
基于功率归一化倒谱的端点检测
2023-05-23 19:56高磊章小兵
无线互联科技 2023年6期
高磊 章小兵


基金项目:安徽工业大学产学研基金资助重大项目;项目编号:RD14206003。
作者简介:高磊(1997— ),男,安徽合肥人,硕士研究生;研究方向:测控技术与语音识别。
*通信作者:章小兵(1972— ),男,安徽芜湖人,教授,博士;研究方向:测控技术与语音识别。
摘要:传统的端点检测在低信噪比(SNR)非平稳噪声下性能会失效,因此文章提出了将最优改进的对数譜幅度估计(OMLSA)以及最小控制递归平均算法(IMCRA)相结合的方法对包含噪声的语音指令进行去噪处理,提取PNCC的第一维静态特征作为特征参数。同时,文章在单参数双门限法的基础上设计了一个自适应阈值,可以更好地跟踪预测实际语音的起始与终止端。Matlab仿真结果显示,该算法在各种非平稳噪声下比经典算法优势更大。
关键词:端点检测;最优改进的对数谱幅度估计;最小控制递归平均算法;PNCC;自适应阈值
中图分类号:TN912.3 文献标志码:A
0 引言
语音端点的检测准确度是语音识别精度中最关键的一步。它的功能是把被背景噪声覆盖的语音提取出来,确定语音的开始和结尾。针对端点检测的方法,人们研究出了模型匹配和特征提取两大类。模型匹配方法对计算机的性能是一个考验,消耗时间长,实际情况下用处不大。特征提取方法时域、频域、时频域的结合可以优势互补,应用较为广泛。张毅等[1]在子带谱熵的基础上结合了子带能量,两者做比值处理,拉开语音片段与噪声片段差距,解决了子带谱熵的不稳定性问题,添加中值滤波去除参数波形中不稳定的毛刺,该算法计算简单、快速高效,更易检测出语音的端点。朱春利等[2]基于LMS自适应滤波降噪,选择合适的窗长计算短时能量,改进过零率拉开静音与噪声的差距,之后中值平滑去除LMS残留野点,更能反映原始语音信号的特征。目前,这些方法在高信噪比环境下可以稳定运行,但是在非平稳环境下不再生效,判断端点仍不能达到人们的满意度。
本文首先利用最小控制递归平均算法来跟踪噪声的实时变化,其次用最优改进的对数谱幅度估计算法增强语音重建语音质量,最后提取PNCC的第一维静态特征作为端点检测的参数。在检测过程中,本文基于VAD的原理设计出自适应根据特征参数变化的阈值,为更加精确地定位语音提供帮助。
1 最优改进对数谱幅度估计(OM-LSA)
为了有效地抑制非平稳声,引入基于统计模型的单通道语音增强方法,可以显著地减少残留噪声,提高了增强语音的质量。
其中,y(t)表示带噪语音,x(t)表示纯净语音,d(t)表示不相关的噪声,其中t表示离散时间指数。两边同时做离散傅里叶变换:
其中,k表示频域分量索引,l表示帧的编号索引。为了使估计出来的纯净语音频谱幅度X^(k,l)与实际纯净语音X(k,l)接近,需要计算自适应频谱滤波器增益函数:
自适应滤波器增益为:
其中,GH1(k,l)表示对数谱幅度增益,p(k,l)表示语音存在条件概率,Gmin表示最小增益经验值起到抑制音乐噪声的作用[3]。
2 基于PNCC的端点检测
2.1 PNCC特征
PNCC是一种在抗噪声和混响下有很大优势的语音特征,能够在不影响识别能力和运算复杂性的前提下,通过长时间帧功率分析有效地消除背景噪声的影响[6]。
PNCC特征参数公式:
其中,B表示PNCC维数,n表示PNCC维数的索引。
近几年,美国科学家Kim等[7]提出功率归一化倒谱系数(PNCC)将其运用于语音增强算法。参考吴新忠等[5]提取MFCC0的优秀效果,本文取PNCC的第一维参数PNCC1用于端点检测任务。
2.2 自适应阈值
外界噪声的变化会带动特征参数的变化,因此将特征参数与阈值联系起来才能适应环境的变化。将PNCC1特征参数的前几帧进行平均得到的PNCCN作为初始阈值:利用对数谱距离(VAD)式(14)判定当前帧是否语音帧,若为语音帧(NF=0),则阈值不变,若为非语音帧(NF=1),则依据下式(15)对阈值进行更新得到PNCCnew:
其中,NoiseCounter是累计的无语音段长度,NoiseMargin是语音段与无语音段之间的最小距离,设为2.5,Hangover是最小的无语音段长度,设为8。
