
基于轻量级卷积神经网络的小样本虹膜图像分割
2023-05-21 03:53林大为刘元宁朱晓冬
吉林大学学报(理学版) 2023年3期
霍 光,林大为,刘元宁,朱晓冬,袁 梦
(1.东北电力大学 计算机学院,吉林 吉林 132012; 2.吉林大学 计算机科学与技术学院,长春 130012; 3.吉林大学 符号计算与知识工程教育部重点实验室,长春 130012)
虹膜识别可用于安防、国防和电子商务等领域[1],具有方便、稳定、独特等特点.虹膜识别系统包括虹膜图像采集、预处理、虹膜分割、虹膜归一化、虹膜特征提取和虹膜匹配验证[2].虹膜分割的精度直接影响虹膜图像识别的准确率.目前虹膜分割方法主要分为传统的分割方法和基于卷积神经网络的分割方法.
传统的虹膜分割方法主要包括基于Hough变换的算法[3]和基于梯度微分的算法[4].许多后续的传统算法都使用微积分算子变体[5]和Hough变换变体[6]定位虹膜边界.传统方法不需要大量的图像样本训练模型参数,但在非理想的拍摄条件下,采集的虹膜图像可能包含了光斑、睫毛遮挡、眼睑遮挡等噪声,这些噪声会严重影响虹膜识别的准确率.
为解决传统方法的不足,虹膜分割领域开始结合卷积神经网络方法,并取得了较好的成果.目前,大部分虹膜分割模型使用FCN(fully convolutional networks)[7]和UNet(U-shaped networks)[8]作为基准网络.为提高模型的鲁棒性,Chen等[1]提出了一种基于FCN和密集连接块相结合的架构,虽然该模型有效降低了无关噪声对模型的干扰,但该模型的可训练参数高达142.5×106.随着神经网络的加深,需要学习的参数也会随之增加.当数据集较小时,过多的参数会拟合数据集的所有特点,并非数据之间的共性,从而导致过拟合现象.因此,复杂的虹膜分割算法无法在小样本数据库上最大限度地发挥卷积神经网络的性能.
目前解决小样本学习主要通过数据增强和减少网络参数两种方法.数据增强是对原始数据采用缩放、裁剪、平移等方式增加训练集的数量.该方法应用于深度学习中的各领域.但在虹膜分割领域,使用数据增强后的数据集训练网络不仅不能提升模型的拟合能力,还会大幅度增加模型的训练时间.因此,减少网络参数已成为解决小样本虹膜分割的主要方法.Huo等[2]和周锐烨等[9]通过使用轻量级网络替换传统卷积的方法减少网络参数,虽然该方法可明显减少网络的参数量,但这些分割模型的可训练参数仍超过2×106.因此,如何在少量数据库上训练好模型的参数,是小样本虹膜分割面临的挑战.基于此,本文提出一个适用于小样本数据集的虹膜分割模型.
1 网络模型的设计
1.1 整体结构设计

