
基于BERT_BiGRU边界预测的中文意见目标提取
2023-05-14 14:13:23王丽亚陈哲
计算机时代 2023年5期
王丽亚 陈哲

摘要: 提出一种基于中文BERT-wwm-ext嵌入的BIGRU网络模型。利用中文BERT-wwm-ext得到字向量,加强了模型对深层次语言表征的学习能力。将得到的字向量输入到BIGRU网络中,进一步学习上下文语义特征。将模型预测的边界分数向量利用解码算法转化成最终的答案。在多组数据集上做对比实验表明,所提模型能有效地提高中文意见目标提取的准确率。
关键词: BERT-wwm-ext; BiGRU; 边界预测; 中文意见目标提取
中图分类号:TP391 文献标识码:A 文章编号:1006-8228(2023)05-94-05
Chinese opinion target extraction based on BERT_BiGRUboundary prediction
Wang Liya1, Chen Zhe2
(1. College of artificial intelligence,Zhejiang Industry & Trade Vocational College, Wenzhou, Zhejiang 325003, China;
2. College of Computer Science and Engineering, Wuhan Institute of Technology)
Abstract: In this paper, a BIGRU network model based on Chinese BERT-wwm-ext embedding is proposed. First, the word vectors are obtained by using Chinese BERT-wwm-ext, which strengthens the learning ability of the model for deep level language representation. Then, the obtained word vectors are input into the BIGRU network to further learn the context semantic features. Finally, the boundary score vectors predicted by the model are converted into the final answers using the decoding algorithm. The experimental results show that the proposed model can effectively improve the accuracy of Chinese opinion target extraction.
Key words: BERT-wwm-ext; BiGRU; boundary prediction; Chinese opinion target extraction
0 引言
意见目标提取(OTE)[1]是意见挖掘和情感分析的基本任务,是自然语言处理(NLP)领域的研究热点。意见目标提取主要是对文本中表达意见的主体进行抽取。例如文本“烟台最好吃的烤翅尖就在所城里阿宋烧烤。满墙都是老烟台的剪贴画,招牌菜就是烤翅尖。”是对目标“阿宋烧烤”表达建议。OTE任务就是对文本中意见目标“阿宋烧烤”的提取。传统方法将意见目标提取建模为序列标签任务。意见目标提取任务要求从文本中定位出意见表达的目标,目标片段由文本中的一个片段组成的情况,因此,本文把该任务重新建模为边界预测任务,预测出文本中两个位置索引去指示答案的起始和結束位置。在抽取过程中避免了繁琐的序列标记操作。
1 相关研究
传统的意见目标提取方法可分为三类:基于规则[2]、基于统计[3]、基于规则和统计相结合[4]。但是这三种方法具有很强的局限性,过于依赖人工制定的规则,过程复杂。而基于深度学习的方法不再依赖于人工特征,减少了人力代价,提高了工作效率。
Liu等人[5]利用递归神经网络(RNN)和单词嵌入来提取意见目标。Poria等人[6]引入深度卷积神经网络(CNN)并结合语言模式以实现更好的性能。Wang等人[7]2016年提出RNCRF模型,由递归神经网络和CRF组成。Li等人[8]2018年提出基于字符的BILSTM-CRF结合POS和字典用于中文意见目标提取。在3组共10万条数据上进行实验,并与最流行的抽取框架BILSTM_CRF模型比较,证明其方法是最佳的。
但是以上基于深度学习的方法将OTE任务建模为序列标记任务,且文本表示利用单词嵌入或字嵌入,对语言表征学习深度不够。
