
基于改进Transformer的复合故障解耦诊断方法
2023-05-16 11:06王誉翔钟智伟夏鹏程黄亦翔刘成良
浙江大学学报(工学版) 2023年5期
王誉翔,钟智伟,夏鹏程,黄亦翔,刘成良
(1.上海交通大学 机械与动力工程学院,上海 200240;2.上海交通大学 机械系统与振动国家重点实验室,上海 200240)
在故障诊断领域,目前主要研究集中在单一部件的单一故障类型的故障诊断,如对轴承和齿轮的故障诊断方法[1-3].在实际工程环境中,机械系统不同的零部件是高度耦合运行的,往往会发生一个部件上多处故障、多个部件同时故障等多种复合故障的情况[4-5].针对单个部件及单一故障类型的诊断模型易受到环境噪声、传递路径等因素影响,模型准确度会极大地降低[6].以振动信号为例,当复合故障出现时,不同故障之间会互相影响,使得采集到的振动信息不再是不同故障状态下振动信息的简单叠加,会出现谐振等复杂现象,复合故障诊断更为复杂和困难.因此需要考虑故障解耦方法,即输出复合故障为内部单一故障组合.若是不对复合故障进行解耦分析,将导致故障分析粒度含糊、解释性差,不利于机械设备按不同单一故障制定针对性的运维措施以及设备的再设计.
目前常见的复合故障诊断大致可以分为2类,一类是基于经验和模型的,另一类是基于数据驱动的.前者一般利用信号处理的方法和一定的先验知识进行定性分析.Li等[7]在基于模型方法研究下复合行星齿轮组的太阳轮故障的特性,建立一个三维块状参数非线性动态模型,用来进行故障分析.Lyu等[8]基于量子遗传算法改进最大相关峰度解卷积方法,处理轴承和齿轮的复合故障信号,与功率谱和包络谱分析结果对比,提出的方法在复合故障分析上具有良好的效果.随着机械设备实际运行的负载、工况条件越来越复杂,传统的基于模型和经验的分析很难全面覆盖到所有情况,建模复杂度和计算量将指数倍增,难以应用于实际工况环境中,而基于数据驱动的复合故障诊断则可以很好地解决这个问题.陈仁祥等[9]利用一维卷积神经网络和领域自适应学习单一故障和复合故障中的特征,以实现对旋转机械的复合故障.Huang等[10-11]最早将深度学习的思想引入到轴承和齿轮的复合故障诊断中,并利用多个传感器的数据和多个预训练模型实现较高准确度的复合故障诊断.Jin等[12]使用解耦注意力残差网络进行轴承的复合故障诊断,并引入主动学习的概念.吴守军[6]使用一维深度卷积神经网络进行齿轮箱的复合故障诊断,在一定量复合故障数据的前提下,可以实现良好的诊断效果.Liang等[13]用小波变换处理原始振动信号,进一步将小波变换图像结果传递给多标签神经网络进行分类,通过同时训练单一故障数据和复合故障数据,实现较高的故障诊断准确率.Zhang等[14]提出一种混合不平衡学习方法,用以解决复合故障数据量与单个故障数据量不平衡的问题.
上述常见的复合故障诊断算法仍然存在一定局限性,原因有以下几个方面:1)绝大多数故障诊断方法[9,15-16]仅仅将复合故障简单等同于一种新的单一故障类型,没有充分考虑复合故障和组成复合故障多个单一故障之间的关系,并且故障分析粒度含糊、解释性差.不利于机械设备按不同单一故障制定针对性的运维措施以及设备的再设计.因此,需考虑故障解耦的方法,即输出复合故障作为内部单一故障的组合.2)基于数据驱动的复合故障诊断方法具有不错的诊断效果,但是大部分都需要大量的单一故障数据和一定的复合故障做预训练[11-13],有些方法甚至需要多传感器数据,在实际工业环境中往往难以获得大量的故障数据[17].针对以上所述的问题,提出了一种基于改进Transformer的复合故障解耦诊断方法,可以在一定量单一故障数据和极少量复合故障数据样本情况下实现较高的故障诊断准确度.
主要贡献包含以下几点:
1)Liu等[18]将Transformer应用于图像的多标签分类,进一步验证Transformer中多头注意力机制的有效性.因此本研究引入Transformer的解码器以及提出一种新型的故障解耦分类器.与传统诊断方法中视复合故障为与单一故障毫无关联的新故障类型不同,故障解耦则充分考虑了复合故障和单一故障之间的联系;
2)结合基于STFT的特征提取方法和所提的新型故障解耦分类器,本研究提出一种基于改进Transformer的复合故障解耦诊断方法.通过行星齿轮箱的复合故障实验数据验证,所提方法可以在仅训练一定量单一故障数据和极少量复合故障数据的情况下,有较高的复合故障诊断准确度.