图1 本文模型的整体网络结构Fig.1 Overall network structure of proposed model
本文网络模型的整体结构如图1所示,模型的实现细节列于表1.网络模型由编码器、解码器和注意力机制组成.编码器用于提取虹膜图像的特征信息,解码器用于将特征信息转化为语义信息.
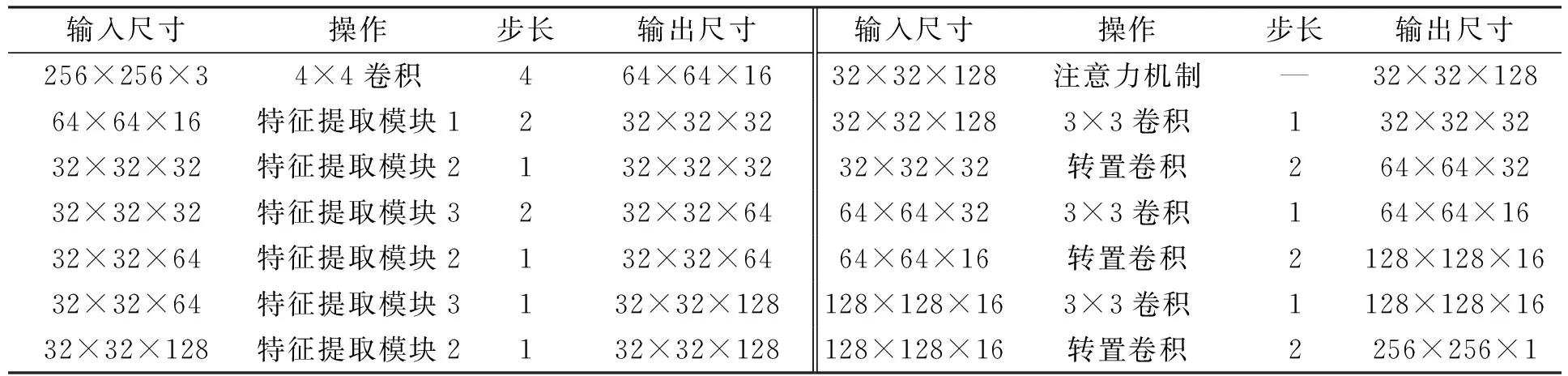
表1 本文模型结构实现细节
1.1.1 编码器
输入图像首先经过4×4卷积层,其卷积核的数量为16,步长为4.在网络下采样后期阶段使用传统的3×3卷积层和5×5卷积层会引入大量的模型参数.深度可分离卷积通过采用逐通道卷积和逐点卷积执行卷积运算.在网络中使用深度可分离卷积能在保证特征提取能力的前提下,大幅度降低网络的可训练参数.本文基于深度分离卷积设计3个特征提取模块: 特征提取模块1~3.特征提取模块结构如图2所示.模块1由两个深度可分离卷积层和两个1×1卷积层组成.其中第一个1×1卷积层用于减少特征图的通道数,第二个深度可分离卷积层用于缩小特征图的宽和高为原来的1/2.因为模块2输出特征图的维度与输入特征图的维度一致,所以输入特征图与输出特征图通过相加操作进行融合.通过这种连接可有效减少梯度消失问题.模块3输出的特征图维度在高度和宽度方向保持不变,深度方向增加.通过增加网络的深度可学习到更丰富的特征信息.网络通过两次下采样操作将特征图变为原来的1/16.

图2 特征提取模块的设计Fig.2 Design of feature extraction module
1.1.2 注意力机制
注意力机制由空间注意力机制和通道注意力机制组成.空间注意力机制用于增加模型的感受野,提取更丰富的上下文特征信息; 通道注意力机制用于增加模型对虹膜区域通道的学习能力,降低对无关噪声的响应能力.
1.1.3 解码器 特征图通过一系列的卷积层和转置卷积层逐步恢复到原始尺寸.3×3卷积层用于将提取到的特征信息转化为语义信息,转置卷积用于增大特征图的宽和高为原来的2倍.为减少特征信息丢失,编码器通过跳跃连接与解码器相连.预测的分割图为二值图像,其中1表示虹膜区域,0表示非虹膜区域.
1.2 注意力机制
在非理想条件下拍摄的虹膜图像可能会包含大量无关噪声.随着下采样次数的增加,虹膜图像的空间特征信息会逐渐丢失.这些都会影响虹膜分割的准确率.为解决上述问题,本文在编码器和解码器之间加入了通道和空间注意力机制,该模块的结构如图3所示.输入模块的特征图维度为H×W×C,其中H,W,C分别表示特征图的宽、高和通道数.

