
Modified Cepstral Feature for Speech Anti-spoofing
2023-05-18 14:36:52HEMingrui何明瑞ZAIDISyedFahamAliTIANMianxin田娩鑫SHANZhiyong单志勇JIANGZhengru江政儒XULongting徐珑婷
HE Mingrui(何明瑞), ZAIDI Syed Faham Ali, TIAN Mianxin(田娩鑫), SHAN Zhiyong(单志勇), JIANG Zhengru(江政儒), XU Longting(徐珑婷)*
1 College of Information Science and Technology, Donghua University, Shanghai 200051, China
2 SPIC Jiangsu Offshore Wind Power Co., Ltd., Yancheng 224001, China
Abstract:The hidden danger of the automatic speaker verification (ASV) system is various spoofed speeches. These threats can be classified into two categories, namely logical access (LA) and physical access (PA). To improve identification capability of spoofed speech detection, this paper considers the research on features. Firstly, following the idea of modifying the constant-Q-based features, this work considered adding variance or mean to the constant-Q-based cepstral domain to obtain good performance. Secondly, linear frequency cepstral coefficients (LFCCs) performed comparably with constant-Q-based features. Finally, we proposed linear frequency variance-based cepstral coefficients (LVCCs) and linear frequency mean-based cepstral coefficients (LMCCs) for identification of speech spoofing. LVCCs and LMCCs could be attained by adding the frame variance or the mean to the log magnitude spectrum based on LFCC features. The proposed novel features were evaluated on ASVspoof 2019 datase. The experimental results show that compared with known hand-crafted features, LVCCs and LMCCs are more effective in resisting spoofed speech attack.
Key words:spoofed speech detection; log magnitude spectrum; linear frequency cepstral coefficient (LFCC); hand-crafted feature
Introduction
Automatic speaker verification (ASV) is a technique or system which verifies the speaker identity from a target individual’s utterance[1]. ASV comes into practical use due to rapid development in this field. However, it faces logical or physical attacks. In order to distinguish whether one utterance is genuine or spoofed, proper detection approaches should be considered. The ASV system meets various attacks in which the logical attacks are directly introduced to speech signals, and physical attacks are mostly introduced by a receiver device like microphones[1-2]. As a result, both of these attacks can put the ASV system at risk. This risk leads researchers to concentrate on speech detection modules. Increasingly, researchers have been focusing on speech detection techniques[3-9]since the ASVspoof 2015 challenge appears[1-2]. A speech anti-spoofing system typically consists of front-end feature extraction and a back-end classifier[11-18].
In order to ensure the security of the ASV system and resist the attack of spoofed speeches, it is essential to create appropriate countermeasures. Many countermeasures have been developed in response to the ASVspoof 2019 challenge[8]. Here logical access (LA) database which concentrates on spoofed speeches synthesized by using speech synthesis (SS) and voice conversion (VC) approaches is explained. In SS attack, the fraudster generates a spoofed speech of the particular speaker by tuning the speech synthesizer and afterwards broadcasts it to the ASV system to get access. In VC attack, the speech of the parent speaker is transformed to the speech of the particular speaker by an algorithm. Feature extraction modules can be deployed in LA database, such as Mel frequency cepstral coefficients(MFCCs), modified group delay function (MGDF)[13], cosine-normalized phase features, fused magnitude and phase features, relative phase shift (RPS) features[13], constant-Q cepstral coefficients(CQCCs)[14], inverted Mel frequency cepstral coefficients(IMFCCs)[15], and high-dimensional magnitude and phase features[16].
The physical access (PA) database concentrates on playback attack, involves capturing the speech of a particular speaker and broadcasts the replay to deceive the identification system[11]. Feature extraction modules can be deployed in the PA database, such as CQCCs, linear frequency cepstral coefficients(LFCCs), MFCCs, instantaneous frequency and cepstral coefficients(IFCCs)[15], linear frequency residual cepstral features[13], and variable length energy separation algorithm (VESA) based features[13].
Todiscoetal.[2]proposed CQCCs based on constant-Q transform (CQT). Compared with Fourier transform, CQT has higher frequency resolution for the processing of low-frequency waves, and provides higher temporal resolution for the processing low-frequency waves[2], making CQCCs capable of collecting some recording devices and environment information in spoofed speech detection[2]. The appearance of CQCCs has inspired many works. For example, Yangetal.[5]combined CQT with amplitude-phase spectra, discrete cosine transform (DCT) and octave segmentation, and proposed constant-Q magnitude-phase octave coefficients extracted from amplitude-phase spectra for playback speech detection (PSD), which outperformed significantly other features extracted only from amplitude spectra.
In order to improve the security of ASV systems, more and more researchers in related fields have begun to study the detection of spoofed speech attacks. The front-end part of recording PSD is the feature parameter extraction. The features of an anti-spoofing system can be classified into two categories based on their generation method: artificially designed features and deep features. Generally speaking, artificially designed features can be obtained through mathematical formulas. Artificially designed features which are mainly related to cepstral, are commonly used in anti-spoofing systems, such as MFCCs[27], IMFCCs[27], LFCCs[28], linear prediction cepstral coefficients(LPCCs)[29]and CQCCs[10]. Deep features are usually obtained by deep learning of various neural networks, including deep neural networks(DNNs)[9], recurrent neural networks(RNNs)[9]and convolutional neural networks(CNNs)[9].
The frequency range of human vocal organs is mostly concentrated in low frequency. It is compulsory that the feature has to be transformed to the frequency domain from the time domain. The method commonly used to convert the time domain to the frequency domain is short time Fourier transform (STFT) or CQT. STFT has problems, for example periodic truncation at low frequency, which will lead to low frequency resolution of speeches. The problem can be effectively addressed by CQT, which offers better resolution for low frequencies and more accurately captures the original sound features. Previous related work[6]utilized CQT as the basis and used the Fisher score to demonstrate the effectiveness of the variance or mean addition method in improving performance. The CQCC basically relies on CQT, and CQT uses frequency bins that are geometrically spaced and has a constant-Q factor throughout the spectrum.
