
基于超分辨重建和公共特征子空间的低分辨率人脸识别
2023-05-08 04:44李云红刘杏瑞谢蓉蓉苏雪平张蕾涛拜晓桦
西北大学学报(自然科学版) 2023年2期
李云红,刘杏瑞,谢蓉蓉,苏雪平,张蕾涛,拜晓桦
(西安工程大学 电子信息学院,陕西 西安 710048)
人脸识别技术是机器视觉和模式识别领域的一个研究热点,广泛应用于人机交互、公共安全和信息安全等领域[1]。比较典型的人脸识别技术有基于模板匹配的人脸识别法[2]、基于特征脸的人脸识别法[3]、基于隐马尔可夫模型的人脸识别法[4]和基于神经网络的人脸识别法[5]。因为低分辨率图像具有的人脸特征信息量小、噪声多、可利用识别的像素点和图像特征少等因素,低分辨率人脸识别比高分辨率人脸识别更加困难[6]。
关于低分辨率人脸识别,Freeman等人提出单通道超级分辨率算法,只需要在训练集中对采自本地图像数据的每个斑块的向量进行最近邻搜索[7]。肖哲构建了高、低分辨率对应的人脸数据集,学习低分辨率数据集中相应高低分辨图像的局部像素结构,通过学习到的知识对图像重建获得高分辨率图像[8];Hennings-Yeomans等人将超分辨率重建和人脸识别同时进行[9];马博宇对高分辨率基准集图像进行下采样操作,获取到对应的低分辨率基准集后,再将低分辨率的测试样本集和低分辨率的基准集的人脸图像特征进行对比,得出最后的分类识别结果[10];范文豪通过在保持特征类内距离的情况下,增大类间距离,提高模型的泛化能力[11];Choi等人通过最小化高、低分辨率特征重构产生的误差,在低分辨率特征子空间中进行人脸识别[12];Lei等人提出了基于局部频域的人脸特征提取方法[13]。根据高、低分辨率图像空间特征维度不匹配的特点,低分辨率人脸图像识别大致分为“间接”超分辨(super-resolution,SR)与“直接”的公共特征子空间法两类[14]。研究表明,图像超分辨重建在人脸监控和识别等领域具有重要的应用价值[15]。
针对超分辨方法识别精度不高和公共特征子空间方法无法重建低分辨率的高分辨率图像的问题,本文结合超分辨法与公共子空间法,在InSRNet超分辨网络基础上,提出一种基于生成对抗网络的低分辨率人脸识别网络InGLRNet,通过InGLRNet网络与CLPMs、MDS、Deep-Face和Face-Net经典的4种低分辨率人脸识别方法进行对比实验,验证InGLRNet网络在低分辨率人脸图像识别上的准确性和有效性。
1 InGLRNet网络设计
