
基于Scrapy的岗位推荐系统的设计与实现
2023-05-06 17:59:49曹培林永意
无线互联科技 2023年24期
曹培 林永意
摘要:大数据和人工智能的发展,使得网络上的信息呈爆炸式增长。如何从海量数据中迅速精准地挖掘出有效信息已经成为一个研究热点。文章以爬虫框架Scarpy为基础,结合Redis、布隆过滤器(Bloom Filter,BF)和PostgreSQL数据库,设计并实现了一种基于Scrapy的岗位推荐系统。该系统可以从指定的URL获取信息,存入数据库,并以网页或者邮件的形式呈现给用户。
关键词:岗位推荐系统;布隆过滤器;Scarpy;PostgreSQL
中图分类号:TP311 文献标志码:A
0 引言
近年来,科学技术正发生着日新月异的变化,互联网已经成为人们获取信息的主要渠道[1]。在大数据时代,搜索引擎作为一种常见的互联网应用,已经成为人类与互联网海量信息的连接桥梁。网络爬虫(Web Spider)是一种可以自动提取网页数据的程序[2],可以帮助搜索引擎从互联网上下载页面信息,是搜索引擎的一个重要组成部分。
1 相关技术综述
1.1 Scrapy爬虫框架
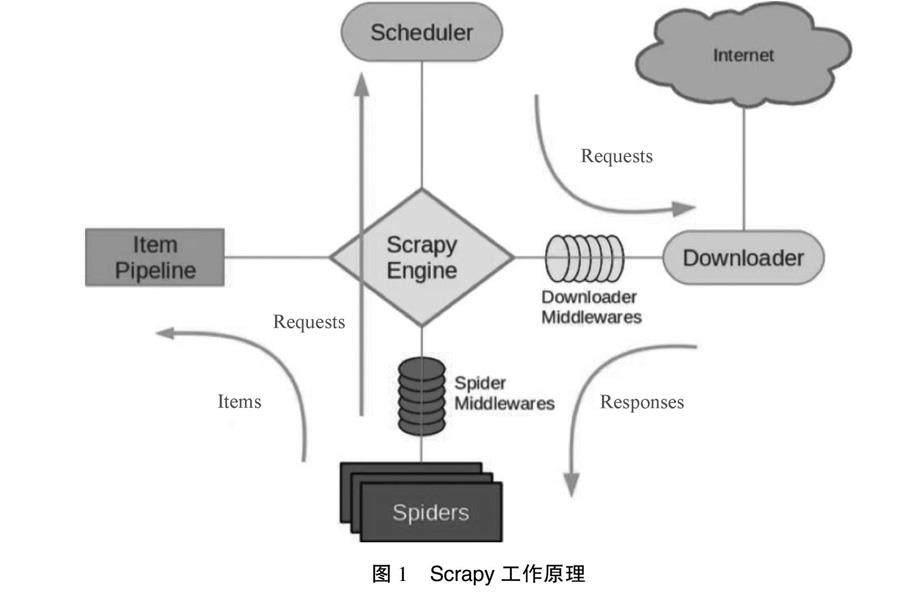
Scrapy是一个基于Python的可爬取网站数据,并提取结构化数据的应用框架,其工作原理如图1所示。
各组件的职能如下[3-4]。
Scrapy Engine(引擎):负责Scheduler、ItemPileline、Spiders以及Downloader 4个组件之间的通信和数据传输,是整个爬虫的中枢组件。
Scheduler(调度器):接收来自Scrapy Engine的请求,并按特定的规则整理排序入队,当Scrapy Engine有需求时,再还给Scrapy Engine。
Downloader(下載器):下载Scrapy Engine发出的所有请求,并将收集到的响应回传给Scrapy Engine,Scrapy Engine后续交给Spiders来处理。
Spiders(爬虫):处理Scrapy Engine传来的响应,分析提取Item字段所需要的数据,同时将需要跟进的统一资源定位器(Uniform Resource Locator,URL)交给Scrapy Engine。
Item Pipeline(管道):处理被Spider提取出来的Item,并作分析、过滤、存储等后续处理。数据被存入Item后,将被送到Pipeline,经过处理后存入数据库或者本地文件。
Downloader Middlewares(下载器中间件):可看作一个自定义的扩展下载组件,处理下载器传递给Scrapy Engine的响应。
Spider Middlewares(Spider中间件):一个自定义的扩展组件,处理Scrapy Engine和Spider之间的通信。
1.2 Bloom Filter