1 基于改进Transformer的故障解耦分类器
1.1 故障解耦分类器
传统的故障分类器和故障解耦分类器的直观区别在于分类器一次输出的标签个数.如图1所示,上侧部分即为传统故障分类器的模型,下侧部分即为故障解耦分类器的模型.2种分类器的输入均为特征提取得到的特征值,传统分类器仅能输出一个故障标签,故障解耦分类器则可一次输出多个标签.当面对复合故障时,由于传统分类器仅能输出一个标签,将复合故障视为一种新的故障类型[19],无法充分利用复合故障与单一故障之间的联系(标签与标签之间都为独立).故障解耦分类器将复合故障解耦输出成多个单一故障的组合,用多个单一故障的标签组合来代表复合故障,充分表达出复合故障与单一故障之间的关系.如图1下侧部分所示,用几个已知的单一故障标签即可排列组合表示出所有可能的复合故障情况.一般的传统故障分类器是通过softmax函数实现的,而一般的故障解耦分类器是通过sigmoid函数实现的.

图1 故障解耦分类器和传统故障分类器的区别Fig.1 Difference between fault decoupling classifier and traditional fault classifier
最终传统分类器的输出是式(1)输出最大值对应的第i个标签:
在一般的故障解耦分类器中,会预设一个阈threshold sigmoid(yi)i值 ,如果 大于阈值,则输出第个标签,最多可以输出n个标签:
1.2 基于改进Transformer的故障解耦分类器
标准Transformer方法最早应用于自然语言处理(natural language processing, NLP)领域[20]的机器翻译.与同时期其他深度学习方法相比,Transformer 依赖内部的多头注意力机制,可以精确捕捉到长文本中各个词的位置与含义,因此在机器翻译中具有明显优势.Transformer开始广受学者关注,并被不断改进应用到图像、视觉等[21]其他领域.Transformer采用编码器-解码器(encoder-decoder)的架构.编码器主要包含多头注意力层(multi-head attention)和前馈连接层(feed forward module),而解码器相比于编码器增加了遮罩多头注意力层(masked multi-head attention).在机器翻译中,标准Transformer的处理方法是先由编码器对长文本进行位置编码和特征提取,而后输入到解码器中,解码器再结合输入词向量对编码器的特征提取结果进行解码,最后得到每个输入词向量的概率并输出完成机器翻译.Transformer结构的成功主要得益于内部的多头注意力机制,这一机制可以使得模型学习到输入的上下文信息,对不同输入的词向量关注到不同长文本的位置.复合故障解耦的关键在于模型是否能够在复合故障中发现耦合的单一故障,基于标准Transformer结构,设计一种基于改进Transformer的故障解耦分类器.
相比于原生Transformer编码器-解码器的结构不同,本研究仅使用了Transformer中的解码器.在该故障解耦分类器中,输入特征提取得到的特征层,输出一个或多个故障标签.具体的工作过程与一般的解耦分类器不同,该故障解耦分类器是通过对提取的特征层进行一次次标签查询(query)来判断是否输出某个标签.故障解耦分类器会一次次用“点蚀”、“磨损”、“断齿”等标签到特征提取层进行“查询”,进一步通过“查询结果”来判断是否输出“点蚀”、“磨损”、“断齿”等标签,“查询结果”就对应于故障的标签输出概率.(“一次次”只是为了形象介绍解耦分类器的工作原理,实际可以通过矩阵运算一次性得到所有标签的输出概率结果,具体计算公式将在2.3节详细阐述.)上述功能的实现依赖于Transformer中解码器的交叉多头注意力机制.之所以称为交叉多头注意力机制,是因为该模块同时连接左侧提取的特征层和下侧的标签查询信息,将标签查询的信息引入到提取的特征层,因此使得解码器可以自适应提取出与标签对应的特征信息,进一步对该标签的输出概率进行预测.
2 复合故障解耦诊断方法
2.1 数据处理模块
为了减少噪声干扰,传感器一般安装在被监测设备附近,采集到的原始振动信号如图2所示,其中t为时间,A为振动的幅值.根据故障机理可知,不同故障的区别在频域比时域更明显.为了提取出振动信号中的频域信息同时保留一定的时域信息,将先使用时频处理工具对原始振动信号进行预处理.基于信号处理的稳定性、通用性的考虑,选择STFT作为时频处理工具,STFT的结果如图3所示.使用Tukey窗函数进行STFT,其中f为振动的频率,窗函数的长度为255,窗函数重叠数为170.
图2 传感器采集的振动信号Fig.2 Original vibration signal collected from sensors
图3 预处理后的STFT图像Fig.3 Preprocessed STFT spectrum
2.2 特征提取模块
图4是所提方法的算法流程图,其中左下角部分则为特征提取模块,右侧是故障解耦模块的示意图,计算流程可以分为2个部分,即查询标签更新和概率预测,N为模块个数.特征提取模块主要用来进一步提取处理后的STFT图像中有效的特征值,由一个三层卷积神经网络组成.前2层分别包含一个二维的卷积层(Convolutional2d)、ReLU层和最大池化层(Maxpooling2d),最后一层仅包含卷积层和ReLU层,卷积层和ReLU层间通常会进行批归一化处理.详细的网络模型参数如表1 所示.其中 为特征提取模块最终的输出维度,也是所提方法中提取特征值的维度.
