一级Logistic进行训练前的特征.除此之外,在整个信用评估建模过程中,包括数据预处理、建立模型、调参、评估.之后,通过AUC、准确率等评价指标对模型进行论证,与此同时与构建Stacking集成的基评估器、常见现有的单一集成分类器在3个不同的个人信用评估数据集上进行对比分析.
2 模型构建理论基础
2.1 相关模型的概述
通过对相关文献的梳理,发现集成学习的方法可以融合多个单一学习器的预测效果,可提升预测的准确度,并且Stacking 集成相对 Bagging和Boosting,往往预测精度更高,而且过拟合的风险会更低[19],据此选用Stacking作为元特征提取器.为了生成有效的元特征对后续联级Logistic模型进行特征增强,需要建立有效的Stacking集成模型和初级学习器.据此,本文选取信用风险预警问题中应用最广泛且常见集成学习方法作为Stacking中的预选初级学习器,包括XGBoost,Catboost,LightGBM,Adaboost以及GBDT模型.
极端梯度提升(XGBoost)是一种改进的梯度提升决策树模型,仅以决策树为基分类器,属于Boosting集成学习,并且可进行多线程并行运算,故而运算速度较快,在数据挖掘领域受到广泛应用.XGBoost的实质是由众多决策树集成而来,模型:
(1)

LightGBM与XGBoost的原理相似,该算法由微软提出,属于Boosting集成算法的一种.LightGBM是一种基于直方图算法的决策树,直方图将浮点型连续特征进行离散化,在直方图遍历数据后,根据直方图的离散值,通过累计必要的统计信息,寻找出最优分界点.
AdaBoost是Boosting中经典算法之一,该算法通过不断更新迭代正确、错误样本权重,能降低数据随机性波动导致的泛化错误率,使其具有较好的泛化能力[20].AdaBoost首先给样本(x1,y1),(x2,y2),…,(xn,yn)赋予同等权重1/n,然后引入分类算法构建分类模型,模型在不断迭代学习的过程中,不断更新样本的权重,每轮提高被错判样本的权重,减少正确判断的权重,以提升对分类问题中样本量较少的类别的敏感度.经过重复迭代T次后得到预测函数f1,f2,…,fT,最后经过加权投票决定,预测效果越好权重越大,反之则越小.在实际分类问题中,这就使得即使在数据集不均衡的条件下AdaBoost更偏向错判的样本,但由于其优点,也容易导致过拟合,不太稳定.
GBDT[21-22],又称MART(Multiple Additive Regression Tree),是一种基于迭代的决策树算法,属于Boosting集成的一种,该算法由多个决策树组成.和AdaBoost类似,GBDT也是重复选择一个模型并且每次基于先前的模型表现进行调整,所不同的是,AdaBoost是通过提升错分数点的权重来定位模型的不足,而GBDT是通过计算梯度来定位模型的不足,这也使得在数据集不均衡的条件下更偏向错判的样本.GBDT主要思想是通过不断迭代的方式去减少残差,并且沿着梯度方向进行不断优化来形成多个分类回归决策树,最后将得到的所有决策树的结论进行累加起来得到最终的模型,通过这种不断迭代学习的过程,从而得到较为精准的预测结果.
CatBoost,由2017年俄罗斯搜索巨头Yandex所研究,属于Boosting集成.CatBoost是基于一种对称决策树的GBDT框架,具有支持分类、精度高等优点.CatBoost主要的优点是合理进行处理类别特征,Categorical和Boosting组成了CatBoost.其次,CatBoost还解决了梯度偏差(Gradient Bias)和预测偏移(Prediction Shift)的问题,减少了过拟合现象的发生,同时使用整个数据集进行训练,对数据信息进行高效提取.
对于二分类问题.首先,CatBoost对数值特征进行二值化,即通过oblivious树为基础预测器,将浮点特征、统计信息及独热编码进行二值化.其次,将类别型特征转化为数值型特征,主要是对观测集进行随机排序生成多个随机序列、给定的某个序列利用训练集的平均标签值代替类别(对于出现次数较少的类别进行平滑处理)、利用先验的思想将分类数据转化为数值型.之后,采用“贪婪策略”进行特征组合.其中在处理梯度偏差问题方面,在确定树结构基础上计算叶子节点值,根据不同分割方式下获得的叶节点值,对获得的树进行评分,从而获得最佳分割方式,之后采用梯度或牛顿步长来逼近叶子节点值.
CatBoost实现了训练数据集与处理类特征的同步,极大提高了处理特征的效率;通过计算叶节点的算法来避免“过拟合”,提高模型的泛化性.
