
中文地名地址成分信息识别
2023-05-10 10:26山东科技大学测绘与空间信息学院王钟岳刘洋
数字技术与应用 2023年4期
山东科技大学测绘与空间信息学院 王钟岳 刘洋
在随着人工智能的快速发展和大数据时代的到来,如何在大量的数据中快速的并准确的获取我们所有需要的数据成为了现在计算机技术发展的重要方向,由于中文地名的复杂性对当前的地名地址识别工作起到了较大的困扰。本文利用基于深度学习的模型对中文机构名的识别和匹配进行研究,先通过CRF++训练分词模型,然后通过有限状态机模型结合的状态转移函数,对分词后的地址进行识别,能够准确地对地名地址进行识别,研究结果有很大的现实意义。
随着地理信息和大数据的快速发展,如何准确的识别出我们需要的信息成为现在研究的关键,中文地名地址的命名实体识别是自然语言处理的一项重要任务[1]。命名实体识别是进行信息匹配的前提,命名实体识别是对文本中的重要名词和专有名词进行定位和分类的问题,地名和我们的生活紧密结合在了一起,所以如何准确并快速的检索到我们需要的地名成为了现在研究的关键。
1 国内外研究现状
中文地址成分识别是地址解析中地址分词的一个领域,归类总结,可以将这些方法分为以下3 个类别:基于词典、基于地址规则、基于规则和统计相结合。梁南元[2]教授最先提出了基于词典匹配的方法。于滨[3]提出了一种先通过训练样本来建立起标准地址库,然后再通过推理机对模糊地址进行判断的专家系统,这种方法的缺点在于标准地址库规模的大小严重影响系统的识别率。2006 年钱晶和张杰等提出了基于最大熵的地名识别方法[4],利用最大熵来进行训练提取特征值,同时结合不断变化的词表和规则对地名进行识别,对于地名地址识别有很好的效果。孙存群等[5]提出了分级地址库模型,简化了实现流程,减少了维护分词的步骤。邬伦[6]等提出了基于条件随机场的中文地名识别方法,通过统计地名用字的特征,设计特征模板,根据特征模板构建特征函数,从而完成命名实体识别。随着有限状态机模型的成熟,可以建立中文地址中存在的成分状态转换关系与状态转换函数,运用地址数据训练状态转移概率,可大大减少各个地址要素之间的相互影响。因此,在解决地址成分识别的问题上,有限状态机模型逐渐成为一种切实可行的方法。
2 中文地名的成分解析
2.1 中文地址成分分类
地名的分类是进行地名识别的首要工作,地名应便于记忆,并能帮助运用者能联想起地名与地理实体之间稳定的联想关系。那些容易与特定地理实体建立起关联,能生动地反映当地特点、体现地域文化特征的地名,因指位效能强而受到社会的青睐[7]。地名用字是地名构成的重要部分,根据不同的目的和原则,可以采用不同的地名分类法[8]。因此本文想要通过缩减地名中地址要素的分类,通过几个大类对地名进行整体概括,包括了行政区划、道路、居民区、地址、兴趣点、组织机构名等一共6 大类作为有限状态机识别状态的基础。
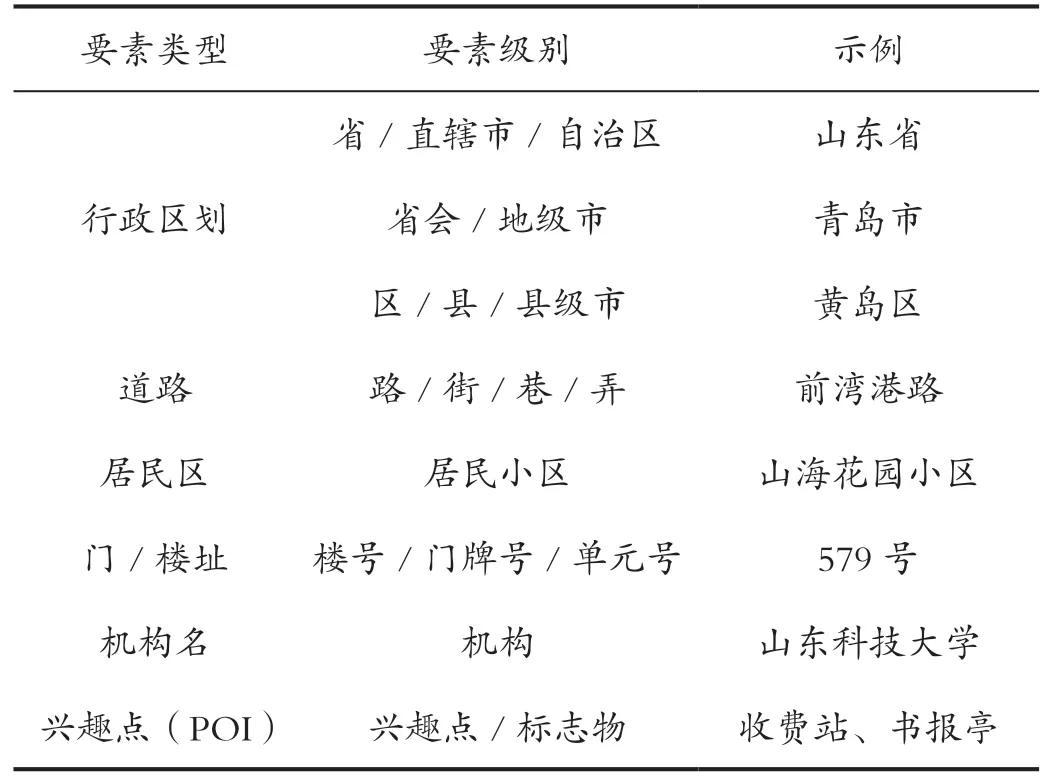
表1 中文地址要素分类Tab.1 Classification of Chinese address elements
2.2 中文地址分词工具
现有的中文分词方法主要有以下几种:
(1)基于匹配的分词方法。基于匹配的分词方法又称为机械分词的方法。它是指按照一定的方法将需要分词的字符串与词典中的词条进行匹配,完成分词。主要有最大匹配法,最大匹配法包括正向最大匹配法、反向最大匹配法和双向最大匹配法。