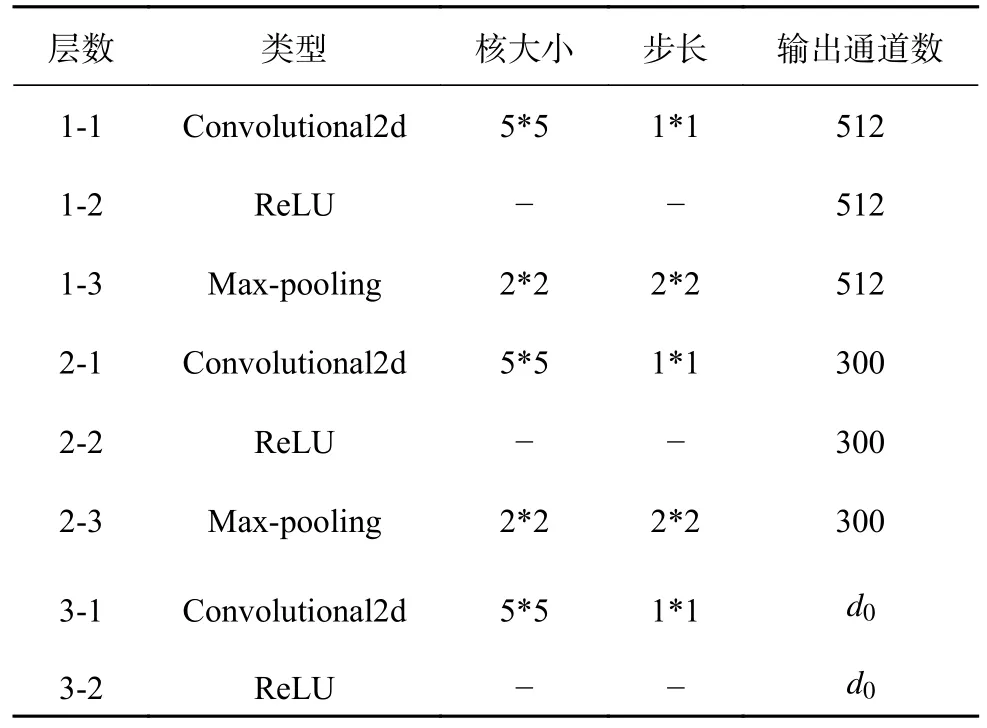
表1 特征提取模块的网络模型详细参数Tab.1 Detailed parameters of network model
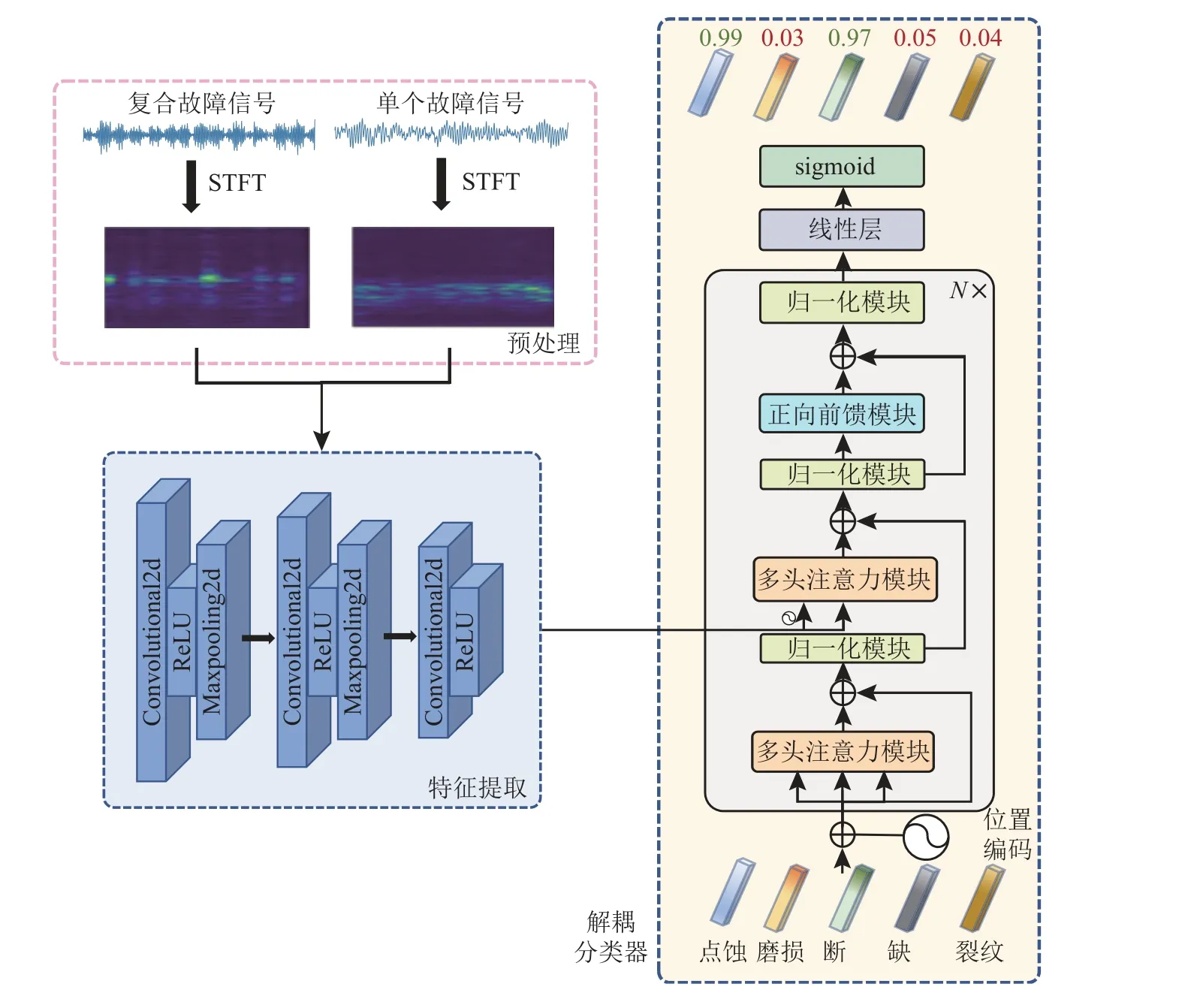
图4 基于改进Transformer的复合故障解耦诊断方法流程图Fig.4 Algorithm flowchart of compound fault decoupling diagnosis based on improved Transformer
2.3 故障解耦模块
多头注意力机制的主要优势是可以根据不同的标签自适应地关注到与标签对应的局部的判别特征区域[20],这一优势也是将其引入到故障解耦模块中的主要原因.在该模块中,每个查询(query)标签对应一种单一故障类型.在故障诊断的过程中,用每个查询标签依次判断输入特征中是否包含标签对应的单一故障特征,如果是则输入该单一故障标签.当所有查询标签轮询判断后,即可实现复合故障的解耦输出.多头注意力机制可以借助标签信息从不同角度或不同位置观察输入特征,因此复合故障模块可以更有效地关注到各个单一故障相联系的局部判别特征区域.
2.3.1 查询标签更新 对输入到故障解耦模块的特征值,使用标签进行查询判断是否输出标签对应的单一故障类型.在判断输出之前,会先将每个标签输入到解耦分类器中和提取的特征一起更新迭代,根据标签更新的结果再判断是否输出.标签更新的过程可以用矩阵运算表示(使用矩阵可以将多次标签轮询的过程转换为一次计算的过程).例如,设被检测设备的常见单一故障种类为K-1种 ,则可输出的标签有K个(包含正常状态的标签).设查询标签矩阵为Q0∈RK×d,其中d为每个查询标签的维度,则为第i个查询标签.将查询标签矩阵输入到故障解耦模块中(如图4右下方),该查询标签矩阵会依次经过2个多头注意力模块(第1个多头注意力模块的输入只包含查询标签矩阵,第2个多头注意力模块的输入包含查询标签矩阵和提取的特征值)和1个前馈连接模块.该更新过程将重复N次(N为解码器堆叠模块的个数).2个注意力模块和前馈连接模块的迭代更新为
