
继电保护设备剩余寿命预测的智能算法研究
2023-05-07 13:43:28马振国黄煜铭张柯琪曹丹怡
兰州理工大学学报 2023年2期
谢 楠, 马振国, 唐 兵, 黄煜铭, 张柯琪, 曹丹怡
(国网江苏省电力有限公司常州供电分公司, 江苏 常州 213003)
有效的剩余寿命预测有助于提高系统的稳定性,极大程度地减少事故的发生,并为预防性维护[1]提供技术支持.随着科技的发展,基于人工智能的剩余寿命预测技术[2]更受重视.对于电力系统,复杂或大型的设备往往安装传感器[3]或其他监测装置,利用人工智能技术对反馈数据进行挖掘,获得大量有价值的信息,比如设备剩余寿命等.针对这方面国内外学者已做了大量的研究工作.
Chinomona等[4]在充分考虑充放电时的电压、电流和温度相关特性基础上,利用长短期记忆模型预测了电池的剩余寿命问题.程成[5]将电网中由传感器获得的数据分为低维监测数据和多维监测数据,对低维数据利用时间卷积网络预测轴承为代表的设备剩余寿命,对高维数据利用卷积长短时记忆网络预测了发动机引擎的剩余寿命.李天梅等[6]对若干剩余寿命预测中出现的局限性和共性难题,提出了一种基于数模联动的大数据下设备剩余寿命的预测方法.李志刚等[7]采用小波变换将继电器性能参数的时序值分解为平稳项和随机项,对平稳项采用AR模型进行预测,随机项通过径向基神经网络模型进行预测,最后通过小波包重构得到继电器的剩余寿命.
综合上述成果,对电气设备的剩余寿命研究都依赖于设备的监测装置和监测数据.其优势在于大量的数据样本为智能算法提供了强有力的支撑,使得训练模型各项参数最优,测试结果更加准确.其缺点在于,针对小样本数据或无监测装置设备的剩余寿命研究,算法的可移植性偏弱,甚至是失效.目前对于无监测数据设备的寿命预测方面的研究非常少见.电力系统是一个完整且庞大的系统,有很多继电保护设备,如DC220V电源等,都无法安装监测装置,其中任何一个小环节的故障都有可能导致整个系统的失稳.所以对这类设备的剩余寿命的研究,其意义不仅在于改善检修策略,提高检修效率,更有利于减少故障率,保障电力系统的安全稳定运行.
本文针对JC市电力公司继电保护设备,通过智能技术研究一类具有共同特征的设备剩余寿命预测问题.
1 供电公司中继电保护设备的剩余寿命问题
JC市作为南部一个重要的经济城市,该市供电公司管辖近200个变电站.目前的检修方式主要是依赖运维检修人员手工记录的文本信息和专家经验.这种检修方式无法适应变电站电气设备规模的快速增长,同时由于检修效率低,导致了不同程度的过检与失检,以致消缺时间过长与资源的浪费.
继电保护设备有几个主要特征:(1) 种类多,体积小;(2) 在运维消缺时以更换为主;(3) 精密化程度高;(4) 使用寿命受温度、湿度、极端天气、生产厂家、设计寿命、操作班组等因素的影响.
JC市供电公司继电保护专业备品库存管理系统中,存放了继电保护设备的消缺日志,变量有元器件名称、厂家、设计寿命、安装日期、损坏日期、温度、湿度、安装地点、间隔、运维班等10个字段(如表1所列).其中,设计寿命是数值型变量,安装日期和损坏日期是时间型变量,其他是文本型变量.

表1 JC市供电公司部分消缺日志
根据继电保护设备的特性及现有的消缺日志,本文分别利用支持向量回归机(support vector regression,SVR)、回归树(regression tree,RT)和随机森林(random forest,RF)三种模型对JC市供电公司继电保护设备的剩余寿命(remaining useful life,RUL)进行研究.
2 求解继电保护设备的剩余寿命的算法
为了在三种方法中能够使用统一的数据和提高计算效率,根据相关联度较高的安装日期、损坏日期、当前日期和设计寿命,重新定义设计生命历程和实际生命历程.
2.1 数据预处理
由于数据中包含异常数据,同时涉及了三种不同的数据格式,因此,先对数据进行预处理.下面是关于数据预处理的算法1.
算法1数据预处理算法
输入:安装地点、间隔、厂家、设计寿命、安装日期、损坏日期、温度、湿度、运维班组.
输出:安装地点、间隔、厂家、设计生命历程、温度、湿度、运维班组和实际生命历程,其中设计生命历程和实际生命历程是数值,其他是标签形式.
