
基于轻量级卷积神经网络的注油孔检测算法
2023-05-08 03:55卢宗远丛英浩
安徽工业大学学报(自然科学版) 2023年2期
孟 瑞 ,卢宗远 ,丛英浩
(1.安徽工业大学a.机械工程学院,b.工程研究院, 安徽 马鞍山 243032;2.上海梅山钢铁股份有限公司,江苏 南京 210039)
烧结机台车在作业的整个过程中,台车轴承经受着高温、重载等恶劣的工况,轴承在缺少润滑的状态下磨损加剧,经常出现损坏,严重影响台车的使用寿命,进而影响烧结生产稳定运行。为确保烧结机台车车轮的良好润滑状态,目前使用一种机器视觉的跟踪注油系统控制机器人自动为车轮注油。其中常采用全局阈值分割、数学形态学、边缘特征提取、霍夫圆检测等传统机器视觉检测算法来定位注油孔[1]。传统检测算法快速便捷,但易受光照、灰尘、油污等现场因素的干扰,导致检测的准确率不高;此外,人工设计的特征与分类器的主观选择也影响识别的准确率。对于表面整洁的注油孔,采用阈值分割和霍夫圆检测等传统机器视觉算法可快速准确地检测到其坐标;但对于注油后的油孔因表面常留有黄油油渍,且油渍分布不规则,采用传统机器视觉检测算法很难准确检测注油孔位置。
与传统机器视觉检测算法相比,卷积神经网络作为深度学习领域的重要分支,在处理图像数据时采用卷积神经网络提取特征,特征表达及泛化能力优于人工设计的特征[2]。随着计算机视觉与深度学习技术在工业机器人领域的广泛应用,深度卷积神经网络(deep convolutional neural networks,DCNN)在视觉机器人中突显出巨大优势。深度学习检测算法主要分为两种,一种是两阶段目标检测算法,主要有RCNN(region with CNN feature)、Fast RCNN、Faster RCNN[3-5]等,先由网络获取目标区域候选框,再通过RCNN 进行分类。赵卫东等[6]使用Faster RCNN 作为电表字符缺陷分步检测算法,在检测每张图像耗时0.6 s 的情况下,准确率达99.9%。然而两阶段目标检测中生成候选区域步骤占用大量资源,导致检测速度慢。与之相比,以SSD(single shot multibox detector)[7]、YOLO[8-9]等为代表的单阶段目标检测算法,只需一次提取特征即可实现目标检测,检测速度快。李维刚等[10]通过调整YOLOv3 算法结构,融合浅层与深层特征形成新的大尺度检测图层,在NEU-DET 数据集上的检测精度较原YOLOv3 算法提高了11%,检测速度保持在50 F/s;卢艳东等[11]提出一种改进的YOLOv3-tiny 轻量级轨道紧固件检测算法,采用具有反向残差的线性瓶颈结构为主干,采用深度可分离卷积检测头部,改进的YOLOv3-tiny 检测精度达98.81%,检测速度达25 F/s。