Yangetal.[6]aimed to improve the performance for spoofed speech detection. Their work was created by adding variances or means to the constant-Q-based cepstral domain, following with octave segmentation and DCT steps. Based on this, this paper proposes several novel features.
(1) Consider that constant Q usually follows uniform resampling before the final DCT step. Thus, we consider uniform resampling, instead of octave segmentation to extract two features. These two novel features are named constant-Q variance cepstral coefficients(CVCCs) and constant-Q mean cepstral coefficients(CMCCs), respectively. These two features further strengthen the high-frequency nonlinear distortion of playback recording and improve the distinction between playback speeches and genuine speeches by adding the variance or mean of samples to the amplitude spectrum after CQT. It is helpful for the system to better distinguish the playback voice.
(2) Considering that the LFCC feature performs competitively with the CQCC, two more LFCC-based features are proposed. In this way, linear frequency variance cepstral coefficients(LVCCs) and linear frequency mean cepstral coefficients(LMCCs) are created for spoofed speech detection. They can reflect the correlation between speech sampling points well and find out more hidden information of speech signals.
Two assessment scenarios are LA utilized models involving VC and SS attack categories, and PA utilized models with playback attack categories[12]. In this research, we concentrate on how to extract hand-crafted features and how should they perform practically. The goal is to develop universal countermeasures for spoofed speech detection.
These features are then used in conjunction with a light convolutional neural network (LCNN) as the back-end classifier, which outperforms the existing systems for both LA and PA scenarios[3]. The LCNN is one of the best back-end classifiers in ASVspoof 2017 challenge, and it is enough to prove that the LCNN has perfect performance in spoofed speech detection. The LCNN structure has a simplified CNN structure containing max-feature map activation (MFM)[12]. The MFM structure serves as a feature selector in the LCNN and suppresses a neuron through a competitive interaction[13], so the neural network using the MFM structure can choose key characteristics that are important for task solving.
The outline of the following part is as follows. In section 1, CMCC and CVCC feature extractions are described, and modified LMCC and LVCC are also discussed. The experimental results based on proposed features are shown in section 2, and they are compared with other known single feature based systems on the ASVspoof 2019 dataset in section 3. Conclusions are given in section 4.
1 Modified Features
1.1 Proposed CVCCs and CMCCs
In 1991, Brown redefined the content of CQT[25]. In essence, CQT is a set of filters, which is often used as a processing method for music signals. The difference between CQT and Fourier transform is that the horizontal axis frequency of the former spectrum is not linear, but based on log2, and the length of the filter window can be changed according to the frequency of the spectral line. Compared with the Fourier transform, the low frequency band in the spectrum after CQT has relatively higher frequency resolution, and the high frequency band in the spectrum has relatively higher time resolution.
CQT converts speeches from the time domain to the frequency domain, and the center frequency between adjacent bins has the same ratio. The center frequency of thek-th binfksatisfies
fk=2(k-1)/Bf1,
(1)
whereBrepresents the number of bins in each octave;f1is the center frequency of the lowest frequency bin.
The value ofQis
(2)
whereδfkrepresents the bandwidth of thek-th bin.
CQT is applied to the discrete speechx(m) to obtainXCQT(k).Then the power spectrumECQT(k) is obtained
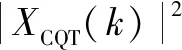
(3)
The log power spectrum log[ECQT(k)] is obtained byECQT(k).Adding the mean of samples to log[ECQT(k)], gets log[ECQT,m(k)].This operation further strengthens the high-frequency non-linear distortion between genuine speeches and playback speeches, so as to improve the distinction between genuine speeches and playback speeches, which is conducive to the detection of playback attack.
As above, CQT brings the nonlinear spectrum, and thus, uniform resampling is considered following CQT. The log power spectrum distribution is geometric, but the spectrum required by DCT is linear. Therefore, log[ECQT,m(k)] needs to be resampled. Applying uniform resampling to log power spectrum log[ECQT,m(k)] can obtain log[ECQT,m(l)], wherelrepresents thel-th frequency band after uniform resampling[25].
The step before the final DCT step is replaced by uniform resampling, instead of octave segmentation to extract two features. DCT can obtain the low-frequency part of the signal, and then filter out the redundant high-frequency noise in the signal. In addition, DCT can decorrelate the low-frequency region. log[ECQT,m(l)]is transformed by DCT, and finally the CMCCC(n) is obtained
(4)
whereLrepresents the number of frequency bands after uniform resampling. The extraction process of CVCCs is similar to that of CMCCs, which will not be introduced in detail here.
1.2 Comparison of CQCCs and LFCCs
CVCCs and CMCCs are both relied on the CQT method. Different from CQT, STFT extracts a short segment from extensive data. Filtering techniques are required for removing different types of noises from the speech signal. Linear filtering is used, if the noise is only not time varying, stationary. Different methods are implemented to the signal for the linear filtering such as adaptive filtering and Kalman filtering.
The features such as LFCCs[25-26], LPCCs and MFCCs, are all based on STFT. In order to intuitively discriminate between LFCCs and CQCCs, Fig. 1 shows the extracted features of the genuine speech and the corresponding spoofed speech based on t-distributed stochastic neighbor embedding (t-SNE) technique. With t-SNE, high-dimensional features are reduced to low-dimensional ones. It is clearly to see that both LFCCs and CQCCs separate genuine speeches and spoofed speeches well. In this section, more attention will be paid to LFCCs.