Devlin等人[9-10]受神经概率语言模型[11]思想的启发提出BERT(Bidirectional Encoder Representations from Transformers)模型。BERT刷新了11项NLP任务的性能记录。可以预见的是,BERT将为NLP带来里程碑式的改变,也是NLP领域近期最重要的进展。针对中文文本,Sun等人[12-13]2019年提出ERNIE模型,是BERT在中文NLP任务上的改进。提出了命名实体级遮罩的概念,对BERT的遮罩语言模型在遮罩方式上进行了修改。近期,Cui等人[14]提出BERT-wwm模型,紧跟谷歌在2019年5月31日发布的一项BERT的升级版本,利用全词覆盖(Whold Word Masking,WWM)技术,更改了原预训练阶段的训练样本生成策略,针对中文文本使用了WWM技术,在中文维基百科(包括简体和繁体)进行训练。
预训练语言模型会直接影响方法的效果。所以本文针对中文短文本,将OTE任务重新建模为边界预测任务,使OTE任务不依赖于序列标记。引入中文版BERT对语言表征进行预训练,加强了模型的语言表征学习能力。在此基础上添加BIGRU网络,进一步学习文本的语义特征。最后将模型预测的边界分数向量利用解码算法转化成最终的答案输出。实验使用Li等人[8]相同的数据集,在三组共10万条数据上实验结果表明,针对本文数据集,将OTE任务重新建模为边界预测任务,BERT_BIGRU边界预测方法在不依赖序列标记的基础上,能有效的提高OTE任务的准确度。
2 BERT_BIGRU边界预测
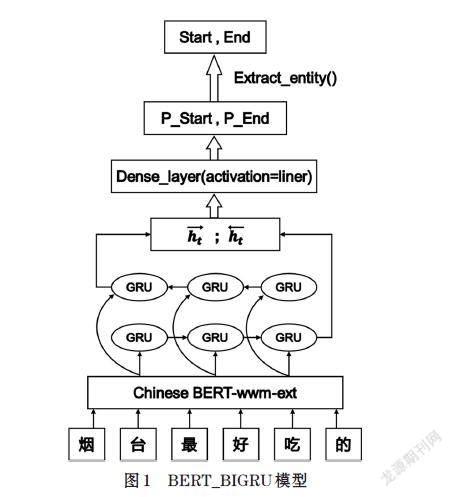
针对中文短文本将OTE任务重新建模为边界预测任务。主要分为三部分:一是BERT预训练语言模型,二是BIGRU模型,三是边界预测。模型结构如图1所示。
2.1 BERT预训练语言模型
BERT模型使用多层Transformer的编码器来作为语言模型,在语言模型预训练的时候,提出了两个新的目标任务,即遮挡语言模型(Masked Language Model,MLM)和预测下一个句子的任务。
本文采用的是哈工大讯飞联合发布的全词覆盖中文BERT预训练模型(BERT-wwm-ext)。此模型也采用了WWM技术,主要更改了原预训练阶段的训练样本生成策略,如果一个完整的词的部分字被Mask,则同属该词的其他部分也会被Mask,即全词覆盖。但较之前的BERT-wwm模型,BERT-wwm-ext模型使用了更大规模的数据中文维基百科数据和通用数据训练而成,进一步提升了预训练语言模型的性能。WWM的生成样例如表1所示。
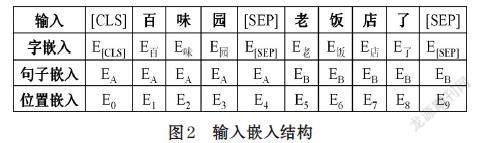
BERT-wwm-ext模型中预测下一个句子的任务,即生成句子嵌入(segmentembedding)。每个序列的第一个标记始终是一个特殊的分类标记[CLS]。对应于该token的最终隐藏状态(Transformer的输出)被用作分类任务的聚合序列表示。用特殊标记[SEP]将它们分开。这样句子对被打包成一个带有两标记的序列。在每个标记上,添加一个学习嵌入,指示它是否属于句子A或句子B。
BERT-wwm-ext模型使用12层Transformer编码器。对于给定的字,BERT-wwm-ext模型通过深层Transformer编码器获得字嵌入(token embeddings)、句子嵌入(segment embeddings)和位置嵌入(position embeddings),然后将三者相加作为该字的输入嵌入(input embedding)。具体结构可视化如图2所示。
2.2 BIGRU网络
BERT_BIGRU模型直接使用BERT層的输出作为BIGRU层的输入。若记t时刻正向GRU输出的隐藏状态为[ht],反向GRU输出的隐藏状态为[ht],则BiGRU输出的隐藏状态[ht],具体计算过程如下:
[ht=GRU(ht-1,Ut)] ⑴
[ht=GRU(ht-1,Ut)] ⑵
[ht=wtht+vtht-1+bt] ⑶
其中,[wt,vt]是权值矩阵,GRU:GRU函数,[Ut]:t时刻的GRU输入,[bt]:偏置向量。
2.3 边界预测
边界预测模块对意见目标的边界进行建模。文本通过BERT_BIGRU网络被表示为一个矩阵[H=h+h]。通过两个全连接层(Dense Layer)得到文本中每个字的两个分数向量,[starti]代表文本的第i个字作为意见目标项起始的概率,[endi]表示文本的第i个字作为意见目标项结束的概率,start和end通过相同结构不同参数计算得出。本文采用交叉熵损失函数,用来评估当前训练得到的边界概率分布与真实目标边界分布的差异情况,对模型进行优化训练。过程如下:
[Losss=-1Ni[ysilnstarti+(1-ysi)ln(1-starti)]] ⑷
[Losse=-1Ni[yeilnendi+(1-yei)ln(1-endi)]] ⑸
[Loss=Losss+Losse] ⑹
其中,[ysi]和[yei]是真实意见目标边界的指示。
