
自适应变分模态分解与RCNN-3结合的扬声器异常声分类方法
2023-05-10 13:42周静雷贺家琛王晓明
西安工程大学学报 2023年2期
周静雷,贺家琛,王晓明,崔 琳
(西安工程大学 电子信息学院,陕西 西安 710048)
0 引 言
随着智能设备的快速发展,以声音作为人机交互渠道的切入点,满足了消费者的需求,并促进智能音箱等相关设备的快速发展。相对应的,故障的扬声器数量也随之增加,给电声企业扬声器生产线测试增加了困难。传统扬声器异常声检测主要是靠人工听音的方式来判断,这种方法容易受听音员的专业水平、工作状态等诸多不确定性因素的影响,导致传统检测方法无法保证扬声器异常声分类的精度及效率,难以满足工厂发展的需求。因此,提高扬声器异常声检测的效率、质量和加快自动化进程,对扬声器产业的发展具有十分重要的意义[1]。
扬声器在大信号激励下,声响应信号是非线性、非平稳的[2-3],所以一般采用时频分析的方式,去获取较为全面的特征[4]。在实际测试环境中,检测过程极易受到外界环境噪声的干扰,为提高扬声器异常声分类的准确率,需要对获取的声响应信号进行降噪。张文义等用卡尔曼滤波、共振稀疏分解和最大相关峭度解卷积等进行降噪[5],但这些方法在处理非线性、非平稳信号时,会造成性能衰退[6];周晓东等采用短时傅里叶变换(short-time Fourier transform,STFT)进行异常声信号处理[7],但STFT分解率比较单一,缺少自适应性。为了解决分解单一问题,文献[8-9]利用经验模态分解(empirical mode decomposition,EMD)进行处理,但仍存在模态混叠等问题。文献[10-11]采用集合经验模态分解(ensemble empirical mode decomposition,EEMD)对响应信号进行分解,一定程度上解决了模态混叠问题,但如果参数选择不合适,仍会出现这一现象;而VMD与EMD相反,是从低频到高频逐一进行分解出各模态分量,其抑制模态混叠的情况优于EMD,并且其降噪效果更加理想[12]。传统的扬声器异常声分类网络中,大多采用支持向量机(support vector machine,SVM)算法[13-15]、K最近邻(K-Nearest Neighbor,KNN)算法[16]等,但是此类方法分类效果相对较差。近年来,深度学习广泛应用于故障诊断领域。文献[17-20]采用CNN进行不同故障类型的分类,取得良好效果。神经网络模型的深度是获得好的训练结果的重要因素,但随着网络模型深度的提升,“梯度消失、爆炸”与网络退化现象越来越严重。针对以上不足,康玉祥等采用残差网络对滚动轴承进行故障诊断,并取得很好的诊断效果[21]。
本文针对扬声器异常声信号特征提取困难以及识别准确率较低等问题,提出了一种基于AVMD与RCNN-3相结合的扬声器异常声分类方法。首先以平均包络谱特征因子作为衡量VMD分解好坏的标准,通过GWO算法优化VMD,找到合适α和K,后又通过RF-RFE算法对VMD所提取的特征做进一步筛选,提取最优特征子集;最后用 RCNN-3模型进行分类;RCNN-3模型可以有效防止网络退化,提高分类的准确率和效率。
1 理论分析
1.1 扬声器异常声特征提取理论