Step1,清洗数据.对第j条记录的设计寿命zj4,利用Z-score方法筛选出奇异值,删除包含奇异值的消缺记录,Z-score方法的公式如下:
其中:μ与σ是设计寿命zj4的均值与方差,通常阈值zθ∈(1,3),保留满足上式的数据得到数据集矩阵x.
Step2,字段标签化.将文本数据安装地点、间隔、厂家、温度、湿度、运维班组标签化处理.
Step3,计算数据集矩阵x.根据安装日期、损坏日期、当前日期和设计寿命,定义设计生命历程和实际生命历程.设某一类元件的消缺记录中第i个元件的安装日期为Date_install[i], 损坏日期为Date_broken[i],设计寿命为Planed_life[i],设已损坏且经过清洗的元件Ei数量为n,I为间隔天数:
forifrom 1 ton
j=1
now=Date_install[i]+I
while now #设计生命历程 #实际生命历程 xr=(安装地点,间隔,厂家,D[r],温度,湿度,运维班组) j=j+1 now=now+I Step4,数据矩阵[x,y]按照4∶1的比例分配训练数据[xtrain,ytrain]和测试数据[xtest,ytest]. 在机器学习[8]中,支持向量回归机(SVR)是一种非参数回归模型,回归超平面[9]是通过优化与附近支持向量的距离来确定的.首先来考虑得到寿命预测的回归超平面. 对于给定的训练集D={(x1,y1),(x2,y2),…,(xm,ym)},yi∈(0,1],由于无法确定训练集在原始空间中是否具有线性可分性,因此,设划分超平面为 f(x)=wTφ(x)+b (1) 式中:x=(x1,x2,…,xp);φ(x)表示将x映射后的特征向量;w=(w1,w2,…,wp)T为权重向量;b为偏差. 求解回归超平面f(x)问题可以转化为凸优化问题,结合优化问题的标准形式、拉格朗日函数及其KKT条件,可以得到式(1)的最优解为 f(x)=w*Tφ(x)+b* (2) 式(2)即为用来预测剩余寿命的回归超平面. 下面根据SVR给出剩余寿命预测的算法2. 算法2剩余寿命预测算法 输入:调用算法1得到训练数据. 输出:第k个元件的剩余寿命SVR[k]. Step1,调用算法1获得训练数据[xtrain,ytrain]和测试数据[xtest,ytest]. Step2,通过训练数据[xtrain,ytrain]得到预测模型,将某一类元件处理过的数据[xtrain,ytrain]输入到式(2)中,获得回归超平面表达式,即 f(x)=w*Tφ(x)+b* (3) Step3,有效性检验.令Ttest为测试数据的行数,对给定的Δ>0, 若 转到Step4,否则转到式(2)的求解中进行调整惩罚系数,直到满足为止. Step4,计算剩余寿命. Step4.1,将在用设备的第k条数据xk=(安装地点,间隔,厂家,D[k],温度,湿度,运维班组)代入式(3),输出f(xk),即为该元件实际寿命的生命历程的预测值. Step4.2,预测在用的第k个备品的损坏日期: Date_predicted_broken[k]=Date_install(k)+ Step4.3,输出在用第k个备品的寿命剩下的天数SVR[k]: SVR[k]=Date_predicted_broken[k]-Date_today 回归树(RT)[10]是利用决策树进行变量预测的一种算法,由于其易理解、易构建、速度快等特点,被广泛地应用于数据挖掘中.