
融合文本描述和层次类型的知识表示学习方法
2023-05-16 11:06李松舒世泰郝晓红郝忠孝
浙江大学学报(工学版) 2023年5期
李松,舒世泰,郝晓红,郝忠孝,2
(1.哈尔滨理工大学 计算机科学与技术学院,黑龙江 哈尔滨 150080;2.哈尔滨工业大学 计算机科学与技术学院,黑龙江 哈尔滨 150001)
知识图谱(knowledge graph, KG)[1]是一种用图模型来描述知识和建立世界万物之间关系的技术方法,并且已经成为智能问答等多个人工智能领域的重要资源.KG通过三元组(头实体、关系、尾实体)的形式以保存数据.传统的知识表示方法都是以符号逻辑为基础进行表示,易于刻画离散、显性的知识,具有较好的可解释性.在表示过程中,有许多不能用符号来刻画连续、隐形的知识会失去鲁棒性,从而在下游任务中难以达到预期效果[2].为了解决此问题提出表示学习.该方法有效度量实体和关系的语义相关性,缓解KG中的稀疏性问题[3].已有的方法主要分为翻译模型和卷积神经网络(convolutional neural network, CNN)模型.Bordes等[4]提出TransE模型,该模型将关系向量视为实体向量之间的转换,并实现向量的规范表示.继TransE之后,研究人员提出各种其他翻译模型,如TransH[5]、TransR[6]、TransD[7]、TransA[8]和TransG[9].这些模型对KG中的内部结构信息进行表示学习,但是语义可解释性较差.基于CNN的模型增加了对复杂关系和参数规模的考虑,可以学习更多的嵌入表示.
在大型的知识库中,如维基百科,对每个实体都有简单的文本描述,这些额外的文本信息可以有效提高知识表示能力.Wang等[10]将实体和单词/短语在同一向量空间中表示,使得预测结果更准确.DKRL模型[11]充分利用实体的描述信息,分别使用连续词袋模型和卷积神经网络模型对实体描述信息进行编码.在Freebase中,层次类型包括属性、类型和域,它们都是非常重要的外部信息.TKRL模型[12]充分利用知识库中的层次类型信息增强实体的表示.以上3个模型只考虑实体描述信息和层次类型信息,忽略了关系的描述信息.
关系抽取是从纯文本中提取未知关系事实并将关系加入到知识图谱中,是自动构建大规模KG的关键.由于缺少标记的关系数据,远程监控(distance supervision)通过假设包含相同实体的语句在关系数据库的监督下,可以表示相同的关系,使用启发式匹配来创建训练数据[13].PCNN模型[14]对按实体位置划分的卷积表示段使用分段最大池化.与CNN相比,PCNN能够更有效地捕捉实体内部的结构信息.MIMLCNN模型[15]进一步将关系抽取 扩展到多标签学习中,使用跨句子最大池化进行特征选择.Han等[16]提出层次选择性Attention,通过连接每层的Attention来表示捕捉关系层次的信息.Zhang等[17]将图卷积神经网络(graph convolutional network, GCN)应用于知识图谱中的关系嵌入以及基于句子的关系抽取.
这些方法都取得较好的实验效果,但是融合方法单一,仍存在3个问题:1) 这些方法只考虑单类外部信息,仅仅在单词上对齐,没有将三元组结构和文本信息相结合.2) 文本描述可能从各方面表示一个实体,在给定特定关系的情况下,并非文本描述中提供的所有信息都对实体起决定作用.3) 三元组的结构表示向量从现有的三元结构信息中学习得来,文本表示向量是从与文本语料库中相关联的信息中学习而来,需要保证这2种向量的维数一致,以提高知识表示的性能[18].
为了更好地表示实体和关系,提出融合文本描述和层次类型的知识表示学习方法(ETLKRL).主要做了以下工作.
1)提出一个融合文本描述和层次类型的知识表示学习模型ETLKRL,通过融合三元组自身结构信息、文本描述信息和层次类型信息,充分利用KG以外的信息,提高知识表示和知识推理的准确性和可解释性,解决了外部信息利用不足等问题.
2)使用CNN引入文本描述信息,并从文本描述中提取可靠的特征信息;使用基于注意力机制卷积神经网络,通过相关文本分配权重,从文本句子中提取有效信息,从而获得区分度高、语义准确度更好的关系向量表示;使用加权层次类型编码器来构造层次类型投影矩阵,并使用特定关系的类型约束来投影实体.
3)在WN18、WN18RR、FB15K、FB15K-237和YAGO3-10数据集上,进行链接预测和三元组分类实验.结果表明,在链接预测和三元组分类2项实验任务中,所提模型与基线模型相比更具有明显优势,能够处理外部信息利用不足等问题,并有一定的可扩展性.