上述算法中通过使用改进的卷积神经网络完成不同尺度目标的检测。对于注油机器人等工业流水线类机器人,检测的目标尺度相对固定、检测难度较低,但对检测的实时性要求较高;且机器人部署平台性能有限,当前深度学习模型冗余度较大无法充分发挥检测效果。鉴于此,基于YOLOv5 算法,提出一种改进的轻量级检测算法YOLOv5-S,采用ShuffleNetv2 作为特征提取部分并调整输入图像分辨率和深度卷积核尺寸,以期机器人在工控机算力和存储资源有限时也具备良好的识别率和检测速度。
1 网络构建
1.1 YOLOv5 网络结构
YOLO 系列算法是目前使用最多的一种单阶段目标检测算法,当前最新版本为YOLOv5,结构如图1。YOLOv5 对应4 个模型,分别是v5s,v5m,v5l 和v5x。YOLOv5s 模型相对简洁、训练速度快,其他版本模型都是在YOLOv5s 模型的基础上对结构进行加深与加宽的。文中选用模型最小的YOLOv5s。

图1 YOLOv5 网络结构Fig.1 YOLOv5 network structure
YOLOv5 分为三部分,具体为特征提取、FPN 与YOLO Head。将输入的图像缩放至规定尺寸后,在主干网络中进行特征提取,获取3 个有效特征层用于下一步网络的构建;FPN 为YOLOv5 的加强特征提取网络,主干网络输出的3 个有效特征层通过FPN 进行特征融合,结合不同尺度的特征信息进行特征加强;YOLO Head 是YOLOv5 的分类器与回归器。通过主干网络和FPN 获得3 个加强的有效特征层,每个特征层的特征图都有宽、高和通道数,此时特征图可看作特征点的集合,每个特征点的特征数即为通道数。每个特征点由YOLO Head 判断是否有目标物体与其对应。因此,YOLOv5 算法目标检测流程为特征提取、特征加强、预测特征点对应的目标。
1.2 ShuffleNetv2 网络结构
Ma 等[12]将ShuffleNetv2 作为一个有效的分类网络,同时提出4 条实用准则:
1) 当卷积层输入输出特征通道数相等时,内存访问量(memory access cost,MAC)最小,模型速度最快;