将OTE任务重新建模为边界预测任务。由于OTE任务需要输出的是具体目标实体片段,而BERT_BIGRU模型的预测结果是两个分数向量,则需要解码算法将分数向量转化成最终的目标实体输出。
利用两个softmax分别预测结果首尾,选择概率最大的片段。softmax函数如下:
[softmaxx=exp(x-max(x))/sum(exp(x-max(x)))] ⑺
3 实验
3.1 实验数据
数据[16]来自百度(baidu)、点评(dianping)、马蜂窝(mafengwo)这三个互联网公司,具体数据集设置如表2所示。
3.2 评价指标
实验所用评价指标为Accuracy、Precision、Recall、F1,其值越高,代表模型分类能力越好。定义TP:为模型识别完全正确的实体个数,FP:为模型识别出的结果包含正确的实体,但边界判定出现错误的个数,FN:识别错误的个数。评价指标公式如下:
[Accuracy=TP/(TP+FP+FN)] ⑻
[Precision=TP/(TP+FP)] ⑼
[Recall=TP/(TP+FN)] ⑽
[F1=2*(Precision*Recall)/(Precision+Recall)] ⑾
经观察抽取结果,本文模型在实验过程中不存在抽取为空的情况,在计算FP时注意了抽取结果不存在原句,且容错字符个数小于10,为避免指标计算理解差别,这里给出具体的打分代码算法。见表3。
3.3 实验结果与分析
文献[8]中的工作,已针对相同数据集设置了多组详细的对比实验,其中包括了最流行的抽取框架BILSTM_CRF模型。并证明其方法是最佳的。所以,本文直接与其对比。
⑴ BILSTM_CRF[8]:建模为序列标记任务。首先生成字符位置信息特征([CP-POS]@C)并构建字典特征(DictFeature),最后将[CP-POS]@C和DictFeature整合到基于Word2vec字符嵌入的BILSTM_CRF模型中。
⑵ BERT:建模为边界预测任务。与本文唯一差别是神经网络模型为BERT-wwm-ext模型加普通Dense层。
⑶ BERT_BIGRU:建模为边界预测任务。本文方法。
为了测试模型的有效性,在实验过程中,所有模型都执行相同的数据预处理和分类器。测试集的实验结果如表4所示。
表4显示了3组模型在测试集上的对比结果。从综合评测指标Accuracy、F1上来看。第一组与第二组的比较可知,对意见目标提取任务重新建模为边界预测任务的方法更优。基于BERT边界预测的方法引入BERT-wwm-ext模型进行语言表征学习,再结合线性网络层,得到边界预测的分数向量,最后利用两个softmax分别预测结果首尾,选择概率最大的片段。相对第一组实验,减少了预处理部分對生成字符位置信息特征([CP-POS]@C)和构建字典特征(DictFeature)的工作,即很大程度上减少了繁琐的特征生成工程。
第三组与第二组的比较,三个数据集,BERT_BIGRU模型在点评数据集上稍低,即Accuracy值低0.0007、F1值低0.0004。但在百度、马蜂窝两个数据集上均高于BERT模型,所以在一定程度上,添加BIGRU网络学习文本上下文语义特征有利于提高模型对文本边界预测的准确度。综上,本文提出的BERT_BIGRU模型比其余二组模型更优。
为了量化模型的优劣,本文在测试集上进行预测。预测值统计结果如表5所示。Right为模型提取完全正确的样本总数,Wrong为模型提取错误的样本总数。另外,本文实验结果及模型最优的权重已分享至谷歌云盘[17]。
4 总结
本文提出了一种基于BERT_BIGRU边界预测的中文意见目标提取方法。将意见目标提取任务建模为边界预测任务,并引入BERT-wwm-ext模型进行语言预训练,且添加BIGRU网络学习文本上下文语义特征,有利于提高模型对目标实体边界预测的准确度。实验在百度、点评、马蜂窝三个共10万条数据集上进行训练和测试,结果表明BERT_BIGRU边界预测方法在不依赖数据序列标记的基础上,将准确度提高近8%,能有效地提高中文意见目标提取的准确率,但由于BERT模型的复杂化,一定程度上增加了模型时间代价。今后研究如何提高抽取工作的准确率且时间代价更小的模型,是下一步工作的目标。
参考文献(References):
[1] Kang Liu, Liheng Xu, and Jun Zhao. Opinion target
extraction using word-based translation model. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, EMNLP-CoNLL 2012, July 12-14, 2012, Jeju Island, Korea,2012:1346-1356
[2] Feng Chunsheng, Hao Aimin. Automaric Recognition of