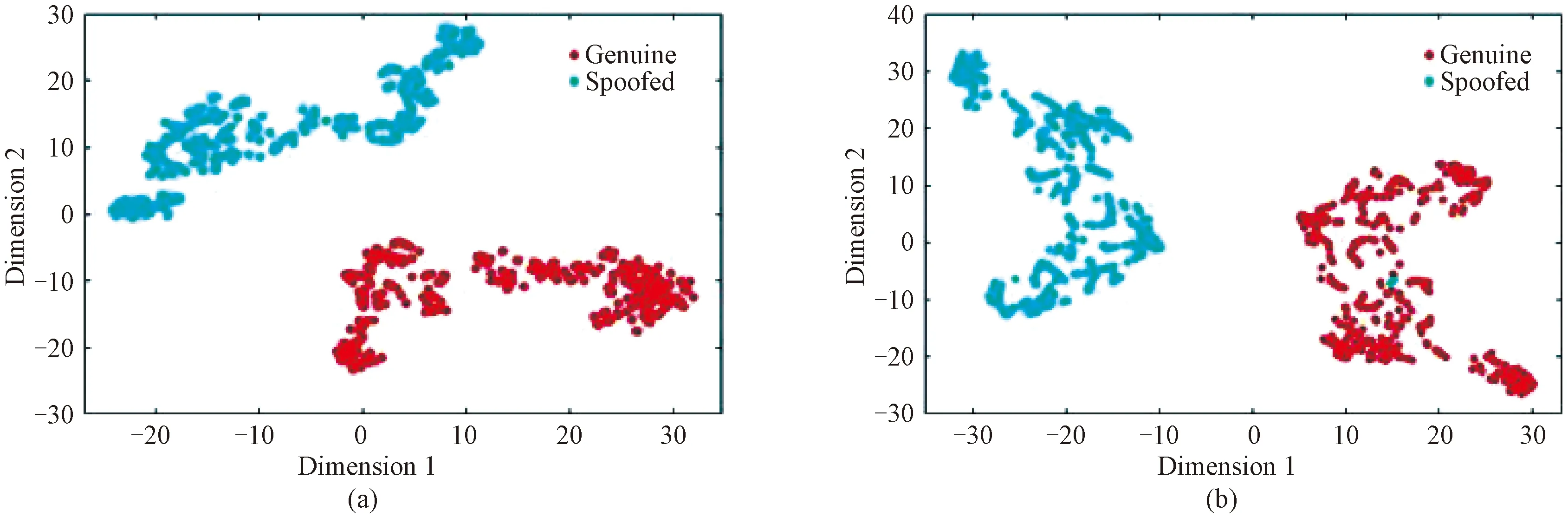
Fig. 1 Discrimination between LFCC and CQCC based on t-SNE technique: (a) reduced two-dimensional LFCC; (b) reduced two-dimensional CQCC
1.3 Proposed LVCCs and LMCCs
Based on LFCCs, the variance and the mean are added to the log power spectrum domain as LVCCs and LMCCs, which is shown in Fig. 2.
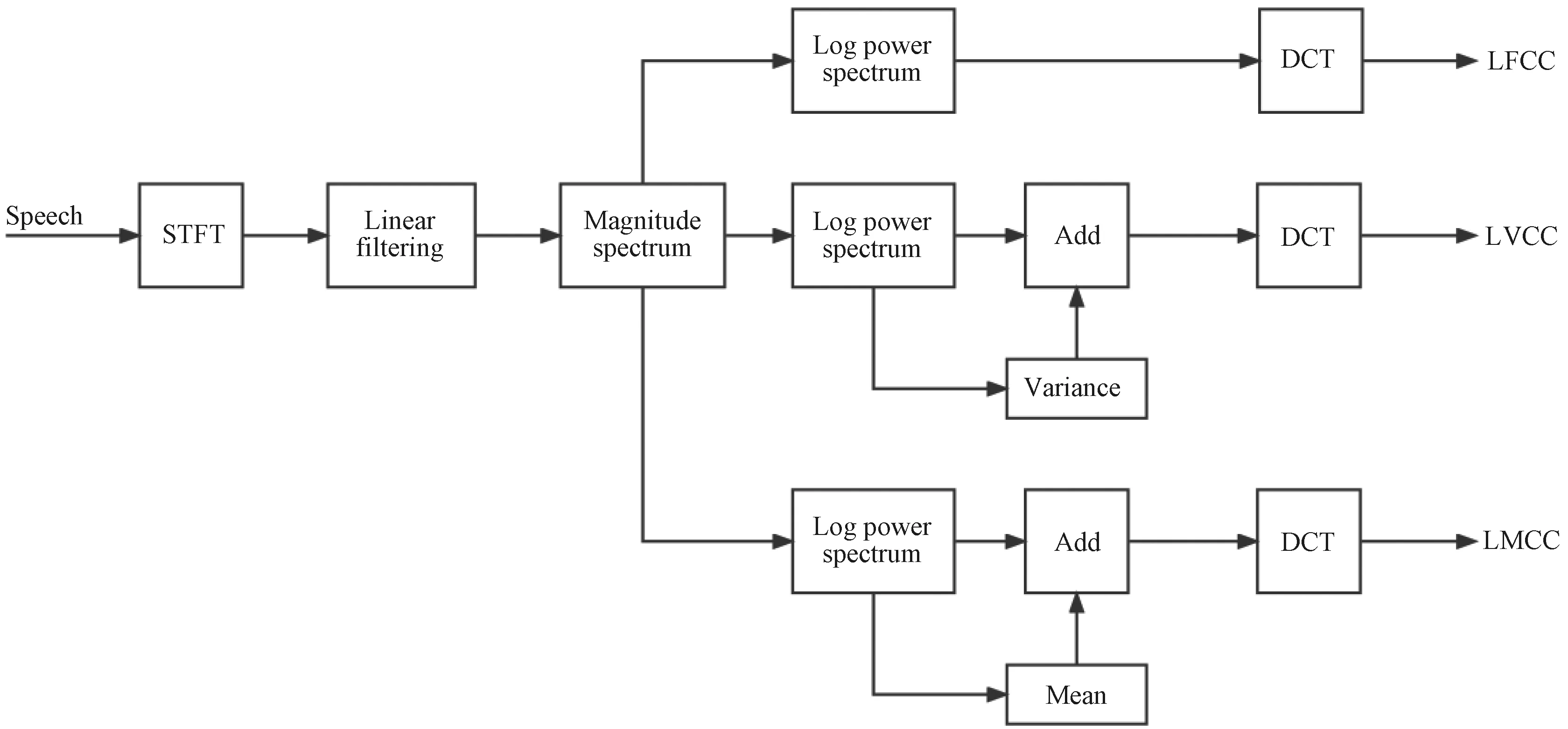
Fig. 2 Schematic diagram of LVCC and LMCC feature extraction
LVCC feature extraction contains six modules, namely, STFT, linear filtering, magnitude spectrum, log power spectrum, variance addition and DCT. The linear filtering converts STFT to inverse-STFT. The magnitude spectrum value is then computed, followed by the addition of the variance of the log power spectrum output.