2) 卷积的分组运算增加MAC,以减慢模型速度;
3) 模型中的分支数越少,模型速度越快;
4) 元素操作的时间消耗远大于触发器中反映的值,应尽量减少元素操作。
基于上述4 个标准,文中提出ShuffleNetv2 网络结构,如表1。在ShuffleNetv2 网络模型中,主要结构是中间的3 个stage,每个stage 中ShuffleNetv2 的下采样单元均重复1 次,ShuffleNetv2 基本单元重复次数分别为3,7,3。图2(a)为ShuffleNetv2 的基本单元,输入的特征通道被平分后分别进入2 个分支卷积,再将输出进行堆叠操作,特征图通过基本单元的操作后大小和通道数不变。图2(b)为Shuffle-Netv2 的下采样单元,将输入的特征通道复制2 份直接进入2 个分支,特征图尺寸通过下采样单元的操作后变小,输出的通道数增加1 倍。对于ShuffleNetv2结构,在边缘设备部署时具有较低的延时及较好的泛化性能。为实现在更低计算资源的嵌入式场景中使用,或在轻量级检测框架中作为网络的特征提取部分,需对ShuffleNetv2 进行优化。
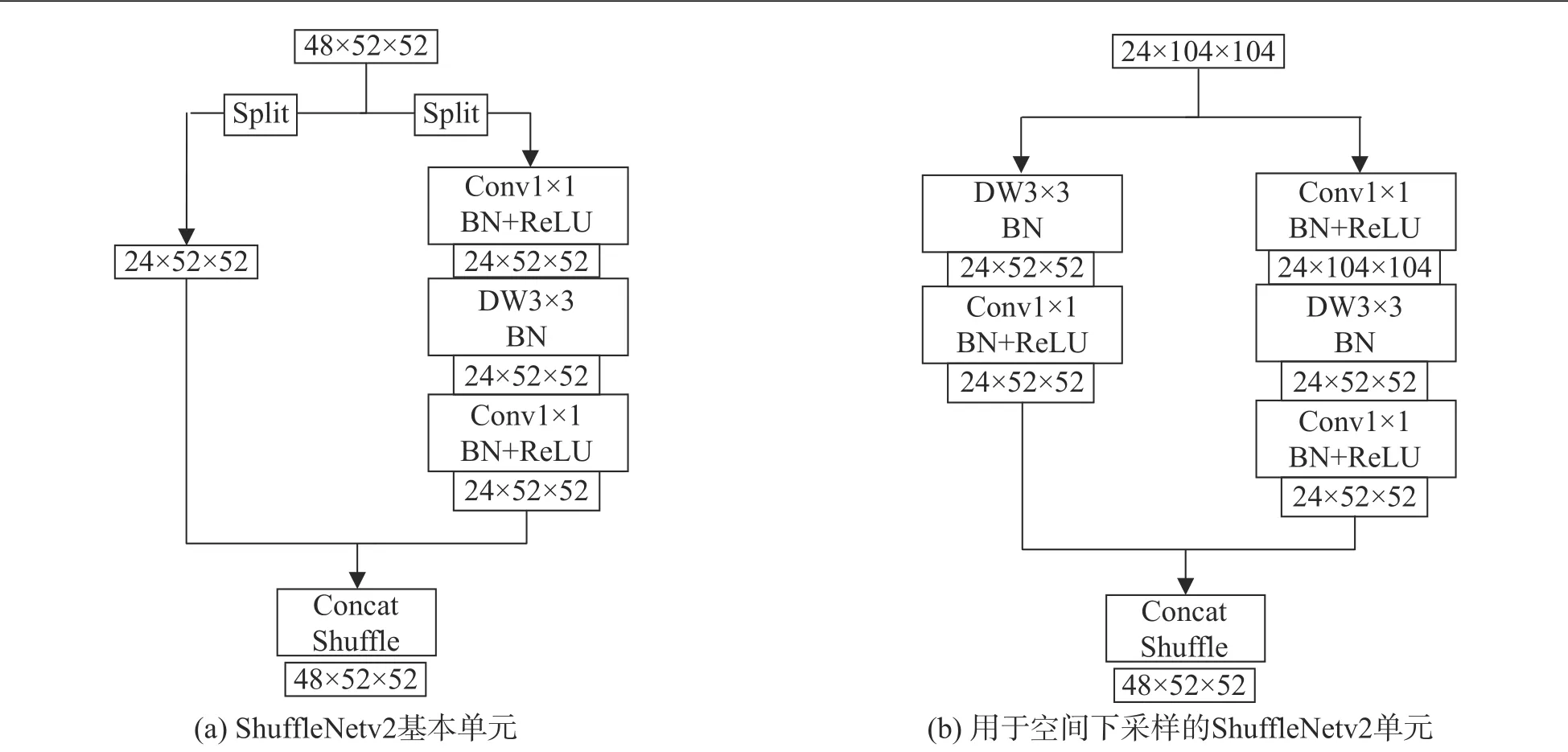
图2 ShuffleNetv2 的构建块Fig.2 Building blocks of ShuffleNetv2
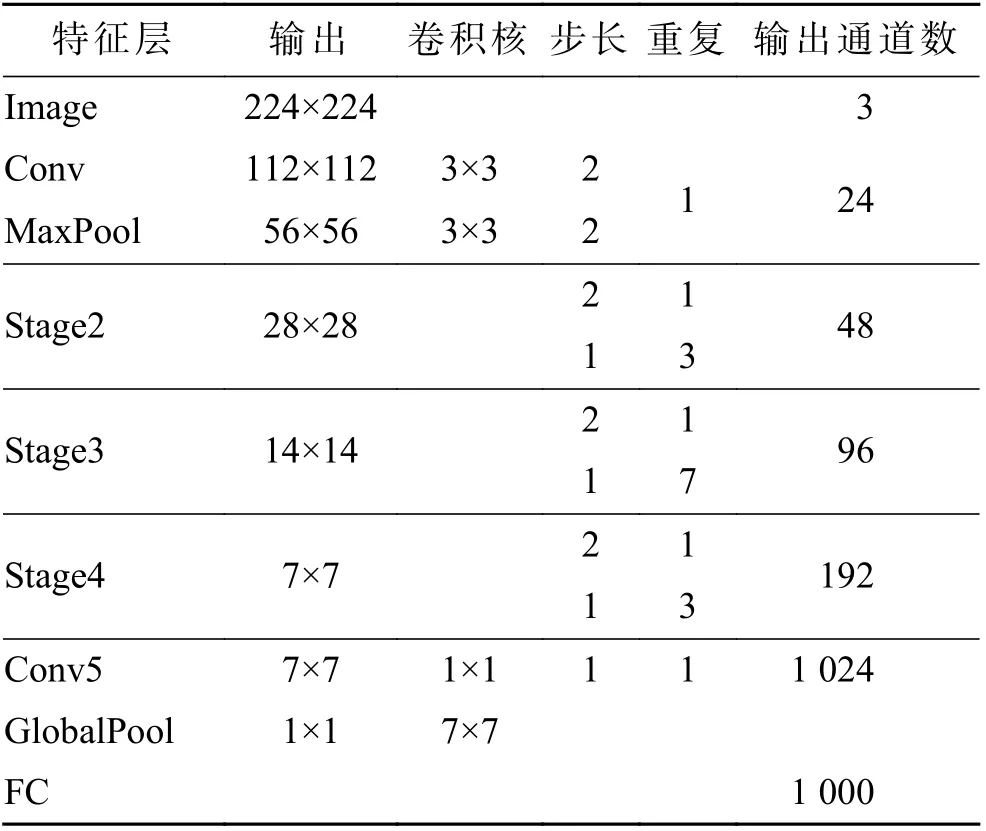
表1 ShuffleNetv2 网络结构Tab.1 ShuffleNetv2 network structure
1.3 YOLOv5-S 网络结构
CNN 中多数卷积运算的目的是提取图像特征,卷积过程中网络每层输出特征图上的像素点在输入图像映射的区域大小被称为感受野。大的感受野包含更多的上下文信息和像素信息,有利于对大型对象的定位。文献[13-14]也证明了感受野对语义分割和目标检测任务的有效性,YOLO,SSD,RetinaNet 等算法特征提取部分的定位任务比分类任务难度大。由此表明在后期的特征融合阶段浅层特征应更充分,同时只有结合深层特征才能在目标检测任务中达到理想的效果。从目前的轻量级特征提取网络中发现,ShuffleNet[15]、MobileNet[16-17]的输入分辨率限制了感受野的大小,且缺乏浅层特征,不利于目标检测任务中的定位。