Natural Language Based on Pattern matching[J]. Computer Engineering and Applications,2006,42(19):144-146
[3] Liu Zhiqiang, Du Yuncheng, Shi Shuicai. Extraction of Key
Information in Web News Based on Improved Hidden Markov Model[J].Data Analysis and Knowledge Discovery,2019(3):120-128
[4] Cheng Zhigang. Research on Chinese Named Entity
Recognition Based on Rules and Conditions Random Fields[D]. Central China Normal University,2015
[5] Pengfei Liu, Shafiq R. Joty, and Helen M. Meng. Fine-
grained opinion mining with recurrent neural networks and word embeddings. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, EMNLP 2015,Lisbon, Portugal, September 17-21,2015:1433-1443
[6] Soujanya Poria, Erik Cambria, and Alexander F. Gelbukh.
Aspect extraction for opinion mining with a deep convolutional neural network. Knowl.-Based Syst.,2016,108:42-49
[7] Wenya Wang, Sinno Jialin Pan, Daniel Dahlmeier, and
Xiaokui Xiao. Recursive neural conditional random fields for aspect-based sentiment analysis.In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, EMNLP 2016, Austin, Texas, USA, November 1-4,2016:616-626
[8] Yanzeng Li, Tingwen Liu, Diying Li, et al. Character-
based BiLSTM-CRF Incorporating POS and Dictionaries for Chinese Opinion Target Extraction. Asian Conference on Machine Learning,ACML,2018:518-533
[9] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of
deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805,2018
[10] https://github.com/google-research/bert.
[11] Bengio Y, Ducharme R, Vincent P. A neural probabilistic
language model[J]. Journal of machine learning research,2003,3:1137-1155
[12] Sun Y, Wang S, Li Y, et al. ERNIE: Enhanced
Representation through Knowledge Integration[J]. arXiv preprint arXiv:1904.09223,2019
[13] https://github.com/PaddlePaddle/ERNIE.
[14] Yiming Cui, Wanxiang Che, Ting Liu, et al. Pre-Training
with Whole Word Masking for Chinese BERT[J]. arXiv preprint arXiv:1906.08101,2019
[15] https://github.com/ymcui/Chinese-BERT-wwm.
[16] https://github.com/kdsec/chinese-opinion-target-
extraction
[17] https://drive.google.com/drive/folders/1t7jFhO2T_-
UfmBzcXCHU2QLDnRvo4QIj?usp=sharing