图3 注意力机制模块结构Fig.3 Attention mechanism module structure
空间注意力机制: 先输入特征图通过1×1卷积层将特征图的通道数压缩到1; 然后输出的特征图通过Sigmoid激活函数得到空间注意力图; 最后将空间注意力图与输入特征图相乘完成空间信息的校准.
通道注意力机制: 先输入特征图通过全局平均池化得到维度为1×1×C的特征图.使用全局平均池化可帮助模型捕获全局信息,通过两个1×1卷积层对特征图进行信息处理,最终得到维度为1×1×C的特征图; 然后特征图通过Sigmoid激活函数进行归一化,对通道赋予不同的权重; 最后与输入特征图相乘,得到经过加权的特征图.
空间注意力机制输出的特征图与通道注意力机制输出的特征图通过相加操作实现信息融合.该注意力机制不仅考虑了通道和空间信息,还考虑了方向和位置信息.该模块在不明显增加参数量的条件下,将网络模型的注意力更多关注于虹膜区域.
2 实验结果及分析
2.1 数据集
实验在虹膜数据库UBIRIS.V2[10]上进行.UBIRIS.V2数据库中虹膜图像是在非合作条件下拍摄的.因为该数据库中的大量虹膜图像包含各种无关噪声,所以是最具有挑战性的公共虹膜数据库之一.本文将数据库按7∶1∶2分为训练集、验证集和测试集三部分.其中: 小样本数据库1中训练集的数量为280张,验证集的数量为40张,测试集的数量为80张; 小样本数据库2中训练集的数量为560张,验证集的数量为80张,测试集的数量为160张; 大样本数据库中训练集的数量为1 575张,验证集的数量为225张,测试集的数量为450张.
2.2 训练参数
本文实验环境基于Pytorch深度学习框架.硬件设备为NVIDIA 1080Ti GPU,11 GB显存.采用Adam优化器,初始学习率设为0.01,第一次衰减率设为0.9,第二次衰减率设为0.999.每次训练从训练集中取16个样本进行训练,选择Dice损失函数[11]训练网络.
2.3 评价指标
本文通过参数量衡量模型的复杂程度.参数量即模型的可训练参数,模型的参数量越大,训练模型所需的数据量就越大.为衡量模型的分割精度,本文选择平均交并比(mean intersection over union,MIOU)和F1得分(F1)作为评价指标,计算公式如下:

(1)

(2)
其中TP表示真阳性样本的数量,FP表示假阳性样本的数量,FN表示假阴性样本的数量,TN表示真阴性样本的数量.MIOU和F1值介于0~1之间,MIOU和F1值越接近于1表示模型的分割精度越高.
2.4 不同算法性能比较
在UBIRIS.V2数据库上,将本文算法与传统算法Caht[12],Ifpp[13],Wahet[14],Osiris[15],IFPP[16]和基于卷积神经网络的算法Linknet[17],PI-Unet[9],DMS-UNet[2]性能进行对比,结果分别列于表2和表3.基于神经网络的分割方法在3个数据库上的损失衰减曲线如图4所示.为更好观察算法的性能,本文可视化了所提方法与基于神经网络方法在小样本数据库1上的分割结果,对比结果如图5所示.