式中:Q为经过位置编码的和为2个间接变量矩阵,M ultiHead(query,key,value) 和 FFN(x)为标准Transformer解码器中多头注意力函数和前馈连接函数,为特征提取模块得到的特征矩阵,是经过位置编码的.由于不需要进行自回归预测,所以 m ultiHead函数不再需要进行遮罩.因此 ,K个标签在每层的计算中都可以并行计算.2.3.2 概率预测 在查询标签迭代更新后,则进行标签输出的概率预测.根据上文所述,查询标签更新的结果(经过正向前馈模块处理后)为QN∈RK×d,为了进行标签输出的概率预测,需要进一步对比查询标签更新的结果进行处理.如图4右上方所示,将对QN再进行线性化处理,然后输入到 sigmoid 层.sigmoid的 输 出结果在0~1.0,此处可以视为标签的输出概率.线性层和 sigmoid层的处理同样可以通过矩阵运算实现:
式中:Wk∈Rd,W=[W1,···,Wk]T∈RK×d;bk∈R,b=[b1,···,bK]T∈RK是线性层参数;p=[p1,···,pK]T∈RK为K个标签的预测概率.
2.4 复合故障解耦诊断流程
所提复合故障解耦算法的流程图如图4所示,主要计算步骤如下.
S1:对传感器直接采集到的原始信号进行预处理,使用短时傅里叶变换(short-time fourier transform, STFT)得到时频域图像.
S2:将时频域图像输入到特征提取模块进行特征提取,并将提取的特征值作为故障解耦模块的输入.
S3:设有K个故障标签,则初始化K个查询标签,将特征提取得到的特征值,作为第2个交叉注意力模块的输入.在训练阶段时,通过端到端的训练可以使得最后模型的每个查询标签都准确代表对应的故障类型.在测试阶段中,各个标签和提取的特征会经过多头注意力模块、正向前馈模块的迭代更新,最终经过线性层和sigmoid映射得到对应单一故障的输出概率.本研究设置输出概率阈值为0.5,当sigmoid映射结果大于阈值时,则输出单一故障对应的标签,反之则不输出.在所提方法中,每个查询标签都有确定的物理意义,代表着某个对应的故障标签,这也是所提方法与DETR(detection transformer)[22]的区别所在.
