
基于特征感知和更新的显著物体检测
2023-05-08 03:01陈小伟
计算机应用与软件 2023年4期
陈小伟 张 晴
(上海应用技术大学计算机科学与信息工程学院 上海 201418)
0 引 言
显著物体检测(Salient Object Detection,SOD)旨在从视觉场景中自动检测和分割出最引人注目的物体,其检测结果通常用灰度图表示,每个像素的灰度值表示该像素属于显著物体的概率。显著物体检测可广泛应用于各种计算机视觉应用任务以大幅度降低其处理复杂度,包括图像编辑[1]、行人再识别[2]、视觉追踪[3]和图像分割[4]等。
由于基于手工选择特征的传统的显著物体检测方法[5-6]主要采用中低层特征和各种先验性假设(对比度、背景、边界等)进行显著性计算。最常用的对比度方法基于显著性区域与背景的颜色特征具有较大差异这一假设。传统的显著物体检测方法面对简单场景时检测效果良好,但是由于该类方法仅关注中低层特征,缺乏对高层语义信息的表示和学习能力,因此在面对复杂场景时往往不能取得令人满意的检测效果。
卷积神经网络由于其强大的特征表征和学习能力,被广泛应用于计算机视觉任务,取得了令人瞩目的成绩。基于卷积神经网络的显著物体检测方法[7-9]能提取图像不同层级的特征,浅层卷积层组得到的特征富含中低级特征,但缺乏全局信息,而深层卷积层组得到的特征包含丰富语义特征,但缺乏细节信息。因此,如何从卷积神经网络中提取不同层级的特征,以及如何有效融合这些不同层级的特征,是关键且具有挑战性的问题。
现有显著性检测模型一般采用多尺度特征方法提取全局特征,然而这些方法仅仅针对同一层级特征的不同尺度进行建模,再简单融合这些多尺度特征,各个尺度特征之间缺乏交互。针对此不足,本文提出全局特征信息感知模块(Global Information Perception Module,GIPM),对同层级特征的各个尺度进行建模,利用各尺度特征之间得到的交互信息进行多尺度特征更新,有效表示和提取显著物体的语义特征,从而获得目标物体的位置信息。
此外,骨干网络的浅层侧输出具有丰富且杂乱的低层级特征,而显著物体检测只需针对特定区域的细节特征进行学习,因此,常用的逐层融合结构容易引入噪声。针对此不足,本文提出显著特征更新模块(Saliency Feature Refinement Module,SFRM),利用全局信息直接引导局部特征,聚焦目标区域学习有用的细节信息,从而得到具有精确轮廓信息的显著物体检测结果。本文工作的主要贡献有:
1) 提出一种新的卷积神经网络用于显著物体检测,实现端到端的像素级预测,利用全局特征感知和局部信息更新,获得具有辨识力的显著性特征,从而提升模型的检测性能。
2) 提出全局特征感知模块和局部特征更新模块,利用多尺度的全局特征引导网络的每个侧输出聚焦学习有用区域的细节特征。
1 相关工作
近年来,深度学习技术在计算机视觉的各类任务中得到了广泛的应用,大幅度提升了算法模型性能。基于深度学习技术的显著物体检测模型能提取图像的高层语义信息,因此突破了传统模型的性能瓶颈,大大提升了检测性能。基于深度学习的显著物体检测算法可以分为两类:区域级预测模型[10-11]以及像素级预测模型[12-14]。
区域级预测模型以区域为基本单位,通过深度神经网络预测其深度特征,位于同一区域内的所有像素享有同样的显著性值。Li等[10]利用全卷积层整合从一系列区域中提取多尺度特征。在文献[11]中,研究人员采用两个深度卷积神经网络以获取图像区域的全局和局部特征。这些区域级预测模型较传统方法提升了检测性能,然而,由于其不能有效表示图像的全局语义信息,因此在面对低对比度、背景杂乱等复杂场景时,检测准确率较低。另外,这类方法依赖区域分割技术,必须多次运行网络才能计算图像中所有区域的显著性值,因此其算法非常耗时,实用性较低。
像素级预测模型利用全卷积神经网络结构实现端到端的预测,提取和融合从骨干网络不同边侧输出的多层级多尺度特征。Liu等[15]提出基于池化的全局引导模块和特征整合模块,利用高层语义特征逐步更新多层级显著性图。Wei等[16]设计了交叉特征模块以融合多层级特征,探索特征间的互补性。Pang等[17]提出相邻层级多尺度特征的融合方式。Zhao等[18]设计了一种新型的门控双分支结构,促进不同层次特征之间的协作以提高整个网络的可分辨性。Wu等[19]旨在通过叠加交叉细化单元(CRU)同时细化显著目标检测和边缘检测的多层次特征。文献[20]通过渐进式上下文感知的特征交织整合模块有效集成多层级特征。尽管这些方法极大提高了检测性能,但是在边界细节和分割质量上仍存在一定的提升空间。
2 本文模型
本文基于特征金字塔(Feature Pyramid Network,FPN)结构构建网络模型,自顶向下逐层级连接深层特征和浅层特征,网络结构如图1所示。主要包括两个部分:全局信息感知模块(Global Information Perception Module,GIPM)和显著特征更新模块(Saliency Feature Refinement Module,SFRM)。首先,采用预训练的卷积神经网络ResNet-50作为骨干网络生成多层级多尺度的侧边输出粗糙特征;然后,在每个侧边采用一个卷积层组提升粗糙特征的显著性表达能力,每侧的卷积层组均由3个3×3的卷积层组成;其次,采用全局信息感知模块GIPM产生全局语义特征,定位显著物体区域;最后,利用显著特征更新模块SFRM融合全局特征和侧边输出特征,得到最终的具有精确轮廓信息的显著物体预测结果。
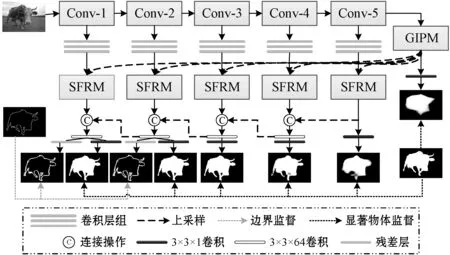
图1 本文网络结构模型
2.1 GIPM
全局特征具有丰富的语义信息,能定位出显著物体的位置,在显著物体检测中具有十分重要的作用。在不同的视觉场景中,显著物体具有不同的尺度,因此良好的显著物体检测模型需要具有获取全局特征的多尺度信息的能力。为了更好表征具有全局上下文信息的多尺度语义特征,本文设计全局信息感知模块GIPM,其详细结构如图2所示。