1 相关工作
随着研究的不断深入,知识表示学习方法越来越多,主要分为3类:翻译模型、语义匹配模型和融合附加信息模型.
1.1 翻译模型
TransE[4]是最具代表性的翻译模型,将实体和关系嵌入到d维向量空间中,即h,r,t∈Rd,Rd为d维空间.同时遵循平移原则,即h+r≈t.得分函数为
式中:h、r和t分别为头实体、关系和尾实体的向量;L1和L2为范数,分别为曼哈顿距离和欧氏距离.
TransE模型参数少,在1-1关系中表现较好,但是在处理1-N、N-1、N-N等复杂关系时存在缺陷.为了解决这一问题,TransH模型[5]引入超平面机制,将h和t投影到关系的特定超平面中,使得实体在不同关系的超平面中具有不同的表示.TransR模型[6]将实体和关系都表示为语义空间Rd中的向量,每一种关系同时又对应着一个特定的关系空间Rk.CTransR通过将不同的头尾实体聚类成组,并为每个组学习不同的关系向量来扩展TransR,但是TransR模型运算量大且参数多.TransD模型[7]对每个实体或关系使用2个向量进行表示,一个向量表示语义,另一个用来构建映射矩阵,以向量的乘积代替矩阵,减少模型的参数规模.以上模型都限制平移要求,导致翻译原则不灵活.TransM模型[19]在计算得分函数时,为每个三元组赋一个预计算的权重,该权重反映在该关系下的实体节点的度.TransF模型[20]只须保证h+r的方向与t的方向相同即判定三元组成立.TransA模型[8]为每个关系r引入一个对称的非负矩 阵Mr,并使用自适应马氏距离定义评分函数.
1.2 语义匹配模型
RESCAL模型[21]用向量表示实体,用矩阵表示关系,通过自定义的得分函数捕获三元组的内部交互.DistMult模型[22]通过将Mr限制为对角矩阵来简化RESCAL.ComplEx模型[23]通过引入复值嵌入来扩展DistMult,以便更好地对非对称关系进行建模.上述三者都属于语义匹配模型,通过匹配实体的潜在语义和向量空间中的关系来衡量三元组的准确性.
1.3 融合附加信息模型
目前大多数研究只对三元组自身结构进行嵌入,将实体和关系表示到连续向量空间中,并定义评分函数衡量真实性.事实上,KG中还隐含着其它丰富的信息可以提高知识表示能力,将文本描述信息、图拓扑结构、逻辑规则、关系路径、视觉信息和时序信息等外部信息与KG相结合来提高知识表示的有效性.Zhang等[24]利用关系簇、关系和子关系的层次关系结构扩展现有的嵌入方法.GAKE模型[25]同时使用邻居、边、路径3种上下文融入图结构信息.Guo等[26]提出一种融合三元组事实和逻辑规则的联合表示学习模型,视觉信息也可以提高知识表示能力.IKRL模型[27]将图像编码到实体空间,并遵循翻译原则.夏光兵等[28]通过融合实体的文本描述信息、层次类型信息和图的拓扑结构信息,充分利用三元组以外的多源异质信息来提高知识图谱各类任务的效果.杜文倩等[29]同时学习三元组信息、实体描述以及实体类型信息来处理一对多、多对多等复杂关系.Wang等[30]首次将概念和实例进行联合嵌入,基于邻居信息和所属概念为实例,设计预测函数,使实例的嵌入更具表现力.
翻译模型是根据距离公式计算向量的组合,因此,实体关系向量本身的特征信息没有得到很好的应用.融合附加信息模型具有较高的链接预测准确率,但是只针对实体进行信息融合,并没有融合关系描述信息,语义可解释性较差.在充分利用KG的结构信息基础上,文本提出方法融合外部文本信息,以获得实体和关系的向量表示,具有良好的语义解释和较高的预测精度.
2 ETLKRL模型
2.1 模型结构
联合表示学习模型是建立在三元组本身的结构向量之上.实体描述信息丰富了实体的语义,层次类型能够区分在不同关系下实体的不同属性,关系描述信息使得关系的语义更精确,充分利用结构信息和提取文本有效特征,从而更好地增强向量表示,具体的模型结构如图1所示.ETLKRL模型的能量函数E由4个部分决定:

图1 ETLKRL模型整体框架Fig.1 Overall framework of ETLKRL model
ES为三元组自身结构的能量函数:
式中:hS、rS和tS分别为头实体、关系和尾实体的自身结构.