2.2 模型的构建
本文提出的个人信用模型构建的基本流程图,如图1所示.
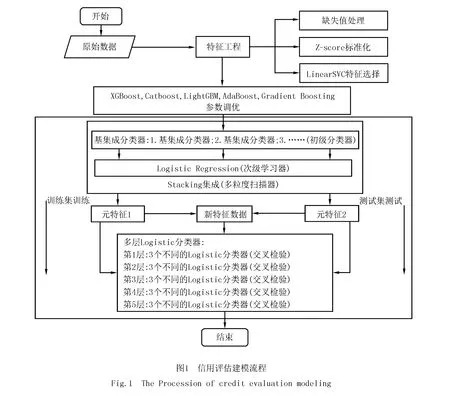
2.2.1数据预处理概述
为了降低数据集本身对于分类器的影响,对原始数据集采取预处理,包括缺失值处理、规范化处理和特征选择,其中规范化处理采用Z分数标准化(Z-Score Standardization),特征选择使用线性分类支持向量机[23](LinearSVC)方法.
2.2.2分类器设计
(1)分类器设计思路及结构说明
分层训练的训练过程采取逐层训练的方式.联级结构属于一种多层联级的训练框架,通过算法将不同层的训练结果进行结合.在前向传播设计方面,基于联级结构中后续层的分类器通过前一层的反馈进行训练,由于每层的Logistic模型自身缺乏对数据特征的学习,在进行前向传播训练中需要进行特征增强处理.受深度森林[24]构造原理启发,在联级结构外部设计基于Stacking集成的多粒度扫描器进行训练预测生成多个元特征,并组合生成新特征向量用于联级结构的起始输入训练以及元特征用于每级训练的特征增强,为避免过拟合现象的发生,每级Logistic模型均使用交叉检验.整体的分类器主要涉及两方面的结构,一是多粒度扫描器的构建,二是联级Logistic结构的构建.
(2)多粒度扫描器的构建
受卷积神经网络和深度森林[24]构造原理的启发,对原始输入特征使用基于不同随机模式Stacking的多粒度扫描方式产生联级Logistic的输入特征向量.其中,Stacking集成中初级基集成学习器选用预测性能较高的学习器,即基集成学习器作为单一学习器经过网格搜索调优后,训练预测正确率之间有着明显差异中较高得分的学习器作为初级学习器.
例如图2中所示,对于维度为的输入v数据,若采用d维滑动窗口对输入的特征进行处理,且分类标签类别数为c,通过Stacking的训练预测,最终可以得到c(v-d+1)维度特征向量.在实验中,通过对滑动窗口维度的设置,从而最终可以得到不同粒度的特征向量.
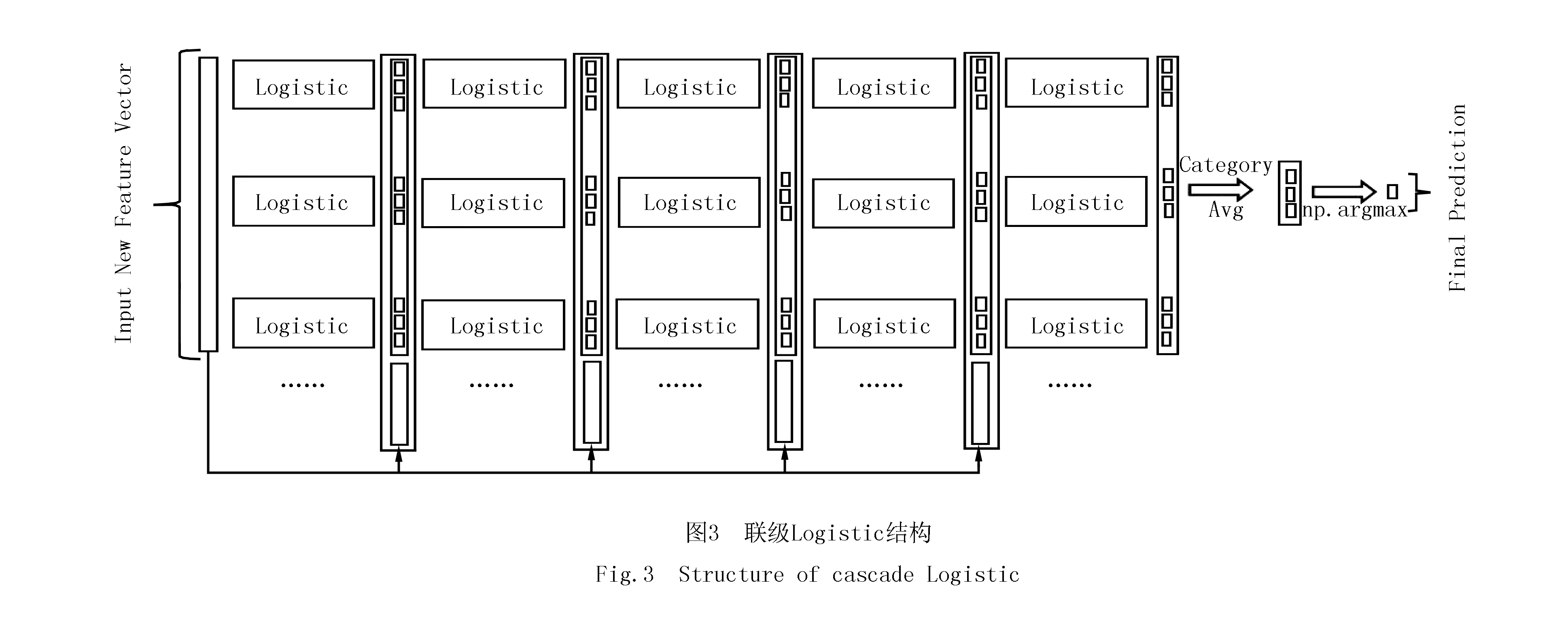
(3)联级Logistic结构的构建
受多层感知器神经网络[25](MLP)的构造原理启发,类似于神经网络中对输入特征经过每层以sigmoid激活函数的多个神经元进行训练,从而构造联级Logistic.在联级Logistic中,每一级都包含多个不同随机模式的Logistic,由多粒度扫描器产生的元特征对每级训练前进行特征增强,使得每经过一级的训练,预测准确率都有明显提升.为了防止过拟合现象的发生,每级中的不同Logistic均进行交叉检验.整个构造原理如图3所示,联级Logistic的级数可以进行自定义,每一级Logistic学习输入特征向量的信息,经过处理后传输到下一层,每一级中Logistic均采取自适应惩罚系数进行调节,同时对于起初某些不太均衡的数据集可由Logistic自身class_weight参数设置进行微调,并且每级结束后均进行预测估计.与此同时,设定了早停机制,即每级相比上一级预测效果没有显著提升,不必增加层级的深度,终止训练过程.

