
基于组合预测模型电力负荷优化算法研究
2023-05-17 03:16:34林希程
电子技术与软件工程 2023年5期
林希程
(常州供电公司 江苏省常州市 213000)
精准的负荷预测对于降低电力运行成本、提高电网环境效益和经济效益具有重要作用。随着电力市场化和发电方式多元化的推进,电力负荷预测更加复杂多变,需要综合利用多种预测模型进行基于组合的预测。基于组合预测模型电力负荷优化算法的研究,可以通过有效地整合多个预测模型的优势,提高负荷预测的准确度和稳定性,优化电力系统的运行和管理。因此,开展这方面的研究具有重要的理论和实践价值。
1 VMD-奇异谱分析降噪法
VMD 是一种基于变分原理的信号分解方法,通过迭代优化过程,将信号分解为若干个本征模态函数(EMD)。每个EMD 均为单调且不会出现内部振荡的信号,具有一定的物理意义和可解释性。VMD 分解后每个本征模态函数可以分别分析,从而减少了信号自身的混叠效应。
基于VMD 的降噪方法通常分为两步,第一步是对目标信号进行VMD 分解,提取出主要的信号分量;第二步是根据阈值筛选出包含噪声信息的本征模态函数,进一步去除噪声。
VMD-奇异谱分析法结合了VMD 和SSA 两种方法的优点,同时去除了两种方法的缺点,使得降噪效果更加稳定和鲁棒[1]。SSA 方法是一种基于矩阵分解的信号分解方法,将信号转化为一个矩阵,并通过对矩阵的特征分解来提取信息。SSA 方法具有较好的自适应性和稳健性,但在高频部分分解不稳定。
1.1 奇异谱分析
该分析方法经常应用于非线性时间序列研究活动中,而电力负荷变化呈现出明显的非线性时序特征。因此,研究人员设电力负荷变化过程中的一维时间序列为{hi,i=1,…,N},将其对应的Hankel轨迹矩阵设定为H,则可以得到:
公式(1)中,L代表滑动窗口参数,且L满足1<L<N,变量K=N-L+1 的定义为,利用奇异值分解公式可以得到:
公式(2)与公式(3)中,λi代表降序排列奇异值,Ui代表左奇异值向量,Vi代表右奇异值向量。利用奇异值分解到相应的特征向量,在此基础上利用分组在众多信号源中筛选出目标信号,利用时间经验正交函数对信号进行重建,进而得到重构序列。
1.2 VMD-奇异谱分析
基于VMD 分析法,探究人员将原始序列划分为Res分量以及IMF分量,将设计峭度函数值设定为k(x)并对IMF分量进行重构,将得到的峭度值与阈值进行横向对比,确定需要重构的IMF分量数值。其计算公式为:
公式(4)中,E代表期望值,变量η代表数列平均值。
变分模态分解(VMD)和奇异谱分析(SSA)方法结合在一起可以实现更好的信号降噪效果。其详细过程如下:
(1)定义相关参数。在VMD 中,需要设置信号分解的迭代次数K,每次迭代时加入的正则化项参数alpha,还有对每个本征模态函数计算Hilbert-Huang 变换时使用的窗口宽度。在SSA 中,需要设置Hankel 矩阵的列数L 和重构矩阵的行数K[2]。
(2)输入原始数据序列,并对其进行VMD 降噪。VMD 会将信号分解为若干个固有模态函数(IMF),其中每个IMF都是相对单频率的信号分量。得到IMF后,需要通过测量其峭度值来判断其是否包含噪声成分。峭度值越小,说明IMF 内部的频率变化越单调,表明该IMF 包含了重要的信号信息而不是噪声。因此,需要计算每个IMF 的峭度值,将峭度值大于阈值的IMF 进行重构。
(3)使用SSA 对重新构建的每个IMF 进行两次降噪。1.需要计算相应的Hankel 矩阵,并通过奇异值分解得到相应的变量参数和特征向量。2.对这些特征向量进行分组,并通过时间经验正交函数和时间主成分来重建信号。这两次降噪过程可以进一步去除残余的噪声成分。3.将所有去噪后的IMF 相加即可得到完整的降噪序列。
与其他降噪方法相比,VMD 与SSA 结合的降噪方法有以下优势:
(1)VMD 能够提取出单调的本征模态函数,这使得降噪效果更加准确和可控。
(2)SSA 具有较好的自适应性和稳健性,这使得算法能够在多种信号环境下具有较好的表现。
(3)通过筛选大于阈值的IMF 并进行重构,可以进一步实现对噪声的去除,从而提高信号降噪的效果。
2 混沌自适应鲸鱼优化算法
2.1 鲸鱼算法
混沌自适应鲸鱼优化算法是一种基于混沌理论和自适应思想的优化算法,通过仿真鲸鱼觅食行为中的个体学习和群体智能行为来求解优化问题。该算法结合了混沌系统的随机性、多样性以及自适应性与鲸鱼求食的高效性和灵活性,具有较强的全局收敛能力。