例如对于青岛市直属机关来说我们的词典中有青岛市、青岛、直属、市直属、机关。进行正向最大匹配的时候第一个识别的词语就是青岛市,第二个词为直属,第三个词为机关。结果为{青岛市、直属、机关}进行逆向最大匹配的时候识别的第一个词为机关,第二个词为市直属,第三个词为青岛,结果为{青岛、市直属、机关},而利用双向最大匹配算法的结果为{青岛市、直属、机关}。
(2)基于理解的分词方法。基于理解的分词方法就是让计算机去理解学习人脑对句子的理解,从而进行分词。它的主要区别与基于规则的方法的特点就是,再进行分词的同时对语句的信息构词以及相对应的语境进行理解,从而达到减少错误的出现。主要包括3 个关键,分词系统、句子语义理解、总控制。在总控制的帮助下,分词系统和语义理解系统对分词结果进行检查,减少错误的出现,模拟了人脑进行处理的过程,但它有一定的缺点,需要大量的语言知识和信息,再加上汉语知识的复杂性,很难将信息组织成机器可以学习读取的形式。
(3)基于统计的分词方法。基于统计的分词方法就是在有大量已经分词的数据的前提下,利用机器学习模型学习分词切分的规律,从而实现对分词任务的切分。对训练文本中词组合的频度进行统计,计算他们之间互现的信息,根据他们出现的频率从而认为他们构成了一个词,也是一种无词典的分词方法。随着各种大规模标注语料库的建立,基于统计学习的分词方法渐渐成为了主流的方法。
本文选择利用统计的CRF++分词方法,CRF++的分词思路主要是通过对词语进行标注,对句子中的字进行标注,既考虑了文字出现的频率也同时考虑了上下文信息,具有很好的学习能力,而且对未登录词和具有歧义的分词结果有较好的效果。
中文地址分词工具采用条件随机场的基本工作原理,CRF 将句子中每个单词根据所在位置进行分类,是目前的主流序列标记算法[9]。CRF++把中文分词任务看作是序列标注任务,通过BMES 四字标注法进行标注,B 代表词首,M 代表词中,E 代表词尾,S 代表其他。
通常我们将等待分词的语句称之为输入序列,分词完成后的结果为输出序列,所以CRF++分词的目的就是:在给定输入序列A 的条件下,找到输出概率最大标注结果B。将分词后的结果作为模型的输入,输入进本文的有限状态机模型中。
3 基于有限状态机的地址成分识别
本文的基本识别思路是:首先,利用中文地址分词工具对地址串进行分词标注;然后将分词好的地址串依次打入有限状态机模型,利用标注及特征词完成成分级别的识别,若存在由一种状态引出两条方向的情况,则采用训练好的转移函数判断分支权重,识别为权重较大的状态。最后,利用构建好的验证函数对状态转移进行验证,判断是否无误。整个地址串成分全部完成有限状态机流程,则完成成分识别。
作为在有限状态机中最重要的部分,状态转换函数能够识别各个地址成分中的特征标注及特征词,按照特征词来完成状态的识别,并将其打入相应的状态。而遇到在成分中不包含特征词的情况下,这时候我们无法通过标注以及特征词来判定该成分的状态,也就是说此时会存在两种及两种以上的状态转移可能,所以状态转移分支权重这时候会起到很重要的作用。
当地址成分通过转换函数进入某一状态后,对于地址串中的行政区划部分我们往往能够做到准确的识别,但对于地址串后面的街道名、机构名等往往简单识别会产生歧义。因此,本文特建立验证函数,根据某一成分的后一个状态来进一步验证某一地址元素的正确状态。