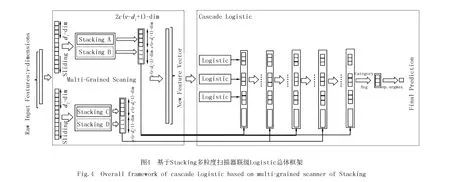
(4)总体结构
图4是基于Stacking特征增强多粒度联级Logistic的总体框架,若输入特征为v维,分类标签种数为c,多粒度扫描器模块具有2个滑动窗口,经过第一个单位滑动维度为d1的多粒度扫描器和第二个单位滑动维度为d2的多粒度扫描器,最终可以得到维度为2c(2v-(d1+d2)+2)的特征向量作为联级Logistic的第一级输入.每一个多粒度扫描器除了生成联级Logistic的开始输入,还交替用于每级Logistic训练前的特征增强,经过每级的训练,不断重复这一过程,直到预测性能达到最优.
3 信用评估实验
3.1 评价指标构建
在分类算法中,常见的分类指标有准确率(Accuracy)、精准率(Precision)、召回率(Recall)、真正例率TPR(True Positive Rate)、假正率FPR(False Positive Rate)、ROC(Receiver Operating Characteristic)曲线和AUC(Area Under Curve)[26-28]等,这些指标都是由混淆矩阵(Confuse Matrix)中的真正类TP(True Positive,TP)、假负类FN(False Negative,FN)、假正类FP(False Positive,FP)和真负类TN(True Negative,TN)计算得来.
准确率(Accuracy,简称为A)表示预测正确的概率:
(2)
精确率(Precision,简称为P)表示正确预测为正样本(TP)占所有预测为正样本(TP+FP)的比重:
(3)
召回率(Recall,简称为R),也称灵敏度(Sensitivity,简称为S),表示正确预测为正样本(TP)占所有真实正样本(TP+FN)的比重:
(4)
由式(3)和(4),可以发现精确率和召回率之间是具有相互的影响,为了同时兼顾二者,并且在尽可能提高精确率和召回率的同时,减少二者之间的差异,故此引入F1-score:
(5)
真正率与召回率公式相同,都表示正确预测为正样本占所有预测为正样本的比重:
(6)
假正率指的是错误预测为正样本占所有真实为负样本的比重:
(7)
ROC曲线是对整个分类器性能测试的一种可视化,通过曲线的形式来描述出真正例率与假正例率之间的变化关系.一个好的预测分类器往往尽可能靠近ROC曲线的左上角,越靠近左上角,表示分类器的性能越好.另外,为了更好量化ROC曲线所体现出的测试性能,可用ROC曲线下方的面积即AUC值来表示整个模型的性能表现.