ED为基于文本描述的能量函数,为了使得ES和ED相兼容,ED定义为:ED=EDD+EDS+ESD.
式中:hD和tD分别为头实体和尾实体基于文本描述.
ER为文本关系的能量函数:
式中:hS和tS分别为头实体和尾实体的自身结构,rR为关系向量.
EL为层次类型的能量函数:
式中:hL和tL为通过层次类型投影构建的头实体和尾实体的层次类型.
2.2 文本信息嵌入
现有的大型知识库如维基百科都包含大量的文本描述信息,利用文本信息辅助增强三元组的语义成为表示学习的关键步骤.如图2所示,在Freebase中,文本描述信息包含对实体和关系的简洁描述,并非每个句子都包含被描述的实体和关系.本研究利用CNN实现相关文本描述的嵌入向量表示,根据句子中实体引用的差异对文本实体向量和文本关系向量进行分类.
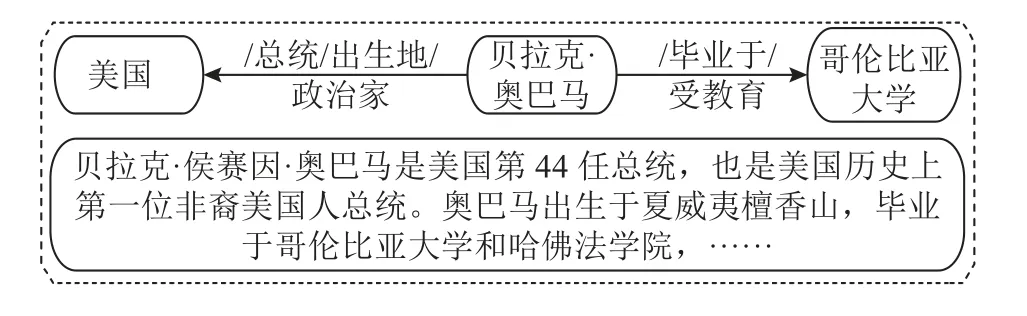
图2 在Freebase中文本描述的示例Fig.2 Example of text description in Freebase
2.2.1 实体描述信息表示 实体描述信息包含丰富的实体语义,可以作为KG的额外信息增强表示学习效果.如图2所示,文本描述信息中隐含着对三元组实体的描述,充分利用这些文本描述信息成为联合表示学习的关键.根据Zhao等[31]提出的方法,利用实体描述作为补充,并获得基于文本描述的实体表示,即hD和tD.当获得实体所在的句子时,表示的集合为Es= (s1,s2, ···,sn),假设窗口大小为k,将滑动窗口设置为1即可获得si,si=si+k-1=(w1,w2, ···,wi,wi+1, ···,wi+k-1).由于每 个文本长短不同,需要在短文本末尾进行补零使得文本对齐, 对于每个文本句子,具体的卷积操作如下.
1) 假设经过预处理过滤掉停用词后的文本长度为n,每个单词的嵌入维度为k,则该文本可以表示为n×k维矩阵作为卷积操作的输入.
2) 将滑动窗口设为1,过滤器有l个通道,卷积核宽度为单词向量的维度,每个卷积核设置为m×k.
3) 每次卷积运算后都会得到一个n-m+1维的输出向量,通过最大池化操作优化向量的特征信息.
4) 最后通过维度矩阵转换得到k维文本向量.
经过卷积运算后,得到与实体关联的文本表示向量为
式中:Wc为卷积层的卷积核,bi为残差,tanh为激活函数.
使用最大池化策略优化语义并提高稳定性.将卷积运算后的输出向量划分为m大小的非重叠窗口,然后在每个连续特征窗口中选择最大值作为窗口的输出向量:
最终与实体相关联的文本信息的向量为
2.2.2 关系描述信息表示 在知识库中,一对实体的文本描述信息可能不同,每个句子对实体对之间关系的重要性也不同.为了解决这一问题,提出基于注意力机制的卷积神经网络,作用于包含一对实体的文本描述,以获得关系的向量表示.
注意力机制用于对指定实体的不同共现句执行语义特征组合,必须根据每个文本与关系r之间的关联程度,将与不同的权重信息进行组合.一个句子s由若干单词构成,单词之间的相对位置决定该句的语义.对于一个句子s= [w1,w2,···,wm],句子s中的每个单词向量wi是由基于词汇表的单词向量x和位置向量p组成,p= [d1,d2],d1和d2分别为头实体和尾实体的方向和距离.因此,单词向量表示为wi= [xi,pi],将含有m句共现实体的一组文本表示为S,S= {s1,s2, ···,sm}.利用卷积神经网络将每个句子编码为关系向量Yi,通过隐藏层进行转换得到最终的关系向量Ei:
式中:Ws为卷积核,bs为残差,Mk为转换矩阵.
