
基于标签挖掘和聚类算法的新用户快速兴趣建模
2023-05-14 08:05黄宇浩顾得豪胡炎林周子楚朱津毅宋爽
计算机时代 2023年5期
关键词:冷启动
黄宇浩 顾得豪 胡炎林 周子楚 朱津毅 宋爽
摘 要: 旅游网站上有着数不胜数的景点信息,但是对新用户来说,网站缺少他们的浏览记录、旅游经历等数据,因此很难从众多景点中精确推荐出适合他们的景点。本研究提出了一种通过标签挖掘和聚类算法快速构建新用户兴趣模型的方法,以提高旅游推荐系统中新用户的用户体验感。
关键词: 旅游推荐; 冷启动; 网络文本挖掘; 用户聚类
中图分类号:TP391.1 文献标识码:A 文章编号:1006-8228(2023)05-88-03
Fast user interest modeling for new users using tag mining
techniques and clustering algorithm
Huang Yuhao, Gu Dehao, Hu Yanlin, Zhou Zichu, Zhu Jinyi, Song Shuang
(Nanjing University of Technology,School of Computer Science and Technology, Nanjing, Jiangsu 211816, China)
Abstract: There are countless tourism information on various travel websites, however, the lack of user data such as browsing history or travel experience makes it difficult to recommend the right point of interest for new users. In this paper, a method to quickly build a new user interest model using tag mining techniques and clustering algorithm is proposed to improve the user experience of new users in the travel recommendation system.
Key words: tourism recommendation; cold start; online text mining; user clustering
0 引言
旅游业是一个热门行业,但是由于缺少新用户的数据,旅游网站往往只能根据景点名、评论数、用户评分计算景点的陈列顺序[1],导致推荐效果不理想,用户体验感差,不利于旅游服务的多样化和个性化。
目前常见的新用户兴趣建模方法有两种,第一种是问卷调查法,即采取问卷的形式获取新用户兴趣,如提供由李克特五级量表构成的选项供用户选择[2]。但是,大量的文字题目会增加用户的负担,降低用户体验,所以不是最理想的手段。第二种是相关推荐法,即基于新用户的个人信息和与其相似的老用户的景点喜好实现推荐。这种方式无需用户操作,但研究表明,如果年龄、性别等的人口统计学信息较为模糊,就不足以支持实现精细化、个性化推荐[3]。
综合以上分析,本文提出一种基于标签内容和聚类算法的快速兴趣建模方法,通过让新用户选择自己感兴趣的景点,快速分析用户的景点偏好,从而缓解新用户的冷启动问题。
1 系统设计
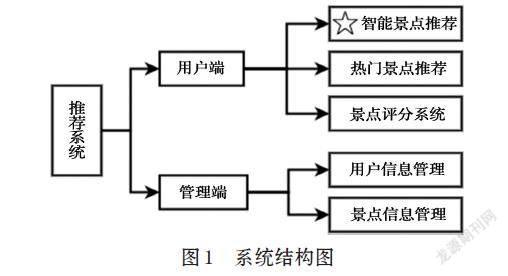
本系统总体分为用户端和管理端,功能分类如图1。
管理端实现了对用户信息及景点信息的增删改查操作;用户端包括智能推荐模块、热门景点推荐模块和景点评分模块,可以查看景点推荐列表并对景点进行评分。用户在注册时,需要填写个人信息,并在若干张预设图片中选择自己感兴趣的景点,系统通过逆向挖掘相应景点的标签,计算出新用户的兴趣。
2 初始化算法设计与实现
2.1 数据采集
本研究以南京市的旅游景点为对象,使用了Python语言,基于爬虫技术从猫途鹰(www.tripadvisor.com)、去哪儿旅行网(www.qunar.com)、百度百科(www.baike.baidu.com)和携程网(www.ctrip.com)采集所有相关数据。数据由三部分组成:①景点基本信息的文本數据,②景点评论及游记的文本数据,③景点的图片数据。采集时间是2022年7月至9月,最终采集到295个有效景点,共计43531条评论和829张图片。
2.2 标签制作与提取
针对景点评论、景点简介等文本数据,使用jieba分词技术提取单词后,去除停用词,基于式⑴~式⑶计算TF-IDF值以构建景点-标签库[4]。
[TF-IDFi,t=TFi,t*IDFi,t] ⑴
[TFi,t=ni,tnt] ⑵
[IDFi,t=lgItI+1] ⑶
其中,TFi,t表示景点i对标签t的依赖程度,ni,t是景点i的文本数据中标签t的出现次数,nt是标签t在所有文本数据中的出现次数。IDFi,t表示标签t的热门程度,用于实现对出现次数过多的热门标签的惩罚,|I|是景点个数,|It|是包括标签t的景点个数。最后,根据TF-IDF将标签降序排列,并计算TF-IDF值的累积和,取累计和小于50%部分作为有效标签。