3.2 数据预处理
在信用评估模型中,融资者(借款人)的个人信息一般包括贷款金额、期限、年龄、职业、贷款用途以及还款记录等数据.由于数据集中包含许多缺失数据、类别型数据等,同时为降低后期训练预测模型的复杂度,提升其正确率,因此需要在建模前进行对数据预处理.在填补缺失值方面,对于连续性数据采取均值进行填补,类别型数据用众数进行填补,并对其进行编码转化成数值型.在特征提取方面,采取线性支持向量机(LinearSVC)进行特征选择.
实验中所使用的数据集来自机器学习开放数据集网站[29](UCI Machine Learning Repository)中的德国信用数据集,Kaggle网站上的公开P2P平台Lending Club的贷款数据集[30]以及信用卡数据集[31](Credit Card Approval Prediction).其中,为了更加符合现实业务需要,并且由于数据量大,故将Lending Club数据类别标签进行规整分类,对Fully Paid和Current归结为正常还款类,对Late(31~120 d),In Grace Period以及Late(16~30 d)归结为延期贷款类,对Default和Charged Off归结为糟糕贷款类,并对数据进行下采样处理.表1所示为各样本数据分别经预处理后得到的实验数据及其相关数据属性.

表1 实验中的样本数据集
3.3 实验与结果分析
为了证实所构建模型的有效性,本文根据前期预选的初级学习器,在不同数据集上进行信用评估实验,构建基于各预选初级学习器的模型和Deep_Logistic模型.其中,Deep_Logistic模型的构建(由图4知),首先针对每种数据,Stacking多粒度扫描器滑动窗口均可设置成原始数据特征v维和v-1维,联级Logistic级数可均设置为5级;其次,根据基于各预选初级学习器的模型训练预测情况,确定Stacking多粒度扫描器的基学习器,再来构建Deep_Logistic模型.最后以Lending Club数据集为例,与近几年文献中在此数据集上所提信用评估模型上的表现进行对比.每个数据集上,在进行联级Logistic过程中交叉检验均采取5折,以确保实验结果的稳定性、可靠性.
(1)德国信用数据集实验
表2~6所示是各单一集成学习器在德国信用数据集上的参数调优结果.
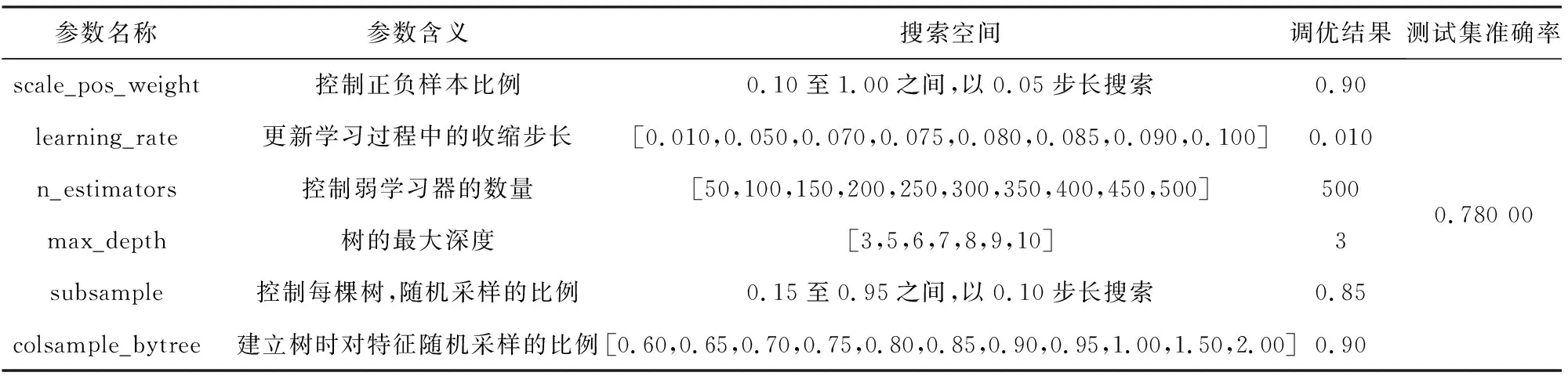