每个句子对实体对之间关系贡献不同,根据句子所表示的实体向量和关系向量,计算每个句子的权重βi:
在表示过程中,假设三元组遵循h+r≈t,则th的结果可以近似表示实体对之间可能的关系,每个句子和实体对之间的关系权重用向量内积形式表示,最终关系定义为
2.3 层次类型信息表示
层次类型信息是外部信息的重要组成部分,对于知识表示学习具有重要意义.如图3所示,在Freebase中,同一个实体在不同场景下代表不同含义;实体的类型层次化,不同粒度的实体含义分布在不同层次的子类型上,且大多数实体具有复杂多样化的层次类型结构,一个实体可能呈现出多种层次类型,每种层次类型包含多个子层.根据Xie等[11]提出的方法,以层次类型结构l为例,其有m层,其中l(i)为l的第i个子类型,每个子类型l(i)只有一个父子类型l(i+1),最精确的子类型是第一层,最通用的子类型是最后一层.即l=(l(1),l(2), ···,l(m)).

图3 层次类型示例Fig.3 Example of hierarchy types
在知识图谱中,一个实体可能有多种层次类型,首先提出一种通用的层次类型编码器,将层次类型信息编码到表示学习中.对于任意一个实体,其投影矩阵为所有类型矩阵的加权和:
式中:Me为实体e的投影矩阵,n为实体e的类型数量,αi为权重因子,li是实体e的第i个类型,Mli为li的投影矩阵.
在不同的语义环境下,实体具有不同的含义,而知识图谱中关系的类型信息决定实体在不同关系中可能属于的类型,所以式(14)不再适用于特定环境.因此,对上述通用类型编码器做出改进,对于一个三元组,以头实体为例,投影矩阵为
式中:Lr,h为由关系特定类型信息给出的关系r中头实体的类型集.
尾实体的投影矩阵与头实体的投影矩阵类似.最终得到头实体和尾实体的层次类型表示:
2.4 模型训练
ETLKRL模型将三元组的结构信息、文本描述信息和层次类型信息相结合,以更好地对三元组的实体和关系进行表示.训练时采用基于边际的优化方法作为训练目标,损失函数定义为
式中:u、v、o分别为头实体、关系和尾实体.γ为衡量正例三元组和负例三元组的间隔参数,E(u,v,o) 为模型的整体能量函数,T为正例三元组构成的集合,T'为从T中经过替换头尾实体得到的负样本,定义如下:
根据式(17)可知,对于正确的三元组,L分数越低,代表性能越好.当模型优化时,采用随机梯度下降法(SGD)来最小化损失函数.在训练开始时,实体和关系的文本描述参数集和子类型投影矩阵随机初始化,三元组自身的实体和关系使用TransE模型通过预先训练的嵌入进行初始化.
3 实验及结果分析
3.1 数据集
使用WN18、WN18RR、FB15K、FB15K-237和YAGO3-10数据集,具体的数据数量如表1所示,其中,N为数量.WN18[7]按照术语的语义进行分组,反映实体间的内部属性.FB15K[4]包含丰富的上下文信息,具有多种数据类型.对于YAGO3-10[32]数据集进行预处理,保留超过10个与实体相关联的关系的三元组.WN18RR[33]与WN18相比,消除反向关系,提供更真实的表示方法为基准.FB15K-237[31]数据集通过删除反向关系从原始Freebase数据集FB15K中提取.与WN18RR和YAGO3-10相比,FB15K-237数据集更具有复杂的关系类型和更少的实体.