该算法的基本思路是输入训练数据集D={(x1,y1),(x2,y2),…,(xm,ym)},yi∈(0,1],输出回归树f(x).在训练数据集所在的输入空间中,递归地将每个区域划分为两个子区域,并决定每个子区域上的输出值,构建二叉决策树的算法. 算法3构建二叉决策树 输入:调用算法1得到训练数据. 输出:第k个元件的剩余寿命RT[k]. Step1,令zi=1-yi,求解 (4) Step2,用选定的(j,s)划分区域并决定相应的输出值: R1(j,s)={x|x(j)≤s} R2(j,s)={x|x(j)>s} Step3,继续对两个子区域执行Step1和Step2,直到满足每一个分支都不能切分为止. Step4,利用得到的回归树的M个叶子顶点对应的M个子区域R1,R2,…,RM,计算回归树表达式: (5) 这里区域Rk上的ck是Rk中所有输入实例xi对应的输出yi的均值,即 Step5,输出第k个在用设备剩余寿命的天数: RT[k]=f(xk)×Planed_life[k] 其中:Planed_life[k]为第k个元件的设计寿命(天). 随机森林(RF)[8]是利用多棵回归树对样本进行训练和预测的集成算法.它有很多优点,如生成高维度数据,不容易过拟合,训练速度比较快. 算法4随机森林预测算法 输入:调用算法1得到训练数据. 输出:第j个元件的剩余寿命RF[j]. Step1,随机抽样.利用Bagging思想[8],对训练数据集有放回地随机抽取N个样本形成样本子集,每个子集中的样本数约为全部训练集中的2/3. Step2,随机选取特征.假设所抽取的样本子集有K个特征,随机抽取k(k≤K)个特征作为特征子空间.在样本子集和特征子空间上,调用算法3,生成一棵回归树Tt,然后利用算法3的式(5)计算回归树表达式fTt(xj),并得到用回归树Tt预测第j个元件的剩余寿命RF_T[t,j]=fTt(xj)×Planed_life[j]. Step3,重复Step2,对给定的数值T,直到生成T棵回归树为止,这T棵回归树构成随机森林.其中用随机森林中第t棵回归树Tt预测第j个元件的剩余寿命RF_T[t,j]. Step4,输出用随机森林预测第j个元件的剩余寿命: 根据JC市供电公司的数据,利用支持向量回归、回归树和随机森林模型分别对常用常见的继电保护设备DC220V电源、CPU和显示屏进行预测,预测结果如图1所示. 首先,根据图1分析三种预测算法对三种设备的预测效果.利用回归树模型预测的三种设备的剩余寿命在真实值附近大幅度波动,尤其是有重要价值的后半段预测值,误差较大.其主要原因在于决策树算法对连续性字段或者对时间序列数据的预测效果较差,导致三种设备的预测效果较差. 图1 三种方法分别对DC220V电源、CPU和显示屏的剩余寿命预测结果 支持向量回归模型预测曲线类似一条直线,其倾斜度与真实值的斜率有一定的偏差,即在真实值和预测值交点的附近,表现较好,其他时间段内表现较差,尤其是这种交点位于时间轴的前半部分时,预测效果最差.因此,可以认为该方法在整体上的表现不能令人满意.主要原因在于继电保护设备的数据集中,只有生命历程这一个时间变量,其他变量与时 间的关联度较差.