为更好地满足目标检测任务中的特征提取,对轻量级卷积神经网络ShuffleNet 进行改进,将输入图像的分辨率调整为416×416,以确保模型能够提取丰富的浅层特征信息;将ShuffleNetv2 部分基本单元中深度卷积的卷积核尺寸由原来的3×3 替换为5×5,以进一步扩展特征图的感受野,如图3。ShuffleNetv2 最后3 个特征层的功能主要是分类,因此只保留Conv1,Maxpool,Stage2,Stage3,Stage4 作为YOLOv5-S 中特征提取部分,具体网络结构如表2。
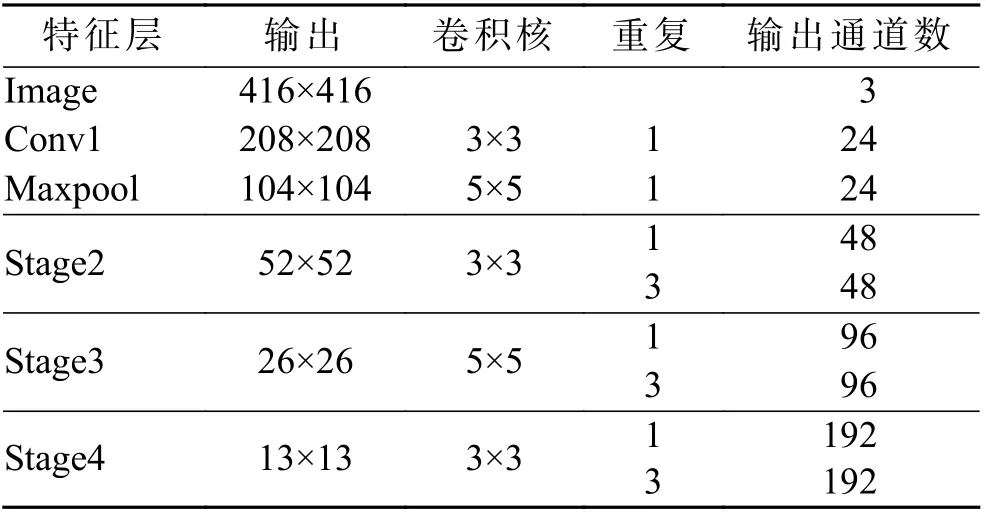
表2 基于ShuffleNetv2 的特征提取网络Tab.2 Feature extraction network based on ShuffleNetv2

图3 改进ShuffleNetv2 的构建块Fig.3 Building blocks for improved ShuffleNetv2
文中通过改进YOLOv5 算法得到轻量级目标检测算法YOLOv5-S,将其网络特征提取部分替换为改进的ShuffleNetv2 结构,YOLOv5-S 算法的网络结构如图4。由图4 可看出:改进算法的网络结构中Stage2,Stage3 和Stage4 的输出分别作为特征融合网络的输入;每个Stage 操作先经过1 个ShuffleNetv2空间下采样单元和3 个重复的基本单元,减少了相同的操作次数,保留了空间金字塔网络(图中的SPP结构)。

图4 YOLOv5-S 网络结构Fig.4 YOLOv5-S network structure
2 实验验证
2.1 数据筛选与处理
采取不同工况下注油孔的图像数据样本,按照工况将数据样本分为三类,即正常注油、注油孔缺失、注油孔密封球损坏,如图5。共采集1 408 张图像,每张图像的分辨率为 640×480,将样本按8∶2 划分为训练集和测试集,结果如表3。使用开源LabelImg 对图像中的注油孔进行标注及分类,样本类别名分别为“oiling”“missing”“breaking”,标注后的文件以 txt 作为后缀,与图像名保持一致。对于所有的实验,使用i7-10700 CPU 加1050 Ti GPU 进行训练,深度学习框架为Pytorch;仅使用CPU 进行测试验证,模拟部署环境。

表3 数据集类别分类Tab.3 Classification of dataset categories

图5 数据集分类Fig.5 Data set classification