LMCC feature extraction contains six modules, namely, STFT, linear filtering, magnitude spectrum, log power spectrum, mean addition and DCT. The linear filter converts STFT to inverse-STFT. The magnitude spectrum value is then computed, followed by the addition of the mean of the log power spectrum output.
STFT is the most widely used algorithm to study non-stationary signals, and it is suitable for speech processing. The specific operation is as follows. The speech signal is divided into frames, and then fast Fourier transform (FFT) is applied to each frame. The formula is
(5)
wherexi(n) is the input signal of thei-th frame;Xi(k) is its discrete Fourier transform;Nis the number of points of FFT. The magnitude spectrum ofXi(k) is operated by linear filtering banks and becomesS(i,l).
(6)
whereKrepresents the number of filters;Hl(k) represents the frequency response function of linear filtering.
The log power spectrum of each frame log[S(i,l)]2is obtained byS(i,l).Adding the mean of samples to log[S(i,l)]2gets log[Sm(i,l)]2.
The log[Sm(i,l)]2is transformed by DCT, and finally the LMCC is obtained. The transformation formula is
(7)
The extraction process of LVCCs is similar to that of LMCCs, which will not be introduced in detail.
1.4 Fisher score of LVCCs and LMCCs
To evaluate the discriminative ability of LVCCs and LMCCs, the Fisher score is utilized the same as that in the previous work [26]. After the log power spectrum, frames of the log power spectrum can be obtained. LetXpresent one genuine frame of the log power spectrum.
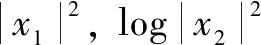
(8)
wherekis frequency bin number.
(9)
(10)
1.4.1FisherscoreofLVCCs
After the variance addition step of LVCC feature extraction, a new vectorX′ is gotten:
X′=
(11)
LetYpresent one-dimensional log power spectrum feature of the corresponding spoofed speech. By replacingXwithY, Eqs. (8)-(11) denote the condition of the corresponding spoofed speech. Noting that the variance addition step is the only difference between LFCCs and LVCCs, to compare the discriminative ability of these two features, Fisher scores of genuine speeches and spoofed speeches are used.
The Fisher score of LFCCs is
(12)
The Fisher score of LVCCs is
(13)
Since Fisher scores in Eqs.(12) and (13) were computed frame by frame, whole frame situation should be considered to evaluate the discriminative ability. Two genuine utterance and the corresponding playback speech are chosen randomly in Fig. 3 to show the difference betweenFXYandFX′Y′.Noting that a higher Fisher score represents better discriminative feature ability, it can be seen that each frame of LVCCs works better than that of LFCCs. To more convincingly evaluate the features, frames of more utterance should be considered.XandYin Eqs.(12) and (13) are compared with parallel data, so the whole parallel data of ASVspoof 2017 playback data is used. The frame means ofFXYandFX′Y′are 0.088 3 and 150.817 3, respectively. Thus, the better discrimination of LVCCs is evaluated both with a visual figure as shown in Fig. 3 and mathematical value.
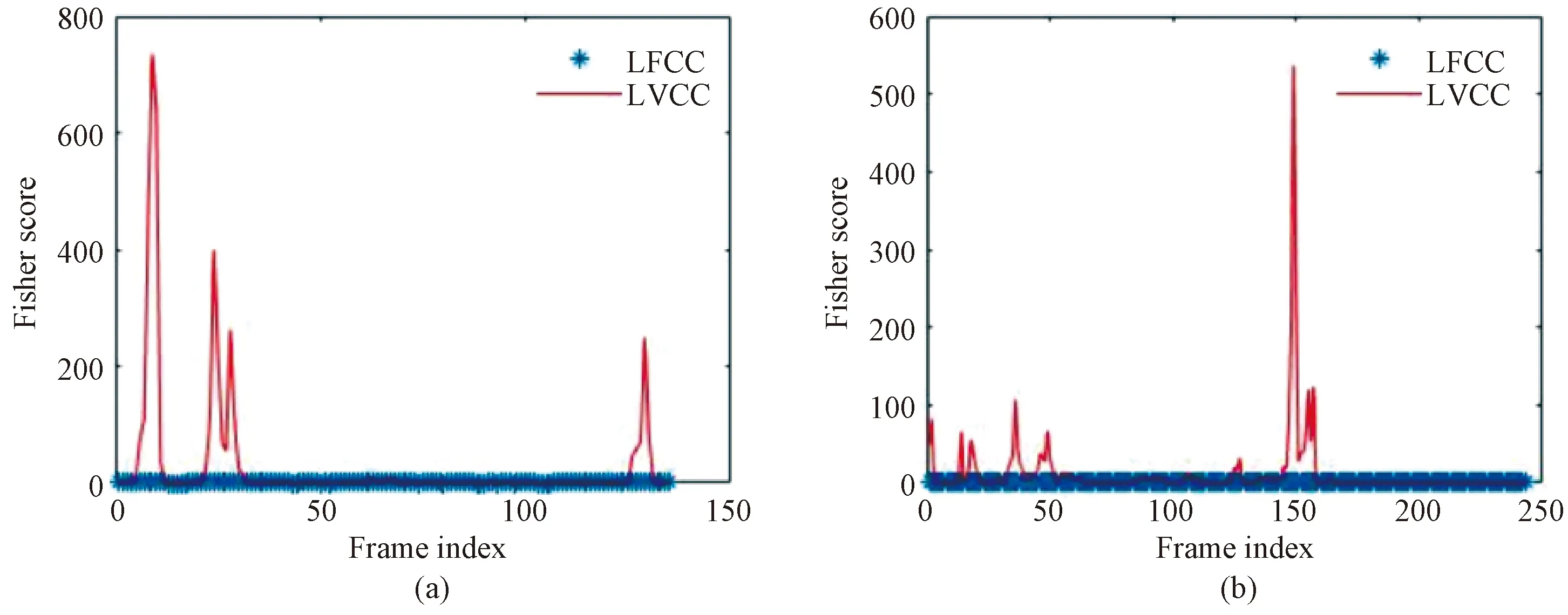
Fig. 3 Comparison of LFCC Fisher scores: (a) FXY; (b) FX′Y′.