图2 全局信息感知模块GIPM细节

(1)
2.2 SFRM
卷积神经网络浅层输出特征包含丰富的图像细节特征,而其深层输出特征包含丰富的全局语义信息。虽然常用的FPN网络结构,能逐渐将深层特征与浅层特征相结合,采用由粗至细的方式更新侧输出的显著图,但是这种逐层连接的更新方式会造成全局信息的损失。为了使浅层网络聚焦于有用区域的细节特征学习,提升网络学习效果,本文提出显著特征更新模块SFRM,其结构细节如图3所示。

图3 显著特征更新模块SFRM细节
SFRM首先将深层输出的全局特征直接与浅层特征相融合,接着通过空间位置权重的计算,突出显著特征中重要的空间信息,从而提高侧输出在显著区域上的细节学习能力。其过程可以表示为:
(2)
(3)
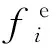
(4)
式中:Avg(·)和Max(·)分别是平均值和最大值计算。
2.3 损失函数
显著物体检测中常用二元交叉熵(Binary Cross Entropy,BCE)作为损失函数。然而,BCE强调的是像素之间的差异,忽略了全局结构信息间的不同,因此,本文模型引入IoU计算预测显著图和真值图之间的图像级差异。整个网络的损失函数可表示为:
(5)

3 实验结果与分析
本模型基于PyTorch实现,训练和测试是在具有一块NVIDIA GTX TITAN GPU的台式计算机上进行。使用具有10 553幅图像的DUTS-TR数据集训练,通过随机水平翻转进行数据增强。使用Adam作为优化算子,学习率设置为5E-3,权重衰减为5E-4,批大小为8,一共训练60期。本文模型为端到端模型,不需要任何的预处理以及其他操作。
3.1 基准数据集及评价指标
在ECSSD、DUT-OMRON、PASCAL-S和DUTS-TE基本数据集上进行了实验以验证本文模型的有效性。这些数据集均具有像素级标签。ECSSD包含1 000幅复杂图像。DUT-OMRON包括5 168幅背景相对复杂的图像。PASCAL-S包含850幅从PASCAL-VOC数据集中选择的真实世界图像。DUTS-TE包含5 109幅包含一个或多个具有杂乱背景的显著物体的图像。
本文采用6个普遍认可的评价指标对模型性能进行评估,包括:准确率-召回率(Precision-Recall,PR)曲线、平均F值(avgFβ)、平均绝对误差(Mean Absolute Error,MAE)和S值(Sm)。
PR曲线:在0~255区间内,用固定阈值对显著图计算其准确率-召回率值对,用于形成PR曲线。
F值:F值是准确率和召回率的综合评价指标,计算方法为:
(6)
式中:β是平衡参数;P为准确率;R为召回率。β2通常设置为0.3以提高准确率权重。
MAE:用于衡量真值图和预测显著性图之间的平均像素误差。
(7)
式中:S表示预测显著性图;G表示真值图;H和W分别表示像素的高和宽。
S值:通过结合区域感知结构相似性So和对象感知结构相似性Sr来衡量显著性图质量,计算公式为:
Sm=αSo+(1-α)Sr
(8)
式中:通常设α=0.5。
3.2 实验对比
为了证明本文模型的有效性,将其与12种近三年具有代表性的基于深度学习模型进行了比较,其中包括:CPD[7]、BANet[14]、PoolNet[15]、EGNet[12]、SCRN[19]、F3Net[16]、ITSD[13]、GateNet[18]、MINet[17]、GCPA[20]、DNA[8]和SUCA[9]。为了比较的公平性,使用作者提供的显著性图进行比较。
3.2.1 定性评估
图4是本文模型与具有代表性算法生成的显著图的视觉比较。通过对比可知,本文模型在各种复杂场景(低对比度、目标接触图像边界、多目标、背景杂乱等)中能够一致高亮显著区域,并有效抑制背景声,效果明显优于其他模型。