基于超分辨方法可重建高质量图像的功能和公共子空间方法的高识别性能,设计了一种基于生成对抗的低分辨率人脸识别网络InGLRNet,图1为InGLRNet人脸识别网络总框架。此网络由生成网络(generator)和判别网络(discriminator)构成。生成网络实现低分辨人脸图像的超分辨功能,将低分辨率人脸样本集输入生成网络,可以生成高分辨率的人脸图像样本,并将生成的高分辨率样本集的特征传递给判别网络。然后,通过特征提取网络将高分辨率基准集图像特征传递给判别网络,最终由判别网络通过生成样本来自基准集的概率判断生成样本的真与假。
1.1 生成网络设计
生成网络由超分辨网络InSRNet和特征提取网络(feature-extraction,FECNN)构成。图2是生成网络结构图,超分辨InSRNet网络将输入的低分辨率样本图像生成超分辨率SR(super-resolution)结果,再由特征提取网络FECNN完成特征提取。
针对超分辨率卷积神经网络(super-resolution convolutional neural network,SRCNN)网络层数较少、感受野较小等不足,设计超分辨InSRNet网络,InSRNet在增加卷积层的同时,采用Inception结构加深网络,减少了网络参数,增加残差网络的旁路输出以减轻梯度消失问题。
鉴于超分辨网络中输入的低分辨率图像可利用像素点较少,InSRNet网络在Inception的结构中将卷积核为3×3的卷积层整体替代为3个分别为1×3、3×1和1×1的小卷积操作,减少了网络模型参数量,提高了网络运行速度。此网络中Inception结构选用的是v2版本,相对于v1版本,v2版本拥有更优秀的性能和更少的参数量[16]。在生成网络中,InSRNet网络串联的3个residual block结构相同,完成低分辨率图像的特征映射。
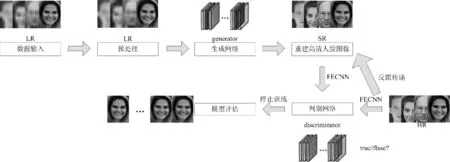
图1 InGLRNet人脸识别网络总框架图
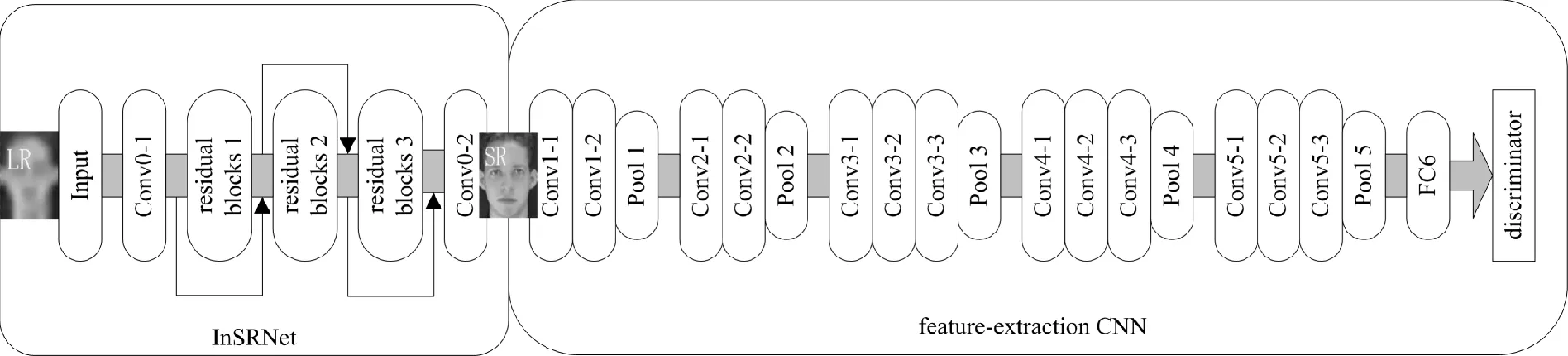
图2 生成网络结构图
为了有效地对生成图像和高分辨率基准图像的特征进行表征,本文以VGG网络结构为模板,设计了特征提取网络FECNN。FECNN是在VGG的基础上,删除了最后2个全连接层,以此来更好地完成特征提取。使用传统的双三次插值方法获得所需的分辨率与尺寸,最后一层的输出是具有4 096个元素的特征向量。
FECNN网络的结构对超分辨网络InSRNet生成的超分辨SR结果进行特征提取,同时对高分辨率基准图像集的特征提取。当它的输入是高分辨率的基准图像集时,作用是将高分辨率图像的特征提取并传输到判别网络中,以便判别网络判断真假。FECNN将高分辨率图像映射到公共空间,生成网络将低分辨率图像映射到该公共空间,构成了判别网络的双输入。