因此,很难进一步调整倾斜度,这也是所有继电保护类设备数据的局限性所在. 从随机森林算法的预测结果看,尽管在有些元件的剩余寿命预测的初期表现稍弱,如DC220V电源,但是在三个元件的生命周期的后半段,表现很好,这也有利于体现剩余寿命预测的价值.随机森林算法的预测结果好的主要原因在于:(1) 随机森林模型中,特征的随机选取增加了小样本的识别率,而且预测结果是很多回归树模型预测结果的平均值,使得总体的预测结果更加准确;(2) 该算法充分利用了继电保护设备数据特征及不同特征之间的相关性,从而使得随机森林模型利用有限的数据充分发挥模型的挖掘能力. 最后,从误差角度进行模型的有效性分析,讨论三种方法下对应的均方根差和平均绝对误差,其计算公式如下: 其中:xp和xa分别表示预测值和真实值.如果某种算法的RMSE和MAE小,则说明该算法更有效.三种预测方法的RMSE与MAE如表2所列. 表2 三种预测方法的误差比较 从表2可知,随机森林算法的RMSE和MAE都是最小的,进一步说明了随机森林模型预测效果的有效性. 综合上述分析,在目前的数据特征下,随机森林模型对于继电保护设备剩余寿命预测的效果最佳. 尽管继电保护设备的监测数据少,但是针对类似于表1的数据仍然可以对设备进行较高精度的剩余寿命预测,三种方法针对三种不同设备的预测效果,整体表现较好,尤其基于随机森林法的预测精度甚佳.本文虽然只是对三个元器件进行了预测, 但是这种方法可以推广至类似继电保护设备中. 对继电保护设备的剩余寿命预测,其实际意义体现在如下几点: 1) 根据剩余寿命的预测结果,可以在设备的运维中,做到提前干预性检修,提高检修效率,减小故障率; 2) 根据在用设备的剩余寿命预测值,可以为继电保护变设备备品的库存提供预测策略; 3) 剩余寿命的预测,可以为继电保护设备的故障诊断和状态评估提供决策依据; 4) 丰富继电保护设备的全生命周期管理. 致谢:本文得到国网江苏省电力有限公司科技项目(J2021102)的资助,在此表示感谢.2.2 基于SVR的预测算法
2.3 基于RT模型的预测算法
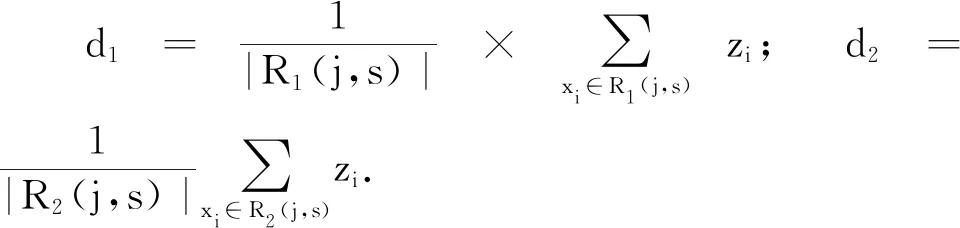
2.4 基于RF的预测算法
3 案例分析
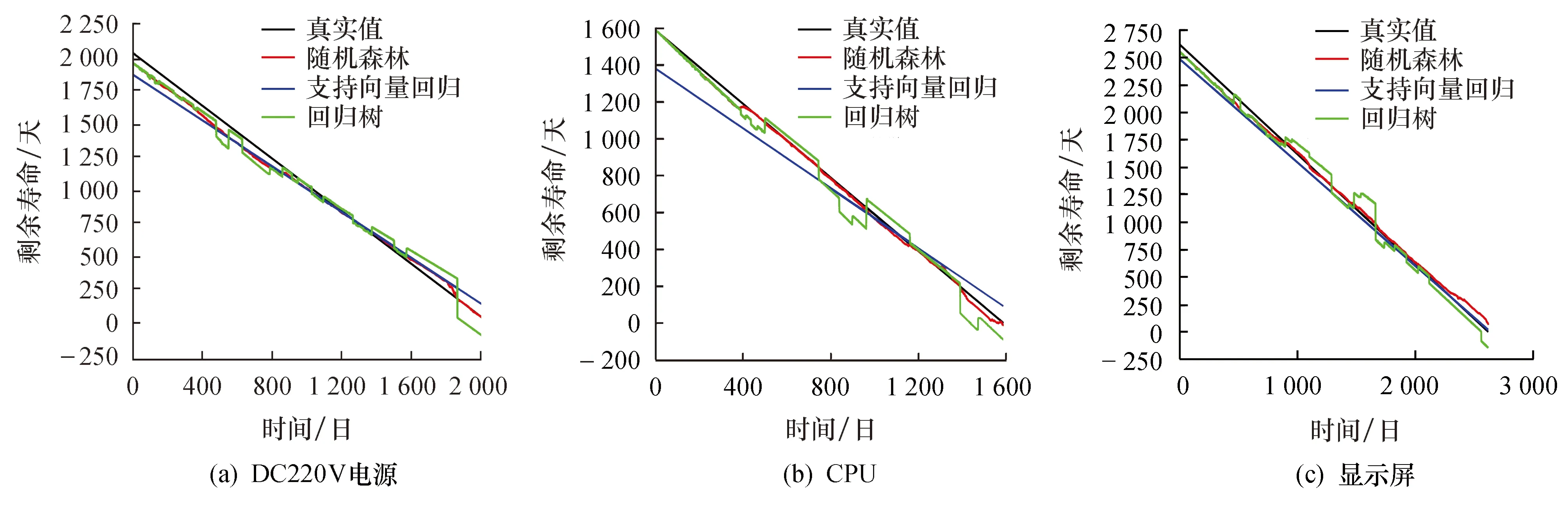
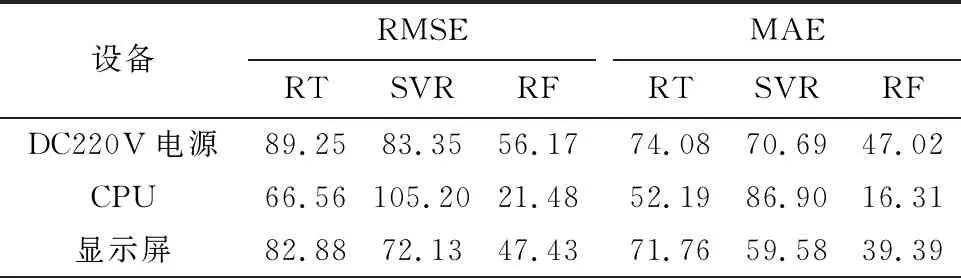
4 结论
猜你喜欢
党员文摘(2022年14期)2022-08-06 07:19:22
党员文摘(2022年7期)2022-04-28 08:57:58
党员文摘(2022年1期)2022-02-14 06:09:00
党员文摘(2022年3期)2022-02-12 10:38:14
经济技术协作信息(2018年32期)2018-11-30 01:43:20
电子制作(2016年19期)2016-08-24 07:49:56
现代工业经济和信息化(2016年2期)2016-05-17 05:34:16
电子制作(2016年23期)2016-05-17 03:54:05
电子工业专用设备(2015年4期)2015-05-26 09:10:40
汽车维修与保养(2015年8期)2015-04-17 03:33:01