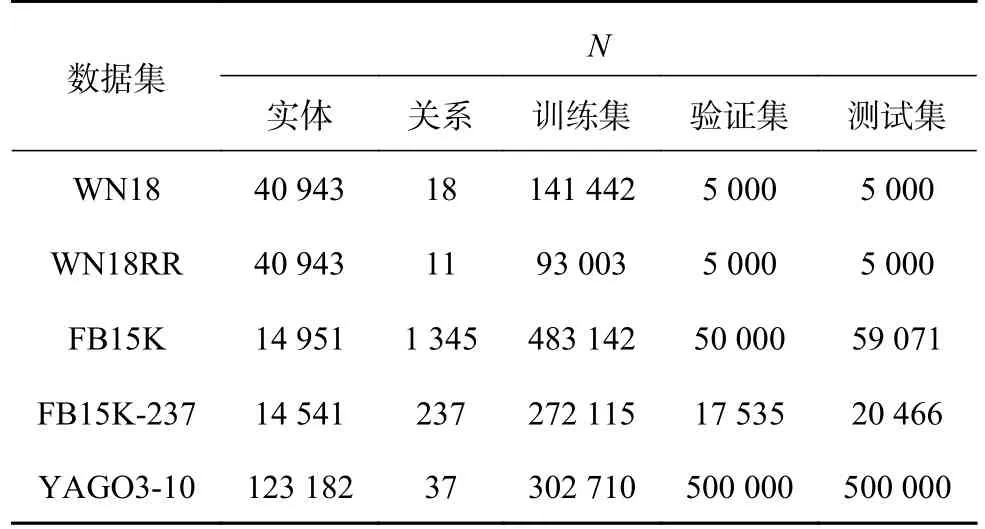
表1 各数据集的数据数量统计Tab.1 Data quantity statistics for each data sets
3.2 实验设置
使用SGD对ETLKRL模型进行训练,设定以下参数的取值范围:batch_sizeB∈(20, 240, 1200,4800),学习率λ∈(0.0005, 0.0010, 0.0020),最大间隔γ∈(0.5, 1.0, 2.0, 4.0, 7.0),实体和关系的向量维度n∈(50, 80, 100),投影矩阵为n×n,单词和句子嵌入维度为(50, 80, 100),加权层次编码器的权重η∈(0.10, 0.15, 0.25, 0.30).
3.3 链接预测
由于数据集中只存在正例三元组,没有负例三元组,需要从数据集中生成负样本.使用二项分布判断一个三元组是否作为负例三元组.现有数据集具有数据不对称的特点,头实体和尾实体之间的关联程度差异大,极大地影响复杂关系数据集上模型预测的准确性.为了减少数据集不对称性对实验准确性的影响,对于可能被填充为负例的实体,以概率q替换头实体,以概率1-q替换尾实体.
3.3.1 实体预测 实体预测是指去除三元组的头实体或尾实体,在缺失部位替换任意实体,通过评价指标评估预测的准确性.常用的评价指标为MeanRank和Hits@n.MeanRank为预测正确实体的平均排序得分,MeanRank值越小表示排名越靠前;Hits@n为正确实体排在前n名的概率,该值越大表示效果越好.将未经处理的实验设置称为“Raw”,剔除对实验有干扰的负例三元组的实验设置称为“Filter”.记录所提模型和基线模型在实体预测任务上的MeanRank和Hits@n,实验结果如表2所示.

表2 在WN18和FB15K数据集上不同模型实体预测的评估结果Tab.2 Evaluation results of different model entity predictions on WN18 and FB15K data sets
1)在WN18和FB15K这2个数据集上,ETLKRL模型的MeanRank和Hits@10均优于大多数基线模型.通过融合实体描述信息、文本关系和层次类型信息可以增强知识表示并提高链接预测性能,在构建知识表示时具有重要意义.
2)在WN18数据集上,ETLKRL模型的性能明显优于TransE模型, MeanRank(Filter)值比最好的基线模型TransD降低了11.8%,Hits@10提升了6.5%.通过引入注意力机制更好地提取文本的有效特征,证明了ETLKRL模型比翻译模型具有更高的知识表示能力,提高了预测精度.
3)在FB15K数据集上,ETLKRL的Hits@10实验结果略低于ConvE模型[33],因为FB15K数据集的内部关系密集,结构相对复杂,ConvE模型擅长建模三重复杂结构信息.ETLKRL模型提取外部文本信息进行融合,从而略微降低结构表征学习的性能.
为了证明ETLKRL模型具有更好的表示能力,进一步预测模型在不同关系类型中的Hits@10值,根据TransE的实验思路,将预测的目标实体划分为更详细的类型,如“1-1”、“1-N”、“N-1”和“N-N”,以更好地分析头实体和尾实体之间不同关联程度的实验效果.对于FB15K数据集进行深入分析,发现FB15K中的1-1关系数有323个,1-N关系数有309个,N-1关系数有390个,N-N关系数有323个.实验结果如表3所示.
