
基于CSSA-BPNN 算法的专利质量评估研究*
2023-05-12 02:26卢志平唐健廷
计算机与数字工程 2023年1期
卢志平 唐健廷
(1.广西科技大学经济与管理学院 柳州 545006)(2.广西工业高质量发展研究中心 柳州 545006)
1 引言
国家将2025 年每万人口拥有高价值发明专利12 件的预期目标作为一项政策指标,写入了“十四五”规划和2035年远景目标纲要中[1]。而高价值专利体现在专利的质量上,表现为专利的各个维度的价值[2]。因此围绕专利进行质量评估,是筛选高价值专利的一个关键。
由于专利质量与专利市场价值存在区别,导致传统的专利评估方法并不适用于专利质量评估,因此不少国内外学者就专利质量的评估方法进行了研究。对专利质量的评估指标进行约减,降低复杂度[3];采用FANP 法对企业对专利组合的质量进行评估[4];通过文献计量分析的方式,对高校中锂电池领域专利质量进行评估[5]。通过对专利的投资组合价值指数进行计算,来评估专利的质量[6]。而对大量的专利同时进行评估时,常用到机器学习的方法。通过对机器学习方法中不同的评估模型进行比较,神经网络模型获得较好的实验效果[7~8]。而神经网络模型本身存在着收敛速度慢,算法不完备的局限性。因此有学者先对神经网络模型进行优化,进而对专利的质量进行评估分析[9~10]。
综上所述,由于机器学习的特点,可以有效节省了人为评估的费用成本和时间成本,同时也克服了主观性因素的存在。但是这类方法在对专利进行质量评估时存在容易陷入局部最优和收敛速度慢的局限性,因此,本文先用CRITIC—熵权法对指标进行筛选,并约减指标,避免冗余。并运用Logistic混沌结合的麻雀搜索算法去优化BP神经网络中收敛速度慢的局限性。该模型可以筛选出高价值的专利,为高校或者企业的专利交易选择提供决策支持。
2 专利评估指标体系选择
早期学者对于专利质量价值评估的研究很多都是参考《专利价值分析指标体系操作手册》[11],但这本手册里面给出的指标很多都是涉及了定性分析,难以量化。本文通过相关文献梳理[2]和咨询专家的意见,构建了一种可定量评估专利质量的指标体系。
3 专利质量评估模型构建
3.1 CRITIC—熵权法的组合权重模型
CRITIC 法可以体现指标间的冲突性,而熵权法则可以衡量指标之间的离散程度。两种方法结合可以使得指标权重结果更加合理[12]。因此,本文使用CRITIC—熵权法去计算各个指标的客观权重,其计算步骤如下。