1.2 判别网络设计
在生成网络的训练中,得到了生成网络提取到的超分辨率SR结果的特征,以及特征提取网络FECNN提取到的高分辨率图像HR(high-resolution)的特征。将提取到的特征输入到判别网络中,由判别网络负责将提取到的特征投影到一个公共空间中,通过损失函数匹配特征的同时,判断生成图像的真假。图3是判别网络结构图,判别网络结构的设计回归到原始的卷积网络,由前4层卷积层以及后两层的全连接层和softmax层共7层网络组成。
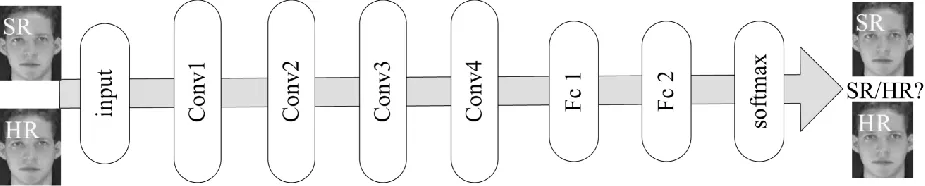
图3 InGLRNet判别网络结构图
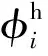
(1)
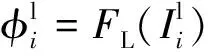
(2)
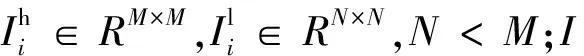
L=lSR+lFECNN+ldisc
(3)
式中:损失函数由超分辨网络InSRNet的损失项lSR、特征提取FECNN的损失项lFECNN和判别网络的损失项ldisc3部分组成。超分辨网络InSRNet的损失项和特征提取FECNN的损失项采用均方误差(MSE)进行计算,损失函数为
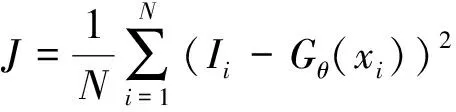
(4)
式中:Gθ为预测值。判别网络的损失函数采用交叉熵损失函数,
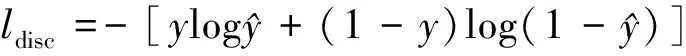
(5)
2 实验过程与结果分析
低分辨人脸识别网络InGLRNet的训练分为3个阶段:第1阶段是特征提取网络FECNN的训练;第2阶段是超分辨网络InSRNet的训练,通过高分辨率图像下采样得到低分辨率人脸图像数据集来训练;第3阶段是合并超分辨网络InSRNet和特征提取网络FECNN,将包含同一个人的低分辨率和高分辨率训练数据集分别输入生成网络。对所有训练图像对重复多次训练过程,微调在前2个训练阶段中获得的权重,以降低所有层的学习率。另外,在将低分辨率图像重建至高分辨率图像的训练过程中,将低分辨率样本图像输入到超分辨网络InSRNet后,从超分辨网络InSRNet的最后一层提取相应的高分辨率人脸图像,以此来测试InSRNet网络超分辨后的图像质量。
2.1 实验过程
实验使用CASIA-Webfaces数据集和FERET数据集共138 984张图像作为构架的低分辨率人脸识别网络InGLRNet的训练集。选用LFW人脸数据集评估构架的低分辨率人脸识别网络InGLRNet的识别性能,LFW人脸数据集中包含13 000张人脸图像。