1.4.2FisherscoreofLMCCs
Similar to LVCCs, the mean addition step is included in LMCC feature extraction. Based on this step, the log power spectrum comes to a new vectorX′′:
(14)
The Fisher score of LVCCs is
(15)
Since the Fisher score is a positive value,FX′′Y′′>FXY, and the LMCC performs better than the LFCC.
2 Experimental Results
2.1 Experimental setup
ASVspoof 2019 challenge emphasizes various known spoofing arrangements, addressing LA and PA. LA is commonly produced with the technique of text-to-speech synthesis (TTS) and voice conversion (VC). PA is received by recording the genuine speech. The performance metrics for evaluation are tandem detection cost function (t-DCF) and an equal error rate (EER)[12-14]in ASVspoof 2019 challenge.
For both LA and PA, the training dataset contained the speech of 20 people (eight men and 12 women), while the development set had the speech of 10 people (four men and six women), both genuine and spoofed. All of data in the training set might be utilized to develop spoofing detectors and countermeasures. The VCTK corpus[3]was used to build all of the systems. The same structure that was used to create the training set was also employed to develop the development set. Twenty-seven distinct acoustic and nine different replay scenarios were used to create training and development data for PA. As a result, the goal is to provide a countermeasure that can accurately detect spoofed data created by undetected spoofing algorithms[3].
The evaluation set is around 4 GB in size, with up to 80 000 trials containing genuine speeches and spoofed speeches. The recording conditions are identical to those used on the development set. Various undetected spoofing techniques are used to produce spoofed data[3]. They are, however, substitutes for the spoofing methods utilized to create the development set. Helpful information is provided into the generic performance of countermeasure models.
2.2 Experiments and evaluations on ASVspoof 2019 LA dataset
2.2.1PerformanceofCMCCsandCVCCsonASVspoof2019LAdataset
CMCC+LCNN and CVCC+LCNN systems were used in the LA scenario of ASVspoof 2019 challenge as shown in Table 1. The dimensions of CMCCs and CVCCs used in the experiment were 30. The EER and t-DCF were used as evaluation metrics. In this scenario, the CMCC can give better results than the CVCC. The two proposed features have been tested on different combinations, and the DA combination for the CMCC+LCNN system shows the best results. For the CVCC+LCNN system, the EER of the SDA combination is 10.31 and t-DCF of the DA combination is 0.269 3 which are the best values.
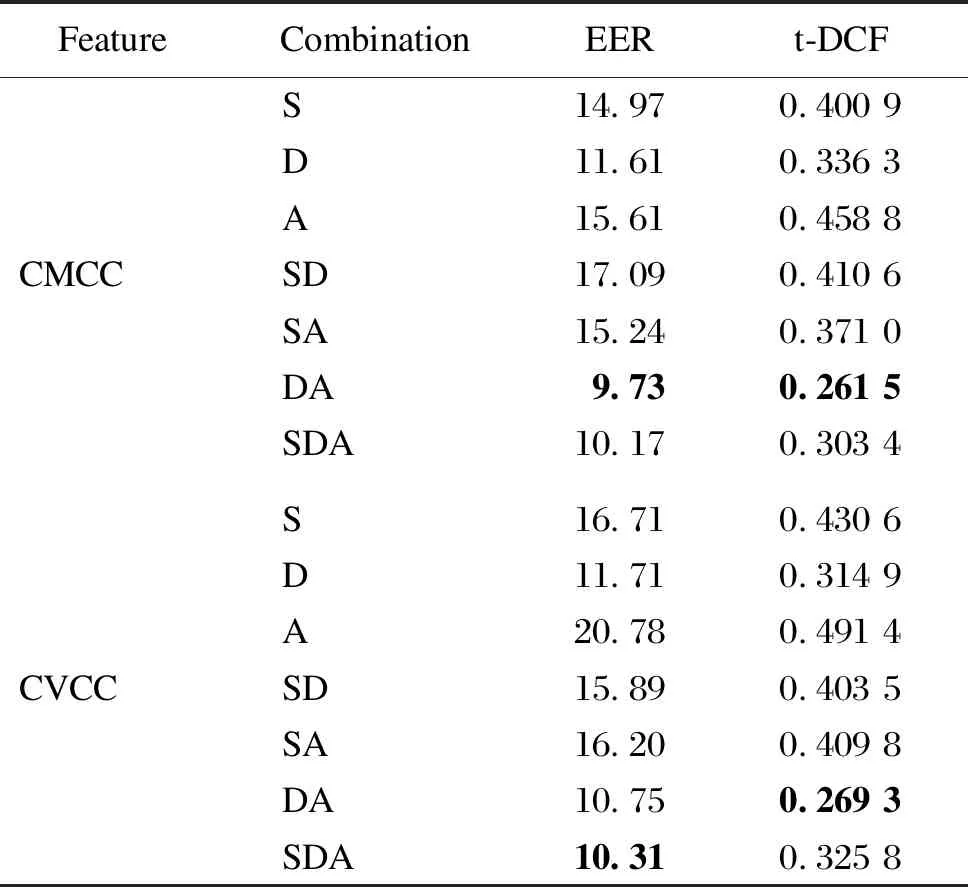
Table 1 EER and t-DCF of CMCCs and CVCCs on ASVspoof 2019 LA evaluation set
2.2.2PerformanceofLMCCsandLVCCsonASVspoof2019LAdataset
LMCC+LCNN and LVCC+LCNN systems were used in the LA scenario of ASVspoof 2019 challenge as shown in Table 2. The dimensions of LMCCs and LVCCs used in the experiment were 30. The EER and t-DCF were used as evaluation metrics. In this scenario, the LMCC can give better results than the LVCC. The two proposed features have been tested on different combinations, and the SA combination for the LMCC+LCNN system shows best results, of which EER and t-DCF are 4.12 and 0.152 5, respectively.