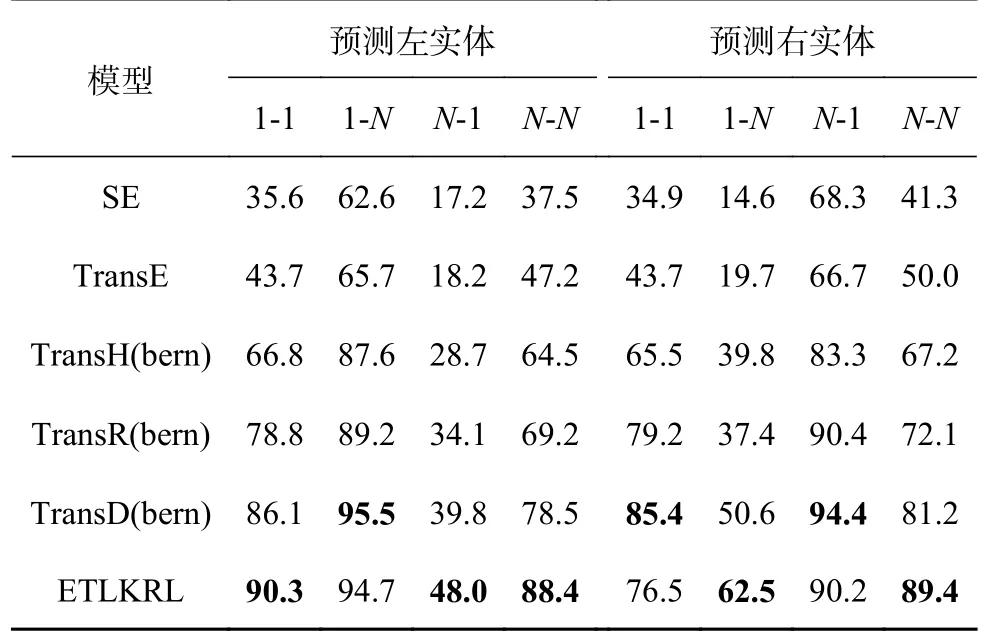
表3 在FB15K数据集上各类关系的Hits@10值Tab.3 Hits@10 values of various relationships on FB15K data set %
1)所提的ETLKRL模型和基于翻译的模型相比,整体上优于基线模型,充分证明了利用文本描述信息和层次类型信息可以作为结构化模型的补充.使用CNN对文本描述信息进行处理,增强了实体结构向量在现有KG中的表示.
2)在FB15K上,ETLKRL模型在预测头实体和预测尾实体方面都取得了较好的结果.尤其在N-N上的结果最为突出,在预测头实体和尾实体结果中,与最好的基线模型TransD(Bern)模型相比分别提高了12.6%和11.1%,表明同时融合层次类型信息和文本描述信息可以有效弥补外部信息不足的问题.
为了进一步证明ETLKRL模型能够更好的完成预测任务,在YAGO3-10数据集上进行相关实验.对比于WN18RR更复杂并且具有清晰语义层次的YAGO3-10数据集,该数据集包含来自维基百科的大量三元组.为了保证实验的有效性,对数据集进行预处理,保留出度和入度在10~20的三元组,在MeanRank、Hits@10、Hits@3和Hits@1评价指标上预测模型的性能.实验结果如表4所示, ETLKRL模型在Hits@3和Hits@1的性能指标上优于其他基线模型,表明融合文本信息后提高预测的精确度,适用于节点相关性高的复杂知识图谱.在MeanRank和Hits@10评价指标上不如ConvE,分析有以下2点原因:1)ConvE模型直接对知识图谱内部结构建模;2)YAGO3-10数据集的关系链接极其复杂,文本信息对数据集没有显著的语义补充效应.

表4 在YAGO3-10数据集上不同模型的链路预测结果Tab.4 Link prediction results of different models on YAGO3-10 data set
3.3.2 关系预测 关系预测是指给定缺失三元组(头实体,?,尾实体)预测关系,为了证明模型的特定关系预测能力,在FB15K数据集上进行关系预测实验,并记录ETLKRL模型和基线模型的MeanRank和Hits@1实验结果.如表5所示, ETLKRL模型的所有评价指标均优于其他基线模型.一方面,DKRL模型的思想是使用连续词袋模型和卷积神经网络模型处理文本描述信息,需要大量数据集才能更好地使模型收敛,降低关系预测的能力;另一方面,使用FB15K数据集,在测试集中存在与训练集相反的关系,比TransE模型的预测结果稍有提高,从而证明了使用注意力机制的卷积神经网络作用于包含一对实体的文本描述s,可以有效获得关系的文本表示向量.充分利用知识图谱的外部信息可以准确预测三元组中缺失的关系并提高关系预测的性能.