扬声器异常声分类中,直接对音频数据进行分类,难度较大,主要原因有:①在大信号驱动下,扬声器声响应信号是非线性、非平稳的,直接分类,难以有效获取异常声特征;②声响应信号数据量较大,若直接分类,模型训练速度慢,模型损失函数值下降困难,导致分类精度不高。所以,本文采用VMD提取声频数据中的特征。VMD以各模态带宽最小和原则,采用非递归方法进行信号分解,可以有效解决模态混叠现象,且分解后,各模态能量相对集中,方便后续提取异常声特征。但VMD分解过程中,二次惩罚因子和模态分解数对分解结果影响较大,又没有确定的数值,其参数选择一般根据实际应用场景来自行选择,受人主观判断影响较大,所以本文用包络谱特征因子(EFF)来衡量VMD分解好坏,以GWO算法作为寻优算法,确定VMD中的最优参数组合。设X(t)为VMD后的时间序列分量之一,其经Hilbert解调后的包络谱的频谱为E(f),EFF[22]的公式如式(1)所示。
(1)
式中:fc表示最大幅值故障频率点;RMS为均方根。
GWO算法[23]是MIRJALILI等于2014年提出的一 种元启发式优化算法,通过模仿自然界中灰狼群的等级制度与捕食策略以迭代计算的方式实现对猎物(最优值)的搜索。通过GWO算法优化VMD,确定好VMD中α和K后, 就可进行特征提取。主要提取特征为能量熵、时频熵、峰峰值等。但提取的这些特征中有些对扬声器异常声分类影响较大,有些对扬声器异常声分类影响较小,甚至有些特征不利于后续分类。所以,有必要对特征进行筛选,提取出最优的特征子集。特征筛选方法为RF-RFE算法。其进行特征选择包含特征重要性计算和递归特征消除2个部分。特征重要性计算是RF算法内嵌的功能,以袋外(out-of-bag,OOB)数据分类准确率为评价准则。
本文所提出的自适应变分模态分解是基于GWO算法, VMD和RF-RFE算法3种模型的特征提取方法。整体步骤如下:
1) 选取正常和每种异常音频数据各20条,作为数据样本,以平均包络谱特征因子作为衡量VMD分解好坏的标准;
2) 通过GWO算法优化VMD,确定最优二次惩罚因子和模态分解数;
3) 对原始音频数据进行VMD,并提取能量熵,时频熵,峰峰值等特征;
4) 用RF-RFE算法对上一步提取的特征进行寻优,确定最优特征子数据集。
1.2 扬声器异常声分类模型理论
传统分类方法(如SVM,XGBoost等)在扬声器异常声分类方面,准确率相对较低,主要是因为传统方法难以有效提取扬声器响应信号中的异常声特征,更无法发掘较深层次特征,进而导致模型性能退化,准确率降低。近些年来,深度学习广泛应用于故障诊断领域,取得了不错的成果。其中,卷积神经网络在特征提取方面有着优良的效果,本文分类模型主要由2个卷积层,1个池化层,3个残差块结构,2个卷积层,1个池化层,1个全局平均池化层,1个全连接层构成,最后通过SOFTMax函数实现分类。
在实验中发现2个卷积层加1个池化层这一固定结构有利于提取更深层次的异常声特征,表示为结构1(见图1)。

图1 结构1
结构1中激活函数统一使用RELU,其使用仿生物学原理,有效的加快梯度下降,防止梯度爆炸,简化计算过程,提高效率。填充方式为0填充,不改变原数据格式,且0填充减小了引入的误差干扰。