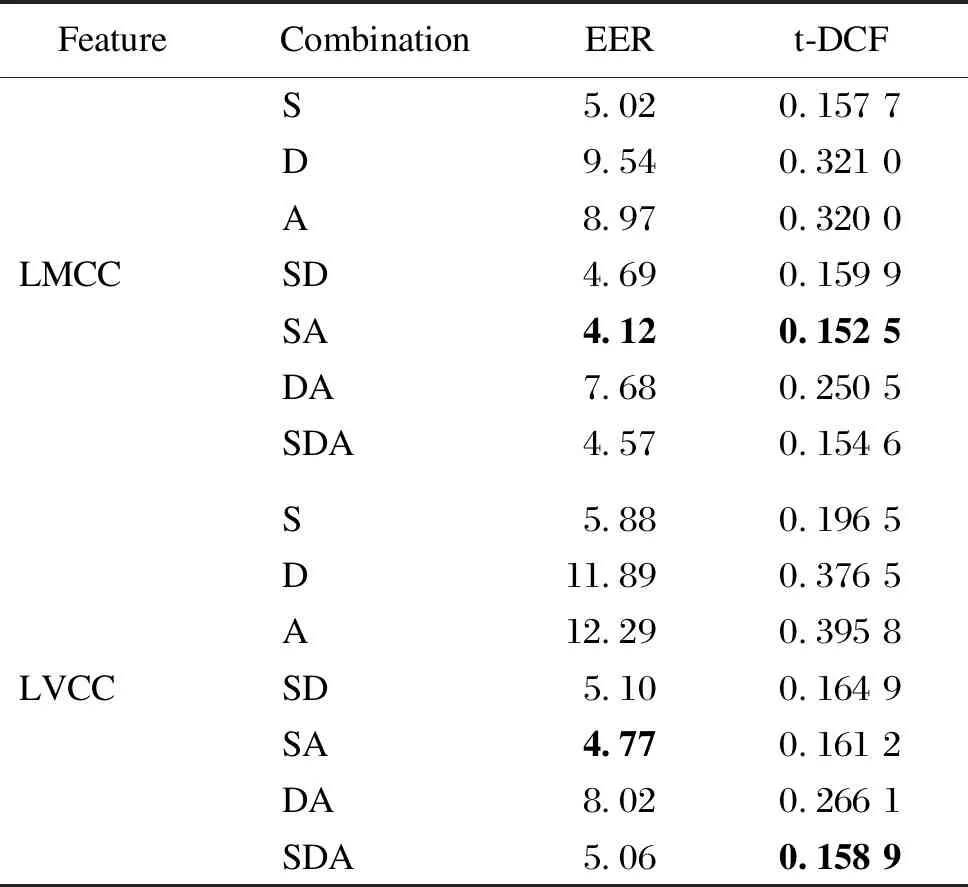
Table 2 EER and t-DCF of LMCCs and LVCCs on ASVspoof 2019 LA evaluation set
2.3 Experiments and evaluations on ASVspoof 2019 PA dataset
2.3.1PerformanceofCMCCsandCVCCsonASVspoof2019PAdataset
CMCC+LCNN and CVCC+LCNN systems were used in the PA scenario of ASVspoof 2019 challenge as shown in Table 3. The dimensions of CMCCs and CVCCs used were 30. The EER and t-DCF were used as evaluation metrics. Two proposed features have been tested on different combinations in this scenario, and it can be seen that the CVCC stands out in comparison with the CMCC. For the CMCC+LCNN system, the SD combination shows the best results, comparing with all other combinations. For the CVCC+LCNN system, the DA combination shows the best results, with the EER of 3.17 and t-DCF of 0.0807.