表2 德国信用数据集上XGBoost参数调优结果

表3 德国信用数据集上CatBoost参数调优结果
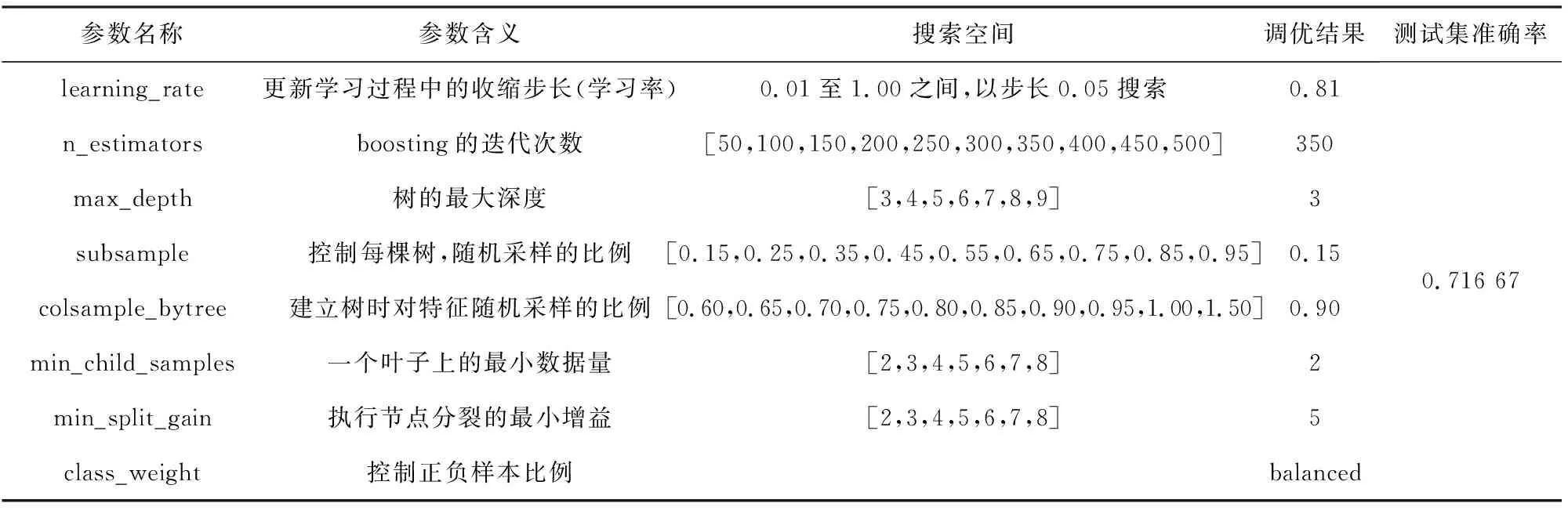
表4 德国信用数据集上LightGBM参数调优结果
由表2~6可知每一学习器在测试集上的预测准确率,确定Stacking多粒度扫描器的构建,其涉及初级学习器有XGBoost,CatBoost.构建Stacking,如表7所示.

表5 德国信用数据集上AdaBoost参数调优结果
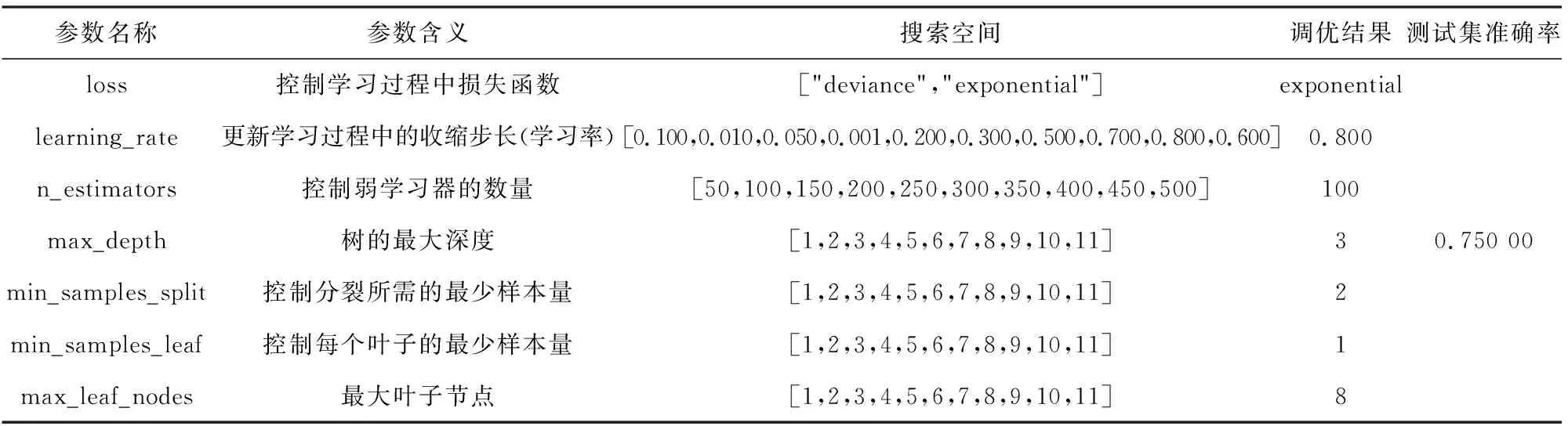
表6 德国信用数据集上GBDT参数调优结果

表7 德国信用数据集上Stacking多粒度扫描器构建
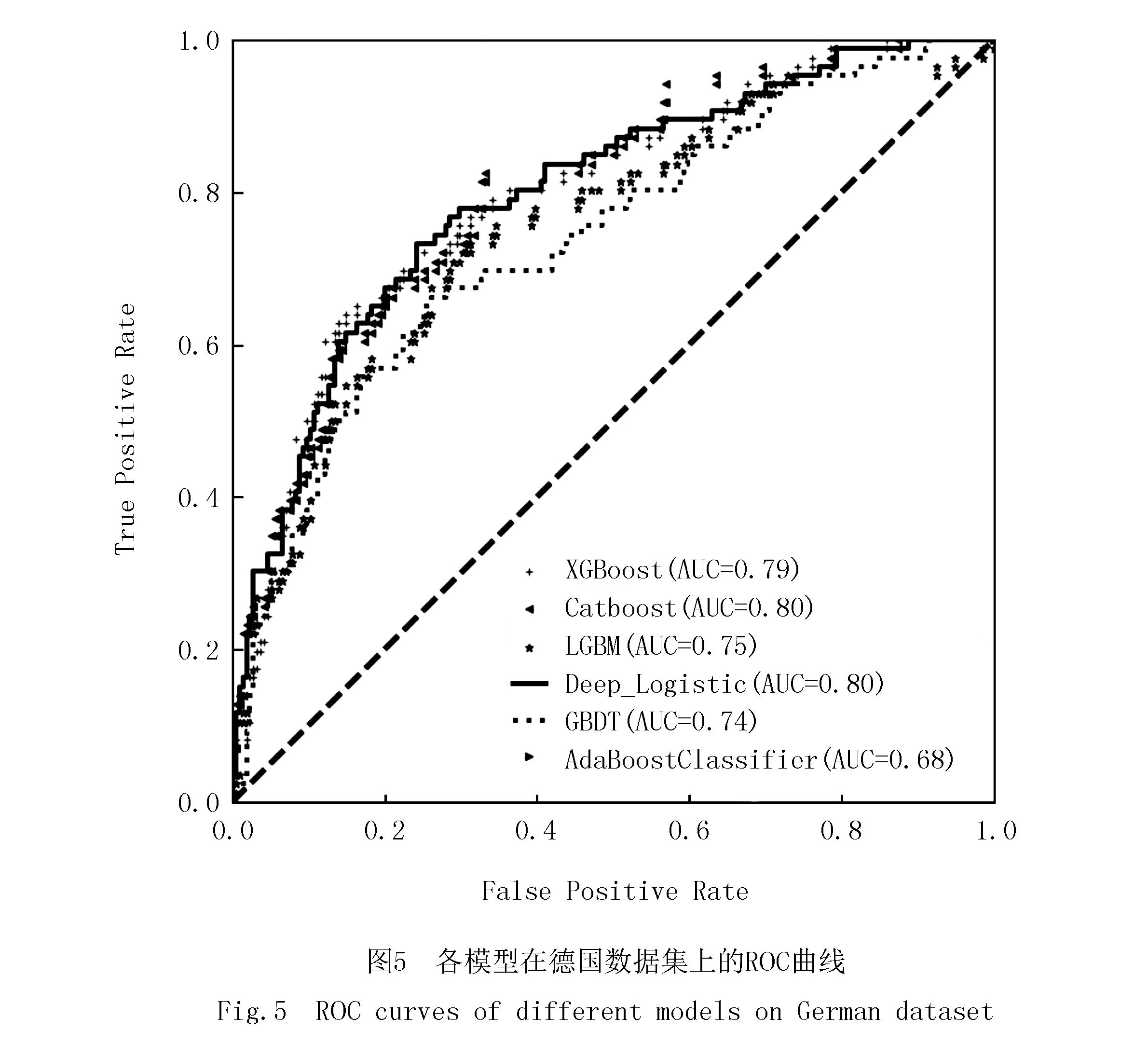
表8和图5是分别使用预选初级学习器XGBoost,Catboost,LightGBM,Adaboost以及GBDT模型与该文所提Deep_Logistic模型在德国信用数据集上的比较,表9是Deep_Logistic模型中联级Logistic每级训练最优参数表.