Bloom Filter[5]是布隆在1970年提出的。Bloom Filter是一种专门解决去重问题的高级数据结构,其实质是一系列随机映射函数和一个二进制向量。Bloom Filter可以用来检索一个元素在一个集合中是否存在。较之其他数据结构,Bloom Filter在空间和时间方面都有着巨大的优势。Bloom Filter有2个基本的指令bf.exists和bf.add。bf.exists用于判断元素是否存在于功率器中,bf.add用于添加元素。
网络爬虫[7]是Bloom Filter的一个常用场景,可以用来去除已经爬取过的URL。在项目应用中,将已经爬取过的URL放入Bloom Filter,每当访问新的URL时,先查询Bloom Filter,如果存在,则说明此网页已经被访问过了,无需再进行下一步操作。如果不存在,则说明该网页没有被访问过,还需要进行数据爬取。RedisBloom作为Redis的一个模块,不仅提供了常见的缓存功能,而且还对布隆过滤器的高效性能和占用空间作了优化。
2 系统设计与实现
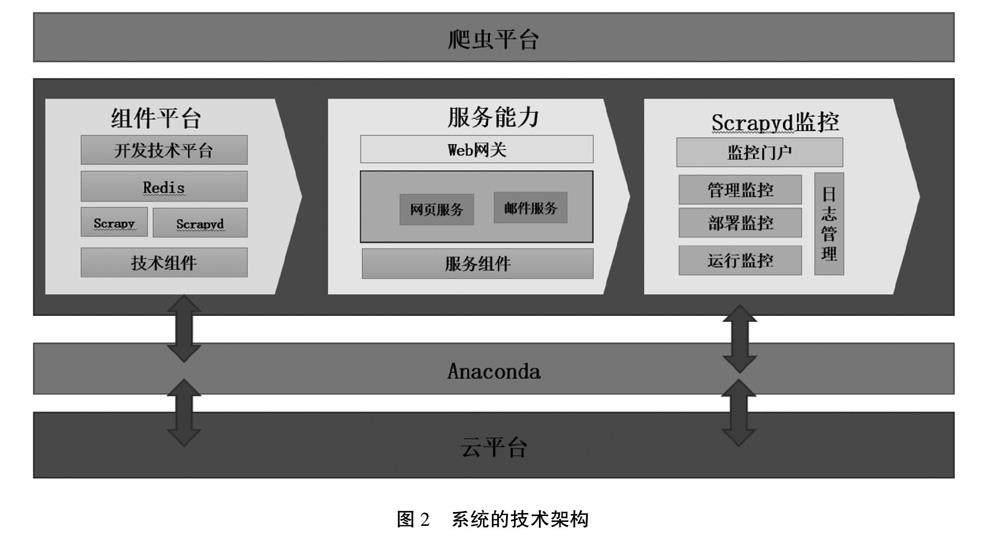
2.1 系统技术架构
系统的技术架构如图2所示。系统部署在某公有云平台,公有云可以降低部署、管理、维护成本,缩短开发周期。另外,公有云的功能更全面,性能更稳定。Python语言配置方便简单、字符处理灵活便捷且有丰富的网络抓取模块,因此,本系统使用Python语言进行开发。版本使用Python Anaconda 发行版,Anaconda提供了一个轻松安装、管理、更新Python包的管理系统和大量常用的科学计算库,另外,Anaconda还提供了一个用于浏览、安装和管理各种包、环境以及工具的可视化界面。爬虫开发技术组件使用Scrapy、Scrapyd、Redis。其中,Scrapy为爬虫框架,Scrapyd主要负责爬虫的管理、部署、运行(包括日志服务)等工作,Redis提供布隆过滤器组件。服务组件提供网页发布服务,邮件订阅服务,Web网关对外提供访问服务。
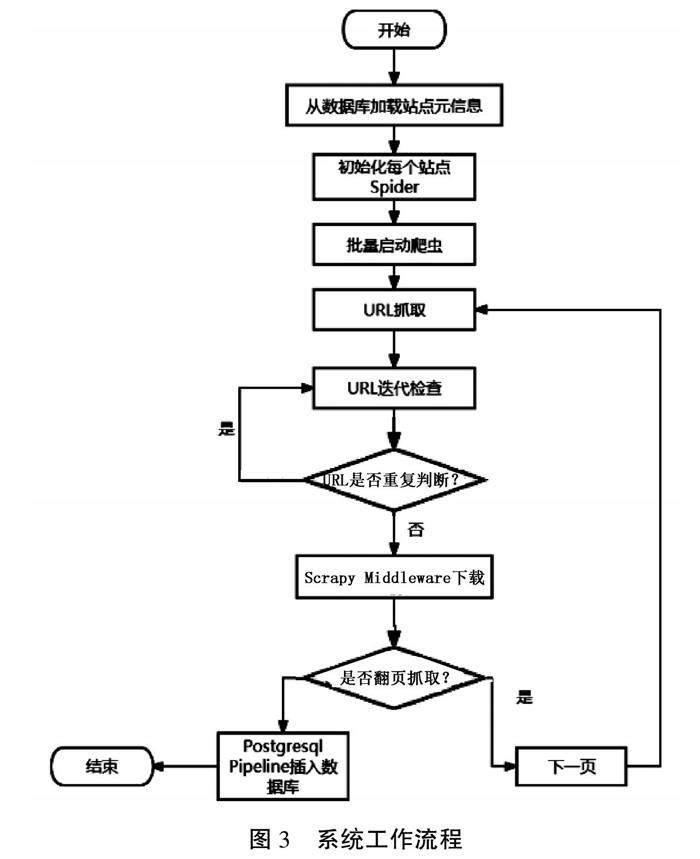
2.2 系统工作流程
基于Scrapy的岗位推荐系统的工作流程如图3所示。系统启动时,从PostgreSQL数据库加载站点元信息。Scrapy通过站点元信息初始化每个站点的Spider,初始化完成后批量启动爬虫,爬取URL以及其他相关信息(如:标题,时间,作者等)。系统通过Redis中的Bloom Filter检查当前URL是否已经被访问过。如果该URL已经被访问过,则结束本条信息抓取操作,进入下一轮循环。如果该URL尚未被访问,则通过Spider Middlewares下载本条URL以及相关信息。最后通过Scrapy Pipeline将数据存入PostgreSQL数据库。
2.3 系统运行结果分析
爬虫程序被设置成定时任务,调度器每天调度执行2次,执行完毕后会以邮件的形式发送给订阅者,主题为“岗位信息发布/岗位数[*]”。用户点击邮 件即可查阅当天发布的岗位信息。
網页和邮件时间同步,每天早晚发布一次。如果没有邮件订阅,用户也可以自行在网页上查询,网页按时间展示当天更新的信息。本系统目前运行状况稳定,所有流程均能自动完成,无需人工干预。
3 结语