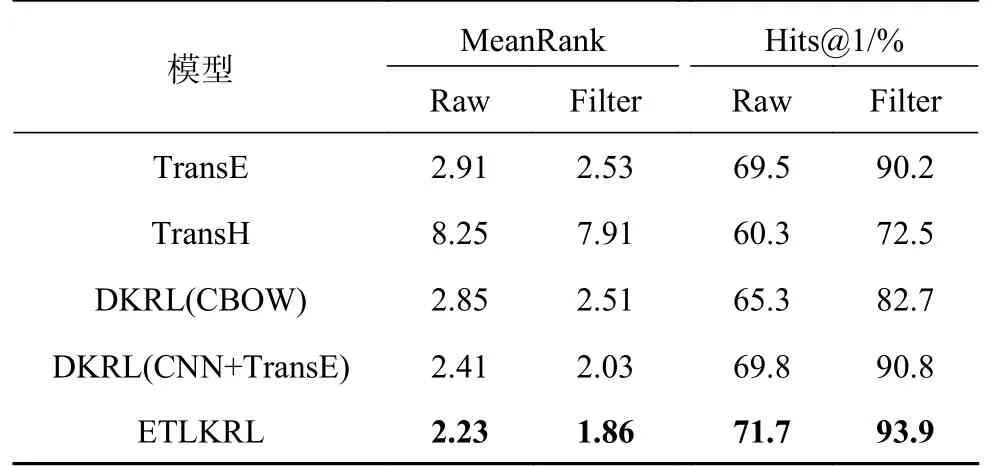
表5 在FB15K数据集上不同模型关系预测的评估结果Tab.5 Relationship prediction results of different models on FB15K data set
3.4 三元组分类
三元组分类的目的是判断一个给定三元组是否正确,主要任务是对一个三元组进行“正确”或“错误”的二元分类.对于一个三元组,如果其得分小于给定的阈值σr,则预测正确,反之则错误.σr由验证集获得最大分类精度时的阈值所决定.在进行三元组分类实验时,选用在WN18和FB15K数据集.三元组分类任务主要使用准确率(ACC)作为评价指标.ACC越高表示模型在三元组分类这一任务上的效果越好,准确率的计算公式为
式中:Tp为预测正确的正例三元组个数,Tn为预测正确的负例三元组个数,Npos和Nneg分别为训练集中的正例三元组和负例三元组的个数.
结果如表6所示,从表中可以看出,ETLKRL模型在三元组分类任务上的结果均优于其他基线模型,在FB15K上的分类精度比DKRL模型高8.4%,比TKRL模型高8.5%,证明了同时融入文本描述信息和层次类型信息可以增强表示能力,弥补稀疏知识图谱中信息不足问题;基于注意力机制的特征提取的方法能够有效的获取与实体相关的文本特征信息,并增强表示结果.
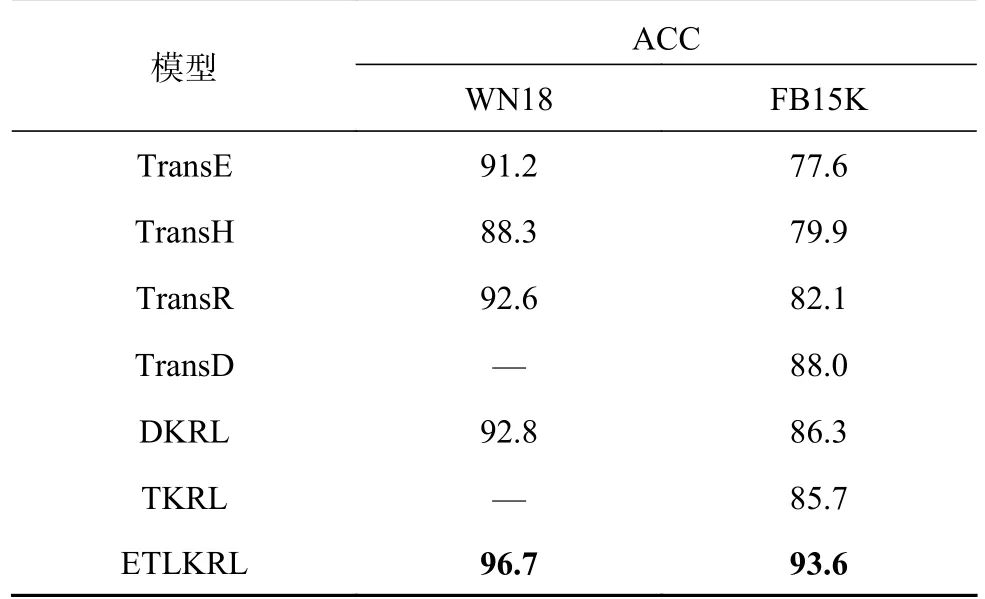
表6 在FB15K和WN18上不同模型的准确率结果Tab.6 Results of different model accuracy rates on FB15K and WN18 data sets %
3.5 模型的复杂度
为了直观展示参数规模m和迭代次数n对模型的影响,在WN18RR和FB15K-237这2个数据集上进行对比实验得到对应的平均倒数排名值(mean reciprocal rank ,MRR).结果如图4所示,(a)和(b)为在WN18RR数据集上的结果,(c)和(d)为在FB15K-237数据集上的结果.与其他基线模型相比,在参数规模和迭代次数相同的情况下,ETLKRL模型的性能优于其他基线模型.对于WN18RR大多数类型的关系将2个不同层次的实体连接在一起,因此ETLKRL模型通过融合层次类型信息具备更优表示的能力,从而提高实体预测性能.