1)首先对专利特征指标进行无量纲化处理,由此得到标准矩阵X*如式(1)所示。
2)由标准矩阵X*通过式(2)和式(3)计算得到标准差σj与指标间的相关系数ρij。
3)计算各指标所含的信息量Gj和客观权重w1,其中,Gj为指标j与另外各指标冲突性的量化指标。Gj越大,表示指标j权重越大。
最后,客观权重w1的计算方式如式(5)所示。
4)通过式(6)计算样本i出现指标j的概率pij,通过式(7)计算j项指标的熵值ej。
5)通过式(8)计算出第j项指标的熵权w2。
6)根据专家组所讨论的意见,系数β取值为0.5,并通过式(9)计算综合权重wj。
3.2 混沌优化的麻雀搜索算法(CSSA)
麻雀搜索算法(SSA)是通过模拟麻雀觅食并逃避捕食者的行为而提出来的一种群智能算法,该算法的收敛速度较快,局部搜索能力也较强,但全局的搜索能力较弱,也容易陷入局部最优而无法跳出[13]。因此,选择Logistic 混沌序列对麻雀种群进行初始化,提高初始解的质量,增强算法的全局搜索能力。
3.2.1 SSA算法主要实现步骤
1)对SSA 算法的参数进行初始化,包括麻雀的种群规模在N,发现者数量PN以及跟随者数量N-PN,侦查者数量SN,迭代次数最大为itermax,搜索维数D,麻雀的初始位置定义为xi=表示个体i的适应度。
2)更新种群中发现者的位置信息,位置更新如式(10)所示:
3)更新跟随者的位置,位置更新如式(11)所示:
4)在每一次迭代发生后,随机选择SN个个体进行侦察预警行为。位置更新公式如下:
β为符合标准整体分布的随机数,xw和xb为最优、最差个体位置,当适应度fi=fg时,个体向附近位置移动;当fi≠fg时,个体向当前最优位置移动,其值收敛于最优位置。
3.2.2 Logistic映射
Logistic 混沌映射具有长期不可预测性,其产生的序列{xn,n=0,1,2,3…}是非周期性、且存在发散的数列,并且初始值表现十分敏感。Logistic映射的方程式如(13)所示:
其中,参数μ(0,4],xn(0,1),当3.5699…<μ≤4时,Logistic映射呈混沌状态。
3.2.3 混沌优化的SSA算法
SSA 算法中加入Logistic 混沌优化,增加种群的多样性,通过混沌扰动避免搜索个体陷入局部最优的限制,使算法持续进行全局搜索。其流程如图1所示。

图1 CSSA算法流程图
1)应用Logistic 映射生成的混沌序列对算法的参数进行初始化,包括麻雀的种群规模N,最大迭代次数itermax,搜索空间维数D,并生成N个D维向量。