虽然使用单一的卷积神经网络可以有效提高准确率,但在分类准确率的稳定性方面存在较大波动,主要是因为单一的卷积神经网络难以有效提取更深层次特征,相当于一个浅层网络。所以本文引入了ResNet结构,用来提高模型的平均准确率和降低波动,提高模型鲁棒性。ResNet在预防神经网络退化方面有着良好的效果,是目前使用最多的深度学习网络中的一种。CNN的网络层数对其训练的效果有着决定性作用。CNN的网络层数加深意味着可以更充分地提取更深层次的特征,提取到的特征维度越高,获取的信息就越多,但随着网络层数的不断加深,出现了梯度消失等现象,从而导致模型训练准确率下降。HE等提出用残差网络解决这一问题,其结构如图2所示[24]。
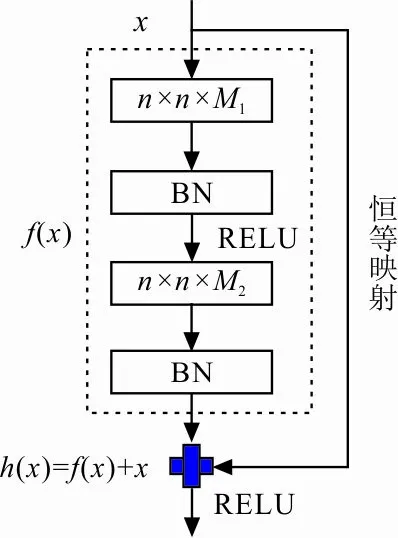
图2 残差结构块
图2中:n×n×M1、n×n×M2是M1、M2个n×n大小的卷积核;BN为归一化操作;RELU为激活函数;输入x在经过卷积、批归一化、激活函数等变换后得到映射函数f(x)。同时x经过恒等映射(使得变换后的格式和f(x)获得的格式具有相同尺寸)后和f(x)进行累加操作得到输出h(x),可表示为
h(x)=f(x)+x
(2)
通过在原有结构上引入ResNet,可以有效提高模型鲁棒性,提取扬声器异常声更深层次的特征。通过实验发现添加3个残差块结构,分类效果最佳。在残差结构中,每个卷积层后会加一个批量归一化层,主要是解决在训练过程中,中间层数据分布发生改变的问题,防止梯度消失或爆炸,加快训练速度。本文分类模型损失(loss)函数为平均均方误差,可表示为
(3)

本文参数选择采用网格搜索优化算法,主要搜索的参数为批大小、学习率、迭代次数;最终优化结果设置批处理样本量为4;迭代次数为100;学习率为0.001。
2 实验与结果分析
2.1 数据采集
实验所用扬声器型号为3580-3型,激励信号为1 800~20 Hz的从高频到低频连续对数扫频信号[25]。本次实验共采集了良品、异物、缺胶、碰圈、脱盆架、音小、纸盆声7种主要类型的扬声器单元,每种类型的扬声器各14个。扬声器单元在大信号驱动下,声响应信号是非线性非平稳的,每个扬声器单元只采集一条数据不能表征个体的所有特征,所以每个扬声器单元各采集20条数据作为样本。异物是指在扬声器单元制作过程中由于工艺等原因导致内部有小颗粒存在;缺胶是指防尘帽或压边处缺胶;碰圈是指音圈形变或支架不平导致与磁体发生碰撞;脱盆架是指盆架安装松动;音小指支片沾有胶水;纸盆声是纸盆破裂而导致等。数据采集平台如图3所示。

图3 数据采集平台
由图3可知,数据采集流程为扬声器异常声分析模块先产生激励信号,经功率放大器后供给被测扬声器单元,同时传声器在消音箱内采集声响应信号,后送给异常声分析模块进行调理,最后由音频分析仪进行数据记录。
2.2 扬声器异常声特征提取实验
用GWO算法优化VMD是以平均包络谱特征因子作为衡量标准,良品音频若以K为6进行分解,那么良品音频的平均包络谱特征因子为6个分量EFF的平均值。VMD中的模态分解数、二次惩罚因子需要人为去设置。本文采用GWO算法优化VMD得到最优参数K=6,α=17 638。7种音频经VMD后的频域如图4所示。每个图有6个分量,从上到下是VMF1到VMF6

(a) 良品