在训练阶段的初期,先对基于VGG网络构建的FECNN进行训练,之后对超分辨InSRNet网络模块进行预训练。对选定的CASIA-Webfaces数据集和FERET数据集中160×160的人脸图像进行下采样,下采样后的图像大小为32×32,由此可得与训练数据集中高分辨率人脸图像相对应的低分辨率人脸训练数据集。在InSRNet网络的训练过程中,InSRNet网络将输入的低分辨率人脸图像生成高分辨率的人脸图像。待超分辨InSRNet网络训练完成后,就可以从InSRNet网络的最后一层提取相应的高分辨率人脸图像。
图4是不同低分辨率重构方法的过程图, 在对低分辨率图像重构过程中, 将超分辨网络InSRNet与传统的经典人脸超分辨重构方法进行对比,对本文设计的超分辨重构网络生成的图像质量进行评估实验。方法1(bicubic interpolation)是使用双三插值对低分辨率图像进行重构,该方法配置仅使用双三次插值法将低分辨率输入图像映射到尺寸为128×128的图像,不使用任何深度神经学习网络。因此,在此训练阶段,仅需要更新FECNN网络权重即可。方法2是超分辨SRCNN网络,使用传统的CNN网络对低分辨率图像进行进一步的重构。方法3是本文提出的InSRNet网络,将残差网络用于超分辨中,替换SRCNN的CNN模块,期望学习到更多的图像细节,以得到更高质量的重构图像。
2.2 实验结果评估
在完成低分辨率人脸识别之前,首先需要对低分辨率图像进行重建,重建的高分辨率图像的质量影响着人脸识别的结果。因此,本文的实验结果评估将从重建的高分辨率图像质量与低分辨人脸识别率2个方面进行分析。
2.2.1 InSRNet生成图像质量评估
图5是3种不同低分辨率重构方法视觉效果对比图。第1行图像是由原始图像下采样后得到的低分辨率人脸训练集图像,中间3行为bicubic interpolation、SRCNN和InSRNet 3种不同低分辨率方法重构后的图像,最后1行图像是高分辨率的原始图像。为了展示效果,将图像放大到同一尺寸32×32,超分辨倍数为4,以便对比3种不同方法重构后的图像质量。
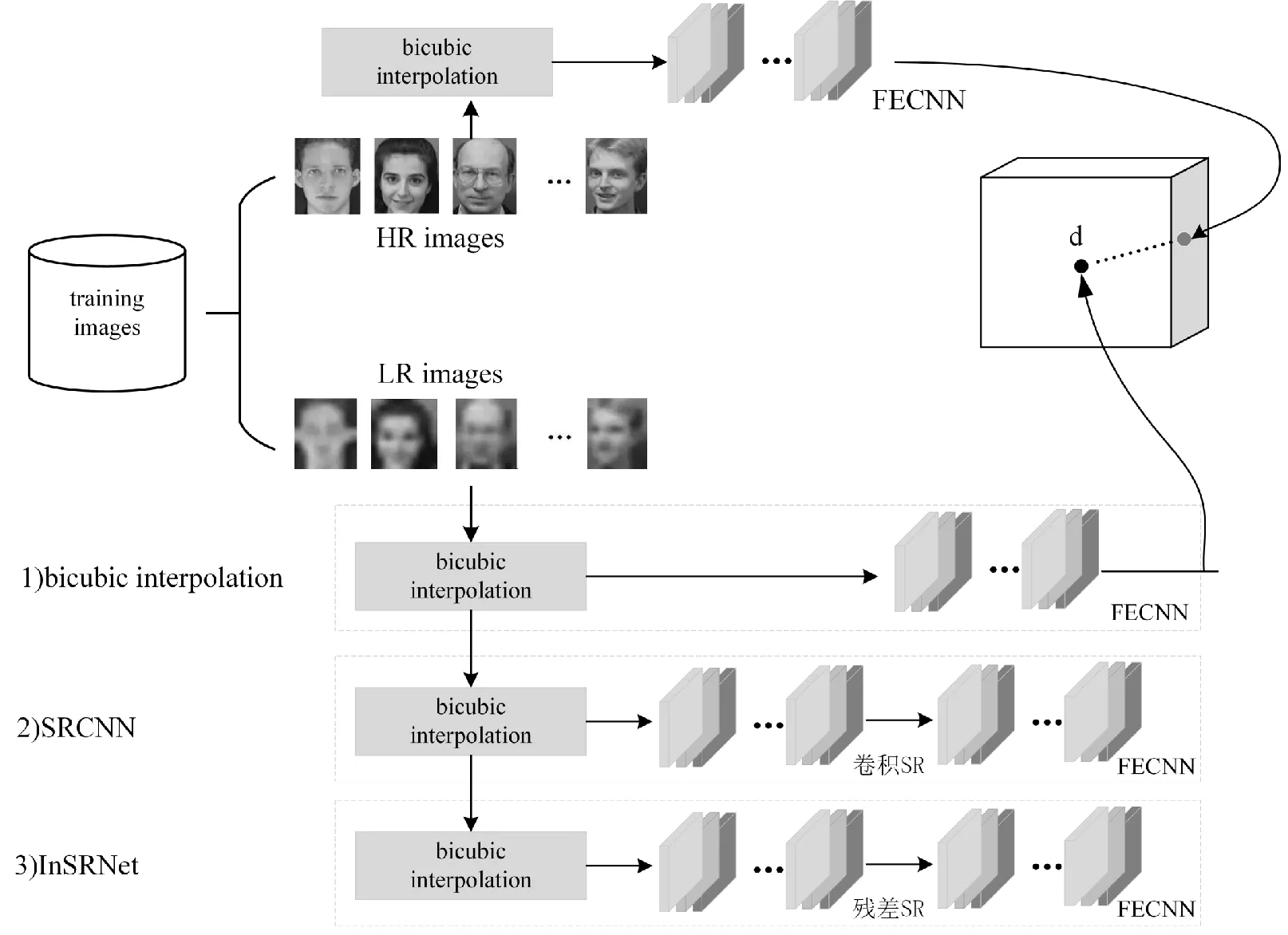
图4 不同低分辨率重构方法的过程图
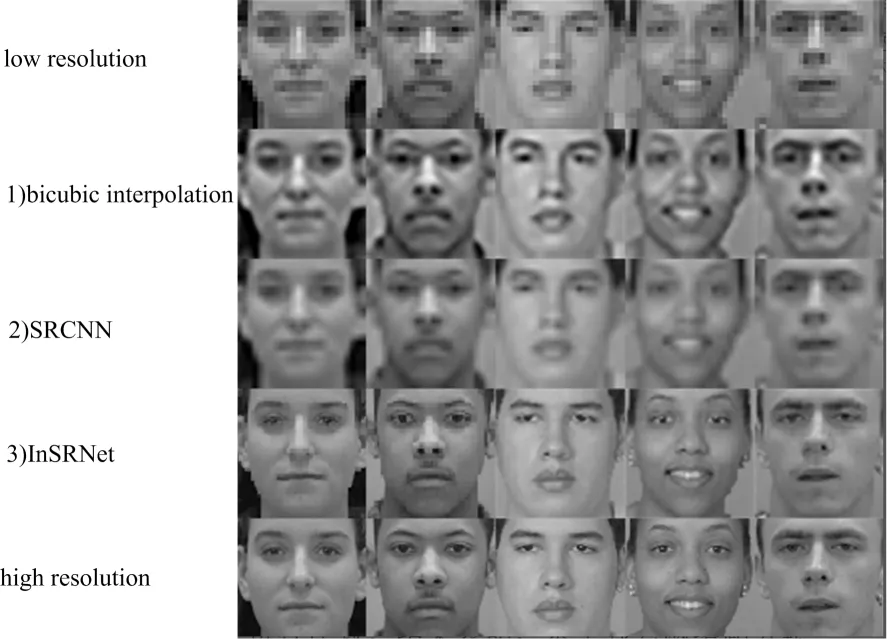
图5 3种不同重构方法在的人脸图像上的视觉效果对比图