图4 本文模型与其他模型生成显著图的视觉对比
3.2.2 定量评估
图5至图8分别是本文算法与12种主流算法的PR曲线比较,可以看到,本文方法几乎在4个基准数据集上均优于其他方法。此外,将本文模型与12种主流算法就avgFβ、EMA和Sm得分进行比较,结果如表1和表2所示,其中:加粗表示最佳性能;下划线表示次佳性能;“-”表示作者没有提供该算法的显著图。可知:1) 本文方法的MAE指标在DUT-OMRON数据集上位列第三;2) 本文方法的S值指标在ECSSD数据集上位列第二;3) 除此以外,本文方法的各项指标在各基准数据上均优于主流算法。说明本文模型能处理各种复杂场景,具有优越性。
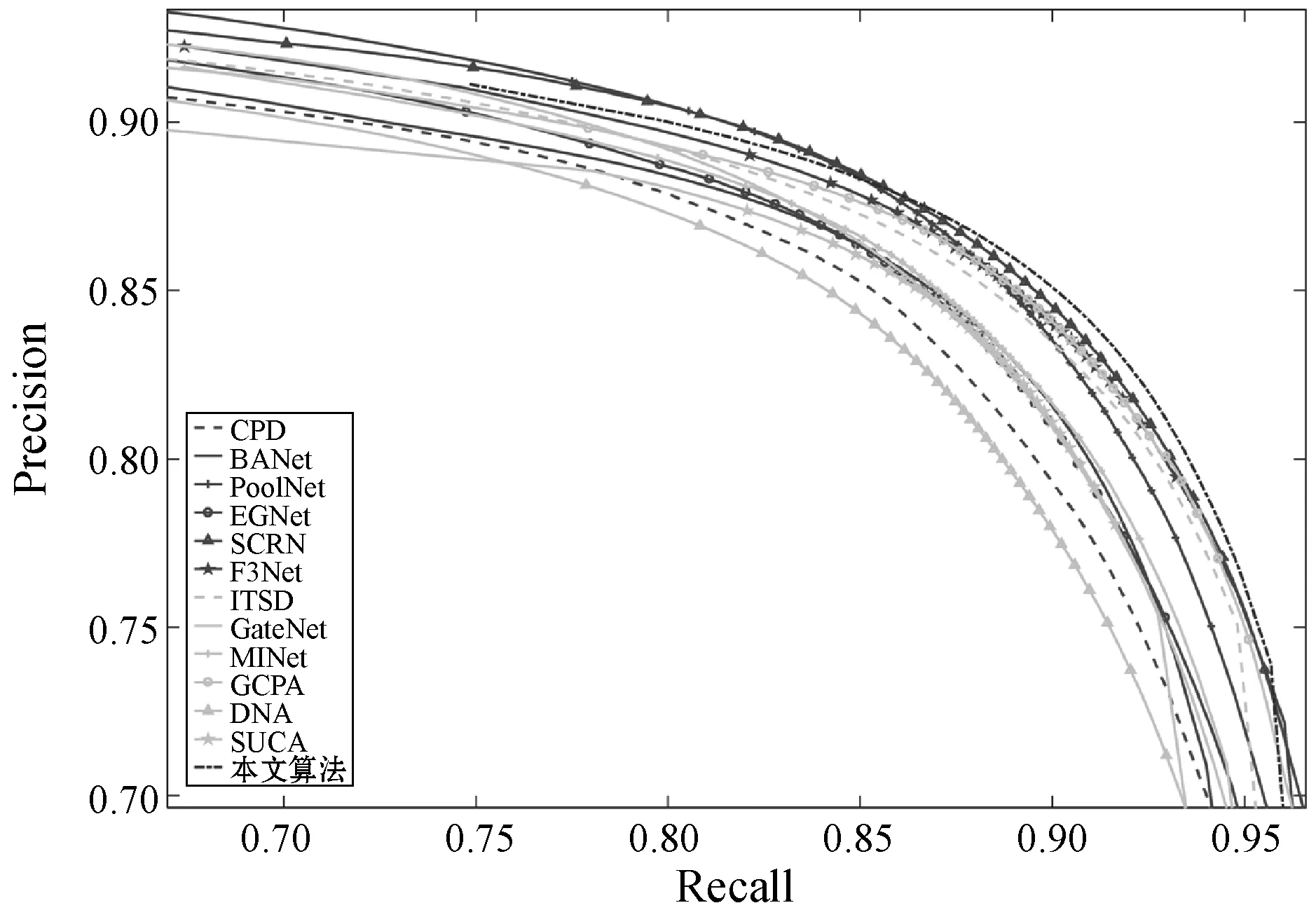
图7 不同方法在PASCAL-S数据集上的PR曲线比较
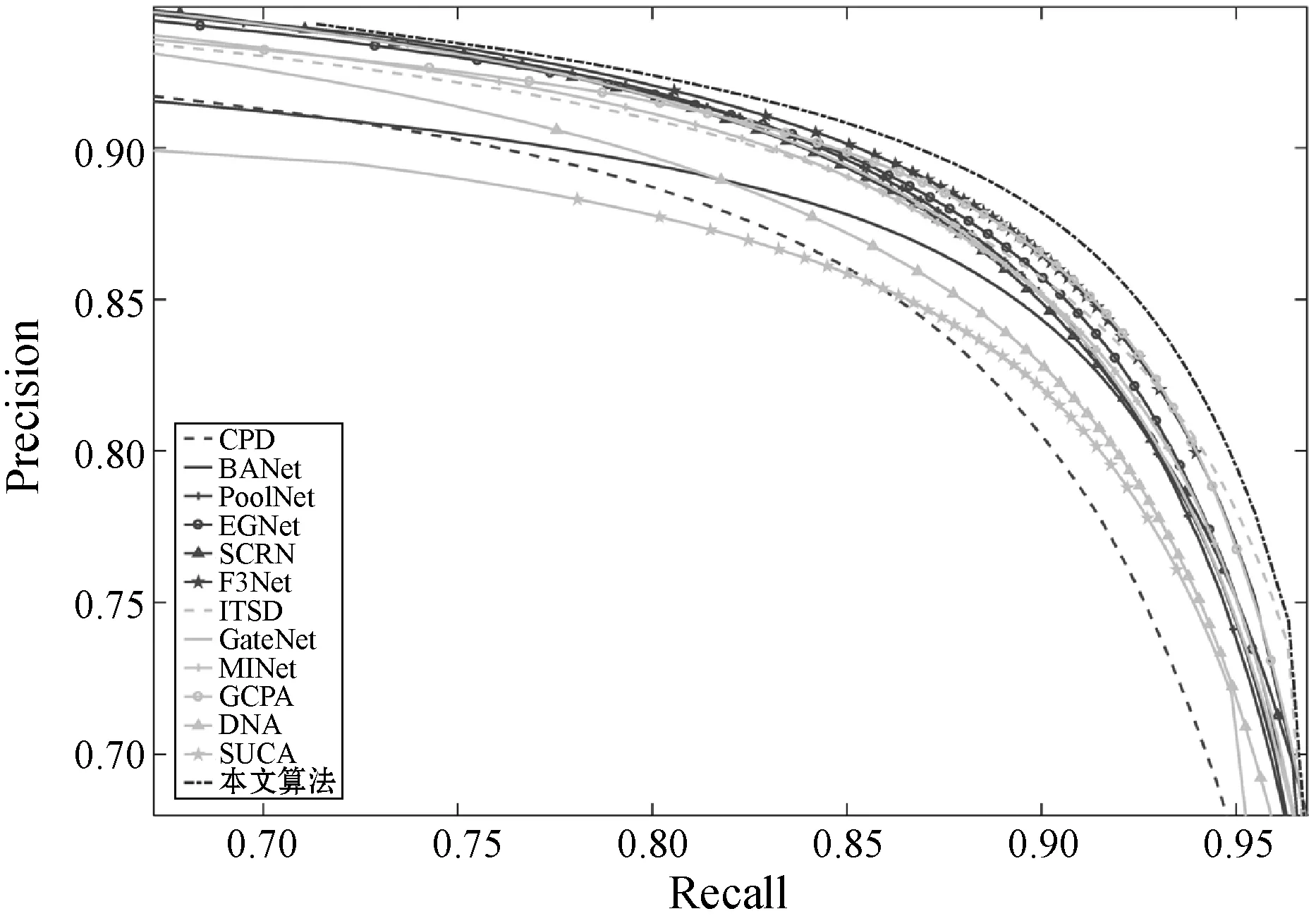
图8 不同方法在DUTS-TE数据集上的PR曲线比较