3 复合故障试验
3.1 试验说明
为了验证所提方法的有效性,设计了多组复合故障试验进行验证.数据集采集自动力传动故障诊断综合试验台,如图5所示.该试验台主要包含1个感应电机,1个行星齿轮箱和1个平行轴齿轮箱.行星齿轮箱和平行轴齿轮箱主要是由感应电机进行驱动,磁力制动机和负载控制器安装在平行轴齿轮箱右侧,用来施加负载,传感器安装位置如图6所示,用于采集振动信号.

图5 动力传动故障诊断综合试验台Fig.5 Power transmission fault diagnosis test bench
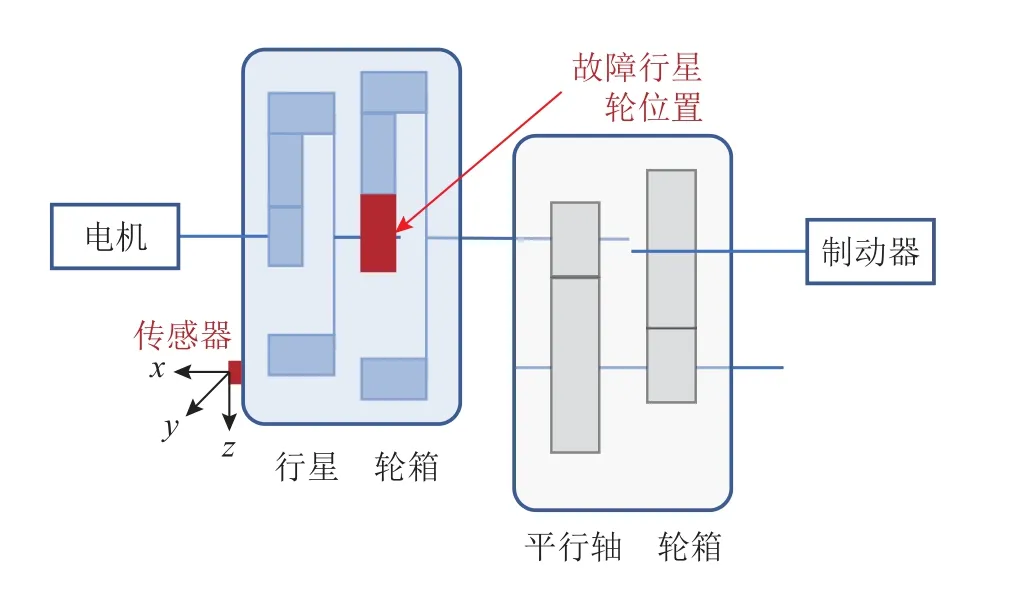
图6 动力传动故障诊断综合试验台示意简图Fig.6 Schematic diagram of power transmission fault diagnosis test bench
本次试验选择9个不同故障状态的行星齿轮,其中包含1个正常状态的齿轮、5个单个故障的齿轮和3个不同故障组合的复合故障齿轮(如图7).故障齿轮的位置如图6所示.9个齿轮的详细的健康状态如表2所示.
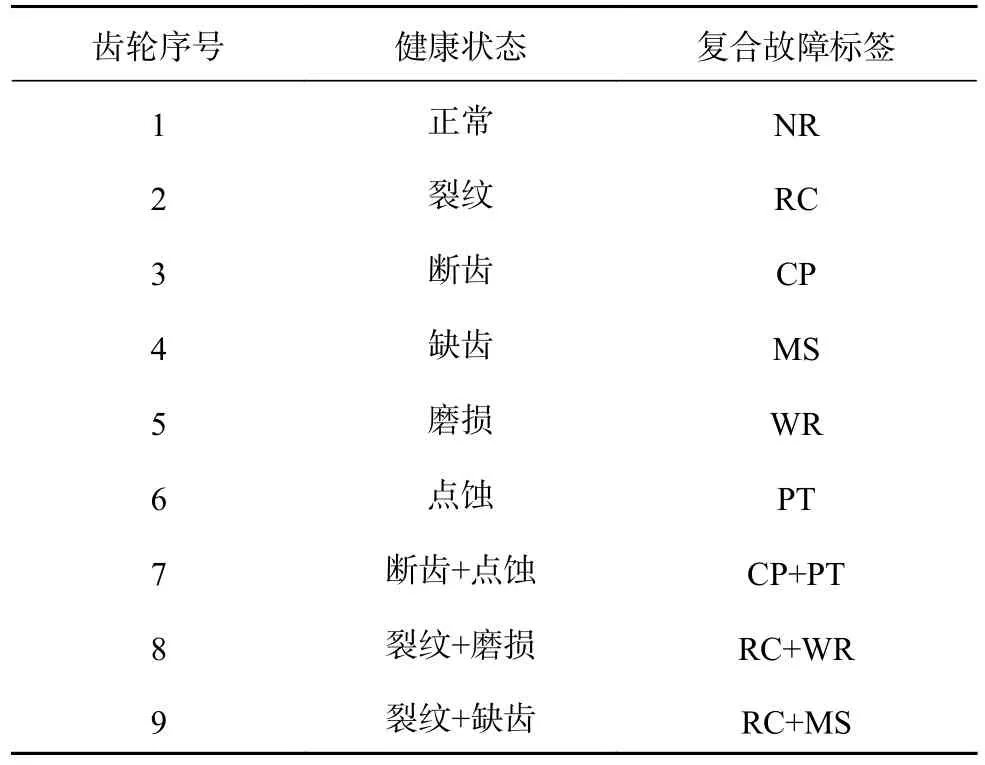
表2 本研究实验所用行星齿轮的健康状态Tab.2 Health status of planetary gear used in test

图7 3个不同故障组合的复合故障行星齿轮Fig.7 Three different fault combinations of compound fault planetary gear
在试验台运行在900 r/min的轴转速下,制动器负载为1 hp,采样频率为5120 Hz.为了采集到充足的数据用以模型验证,每个健康状态的行星齿轮的运行时间为6 min,并截取中间平稳运行部分作为实验验证的数据.