CFCWO 主要包括以下三个阶段:初始化、混沌搜索和自适应更新。在初始化阶段,需要确定种群规模和优化目标函数,并设定各种参数如交叉概率、变异概率等。在混沌搜索阶段,使用初始种群作为鲸鱼群体,在迭代过程中,通过混沌映射函数对种群进行均匀分布,从而增加了种群的多样性,避免陷入局部最优解。同时,将每个鲸鱼的位置视为一种可能的解,采用生物学习性的方式来探索周围环境的极值点。这个过程通过计算鲸鱼的适应度来实现。在自适应更新阶段,根据适应度动态调整交叉概率、变异概率等参数,使算法具有更好的自适应性和全局搜索能力。
CFCWO 算法的具体实现有以下几个步骤:
(1)初始化阶段:定义求解问题的目标函数,确定种群规模,并根据自己的经验设置算法需要的各种参数。
(2)混沌搜索阶段:生成初始种群,计算每个鲸鱼的适应度。通过混沌映射函数对种群进行均匀分布,并选定一定比例的鲸鱼进行探索周围环境的极值点。具体是将鲸鱼的位置加上一个随机扰动向量,得到新的位置,并计算新位置的适应度。若新位置的适应度更高,则更新该鲸鱼的位置。
(3)自适应更新阶段:根据全部鲸鱼的适应度值,选择精英鲸鱼,并动态调整交叉概率、变异概率等参数,以提高算法的全局搜索能力。同时,根据当前最优鲸鱼的位置和适应度来更新全局最优解,直到满足停止条件为止。
CFCWO 算法的特点在于,它不仅具有混沌系统的随机性和多样性,还引入了自适应学习思想,使算法更加适应不同的问题[3]。另外,它能够快速、准确地找到全局最优解,可用于解决多种实际问题,如函数优化、机器学习、电力系统调度等领域。
2.2 算法优化
本次研究中,相关工作人员尝试对鲸鱼算法进行优化,其主要步骤包括:研究人员深入研究鲸鱼算法的包围捕食过程,并列出该过程的更新公式:
公式(5)中,X(t)代表鲸鱼群当前的位置,Xd(t)则代表最优解,变量t为迭代次数,A、C均为参量系数,其计算公式为:
上述三项公式中,ra与rb均为范围在[0,1]之间的随机数,a表示控制参数,Tmax则为最大迭代次数。
在此基础上,研究人员模拟鲸鱼群搜索捕猎过程,其更新公式为:
公式(9)中,XR(t)代表鲸鱼群中随机选择的鲸鱼个体数量。
3 EOBL-CSSA算法
EOBL-CSSA 是一种组合智能优化算法,其中EOBL 与算法结合在一起,用于时间序列预测问题。EOBL-CSSA 算法的主要目标是从多个数据源中提取有用的信息,以提高预测精度。
具体来说,EOBL-CSSA 的算法步骤如下:
(1)数据预处理:使用VMD-Singular Spectrum Analysis 技术对原始数据进行去噪处理,提取出相对稳定的主要成分。
(2)特征提取:基于CSSA 算法进行时域、频域特征提取,将时域窗口和频域子带分解转换为CSSA 表示,并提取CSSA 重要部分之后进行组合。
(3)模型训练:使用Elman 神经网络模型、LSSVM模型和ELM 神经网络模型进行预测模型的训练。其中,Elman 神经网络模型可以保存短期记忆信息;LSSVM模型通过最小化风险函数,选择合适的超参数;而ELM 神经网络模型具有快速的训练速度和良好的泛化性能。
(4)组合预测:将训练好的三个模型进行加权组合,得出最终预测结果。为了提高预测精度,采用EOBL 算法对加权系数进行优化。
3.1 精英反向学习策略
精英反向学习策略(EOBL)是一种用于优化算法中的加权系数的智能算法。该策略的主要思想是利用反思和反向思维来提高搜索效率和优化性能。EOBL 策略通过从种群中选择最好的解,并将其与其他解作为对立面进行比较,生成新的解集。这样做可以有效地避免陷入局部极值,提高全局搜索的能力。
EOBL-CSSA 算法是一种组合智能优化算法,把精英反向学习策略应用于时间序列预测问题中,用于提高预测的准确性。在EOBL-CSSA 算法中,精英反向学习策略被用于优化各个模型之间的加权系数,以达到预测结果的最优化。具体来说,EOBL-CSSA 算法中的加权系数是用EOBL 算法进行优化的。
EOBL 算法的运行步骤如下:
(1)选择一个有代表性、可靠的样本作为精英解,并计算其适应度值;
(2)生成反向解,也就是将某些属性的值取反的解;
(3)比较精英解和反向解的适应度值,选出适应度值更好的解作为新的精英解;
(4)使用新的精英解来更新生成反向解的规则,使其更加适应当前优化任务;
重复(2)-(4)步,直到满足终止条件。
在EOBL-CSSA 算法中,将EOBL 算法应用于加权系数的优化,可以通过以下步骤实现:
(1)在数据预处理和特征提取阶段对数据进行处理,以便于模型对数据进行学习和预测;
(2)选择三个模型作为预测模型,如Elman 神经网络模型、LSSVM 模型和ELM 神经网络模型;