2.2 实验与结果分析
为验证改进算法YOLOv5-S 的有效性,在配置条件及数据集相同的条件下对YOLOv5-S,YOLOv5,YOLOv3-tiny[12]进行训练实验。设置初始学习速率为0.01,若模型在2 次迭代以上采用验证损失函数进行训练而损失值没有减少,则将学习速率降至当前速率的0.10,最后在300 次迭代时终止。在轻量级目标检测领域,算法评估指标主要包含模型大小、速度和性能3 个方面。模型大小即所占内存大小,速度评估指标有帧数(FPS)、浮点操作次数(FLOPs)等,性能评估指标有平均精度均值(mean average precision,mAP)、损失、召回率等。YOLOv5-S,YOLOv5,YOLOv3-tiny 算法的mAP、模型大小、FLOPs 等的实验结果如表4。由表4 可看出:与YOLOv5 相比,YOLOv5-S 的mAP 仅下降0.1%,模型大小缩减了10.779 MB,浮点运算缩减了11.7×109次,检测速度提升了11.7 F/s;YOLOv5-S 在速度和精度评估指标方面均优于YOLOv3-tiny。

表4 目标检测模型性能评价指标实验结果Tab.4 Test results of target detection algorithm performance evaluation indicators
YOLOv5-S 的训练与验证数据如图6。

图6 YOLOv5-S 算法的训练与验证数据Fig.6 Training and validation data of YOLOv5-S algorithm
图6 中:横坐标为迭代次数n;纵坐标为训练结果指标。其中:Box,Objectness,Classification 分别为训练集回归坐标损失、置信度损失,分类损失;Val box,Val objectness,Val classification 为验证集的3 项损失;mAP@0.50 为图像预测框和真实框在交并比为0.50 时的平均精度均值;mAP@0.50~0.95 为交并比在0.50~0.95 之间的平均精度均值。由图6(a)可看出:回归坐标损失、置信度损失和分类损失在训练集迭代过程中呈平稳下降趋势;精度、召回率在迭代过程中震荡上升并趋于稳定。由图6(b)可看出:3 项损失在验证集迭代过程中同样呈平稳下降趋势;整体的mAP@0.50 趋近于1,且整体的mAP@0.50~0.95 在0.9以上。证明YOLOv5-S 算法在注油孔检测中效果稳定可靠。