在图5中,以重建人脸图像的视觉质量为依据,将超分辨网络InSRNet的方法与不同低分辨率重构方法进行比较,结果表明,使用基于残差网络超分辨方法(见图5中方法3)可以大大提高超分辨InSRNet网络的重构性能,重构后的图像质量明显优于其他重构方法。同时,为了客观地比较这3种方法的视觉增强效果,使用峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性指数(structural similarity,SSIM)进一步度量3种重构方法的优劣。PSNR的作用是评判重构图像的质量,若PSNR值越大,重构图像中的噪声越小,代表重构图像的质量越高。但是,在有些情况下,人类的视觉感知认为PSRN值低的图像并不一定质量差,即人类的视觉感知与PSNR体现的高质量并不统一,针对这个问题,需要引入结构相似度SSIM作为图像评价指标。SSIM是一个0到1之间的数,SSIM越大,两图像间差异越小。本文将参考这2个指标共同对重构后的图像质量进行评估。
表1是3种不同低分辨率重构方法重建后的高分辨率人脸图像的峰值信噪比PSNR和结构相似性指数SSIM的比较结果。 相比于仅使用双三插值和仅使用传统的CNN网络结构法, 超分辨网络InSRNet方法重构的人脸图像不仅具有最佳的视觉效果, 而且重建的人脸图像与高分辨率基准图像之间的差异最小。 超分辨网络InSRNet方法在PSNR和SSIM上的表现也优于其他2种方法。 表明基于Inception和残差网络的超分辨网络InSRNet能够生成高质量的高分辨率人脸图像, 以供判别网络进行判别。

表1 不同重建方法的PSNR和SSIM
表2为3种不同重建方法在不同低分辨率的Rank-1识别精度,Rank-1识别精度为与目标人脸最相似的人脸中成功找到正确人脸的概率。

表2 不同重建方法在不同低分辨率上的Rank-1识别精度
从表2可以看出,在所有低分辨率重构方法中,超分辨网络InSRNet方法在不同的分辨率情况下都取得了最高的识别精度。结果说明,基于Inception和残差网络的超分辨网络InSRNet在主要训练阶段可以大大提高低分辨人脸识别网络InGLRNet的识别性能。特别当人脸图像的分辨率非常低时,该方法的识别性能明显高于其他低分辨率重构的方法。总之,基于Inception和残差的超分辨InSRNet网络的结构能够生成视觉质量更高的重构图像,并且获得更好的识别性能。
2.2.2 InGLRNet识别率评估
在此次实验中,对训练完成的低分辨率人脸网络在LFW数据集上进行了评估。为了评估构建的InGLRNet网络对不同低分辨率的图像的识别性能,考虑了6×6、12×12、24×24和32×32这4种不同的分辨率。 首先, 分别以不同图像分辨率对超分辨InSRNet网络进行训练; 然后, 将超分辨InSRNet网络连接到FECNN网络组成完整的InGLRNet低分辨率人脸识别网络; 最后, 在每种分辨率条件下, 重新训练构建的低分辨率人脸识别网络。 