(3)对每个模型计算其预测误差,根据误差大小为其分配不同的权重;
(4)然后使用EOBL 算法来优化权重分配,得出最终权重系数,用于加权预测结果;
最终,通过加权组合三个模型的预测结果,得出最终的时间序列预测结果(如图1 所示)。
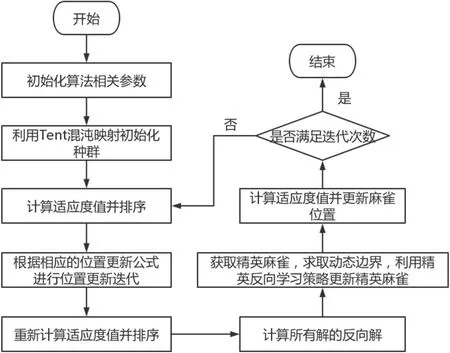
图1: EOBL-CSSA 算法控制流程图
3.2 计算流程
传统的优化算法往往存在着容易陷入局部最优的问题,这就导致了算法的搜索能力和性能受到了限制,难以得到全局最优解。针对这些问题,精英反向学习策略应运而生。
在使用EOBL 策略时,首先需要选取一个有代表性、可靠的个体作为精英解,并计算其适应度值。然后,利用反向思维生成反向解,也就是将某些属性的值取反的解,并与精英解进行比较。选择适应度值更好的个体作为新的精英解,并利用该精英解来更新生成反向解的规则,使其更加适应当前的优化任务。这样,不断重复以上过程,直到满足终止条件。
现代优化算法中的EOBL-CSSA 算法,是一种结合了精英反向学习策略和时间序列预测的组合智能优化算法。其中,EOBL-CSSA 算法主要利用EOBL 策略来优化各个模型之间的加权系数,在时间序列预测任务中达到更高的预测准确度。具体而言,EOBL-CSSA 算法中,首先对原始数据进行预处理和特征提取,以便于模型对数据进行学习和预测。接着,选择三个模型作为预测模型,如Elman 神经网络模型、LSSVM 模型以及ELM神经网络模型。对每个模型计算其预测误差,并根据误差大小分配不同的权重。然后,利用EOBL 策略来优化权重分配,得出最终权重系数,以此来加权预测结果。最终,通过加权组合三个模型的预测结果,得出最终的时间序列预测结果。
在EOBL-CSSA 算法中,精英反向学习策略能够通过优化加权系数,更好地利用多个模型之间的信息交流,从而提高预测模型的泛化性能,进一步提高时间序列预测的准确度。同时,EOBL-CSSA 算法还能够充分发挥各个模型的优势,避免单一模型在应对不同的任务时性能下降等问题。
3.3 构建基于EOBL-CSSA-LSSVM的多模型组合预测模型
在本次研究中,相关工作人员提出了一种基于多模型的电力负荷组合预测模型。该模型主要分为三个系统:
3.3.1 预处理系统
基于VMD-奇异谱分析法对原始数据进行预处理,去除其中的噪声,提取时间序列中的有效数据特征。这样做的目的是使数据更加精确,从而提高预测模型的准确度。
3.3.2 预测系统
研究人员采用CAWOA算法以及EOBL-CSSA算法,对ELM神经网络模型初始阈值以及权值进行优化处理。这样做的目的是进一步提高预测模型的性能,使其更加准确可靠[4]。
3.3.3 加权系统
基于SA 算法,明确每个最佳权重的系数并得到最终预测结果。这样做的目的是充分利用多个预测模型之间的差异性,提高整体预测模型的泛化能力和鲁棒性。
在该研究中,相关工作人员使用了实际的电力负荷数据集作为实验数据,进行了对比实验,比较了本文提出的基于多模型的电力负荷组合预测模型和传统的单一预测模型的区别和优劣。实验结果表明,本文提出的基于多模型的电力负荷组合预测模型相比单一预测模型,在预测准确性和稳定性方面都取得了更好的表现。具体来说,本文提出的模型在多个指标上优于传统单一预测模型,例如:均方误差、平均绝对误差、均方根误差等。
4 结语
本次研究提出了一种基于多模型的新型电力负荷组合预测模型。该模型采用VMD-奇异谱分析降噪方法优化原始数据,再通过EOBL-CSSA 算法优化ELM 神经网络,构建复合预测模型。最后通过SA 算法计算不同预测模型的权重比例,利用加权计算得到最终预测结果,以期为提高电力负荷优化算法计算效率提供技术支撑。
猜你喜欢
幼儿100(2022年41期)2022-11-24 03:20:20
计算机仿真(2022年8期)2022-09-28 09:53:02
数学小灵通·3-4年级(2020年9期)2020-10-27 03:26:14
数学大王·趣味逻辑(2020年9期)2020-09-06 14:17:17
小天使·二年级语数英综合(2019年4期)2019-10-06 02:44:36
动漫星空(2018年4期)2018-10-26 02:11:54
NBA特刊(2018年11期)2018-08-13 09:29:14
海外星云(2016年7期)2016-12-01 04:18:01
世界汽车(2016年8期)2016-09-28 12:11:11
中国塑料(2016年11期)2016-04-16 05:26:02