通过精度和召回率关系曲线可直观比较检测算法的性能,分别将YOLOv3-tiny 和YOLOv5-S 算法训练结果中召回率为横坐标,精度为纵坐标绘制曲线,结果如图7。曲线围成的面积越大网络的性能越高。由图7 可看出:同一坐标系中,YOLOv3-tiny的精度和召回率关系曲线被YOLOv5-S 的精度和召回率关系曲线完全包含,说明后者的性能优于前者。
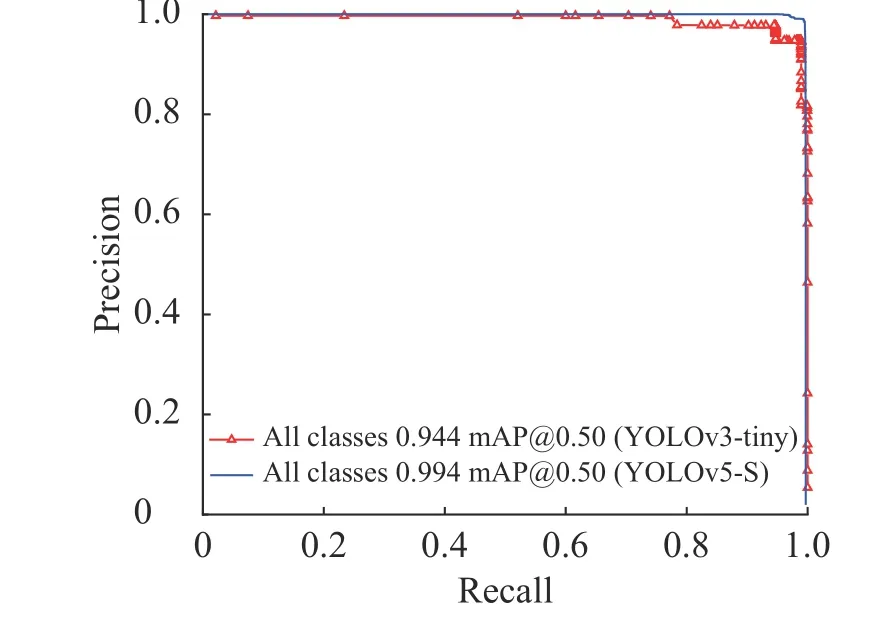
图7 YOLOv5-S 和YOLOv3-tiny 算法的精度-召回率曲线Fig.7 Recall-precision curves of YOLOv5-S and YOLOv3-tiny algorithms
改进算法的检测效果如图8,图8(a)为洁净情况下注油孔图像的检测效果,8(b)为油污情况下注油孔图像的检测效果。图中矩形框为注油孔的检测框,检测框上方文字为类别名,数字为检测注油孔的置信率。由图8 可看出:改进算法对表面留有油污的注油孔也具有良好的检测效果。

图8 目标检测结果Fig.8 Target detection results
3 结 论
针对传统机器视觉检测算法受限及已有的深度学习检测模型存在冗余等问题,通过YOLOv5 算法的改进,提出一种轻量级深度学习检测算法YOLOv5-S,使用ShuffleNetv2 作为特征提取部分,通过更改输入图像的分辨率及扩大深度卷积的卷积核尺寸等手段提升特征提取能力,且使用注油孔样本数据集进行对比验证。结果表明:相比原算法,YOLOv5-S 的mAP 仅下降0.1%,而模型大小和浮点操作次数分别缩减76.7%和71.3%,检测速度提升了11.7 F/s;YOLOv5-S 的检测速度和精度也均优于已有的轻量级目标检测算法YOLOv3-tiny,进一步说明了YOLOv5-S 中更换网络特征提取部分以及优化网络结构的有效性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2017年11期)2017-04-04
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
管理现代化(2016年3期)2016-02-06
智能系统学报(2015年4期)2015-12-27
噪声与振动控制(2015年4期)2015-01-01