随着大数据和人工智能的发展,网络上的信息呈爆炸式增长。纷繁复杂的信息正充斥着人们的日常生活。快速准确地获取有效信息,可以大大提高工作效率和生活质量。利用网络爬虫,用户可以按需获取互联网上的有效信息,避免海量信息的冲击。本文介绍了爬虫框架Scarpy、Redis、布隆过滤器、PostgreSQL数据库等相关技术,设计并实现了一种基于Scrapy的岗位推荐系统,能够帮助用户快速精准地获取所需要的招聘信息。
参考文献
[1]胡文涛.一个分布式动态网页爬虫系统设计与实现[D].武汉:华中科技大学,2022.
[2]黎玉香,于伟.分布式网络爬虫系统的基本原理与实现[J].花炮科技与市场,2018(4):45.
[3]刘泽华,赵文琦,张楠.基于Scrapy技术的分布式爬虫的设计与优化[J].信息技术与信息化,2018(增刊1):121-126.
[4]刘思林.Scrapy分布式爬虫搜索引擎[J].电脑知识与技术,2018(34):186-188.
[5]杨本栋.基于网页信息自动提取的分布式爬虫系统设计与实现[D].北京:北京邮电大学,2022.
(编辑 何 琳编辑)
Design and implementation of a job recommendation system based on Scrapy
Cao Pei1, Lin Yongyi2*
(1.Nanjing Vocational University of Industry Technology, Nanjing 210023, China;
2.Communication University of China Nanjing, Nanjing 211172, China)
Abstract: The development of big data and artificial intelligence has led to an explosive growth of information on the internet. How to quickly and accurately mine effective information from massive data has become a research hotspot. This article is based on the Scarpy framework and combines Redis, Bloom Filter (BF), and PostgreSQL databases to design and implement a recommendation system based on Scrapy. The system can obtain information from specified URLs, store them in the database, and present them to users in the form of web pages or emails.
Key words: recommendation system; Bloom filter; Scarpy; PostgreSQL