3.2 数据说明
在本次试验中,时序数据的样本长度设为2560,因此每个健康状态下的时序数据共有720个样本.对于单一故障和健康状态的数据,分别选择200个样本作训练集,520个样本作测试集(复合故障数据的训练集和测试集划分将在第3.4节详细说明).训练集用来对模型进行训练,测试集用来测试模型的准确率.
在训练过程中,设置正常、裂纹、断齿、缺齿、磨损和点蚀6个查询标签,并初始化6个独热编码向量(one-hot vector),将采集到的时序数据依次经过信号预处理模块和特征提取模块,得到有效的特征矩阵后输入到故障解耦分类器中.在解耦分类器的第1个解码器中,第1个多头注意力模块的query和key是经过位置编码的查询标签矩阵,value则是查询标签矩阵本身,而第2个多头注意力模块的query是上一个模块的输出,key是经过位置编码的特征矩阵,value则是特征矩阵本身,最后经过一系列迭代过程即可得到每个查询标签的输出概率.整个训练过程使用的是交叉熵损失函数.在测试过程中,对于任意健康状态的齿轮,只要输出标签和原标签不是完全相同,则认为是预测错误.
4 试验结果验证
4.1 极少量复合故障样本下诊断性能的研究分析
为了更好地模拟实际工业环境,将在训练样本中仅含少量单一故障样本数据和极少量复合故障样本数据的情况下,研究所提方法的故障诊断性能.为了验证所提方法的诊断效果,对比当前2种广受认可的复合故障诊断算法,下文简称这2种方法为Huang[23]和Liang[13]方法.Huang方法使用一维深度卷积神经网络对振动信号进行特征提取,进一步使用多栈式胶囊作为故障解耦分类器进行故障诊断.Liang方法先通过小波变换对振动信号进行处理得到二维时频图,进一步将时频图输入到多标签神经网络进行复合故障分类.将提出的基于改进Transformer的故障解耦分类器更换为一般的故障解耦分类器,即将特征提取模块的结果直接输入到一维的全连接层,并使用sigmoid函数作为故障概率输出(该方法下文简称STFT-CNN方法),与所提方法进行对比.考虑到公平性,上述4种方法在训练和测试的过程中均使用相同的数据集.在训练集方面,对于单一故障类型,每种故障选择200个样本作为训练集;对于复合故障类型,从0~30个逐步增加作为训练集,训练集中样本的选择为随机过程.为了避免偶然性,针对训练集中各个单一故障和复合故障比例情况,每种情况重复10次(包括随机选择样本作为训练集、模型训练与测试),取10次的测试结果的平均值为最终的诊断准确度.4种方法的学习率均设为0.001,训练轮数为50,选择Adam作为优化器.4种方法在不同复合故障样本数训练下的诊断准确度结果如图8所示.在不同情况下训练集中的单一故障样本数量是相同的,因此随训练集中复合故障样本数量的变化,单一故障的诊断准确度变化不大(均为98%以上),图8仅绘制不同情况下复合故障诊断的准确度,其中N0和 A CC分别为训练集中每种复合故障的样本和复合故障诊断诊断准确度.
从图8中看出,当训练集中仅使用极少量的复合故障样本时,所提方法在复合故障诊断准确度上明显高于其他3种方法.当训练集中每种复合故障的样本数为3个时,所提方法的复合故障诊断诊断准确度达到了59.32%,而Huang方法仅为28.14%,Liang方法仅为12.15%;当训练集中每种复合故障的样本数为5个时,所提方法的复合故障诊断诊断准确度达到了88.29%,而Huang方法仅为45.82%,Liang方法仅为31.91%;当训练集中每种复合故障的样本数为7个以上时,所提方法的复合故障诊断准确度可达到95%以上.