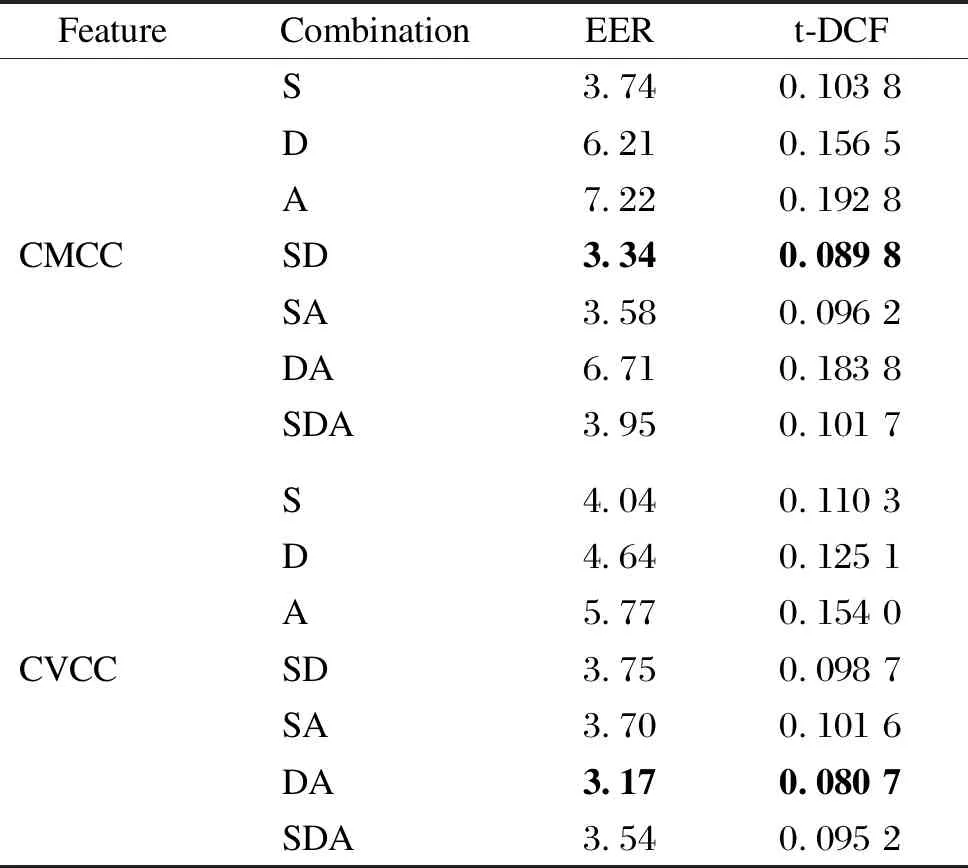
Table 3 EER and t-DCF of CMCCs and CVCCs on ASVspoof 2019 PA evaluation set
2.3.2PerformanceofLMCCsandLVCCsonASVspoof2019PAdataset
LMCC+LCNN and LVCC+LCNN systems were used in the PA scenario of ASVspoof 2019 challenge as shown in Table 4. The dimensions of LMCCs and LVCCs used in the experiment were 30. The EER and t-DCF were used as evaluation metrics. In this scenario, the LMCC can give better results than the LVCC. Two proposed features have been tested on different combinations, and the SDA combination for the LVCC+LCNN system shows the best results, with the EER of 1.34 and t-DCF of 0.039 3.
3 Comparison with Other Systems
In this section, comparison is made among proposed features and other single feature based systems on LA and PA scenarios ASVspoof 2019 challenge. For individual comparison of the proposed features, the CQCC+ResNet system was used as the baseline for CMCCs and CVCCs, and the LFCC+LCNN system was used as the baseline for LMCCs and LVCCs.
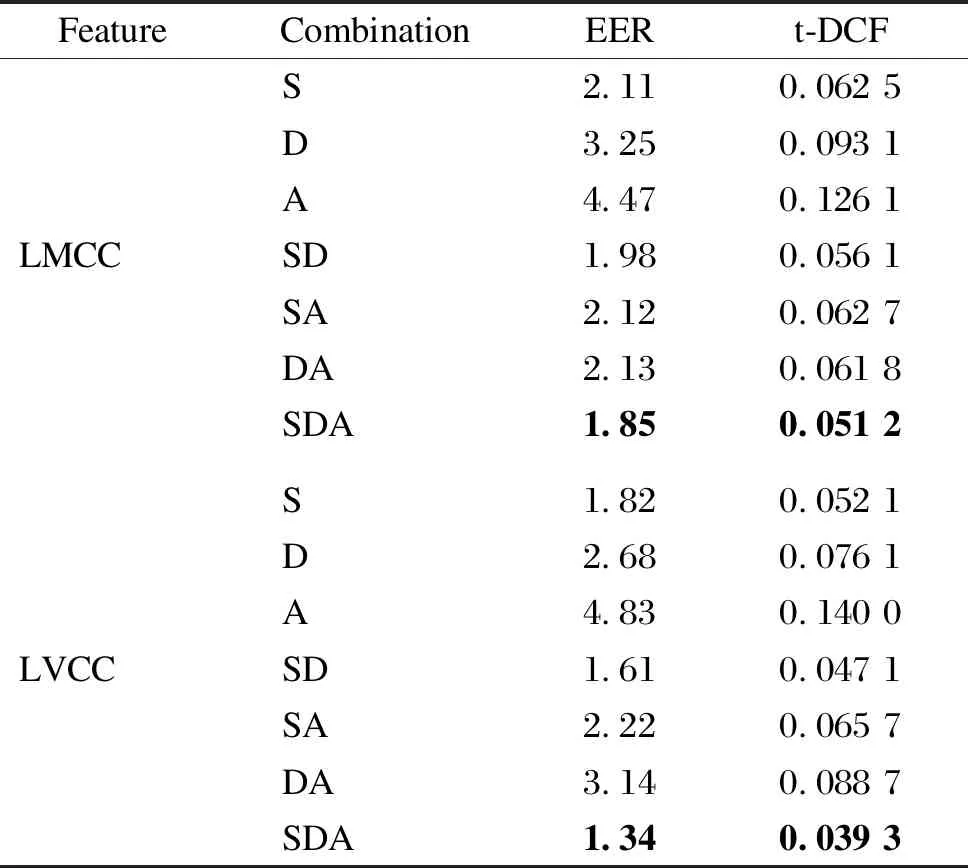
Table 4 EER and t-DCF of LMCCs and LVCCs on ASVspoof 2019 PA evaluation set
3.1 Comparison with other systems on ASVspoof 2019 LA dataset
On the LA evaluation set shown in Table 5, the EER of the LMCC+LCNN system has a 18.58% improvement over that of the LFCC+LCNN system, and the EER of the LVCC+LCNN system has a 5.73% improvement over that of the LFCC+LCNN system.