表2 本文算法与传统算法的对比结果
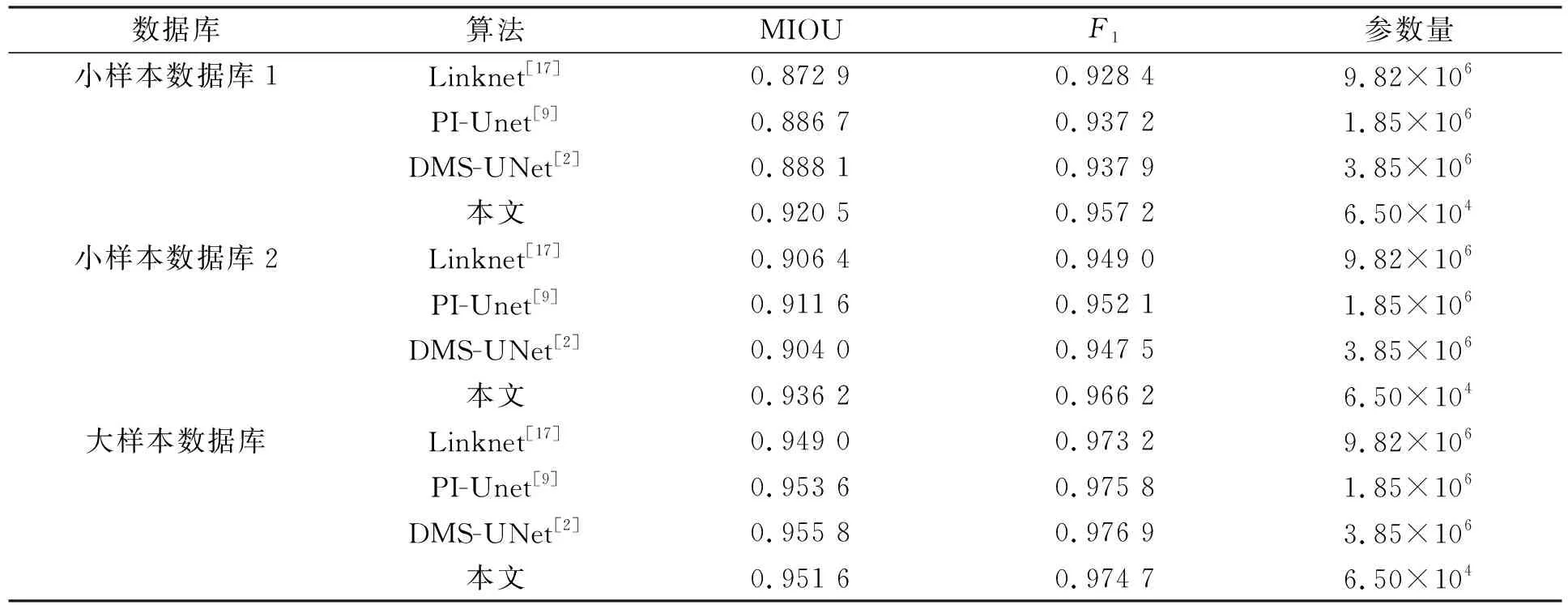
表3 本文算法与基于深度学习算法的对比结果
本文所选数据库是在非合作环境下拍摄的,因此虹膜图像中包含了大量无关噪声.实验结果表明,传统算法在非理想虹膜数据集上的表现较差,难以准确分割出虹膜边界.相比于传统算法,本文模型大幅度提高了分割精度.
损失表示模型在训练集上的预测结果与真实标签之间的误差.不同算法在小样本数据库上损失和准确率的变化曲线如图4所示.由图4可见,相比于其他算法,本文算法的损失曲线随着迭代次数的增加而快速收敛,曲线稳定,没有明显震荡,表明本文算法在小样本数据集上有效地学习了虹膜图像的特征,未发生过拟合现象.

图4 不同算法在小样本数据库上损失和准确率的变化曲线Fig.4 Variation curves of loss and accuracy of different algorithms on small sample database

图5 不同算法在小样本数据库1上的分割结果Fig.5 Segmentation results of different algorithms on small sample database 1
由图5可见,其他虹膜分割算法未准确分割出瞳孔区域.这是因为在网络执行下采样操作中,瞳孔区域特征随之丢失.因为本文算法仅采用两次下采样操作,并且加入了空间注意力机制关注虹膜区域,因此该算法可准确地分割出瞳孔区域.本文算法分割出的虹膜内外边界更平滑、像素错分率更低、分割结果更接近于真实标签.
在小样本数据库1上的结果表明,与最新的轻量级虹膜分割模型PI-Unet相比,本文算法的MIOU和F1分别提高了3.81%和2.13%; 与高性能的虹膜分割模型DMS-UNet相比,本文算法的MIOU和F1分别提高了3.65%和2.06%.本文网络在小样本数据库2上的虹膜分割精度均优于其他分割方法.
在大样本数据库上的结果表明,本文网络的分割精度略低于DMS-UNet和PI-Unet.与PI-Unet相比,本文网络的参数量下降了96.49%; 与DMS-UNet相比,本文网络的参数量下降了98.31%.DMS-UNet和PI-Unet具有更深的网络深度和更多的卷积核数量,因此这些网络具有更多的可训练参数.额外的网络参数量能存储更丰富的特征信息以增加网络的分割精度.
不同网络方法在小样本数据库和大样本数据库上的对比结果如图6所示.由图6可见,随着训练样本数量的增加,网络的分割精度也随之增加,这是因为网络参数在大样本数据库下可得到更充分的训练.本文网络在小样本数据库上的分割精度优于其他方法,在大样本数据库上取得了较好的虹膜分割精度.
2.5 消融实验
为验证注意力机制的有效性,本文将通道注意力机制模块(squeeze and expand,SE)[18]、通道-空间注意力机制模块(convolutional block attention module,CBAM)[19]、空间注意力机制模块(coordinate attention,CA)[20]与本文的注意力机制模块进行对比,其中基准网络不加任何注意力机制模块.为进行公平的比较,其他注意力机制模块与本文模块都在分割网络的编码器和解码器之间引入,不同注意力机制的对比实验结果列于表4.