T1,T2分别是双门限法的高低门限值,如图1所示,横虚线T1是高阈值,横曲线T2是低阈值。竖实线S、竖虚线E是检测出来每一段语音的起始端点。若PNCC1(i)>T1则一定是语音段,从PNCC1(i)与T1的交点分别向两边扩展,将PNCC1(i)与T2的交点作为语音段的起始点位置。相对于传统的双门限法本文注重于细节上的追踪,传统的双门限法T2是一条固定的直线,不能及时应对特征参数波形突变从而导致的误判现象。
3 实验与分析
3.1 实验装置
笔者用高保真麦克风在安静的房间里录音,数据存储格式为8 000 Hz、16 bit的wav文件,此次实验中录制的纯净语音为“你好悠悠,导航去安徽工业大学”,长度为6 s,将Noisex-92标准噪声库中的白噪声、pink噪声、f16噪声和factory噪声分别生成-3,0,3 dB 3个不同的水平,再添加到干净的语音文件中,然后将合成的语音用于端点检测。信号分帧每帧长设为200个样本,帧移为80个样本,两个连续帧的重叠为120个样本,窗口函数为汉明窗。
在Windows 10操作系统下,本文在实验平台Matlab2013a上进行一系列的实验来评价所提算法的有效性,将其与近几年的语音端点检测经典算法进行比较,分别是张毅等[1]、陈昊泽等[8]、朱春利等[2]。
3.2 与经典算法的性能比较
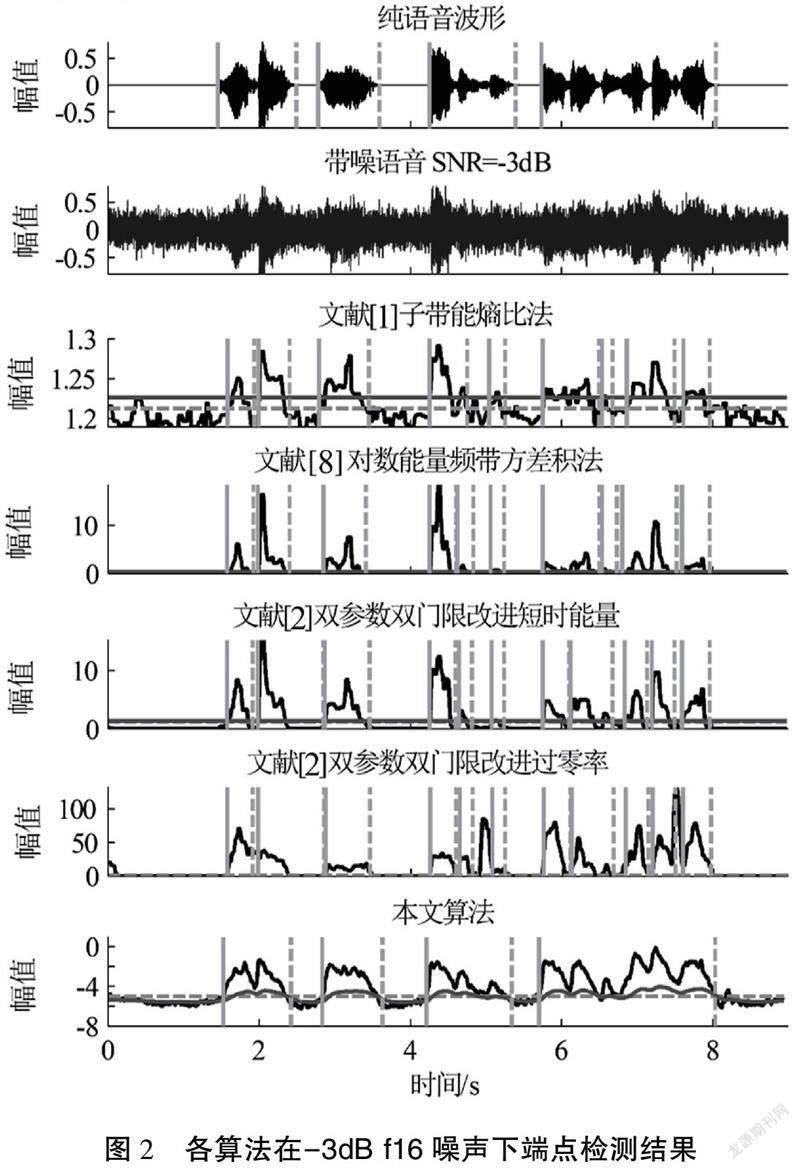
如图2所示,在纯净语音波形上分别用竖实线和竖虚线标记了每一段真实语音的起点和终点,在-3dB f16、factory环境中测试了上述不同的端点检测方法。
如图2所示,张毅等[1]提出的子带能熵比虽然通过双参数比值的方法拉开语音与噪声特征的差距,但是周围产生了大量的尖端毛刺破坏了语音特征,这是导致把噪声误判为语音的关键。
如图3所示,在不规律的factory噪声下,噪声的特征掩盖住语音本身的特征,扰乱原始语音的成分,使得子带能熵比算法失效。
陈昊泽等[8]提出的对数能量频带方差积法虽然与张毅等[1]提出的方法原理相似,但是在图2、图3中均表现出能量弱的语音处两参数做乘积处理会使得能量大处的语音特征幅值更大,能量小处的语音特征幅值更小的特性,因此若阈值选择过小,从而使得弱语音处特征与噪声齐平,导致误判,若阈值选择过大,又会有漏检的错误。朱春利等[2]提出的LMS自适应滤波在非平稳噪声下降噪,前端都会有延迟噪声,残余噪声在图2中表现出过零率前端突出,不可避免地带来了误差,并且双参数双门限法能量和过零率参数对于表达语音的特征自身缺乏抗噪性和鲁棒性,不能有效区分语音和非语音。
本文提出基于IMCRA的高斯统计模型语音增强方法对于被平稳和非平稳的噪声污染的语音在重建语音质量上都有显著的改善,极大地帮助了后续端点特征的提取工作。如图2、图3中本文算法特征参数相较于其他3种算法整体波形平缓,相差大的语音能量通过本文的特征提取也可以达到上下幅值差距不大,语音段幅度遠高于噪声段幅度,这样也避免了阈值的选择带来的困惑,最后自适应的阈值也会随着特征参数的变化而实时更新门限,相比学者[1-2,8]中固定的阈值在语音的开始端和结束端都会有一个上升或下降的趋势,此系统对所有环境下语音的泛化和应变能力得到了提升。
4 结语
经模拟实验得到验证,不管在多么严峻的平稳或非平稳的噪声场景下,相比于经典算法,本文构造的改进方法都能最大限度地保证它必须具有的实际的语音成分,具有判断端点误差度量小和检出率高的优势。此算法对于语音识别前端的预处理项目有一定的参考价值,但是依旧存在不足,一方面如何对算法进行进一步的优化以满足更加复杂的环境,另一方面保持算法精度的同时降低计算量、缩短运算时间是本文接下来要做的工作。
参考文献
[1]张毅,王可佳,席兵,等.基于子带能熵比的语音端点检测算法[J].计算机科学,2017(5):304-307.
[2]朱春利,李昕.基于LMS减噪与改进的双门限语音端点检测方法[J].系统仿真学报,2017(9):1950-1959,1967.