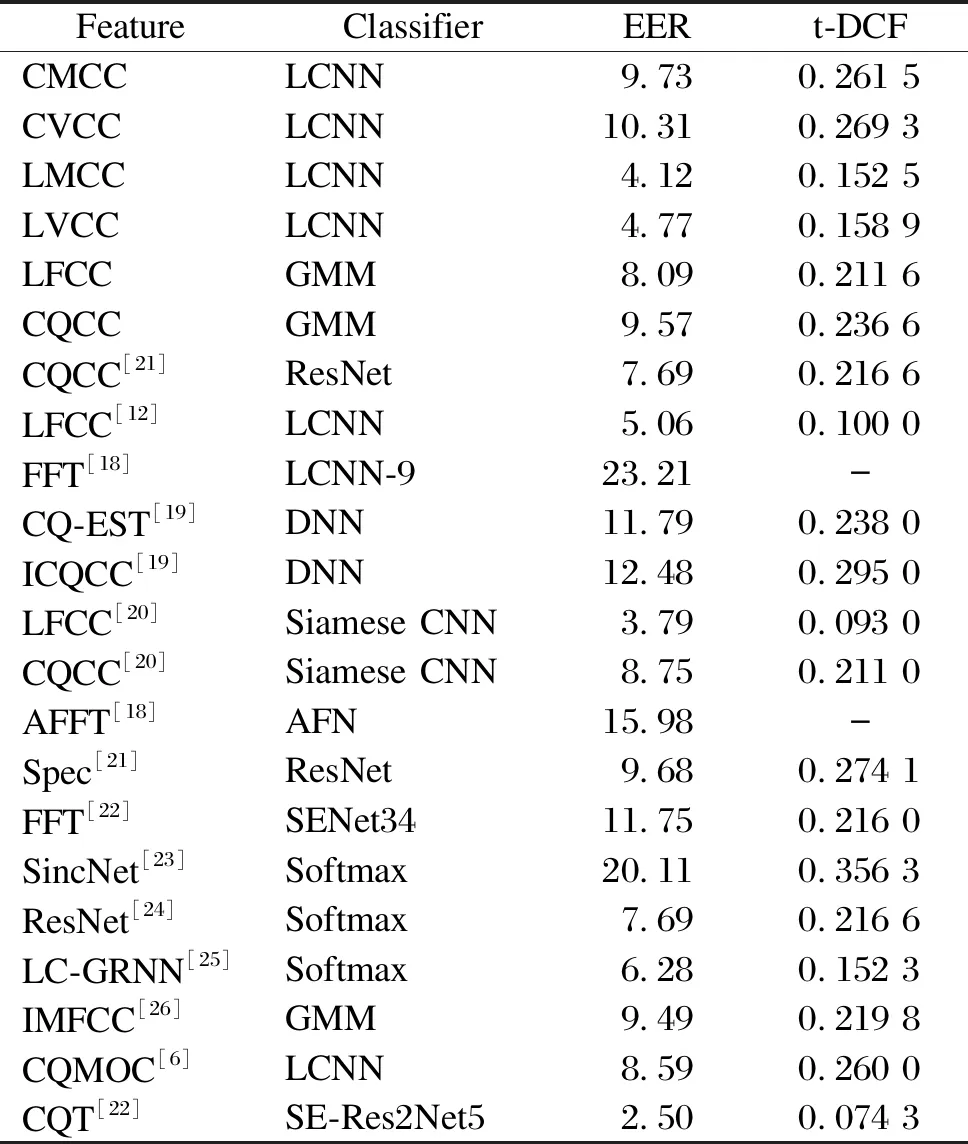
Table 5 Comparison of single system based on different features on ASVspoof 2019 LA evaluation set
3.2 Comparison with other systems on ASVspoof 2019 PA dataset
On the PA evaluation set shown in Table 6, the EER of the CMCC+LCNN system has a 24.60% improvement over that of the CQCC+ResNet system, the EER of the CVCC+LCNN system has a 28.44% improvement over that of the CQCC+ResNet system, the EER of the LMCC+LCNN system has a 59.78% improvement over that of the LFCC+LCNN system, and the EER of the LVCC+LCNN system has a 70.87% improvement over that of the baseline system.
From the results shown in Tables 5 and 6, it can be seen that the proposed features are better than most systems on the ASVspoof 2019 evaluation set, demonstrating the robustness and the effectiveness of the features against spoofed speech attacks.
4 Conclusions
In this paper, the applicability of the proposed features for solving the problem of spoofed speech detection on the ASV system has been studied. In conclusion, the LMCC+LNCC system and the LVCC+LCNN system work better than the CMCC+LCNN system and the CVCC+LCNN system. On the PA evaluation set, compared with that of the LFCC+LCNN system, the EER of the LMCC+LCNN system has a 59.78% competitive improvement, and the EER of LVCC+LCNN system has a 70.87% competitive improvement. On the LA evaluation set, compared with that of the LFCC+LCNN sysem, the EER of the LMCC+LCNN system has a 18.58% competitive improvement, and the EER of the LVCC+LCNN system has a 5.73% competitive improvement. The improvement proves that the proposed features in this paper can reflect the correlation between speech sampling points well and find out more hidden information of speech signals. The robustness and the effectiveness of the ASV system are improved significantly.
 Journal of Donghua University(English Edition)2023年2期
Journal of Donghua University(English Edition)2023年2期
- Journal of Donghua University(English Edition)的其它文章
- Online Fault Detection Configuration on Equipment Side of a Variable-Air-Volume Air Handling Unit
- Exact Graph Pattern Matching: Applications, Progress and Prospects
- A Class of Simple Modules for Electrical Lie Algebra of Type D5
- Data-Driven Model for Risk Assessment of Cable Fire in Utility Tunnels Using Evidential Reasoning Approach
- Fine-Grained Sleep Apnea Detection Method from Multichannel Ballistocardiogram Using Convolution Neural Network
- Proportion Integration Differentiation (PID) Control Strategy of Belt Sander Based on Fuzzy Algorithm