2)通过式(13)对麻雀种群的个体的D个维度进行迭代,并用式(14)将Logistics 映射产生的变量值映射到个体上,其中lb和ub分别为维度的上边界和下边界。
3)计算i个个体的适应度fi,以及记录所在的位置d,并根据个体适应优劣进行排序。
4)将适应度前70%的个体作为发现者,剩下的30%则为跟随者,根据式(10)和式(11)更新发现者和跟随者的位置。
5)从种群中随机选取20%的个体作为侦查者,并根据式(12)更新其位置。
6)当搜索陷入局部最优时,产生混沌序列对个体进行混沌扰动。如式(15)所示:
7)重新更新种群中个体的适应度和其位置。
8)判断算法运行是否达到最大迭代次数或者求解精度,进而执行结果输出或返回4)。
3.3 CSSA优化的神经网络(CSSA—BPNN)
为了解决BPNN 容易陷入局部最优,收敛速度慢的局限性。本文将CSSA 与BPNN 结合,通过CS⁃SA算法中的搜索能力较强的特点,对BPNN模型进行优化。步骤如下:
1)通过CSSA 算法的寻优结果,计算得到最优的初始权值和阈值,并导入BP神经网络。
2)将模型的输出值与训练的专利样本中实际的期望值进行误差计算,如式(16)所示:
3)若该模型误差未达到初始时设定的误差,则该网络模型将所计算得到的误差向前反馈,重新调整神经元之间连接的权值和修正阈值参数。其中权值的调整为μi+γΔμi,γ是学习率(0<γ<1),控制算法的更新速度,Δμi是负梯度方向。
CSSA—BPNN 模型经过反复地调整连接权和修正阈值,最后使得训练误差达到所设定的数值或者误差前馈次数达到最大,则停止训练,并保存训练完成的预测模型。
3.4 专利质量分类结果评价
本文采用准确率(accuracy)、精确率(preci⁃sion)、召回率(recall)和F1 值共4 个指标对分类结果进行评价,如式(18)和(19)所示,其中,M为分类正确的样本个数,N为样本总数,MP为预测正确的正例数,NP为预测为正例的数,Nc表示实际正例数。
4 实证分析
2021 年中国汽车专利的公开量总共为32 万件,同比增长4.2%,持续保持稳步增长态势。发明专利授权量为8.4 万件,同比大幅增长23.3%。可以看出中国汽车的专利在申请和授权的数量上持续提升。也反映出汽车产业已在专利密集型产业中占据了一席之地[14]。同时,新能源汽车产业作为政府扶持的战略新兴产业,其产出的专利更具战略性意义。因此,本文以新能源汽车领域的专利为评估对象,对CSSA-BPNN评估模型的性能进行测试。