为了进一步验证论文构建的InGLRNet低分辨率识别网络的有效性,将构建的InGLRNet网络与CLPMs、MDS、Deep-Face和Face-Net这4种经典的低分辨人脸识别方法在不同的低分辨率下进行了比较。表3是在LFW数据集上不同方法在不同低分辨率之间的Rank-1识别精度比较结果。
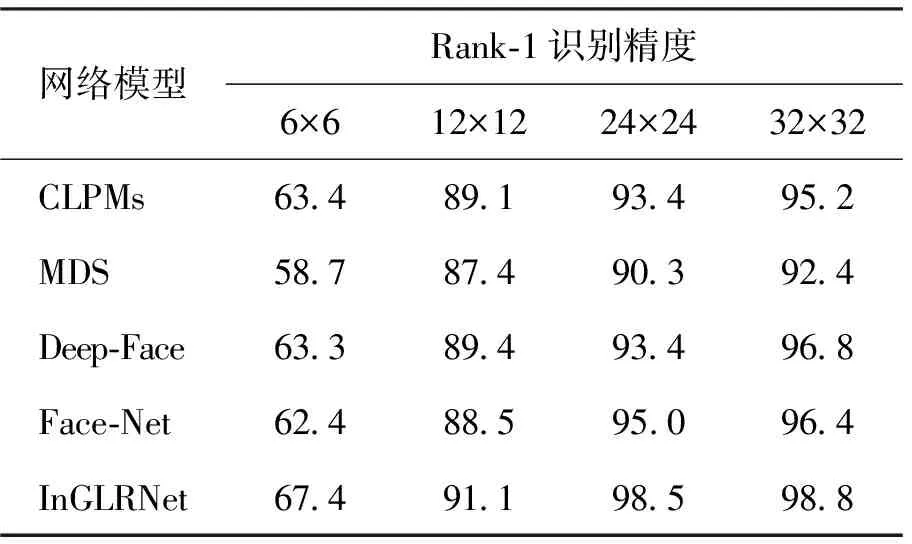
表3 不同人脸识别方法在不同低分辨率上的Rank-1识别精度
CLPMs是基于传统的特征脸与小波变换法,而MDS是基于公共特征子空间的多维度尺寸分析法,这2种方法都不需要下采样和超分辨重构过程。Deep-Face与Face-Net是基于深度卷积网络的低分辨率人脸识别法。从表3可以看出,构建的InGLRNet人脸识别方法在4个分辨率条件下都优于其他方法。在24×24的低分辨率上比性能优异的Face-Net还要高出3.7%。并且,在6×6这样的超低分辨率上,构建的InGLRNet网络也比其他方法有明显优势,比同分辨率中识别性能最优异的CLPMs的识别精度高出6.3%。本文提出的InGLRNet网络在识别性能方面优于其他4种经典的低分辨率人脸识别方法。当输入的人脸图像分辨率较低时,其性能也有明显的提升,对于超低分辨率的人脸图像的识别性能有较好的改善。
3 结语
本文针对传统低分辨率人脸识别准确率较低的问题,搭建了一种基于超分辨和公共特征子空间的低分辨率人脸识别网络InGLRNet。利用超分辨网络和特征提取网络构成生成网络,判别网络采用传统的卷积神经网络结构,以提取并保留足够多而且有效的图像特征,减轻梯度消失问题并且加强图像特征的传播。通过与CLPMs、MDS、Deep-Face和Face-Net这4种经典的低分辨人脸识别方法进行对比实验可知,本文构建的超分辨网络可以实现高质量的高分辨率图像的生成。并且整个InGLRNet网络在识别性能上有显著的提升,在不同的低分辨率条件下都优于其他方法。
猜你喜欢
红外技术(2022年11期)2022-11-25
电子产品世界(2022年9期)2022-05-30
作文中学版(2022年1期)2022-04-14
雷达学报(2020年3期)2020-07-13
学生天地(2020年31期)2020-06-01
艺术科技(2018年2期)2018-07-23
太空探索(2015年8期)2015-07-18
计算机工程(2015年8期)2015-07-03
浙江大学学报(工学版)(2015年1期)2015-03-01
航天返回与遥感(2014年4期)2014-07-31