图8 不同复合故障样本数训练下的复合故障诊断准确度Fig.8 Diagnosis accuracy with different training samples of compound faults
为了进一步对比在训练集仅含极少量复合故障样本时所提方法和其他方法的区别,随机选择一组训练集,其中该训练集中每种复合故障的样本数为5,使用所提方法和Huang方法进行训练和测试,并绘制结果为混淆矩阵,如图9所示.相较于Huang方法,所提方法在极少量复合故障样本的情况下表现出显著优势.因为复合故障的正确输出标签应该为单一故障标签的组合,而且必须输出的所有单一故障标签与实际标签都对应才算分类正确,所以这对故障分类器提出较高要求.如图9(b)所示,Huang方法受到训练集中复合故障样本的干扰,使得除点蚀外的其他标签分类器对点蚀样本比较敏感.在识别点蚀故障时,将识别为其他所有故障标签组合(下文简称为OC),因此点蚀样本的识别率几乎为0.这是由于在极少量复合故障样本的情况下,Huang方法的故障解耦分类器并不能很好地对复合故障进行解耦,因此在面对复合故障的情况时,出现了较多的识别错误.所提方法在训练集中仅含极少量复合故障样本的情况下,则表现出理想的故障诊断效果,复合故障诊断准确率均处于98%以上.
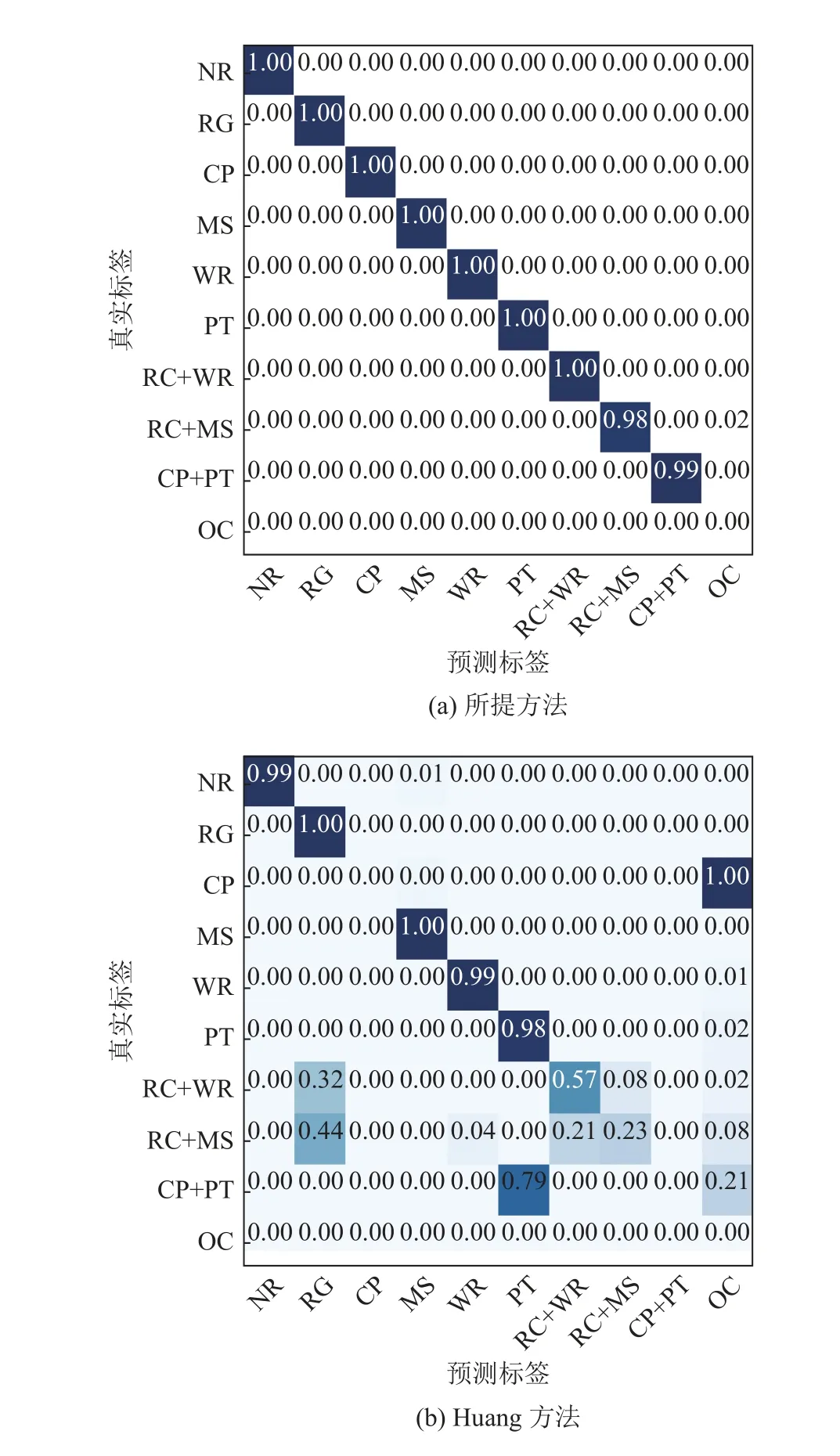
图9 每种复合故障的样本数为5时2种方法的诊断结果混淆矩阵Fig.9 Confusion matrix of two methods when number of samples for each compound fault in training set is 5
对比所提方法与STFT-CNN,2种方法的数据预处理模块和特征提取模块相同,仅故障解耦分类器不同,但是所提方法在极少量复合故障样本的情况下的诊断效果远好于STFT-CNN,这进一步说明基于改进Transformer的故障解耦分类器较一般的故障解耦分类器表现更好.该故障解耦分类器是所提方法在极少量复合故障样本数据情况下,仍具有理想诊断效果的关键所在.