[3]WANG J,YAN L,TIAN J,et al.Speech enhancement algorithm of improved OMLSA based on bilateral spectrogram filtering[J].Journal of Intelligent & Fuzzy Systems,2020(5):6881-6889.
[4]张建伟,陶亮,周健,等.基于改进谱平滑策略的IMCRA算法及其语音增强[J].计算机工程与应用,2017(1):153-157.
[5]吴新忠,夏令祥,张旭,等.基于谱熵梅尔积的语音端点检测方法[J].北京邮电大学学报,2019(2):83-89.
[6]WANG N,HE M,SUN J,et al.Ia-PNCC:noise processing method for underwater target recognition convolutional neural network[J].Computers,Materials & Continua,2019(1):169-181.
[7]KIM C,STERN R M.Power-normalized cepstral coefficients(PNCC)for robust speech recognition[J]. IEEE/ACM Transactions on Audio,Speech,and Language Processing,2016(7):1315-1329.
[8]陈昊泽,张志杰.基于能量和频带方差结合的语音端点检测方法[J].科学技术与工程,2019(26):249-254.
(编辑 王雪芬)
Abstract: The performance of traditional endpoint detection will fail under low SNR non-stationary noise. Therefore, this paper proposes a method combining the optimal improved logarithmic Spectral Amplitude Estimation (OMLSA) and the Minimum Control Recursive Averaging algorithm (IMCRA) to denoise speech commands containing noise. The first dimension static features of PNCC are extracted as the feature parameters.At the same time, an adaptive threshold is designed based on the single-parameter double-threshold method, which can better track and predict the start and end of the actual speech. Matlab simulation results show that the proposed algorithm has more advantages than the classical algorithm under various non-stationary noises .
Key words: endpoint detection; OMLSA; IMCRA; PNCC; adaptive threshold
猜你喜欢
数学物理学报(2022年2期)2022-04-26
汽车实用技术(2022年4期)2022-03-07
空间电子技术(2021年4期)2021-11-10
中国西部(2021年4期)2021-11-04
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
电子制作(2019年22期)2020-01-14
数学物理学报(2017年1期)2017-06-05
系统工程与电子技术(2016年2期)2016-04-16
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
湖湘论坛(2015年3期)2015-12-01