从图4(a)可以看出,良品音频经VMD后,VMF1到VMF6中频频率依次为1 611、1 265、950、626、286、62 Hz,频率间隔均匀,没有出现中心频率较为接近或一样的情况,其他6种音频中心频率也均匀分开,与良品类似,所以变分模态分解可以将声响应信号自适应的分解到不同频带上,不存在模态混叠现象。
在VMD分解后,每个音频数据共提取能量熵,时频熵,峰峰值等特征共108个,但是这些特征不一定全部有助于后续分类,所以需要用RF-RFE算法进行特征筛选,以准确率为评价标准,最终选出的最优特征子集,如图5所示。

图5 最优特征子集
图5中,所有特征重要度和为1,其中U2×8重要度最高,其代表VMD后分量2的第8个特征,为方差,其重要度为0.068;经RF-RFE算法优化后最优特征子集有29个特征,相对于原来108个特征来说,剔除了79个不重要特征,降低了数据维度,提高了分类的准确率和速度。
2.3 实验参数设置
实验中计算机CPU为AMD Ryzen7 3700X,8-Core Processor CPU@3.59GHz, GPU为NVIDIA GeForce GTX 1660 SUPER,16 GiB运行内存。编程语言为python3.6.10,深度学习框架为TensorFlow。
2.4 RCNN分类实验
为了获取最优的网络模型,选取不同残差网络的层数进行实验。将卷积神经网络与2层残差神经网络、3层残差神经网络、4层残差神经网结合,分别构建RCNN-2, RCNN-3, RCNN-4模型,分别训练5次求其平均准确率进行对比,结果如表1所示,准确率和损失函数值如图6所示。

表1 不同残差层数测试结果
从表1可以看出,RCNN-3准确率高且损失函数值最低,分别为99.3%和0.003;RCNN-2次之,分别为91.6%和0.062;而RCNN-4准确率相对较差,主要是随着网络深度的提高,网络参数的增多,出现神经网络退化现象,导致在使用4层残差网络模型的过程中出现了精度低,损失值提高和收敛慢等现象。同样在图6中也可以看出,融合3层残差结构的RCNN-3分类模型效果最好,在准确率和损失函数值收敛速度方面都要优于其他分类模型,且在准确率大小方面整体上也是最好的,因此选择RCNN-3模型作为本文最优模型。本文最优模型参数设置如表2所示。

(a) 准确率
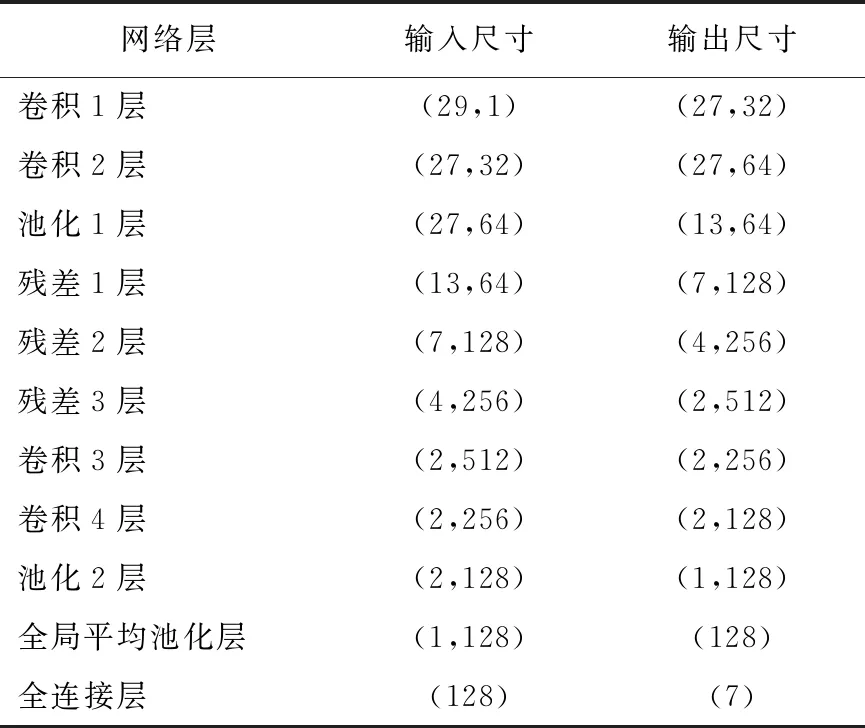
表2 RCNN-3模型参数
表2中,卷积1层到卷积4层步长为1,残差1层到残差3层步长为2,填充方式统一是same,激活函数为RELU;池化1层和池化2层池化核大小为2;全连接层激活函数为SoftMax。数据输入尺寸为(29,1),经过结构1尺寸变为(13,64),放大了感受视野,方便提取特征;残差1层的输入为(13,64),经过3个残差块结构输出为(2,512),进一步放宽了感受视野。后面再加上一个结构1,目的是收缩视野,精炼重要特征,再通过全局平均池化层进行降维操作,最后SoftMax实现高精度多种类扬声器异常声分类。
2.5 扬声器异常声分类对比实验