4.1 专利样本获取
本文从incoPat 专利数据库获取研究需要的数据。根据表1 的指标体系,下载了15 个特征指标。首先,考虑到专利技术生命周期的存在,因此选择了2011 年-2021 年这十年授权的新能源汽车领域的专利。由于在incoPat 专利数据库中,发明授权专利最低价值度为2,最高价值度为10;因此将价值度2~4标记为为低价值专利,赋值为0,将价值度5~7 标记为普通价值专利赋值为0.5,将价值度8~10 标记为高价值专利赋值为1。在三个等级的专利中各随机抽取了1000 条数据信息,共3000 件专利去构建专利指标数据库。选择其中90%为训练集,10%作为测试集,分别用于之后模型的训练和测试。
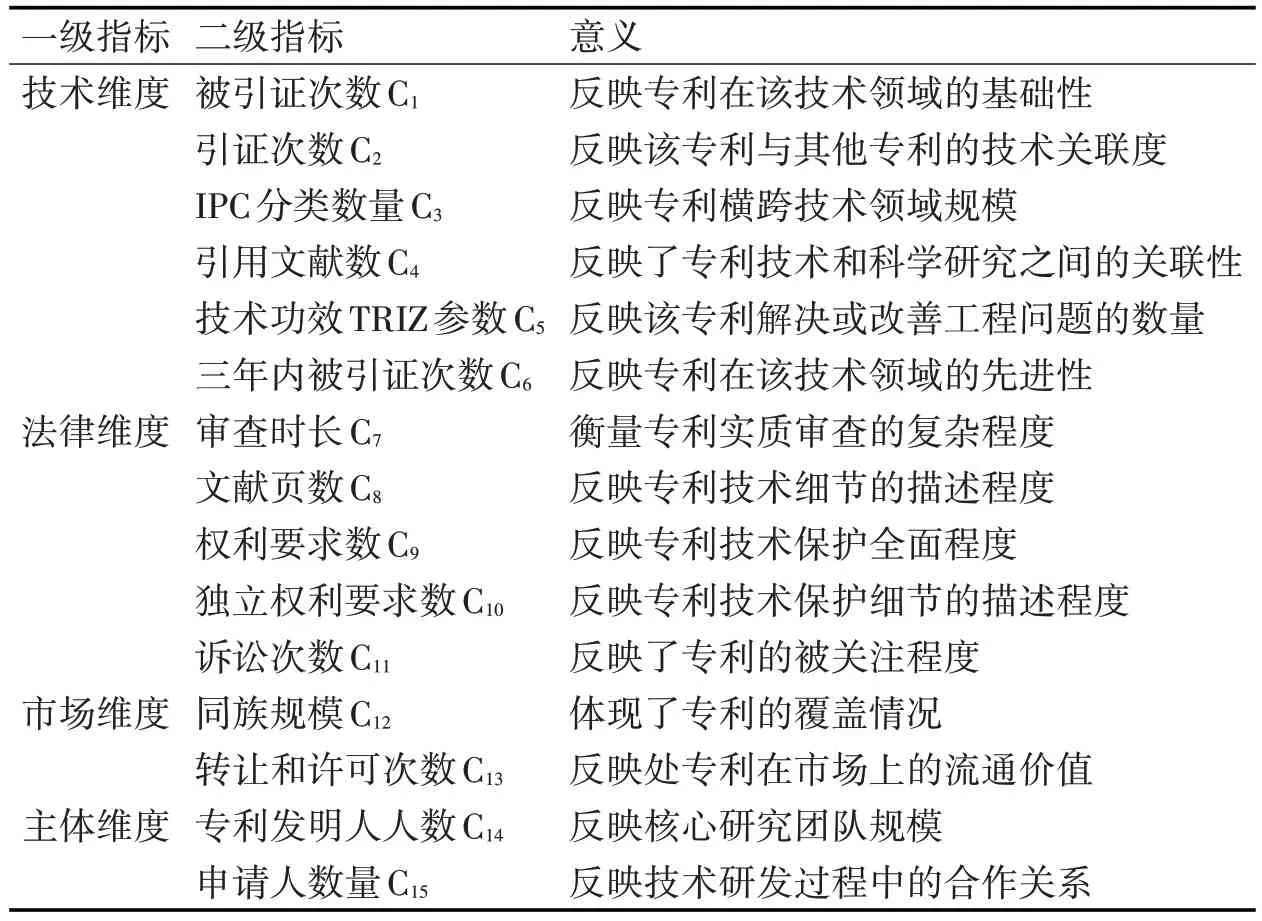
表1 专利质量评价体系
4.2 CRITIC—熵权法提取重要指标
专利评估的过程中所涉及的特征指标较多,各个指标之间存在着相互关联,为了避免模型在训练学习的过程中出现过度拟合,因此需要对特征指标进行约减,降低模型的复杂程度[15]。本文采用CRITIC—熵权法对指标评估权重,约减权重低的指标,保留重要的指标并将其输入到神经网络模型中。根据收集得到3000 条专利样本形成一个指标矩阵R,通过3.1 节的计算步骤,得到各个指标的权重,如表2所示。
对表2 中指标的权重进行排序,并将权重小于0.04 的指标作为数据噪声剔除,剩下10 个重要指标(C1,C2,C3,C4,C6,C9,C11,C12,C13,C15),这些指标占总体权重的84.5%。

表2 特征指标权重
4.3 模型结果分析
为验证模型在专利质量评估方面的效果,将专利样本数据输入到CSSA—BPNN 模型、GA—BPNN模型、PSO—BPNN 和BPNN 模型中进行测试和对比,其中初始种群数量为20,迭代次数为500,神经网络输入层的神经元个数为10,预设误差为0.001;分类结果如图2 所示,并通过式(18)和式(19)计算评价模型性能的4 个指标,其中X 轴表示专利样本的统计项数,Y 轴表述为价值度。结果如表3所示。
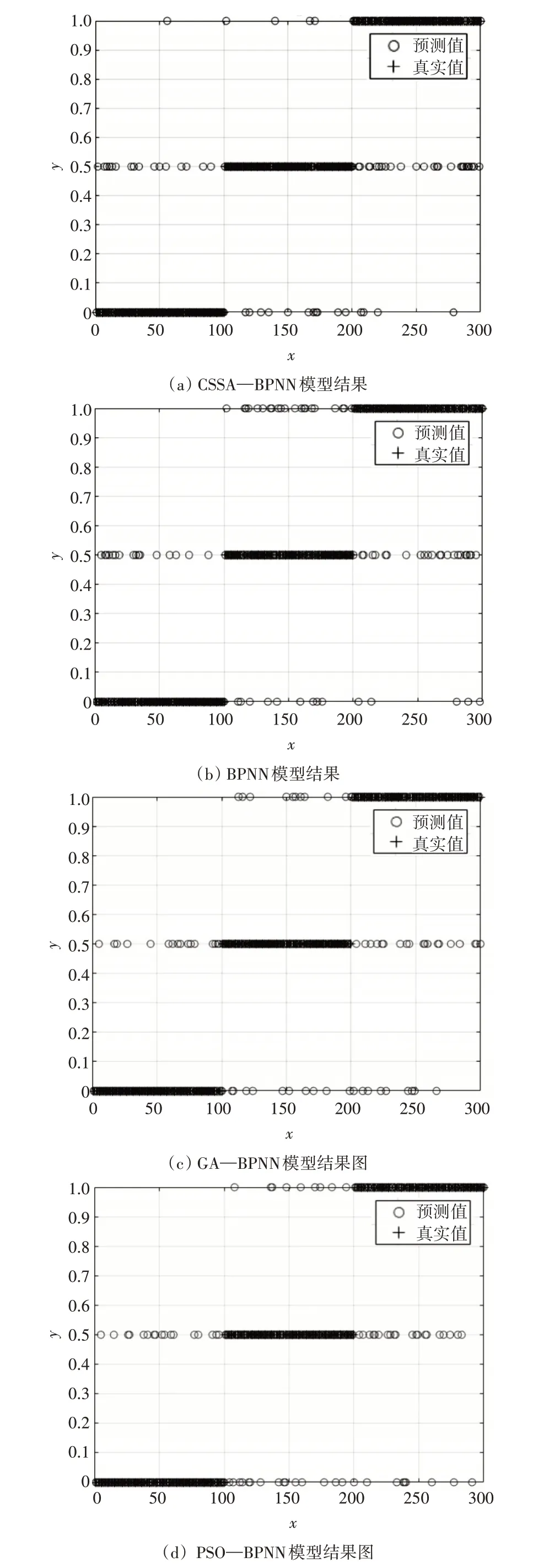
图2 四种模型结果