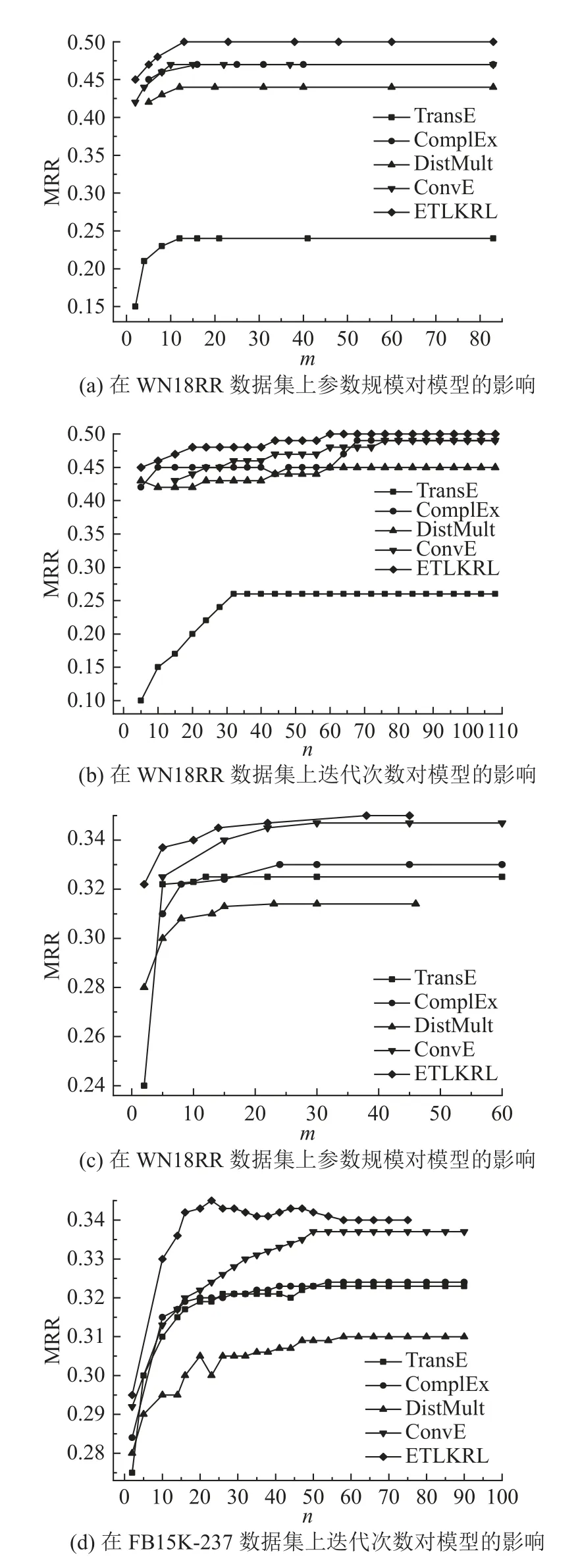
图4 参数规模和迭代次数对模型的影响Fig.4 Influence of parameter size and iteration times on model
4 结语
本研究提出一种融合文本描述信息和层次类型信息的联合表示学习方法,使用CNN构建实体描述表示,使用加权CNN从文本信息中构建关系的表示,使用加权层次编码器来构造层次类型的投影矩阵,将实体的所有层次类型投影矩阵与特定于关系的类型约束结合起来.在WN18、WN18RR、FB15K、FB15K-237和YAGO3-10数据集上,进行链接预测和三元组分类实验.结果表明,所提方法在所有实验任务上都优于其他基线模型,充分证明利用外部信息可以增强实体和关系向量的语义表示.
1)ETLKRL 模型是基于TransE模型,未来可以尝试扩展到其他模型如TransR或TransD提高表示能力;
2)KG中还存在其他附加信息如关系路径、图像视觉信息和逻辑规则等,在后续研究中可以融合多源异质信息进一步优化ETLKRL模型.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
山西大学学报(自然科学版)(2021年1期)2021-04-21
中国外汇(2019年18期)2019-11-25
五邑大学学报(自然科学版)(2019年3期)2019-09-06
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
计算机工程与设计(2015年1期)2015-12-20