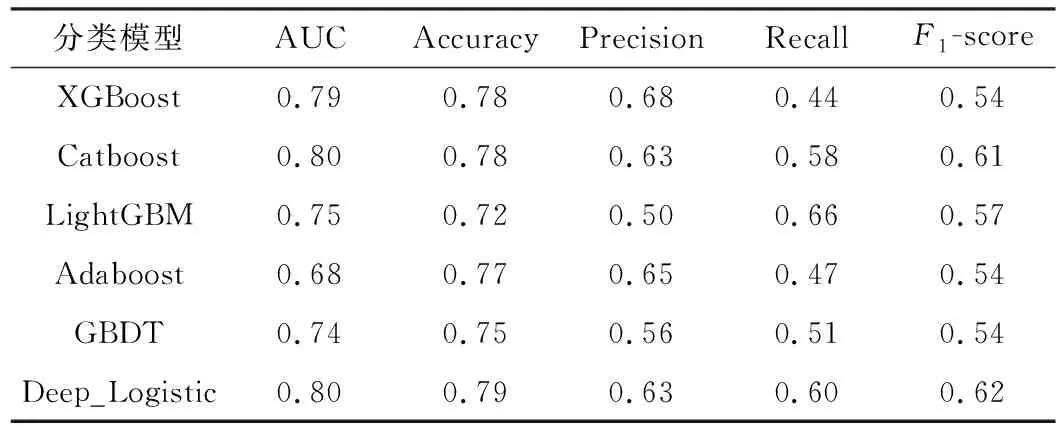
表8 各模型在德国信用数据集上的结果
(2)信用卡数据集实验和Lending Club数据集实验
为了更好地进行有效对比实验,设置在信用卡和Lending Club数据集上的各分类预测器参数配置、寻优方法、Deep_Logistic模型构建方法均与在德国信用数据集上处理方式相同,并且采取一样的参数搜索范围.最终确定信用卡数据集上Stacking多粒度扫描器的构建,其涉及初级学习器有XGBoost,CatBoost,Lending Club数据集上Stacking多粒度扫描器的构建,其涉及初级学习器有XGBoost,LightGBM和CatBoost.由此可得各模型在信用卡、Lending Club数据集上的预测性能对比,如表10所示.表11是在信用卡数据集和Lending Club数据集上联级Logistic每级训练最优参数表.
由表8和图5可知,在德国信用数据集中,Deep_Logistic的AUC值为0.80,与CatBoost同排名第一,比排名第二的XGBoost高出1%,比第三的LightGBM高出5%;Accuracy值为0.79,也为最高,超过排名第二的XGBoost和CatBoost模型1%,比排名第三的AdaBoost高2%;F1-score值为0.62,也为最高,比排名第二模型CatBoost高1%,比排名第三模型LightGBM高5%;相比于构建Stacking初级学习器中XGBoost和CatBoost模型,灵敏度达到60%,有着明显提升.因此,在德国信用数据集中,Deep_Logistic效果最好.
表9表示的是,在德国信用数据集上训练Deep_Logistic模型时,每级Logistic的最优参数.根据早停机制,最优级数为1,并且最优参数自适应惩罚系数C为0.01.

表9 德国信用数据集,每级Logistic最优参数

表10 各模型在信用卡、Lending Club数据集上的结果
由表10可知,在信用卡数据集中,Deep_Logistic的AUC值为1,处于较好水平;Accuracy值为0.999 735,也为最高,超过排名第二的XGBoost模型0.000 398,比排名第三的CatBoost和GBDT高0.000 531;F1-score值为0.999 867,也为最高,相比排名第二模型XGBoost高0.000 2,比排名第三模型CatBoost和GBDT高0.000 267;相比于构建Stacking初级学习器中XGBoost和CatBoost模型,灵敏度达到0.999 734,处于最优;Precision值为1,与CatBoost同排名第一,处于最优.因此,在信用卡数据集上,Deep_Logistic效果最好.由表11可知,训练Deep_Logistic模型,得最优级数为1,最优参数自适应惩罚系数C为0.01.