通过表3 可以知道,四类模型的各项指标均大于0.75,而且三种经过算法优化的BPNN 模型的各项性能指标均优于未经优化的BPNN 模型。其中,CSSA—BPNN 模型的性能最优,在准确率和精确率方面比BPNN 模型高0.04,在在召回率和F1 值上面,CSSA—BPNN 模型也是最高,达到了0.819 和0.808。证明了该模型的有效性和稳健性较好。因此,利用CSSA—BPNN模型对专利质量进行评估是可行的。

表3 模型性能指标对比
并对三种算法进行500 次迭代,其迭代收敛图和结果如图3和表4所示。

图3 三种算法迭代对比图
从表4 可以看出,PSO 收敛代数为393 代,收敛代数在三种优化算法中是最高的,GA 收敛代数为122 代,但总耗时为267.6s,总耗时是最长。CSSA收敛代数为51代,总耗时192.2s,相比于GA和PSO具有更高的效率和更低的运算耗时。而且CSSA算法得到的平均适应值和最小适应值均小于GA 和PSO,说明该算法比传统的优化算法具有较高的求解质量。
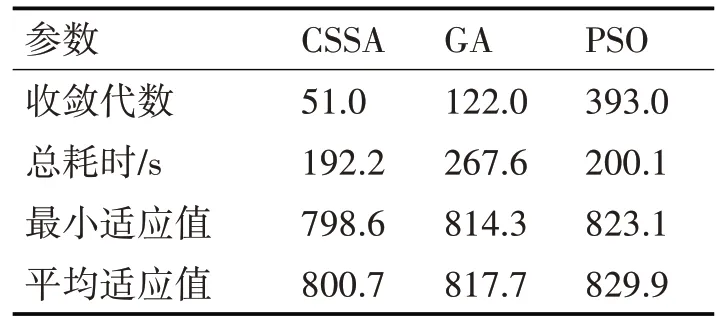
表4 三种算法收敛结果对比
5 结语
本文关注专利质量评估指标的适用性和可操作性,探究机器学习的方法应用于专利质量评估,通过混沌映射改进麻雀搜索算法,并结合神经网络去构建专利质量评估模型。与PSO、GA 优化的模型进行仿真对比,得到以下结论:1)CSSA—BPNN模型对专利质量进行评估时,模型的各项指标均优于BPNN 模型和PSO、GA 优化的BPNN 模型,并且分类准确率达到0.797。2)在算法寻优中,CSSA 比PSO、GA具有更高的效率和更低的运算耗时。
本次研究的主要创新内容如下:1)在专利质量评估体系中同时考虑了专利的技术维度指标、法律维度指标、市场维度指标和主体特征指标。可以综合体现出专利的技术竞争力、经济关联性、权利稳定性等多个方面的价值。2)构建CSSA—BPNN 模型对新能源汽车领域的专利进行质量评估,证明了该评估模型整体性能比传统算法较优。3)通过两种客观权重方法去确定专利各项特征指标的权重,避免主观因素对权重的影响。
猜你喜欢
水运工程(2022年7期)2022-07-29
当代陕西(2020年17期)2020-10-28
电子制作(2019年19期)2019-11-23
传感器世界(2019年4期)2019-06-26
人大建设(2018年5期)2018-08-16
电信科学(2017年6期)2017-07-01
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
河南科技(2014年15期)2014-02-27