2.3 基于聚类算法求初始化图片
为了实现用尽量少的景点挖掘用户对尽量多种类的标签的依赖性,本研究采用如下方法对景点进行分类,并挑选每个类型的代表景点。
⑴ 对景点的每个标签的TF-IDF值进行标准化和归一化,使其值域为[0,1]。
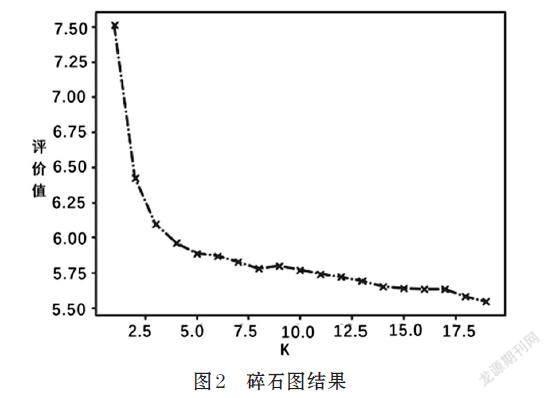
⑵ 基于碎石图决定景点类型数量k,具体步骤是:首先,基于K-means聚类算法[5]将景点分成k类(k=2,3,4,…),计算每种分类结果中,各景点到相应质心的距离,取最小值作为该分类的评价值,取所有类型评价值的平均值作为分成k类时的评价值,最后根据图2中的坡度变化选取了k=9。
⑶ 基于k-means聚类算法将全部景点分成九类。
⑷ 选取每类的代表景点,该步骤设计思路如下:首先,用欧式距离公式计算每个景点i到对应分类c质心的距离sc,i;其次,对sc,i进行z-score标准化得到dc,i后,使用式⑷计算分类c中景点i的评价值rc,i;最后,取每个分类中评价值最高的景点作为代表。式⑷中,ni代表景点i所包含的标签数。由于系统采用图片展示景点,所以设置α值作为判断景点是否具备图片数据的权重,即若有图片则置为1,否则为0。
[rc,i=α×nidc,i] ⑷
3 算法效果评估
3.1 评估方法
本研究采用仿真实验评估用户兴趣建模的效果。由于本实验选出了九个景点并采用“喜欢”和“不喜欢”两种选项,因此可以将用户快速分成29=512种类型。本实验分为以下两个子实验。
实验1 考察不同类型用户的推荐结果间是否存在差异,即:针对每种类型的用户,基于标签推荐算法计算出对应的景点推荐列表,在此基础上,计算任意两组推荐结果的斯皮尔曼顺位相关系数;
实验2 考察不同类型用户的推荐结果是否合理,即:按照旅游网站上列举的景点历史评论数由高到低计算出景点的热门度排序,计算任意推荐结果与热门度排序间的顺位相关系数。
3.2 结果与讨论
本实验使用了SPSS软件对512种推荐结果进行双变量相关性分析。
实验1得到512×512组斯皮尔曼相关系数,并从中除去了自相关的512个数据和重复数据(如x和y的相关系数与y和x的相关系数),结果的平均值为0.718,方差为0.085。这说明任意组合的排序有一定的相似但是存在差异,即采用本方法可以实现多样化的推荐。同时,结果中存在少量组合间的顺位相关系数为1,这些组合对应的是仅有一个景点选择不同的两类用户,造成该现象的原因可能是景点数量较少,没有足够的景点来体现少量标签的差异,导致了标签兴趣不同的用户获得的推荐结果相同,后续可以尝试增加景点数量加以应对。
实验2得到512个相关系数,其平均值为0.827,方差为0.091,这说明本算法得出的推荐结果和热门排序相具有一定的相似性,不是随机推荐。同时,推荐结果与热门度排序的差异体现了针对不同用户可以获得个性化的推荐结果。
虽然本方法能够快速的将用户分类,但本研究没有检查用户兴趣和每种分类间的映射关系,因此后续还需进行用户评价实验。此外,本系统采用了“喜欢”和“不喜欢”两极化选项,若改为“喜欢-中性-不喜欢”等多级选项的话,可以实现更为细致的用户划分,对于选项设置对推荐结果的影响,还应进一步考察。
4 结束语
本文针对推荐系统无法快速、精准建立新用户兴趣模型的问题,提出了一种基于标签挖掘和聚类算法的建模方法。经过多次测试评估推荐结果,本方法能够有效的实现对用户的快速分类,获得多样化的推荐结果,并且该结果可以兼顾个性化与热门度。若将该方法运用在推荐系统中,可以在减少繁琐的操作的同时获得个性化的推荐景点,提升新用户的使用体验,有利于提升网站的用户留存率和用户评价。但是,本研究仅仅针对了新用户的冷启动问题进行了处理,若想要整體改善用户间推荐结果雷同的问题,还可以进一步的加入协同过滤等推荐算法。
参考文献(References):
[1] 刘艳,潘善亮.基于LBSN好友关系的个性化景点推荐方法[J].计算机工程与应用,2015,51(8):117-122
[2] 漆亚莉.城镇居民乡村文化旅游消费意愿影响因素研究——基于南宁市城镇居民问卷调查数据[J].北京文化创意,2022(1):70-78
[3] 陈阿龙.推荐系统用户冷启动问题相关研究[D].硕士,国防科学技术大学,2016
[4] 熊中敏,郭怀宇,吴月欣.缺失数据处理方法研究综述[J].计算机工程与应用,2021,57(14):27-38
[5] 李明媚.基于数据特征选择的融合聚类方法研究[D].硕士,杭州电子科技大学,2022
猜你喜欢
环境污染与防治(2022年9期)2022-09-22
重庆大学学报(2022年6期)2022-06-23
汽车实用技术(2021年17期)2021-09-23
客联(2021年2期)2021-09-10
佳木斯大学学报(自然科学版)(2020年1期)2020-02-12
北京汽车(2017年6期)2017-12-29
科技创新与应用(2017年30期)2017-11-07
商业经济(2017年6期)2017-06-15
科技创新与应用(2017年3期)2017-02-18