4.2 基于改进Transformer的故障解耦分类器的解耦性能研究分析
基于改进Transformer的故障解耦分类器的故障解耦能力主要来源于内部的2大机制:交叉注意力机制和多头注意力机制.交叉注意力机制是图2中自下而上第2个多头注意力模块,因为同时连接左侧提取的特征层和下侧的标签查询信息,将标签查询的信息引入到提取的特征层.利用交叉注意力机制,当使用不同的故障标签进行查询(query)操作时,即可自适应提取出与故障标签相对应的特征,从而进一步对该标签的输出概率进行预测.当输入复合故障的数据时,通过使用单一故障标签进行查询操作,即可依次输出组合复合故障的单一故障标签,以实现故障解耦.
多头注意力机制指的是图2中2个多头注意力模块.相较于单头注意力模块,多头注意力模块可以从不同角度、不同范围提取与故障标签对应的特征,因而可以更全面地匹配到与故障标签相对应的具备区分度的特征.为了进一步验证交叉注意力机制和多头注意力机制的作用,随机选取3段代表不同复合故障类型的振动信号进行分析.对3段振动信号进行STFT变换,得到3段振动信号的STFT图如图10(a)~(c)所示.故障解耦模块中自下而上的第2个多头注意力模块的输出即为多头注意力矩阵.其中,(a)、(d)、(g)对应为第1段振动信号的处理结果,(b)、(e)、(h)和(c)、(f)、(i)分别对应第2、3段振动信号的处理结果;(a)-(c) 是3种复合故障对应的STFT图;(d)~(i) 是使用单一故障标签查询时得到的注意力图像.为了方便分析,将所有的多头注意力矩阵求均值,并可视化为图10(d)~(i).注意力矩阵中所有元素的取值为0~1.0,在图10 (d)~(i)中,颜色越暗表示该位置的元素越接近0,颜色越亮表示该位置的元素越接近于1.0.
从图10可以很直观看到,针对不同的查询标签,注意力矩阵可以准确地关注到每个故障最具区分度的位置区域.图10(f)为使用断齿标签查询的注意力图像,主要关注区域在1500 Hz附近,与断齿频谱图中幅值最大的频率相符.图10(d)~(f)为裂纹标签查询的注意力图像,主要集中在低中频区域,这主要因为裂纹的故障特征往往很小,在齿轮啮合的过程中对低中频区域都有影响,关注区域较大.图10(i)为点蚀标签查询的注意力图像,主要关注在0~200 Hz的区域,对于点蚀故障,该低频区域的特征与其他故障有较大区分度.图10表明,经过少量的单一故障样本训练,故障解耦分类器通过多头注意力机制可以捕捉到与故障标签强相关的特征区域,具备一定物理意义.所提出的解耦分类器通过交叉注意力机制自适应提取出对应的特征值,进行标签输出预测.复合故障的振动信号中掺杂谐振等复杂的信息,但是仅需要极少量复合故障数据进行注意力模块的修正,可以使得所提方法在面对复合故障时依然具有较好的诊断效果.

图10 对 3 段振动数据处理得到的 STFT 图像和多头注意力图像.Fig.10 Visualization of cross-attention maps and STFT spectrum of three segments of vibration signals.
5 结论
提出一种基于改进Transformer的复合故障解耦诊断方法,在少量单一故障数据和极少量复合故障数据情况下,具有较高复合故障解耦诊断准确度,细化故障分析粒度,有利于作为设备预防维护措施及再设计的依据.主要得到以下结论.
1)为了充分考虑和利用复合故障与内部单一故障之间的联系,不再将复合故障简单等同于一种新的单一故障类型,而是将解耦输出多个单一故障的标签,提出一种新的故障解耦分类器.该故障解耦分类器正是因为内部的交叉注意力机制和多头注意力机制,使得在故障解耦的过程中,可以自适应提取出与故障标签相对应的特征,进一步对各个故障标签的输出概率进行预测,从而实现复合故障解耦.
2)基于上述的故障解耦分类器,提出一种基于改进Transformer的故障解耦诊断方法.当训练集中每种复合故障的样本数为5个时,所提方法的复合故障诊断诊断准确度达到88.29%,而Huang方法仅为45.82%%,Liang方法仅为31.91%.由于在极少量复合故障样本的情况下,所提方法更好地区分复合故障中耦合的单一故障,因此能实现更好的解耦效果.
3)对所提出的解耦分类器进行深入的分析,并且可视化了多头注意力模块的输出结果.结果表明,多头注意力模块可以从不同角度、不同范围提取与故障标签对应的特征,因而可以更加全面地匹配到与故障标签强相关的特征区域,具备一定物理意义.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
电子制作(2018年19期)2018-11-14
电子测试(2018年1期)2018-04-18
传媒评论(2017年3期)2017-06-13
自动化学报(2017年11期)2017-04-04
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
第二课堂(课外活动版)(2016年2期)2016-10-21
噪声与振动控制(2015年4期)2015-01-01
电测与仪表(2014年15期)2014-04-04