地址串根据转换函数暂确定状态后,需要进行进一步的验证。对于地址串“a,b,c, d”,从左至右依次将成分输入模型,输入a 成分,根据状态转换函数暂定某个状态A,此时成分a 进入待定验证过程,进而根据下一个成分b 的状态来进行判断,是否根据状态转换关系能够从a 到b,如果可以,则a 可以确定为状态A,如果a 为终止成分,则a 也可以判定为独立状态A,下一步将输入b 成分同样进行验证,否则的话,成分ab 则暂时被看为一个状态B。
此时进入循环,将ab 作为一个成分输入模型,ab进入待定验证过程,如果根据状态转换关系能够从ab到c 或者ab 为终止成分,则ab 可以看成一个独立状态,验证结束。如果ab 不能够到c,则将abc 暂看成一个状态,继续执行循环验证abc 的状态,从而完成识别。
4 实验结果分析
本文的实验语料与上文同样是通过高德的开放数据API 的AddressComponent 对象,是从高德地图上爬取地址成分识别实验所需的语料。本次实验总共爬取了山东省的地址数据总共11270 条的地址数据,三组模型都对这11270 条数据来进行识别测试,作为统一的实验语料。然后输入有限状态机、HMM 和CRF 识别方法进行对比。
对于实验当然是需要实验评价的指标,本文将采用召回率、准确率以及综合指标F 值[10]3 个指标来评价实验以及做实验之间的对比。
通过统计3 种模型的实验结果,得到的测试结果如表2 所示。

表2 各模型实验结果Tab.2 Experimental results of various models
5 总结与展望
5.1 本文总结(This Paper Summarizes)
地址成分的识别是地址匹配技术阶段的第一步,也是利用地址信息导航以及定位系统的基础性的一项技术,这些技术与人们的生活有着息息相关的联系,对人们的生活有着重要的影响。
对于本文而言,主要的核心工作集中在以下几点:
(1)对中文地名地址的成分进行分析,将中文地址进行分类;
(2)通过分词对中文地址的成分进行划分,更好的理解中文地址的构成成分;
(3)为了使有限状态机起到更加准确的效果,本文还提出了构建验证函数,建立判别条件来不断验证地址成分。地址成分通过有限状态机转换函数被判定为某状态后,经过状态验证函数可进一步消除识别歧义,达到更好的识别效果。
5.2 未来工作(Future Work)
基于有限状态机模型的地址成分识别方法是具有一定优势的,但是还存在需要改进的地方。
(1)地址的分词采用CRF++训练的方法,虽然准确率较高,但分词的结果会影响后续标注的正确率。因此,在后续的研究中应该尝试改进这一弊端,这需要大量的准确标注的数据。
(2)对于有限状态机的验证函数,应该不仅仅局限于通过后面的成分来进行判别,应该需要考虑多地址成分之间的关系,加大对地址成分构成的要素分析与统计,把握中文地址不同类别地址之间的差距与区别,在识别的时候能更好地把握地址成分的完整性。
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
北京航空航天大学学报(2019年9期)2019-10-26
小学生作文(低年级适用)(2019年5期)2019-07-26
读友·少年文学(清雅版)(2018年12期)2018-04-04
黑龙江科学(2011年2期)2011-03-14
外语学刊(2011年3期)2011-01-22
空间控制技术与应用(2010年5期)2010-12-23
现代电子技术(2009年14期)2009-09-05