表11 在信用卡、Lending Club数据集上每级Logistic最优参数
Lending Club数据集实验,由上表10可知,在Lending Club数据集中.Deep_Logistic的AUC值为0.956 724,排名第一,超过排名第二的CatBoost模型0.063 266,比排名第三的XGBoost模型高0.063 404;Accuracy值为0.861 221,排名第一,超过排名第二的CatBoost模型0.001 583,比排名第三的XGBoost高0.001 6;Precision值为0.860 335,排名第一,超过排名第二的CatBoost模型0.001 784,比排名第三的XGBoost高0.001 963;Recall值为0.860 610,排名第一,超过排名第二的CatBoost模型0.001 938,比排名第三的XGBoost高0.002 034;F1-score值为0.858 873,排名第一,超过排名第二的CatBoost模型0.001 548,比排名第三的XGBoost模型高0.001 73.因此,在Lending Club数据集上,Deep_Logistic效果最佳.由表11可知,训练Deep_Logistic模型,得最优级数为2,且每级的最优参数自适应惩罚系数为0.1.
(4)与相关文献方法对比实验
在近两年信用评估领域中同样有在基于现有机器学习模型进行改进的模型的应用研究,在表12中对文献[14]中引入到信用评估领域的经典“手写数字”识别模型LeNet-5、文献[24]中引入到借款人信用评估研究的深度森林模型、本文所提Deep_Logistic模型,使用信用评分模型中常用评价指标进行综合对比分析.由于在两篇文献中没有涉及德国信用数据集与信用卡数据集上的实验,因此只在Lending Club数据集上进行对比实验.

表12 Deep_Logistic模型与相关文献模型效果对比
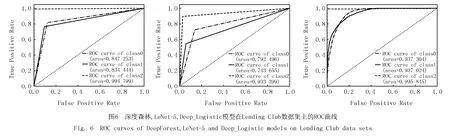
从表12可以看出,Deep_Logistic模型的 AUC 值在Lending Club数据集中是最高的,Accuracy值也都表现不错,明显优于LeNet-5和深度森林模型,在精准度和敏感度方面也比较突出.图6是深度森林,LeNet-5,Deep_Logistic模型在Lending Club数据集上的ROC曲线,综合分析可知,明显可以发现Deep_Logistic模型下ROC曲线更接近左上角(0,1),一定程度上可说明模型性能较好.
结合表8、表10中的各项评价指标可看出:
(1)在常用信用评估方法中,XGBoost和CatBoost进行信用风险评估的效果较好;
(2)在各数据集上,Deep_Logistic相比于构成其Stacking多粒度扫描器的初级学习器中各基评估器,表现更加稳定,信用评估效果要更好,可有效地融合各基评估器的预测性能,提高模型的整体信用评估效果.
4 结束语
本文的目的在于设计一种基于集成学习,拥有联级结构,能融合多个单一集成学习器的分类器,从而有效提出进行贷款和不贷款的策略性建议,辅助P2P平台及相关贷款人提供一种解决方案.本文基于Stacking特征增强多粒度联级Logistic模型对借款人进行信用风险评估,在德国信用数据集、信用卡数据集和Lending Club数据集基础上进行分类预测,同时将其与XGBoost,CatBoost,LightGBM,GBDT以及AdaBoost模型分类方法进行对比,并且用该Lending Club数据与文献中LeNet-5,深度森林方法也进行对比.实验表明,所提方法在3个数据集上表现出的性能均优于其他对比方法,并且也较优于文献中方法.从以上实验中可以发现本文分类器可应用于二分类、三分类问题,理论上也可应用于多分类任务中.但是,由于本文方法中联级部分仅使用Logistic 模型,同时在构建Stacking多粒度扫描器方面,初级学习器中的基评估器种类数量和生成多粒度的滑动窗口维度的增加,会增加模型的整体复杂性,在之后的研究中可以尝试使用更多的分类器作为联级结构的组成部分,如SVC,KNN等,并且探索出更优的方法对于Stacking初级学习器中的基评估器种类数量的选择,以及对最佳的滑动窗口维度的选择.为了进一步尝试使用到其他数据集进行实验应用,从而将本文方法应用于信用评估领域的相关其他方面,并尝试探索联级结构中学习器的数量与预测结果之间的关系以及相互影响,以确保整体的预测模型取得更佳效果.
猜你喜欢
粉末冶金技术(2021年3期)2021-07-28 06:26:16
南京大学学报(自然科学版)(2021年1期)2021-01-30 14:01:04
公民与法治(2020年20期)2020-11-27 01:44:42
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
中国外汇(2019年9期)2019-07-13 05:46:30
数学物理学报(2017年5期)2017-11-23 07:51:31
中国设备工程(2017年7期)2017-04-10 08:09:12
系统工程与电子技术(2016年12期)2016-12-24 07:19:14
瞭望东方周刊(2016年45期)2016-12-07 16:03:39