扬声器异常声检测主要由特征提取与异常声分类2个部分组成。为了验证本文方法的优势,分别进行了2组对比实验。一组固定分类器为RCNN-3,在模态分解方面分别使用EMD,EEMD,WPD和AVMD进行对比,其平均分类准确率分别为85.6%、87.2%、96.7%和99.3%。可以看出,使用AVMD模型分类效果最优,主要是因为使用VMD可以解决模态混叠问题,更有效提取特征,且使用RF-RFE算法对特征进行了筛选,剔除了无效特征,只保留最优特征子集,从而提高了分类准确率。另一组固定模态分解方法为AVMD,在分类器方面分别使用SVM、XGBoost、GA-SVM(genetic algorithm-support vector machines)和RCNN-3进行对比,准确率依次为89.5%、92.9%、96.2%、99.3%;可以发现,使用RCNN-3模型分类效果最优,主要是由于卷积神经网络和残差结构的结合,卷积神经网络相对于传统分类方法学习特征能力更强,残差结构引入可以使用更深层次网络结构,有利于学习更多,更深层次的特征,这2方面的优势结合提高了平均分类准确率。
为了验证GWO算法,VMD模型引入的作用,做了3个实验:实验1不进行特征提取,直接将音频数据输入分类器RCNN-3中进行分类;实验2使用VMD默认参数进行特征提取,然后送入RCNN-3中进行分类;实验3用GWO算法优化VMD之后的参数进行特征提取,最后送入RCNN-3进行分类。实验1到实验3的分类准确率分别为80.6%、93.8%和99.3%,可以发现VMD和GWO算法的引入准确率都有一定提高,主要是因为VMD可以分离不同频段数据,更有效、有规律提取扬声器异常声的重要特征,而GWO算法的引入,解决了VMD中α和K的最优数值确定问题,便于VMD根据实际情况自适应选择参数,达到特征提取的最优效果,减少人为选择参数的误差。
综上,融合残差结构的卷积神经网络模型与AVMD相结合在处理非线性、非平稳的扬声器异常声信号中具有极大优势。
3 结 论
本文针对扬声器的异常声检测精度低和特征提取困难等问题,提出了将自适应变分模态分解和残差卷积神经网络相结合的方法。通过实验对比,结论如下。
1) 在特征提取方面,AVMD中用GWO算法优化VMD,可以将采集到的声响应信号自适应的分解到不同频带上;有效解决了模态混叠、端点效应等现象;此外,通过RF-RFE算法进行特征选择,可以挑选出最优特征子集,减少数据输入维度,提高模型分类精度。
2) 在分类模型方面,RCNN-3分类效果优于SVM、XGBoost、GA-SVM;RCNN-3模型具有收敛速度快、分类精度高以及损失值低等优势。实验充分验证了本文所提方法在扬声器异常声分类方面的优势。
猜你喜欢
青少年科技博览(中学版)(2022年9期)2022-11-01
网络安全与数据管理(2022年3期)2022-05-23
家庭影院技术(2021年7期)2021-08-14
北京航空航天大学学报(2020年10期)2020-11-14
家庭影院技术(2019年8期)2019-08-27
自动化学报(2019年6期)2019-07-23
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
创新作文(小学版)(2016年11期)2016-11-11
河南科技(2015年8期)2015-03-11