表1 不同方法在ECSSD和DUT-OMRON数据集上的性能对比结果

表2 不同方法在PASCAL-S和DUTS-TE数据集上的性能对比结果
3.3 消融实验
3.3.1 不同模块性能分析
为了验证不同模块对本文模型的影响,构建了不同的网络,并在DUT-OMRON和DUTS-TE数据集上进行了不同模块的消融实验。主要考虑以下模型:1) w/o_G:将本文模型中的GIPM用一个卷积降维操作取代;2) w/o_S:从本文模型中去掉SFRM模型。
采用Sm、avgFβ和EMA指标定量分析模块性能,如表3所示,可以看出,本文模块GIPM和SFRM均能有效提升模型的检测性能。

表3 不同模块的性能比较
3.3.2 GIPM模块有效性分析
本文设计了GIPM模块提取图像的全局特征,为了验证该模块的有效性,本节进行了全局特征提取模块的消融实验,用流行的全局特征提取模块取代GIPM模块,包括ASPP、PPM、Inception和RBF,实验结果如表4所示。

表4 GIPM与其他全局特征提取模块的性能比较
可以看出采用GIPM的模型性能最佳,说明本文所提的GIPM模型可以较好提取全局语义信息,精确定位显著目标所在区域。
4 结 语
本文提出一种基于特征感知和更新的显著物体检测模型,首先采用GIPM模型提取全局语义特征,充分挖掘全局特征的多尺度信息,同时直接融合全局语义信息和局部细节特征,根据显著物体的大致定位进行细节特征的进一步学习,并对融合后的特征进行空间位置加权操作,以进一步聚焦有用区域的局部细节学习。在ECSSD、DUT-OMRON、PASCAL和DUTS-TE这4个公开的基准数据集上进行充分实验和比较,结果表明本文模型具有良好的检测性能。本文所提网络模型体积较小,可移植性较高。在今后的研究中,将考虑研究引入深度信息的基于RGB-D的显著物体检测模型,研究如何提取和融合RGB和depth特征,丰富图像细节特征,以获得更完整的显著物体。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
北京航空航天大学学报(2021年9期)2021-11-02
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年11期)2019-07-04
金桥(2018年4期)2018-09-26
北京航空航天大学学报(2018年1期)2018-04-20
太空探索(2016年5期)2016-07-12
中国卫生(2014年5期)2014-11-10
时代英语·高三(2014年5期)2014-08-26