表4 不同注意力机制对网络性能的影响
由表4可见,在基准网络中加入SE模块和CA模块使基准网络的MIOU值分别提高了0.64%和0.76%,在分割网络中加入CBAM模块未提高网络的分割精度.相比于使用SE模块和CA模块,本文网络的MIOU值分别提高了2.13%和2.01%.实验结果表明,本文网络的注意力机制可有效提高网络的分割精度.
为验证注意力机制融合方式的有效性,本文设计4种不同的网络结构进行消融实验,其中基准网络中不含注意力机制.本文对空间-通道注意力机制采用串联和并联两种方式融合,其中串联方式有两种: 通道注意力机制在前,空间注意力机制在后; 空间注意力机制在前,通道注意力机制在后.注意力机制不同融合方式消融实验的结果列于表5.

表5 注意力机制不同融合方式的实验结果
由表5可见,注意力机制采用串联的融合方式并不会增加网络的分割精度.这是因为不恰当的融合方式会影响特征图的数据分布,干扰特征图中有效信息的表达.相比于两种串联方式的分割精度,使用并联方式的MIOU值分别提高了3.74%和3.13%.因此本文采用并联的方式融合两种注意力机制输出的特征图.
为验证本文算法的各模块在提高虹膜分割性能方面的有效性,设计4种不同的网络进行消融实验,其中基准网络中不含注意力机制.4种网络在相同测试集上的分割精度列于表6,分割结果如图7所示.由表6可见,相比于基准网络,加入注意力机制网络的MIOU分别提高了2.12%和1.70%.在双注意力机制的作用下,本文算法获得了最高的分割精度.在不明显提升参数量的前提下,本文算法的分割精度相比于基准网络分别提升了2.78%和1.55%.

表6 不同模型的消融实验结果
不同模型基于不同模块的分割结果如图7所示.由图7可见,基准网络无法准确分割出瞳孔区域.实验结果表明,加入注意力机制可在很大程度上解决上述缺陷.基于空间注意力机制的模型虽然可分割出瞳孔区域,但预测的分割图中包含许多无关噪声.加入通道注意力机制可在训练阶段学习通道之间的相关性,抑制光斑和遮挡等无关噪声的干扰,加强虹膜区域的权重.

图7 不同模型基于不同模块的分割结果Fig.7 Segmentation results of different models based on different modules
综上所述,针对复杂网络在小样本数据集上训练易发生过拟合的现象,本文提出了一个适用于小样本数据库的轻量级虹膜分割模型.在编解码结构的基础上,设计了一个高效的特征提取网络; 空间注意力机制模块用于关注虹膜区域和提取丰富的上下文特征信息; 通道注意力机制模块用于提高模型对无关噪声的抗噪能力.消融实验结果表明了本文使用不同模块的有效性.对比实验结果表明,本文模型在小样本虹膜数据集上不仅取得了最优的分割精度,而且需要更少的模型参数.在分割结果上,本文算法能在含有噪声的虹膜图像中分割出更多的边缘细节,分割的图像更接近于真实标签.因此,本文模型在小样本虹膜数据库上具有良好的应用价值.
猜你喜欢
中国典型病例大全(2022年11期)2022-05-13
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
文萃报·周二版(2018年51期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
警察技术(2015年3期)2015-02-27
电视技术(2014年19期)2014-03-11
