
基于云计算的电力电能计量信息采集系统设计
2023-05-06 07:29:10宋晓川郑宽昀李俊臣武文广
工业加热 2023年3期
宋晓川,郑宽昀,李俊臣,武文广,胡 威
(1.国网陕西省电力有限公司,陕西 西安 710000;2.南瑞集团(国网电力科学研究院)有限公司,江苏 南京 211000)
智能电网建设的迅速开展,将会引入大量的智能电表、电网友好型设备等终端,从而使电力电能能够进行双向交互,为智能电网提供海量数据,但同时也给数据管理、分析和响应技术带来极大的挑战[1]。以往电力电能计量信息依靠人工采集的传统方式,然后再对信息数据进行统计分析和录入等操作[2],不仅效率低且容易出现错误,增加校对过程又会使效率再度降低,对后续电能生产计划的制定也产生不小影响,且电表仅能显示一段时间的电量,需要工作人员定期采集[3-4]。因此推进电力电能计量信息采集系统发展是电力行业发展的关键,但是现有电力电能计量信息采集方式效率层面还不够完善,需要进一步深入探讨。
云计算的出现为信息技术的发展开辟了新通道[5-6]。面对电能信息大数据时代,文献[7]提出基于ATT7022E和STM32的电力数据采集系统,但该系统元素过多,需要的存储空间大,且多余元素会造成空间浪费。文献[8]提出基于Spark的发电机电能计量与分析自动化系统,但该系统在约简过程中容易丢失部分属性,导致信息随之丢失。而偏序约简算法解决了上述难题,利用其并行化特征直接约简电能计量信息数据集,使约简效率和准确率大幅提升。因此本文提出基于云计算的电力电能计量信息采集系统设计,该系统的创新点是配合使用偏序约简算法进行电能数据约简预处理,为电力行业自动化的发展建立技术基础。
1 云计算下电力电能计量信息采集系统
国家电网已建立了与电能信息采集相关的一系列系统,主要负责采集不同用户用电情况下的电力电能计量信息[9]。已有的运行体系缺乏整体统一协调,各部门与专业之间相互协作。对个别业务有特殊要求时,未考虑个别数据采集频率标准,不能实现数据实时共享,限制了系统的应用范围。对比现有国网系统,所提出的信息采集系统整体框架可以减少很多中间环节,具有更加高效快捷的特点。
1.1 电力电能计量信息采集系统硬件设计
云计算的关键技术是将大量的电力电能计量信息资源集中到虚拟化平台上,为不同的电力用户提供丰富的平台服务,同时又能在不占用计算机内存空间的前提下存储海量信息数据,满足电力用户对存储空间的需求。云计算是一种强大的管理平台技术,不仅是一种网络技术,它还是一种集成了分布式存储技术、编程技术和虚拟技术的综合技术[10-11]。且云计算的应用成本较低,功能更加丰富,能够为当前电力电能计量信息采集做出贡献。
基于云计算的电力电能计量信息采集系统硬件设计整体架构图如图1所示。
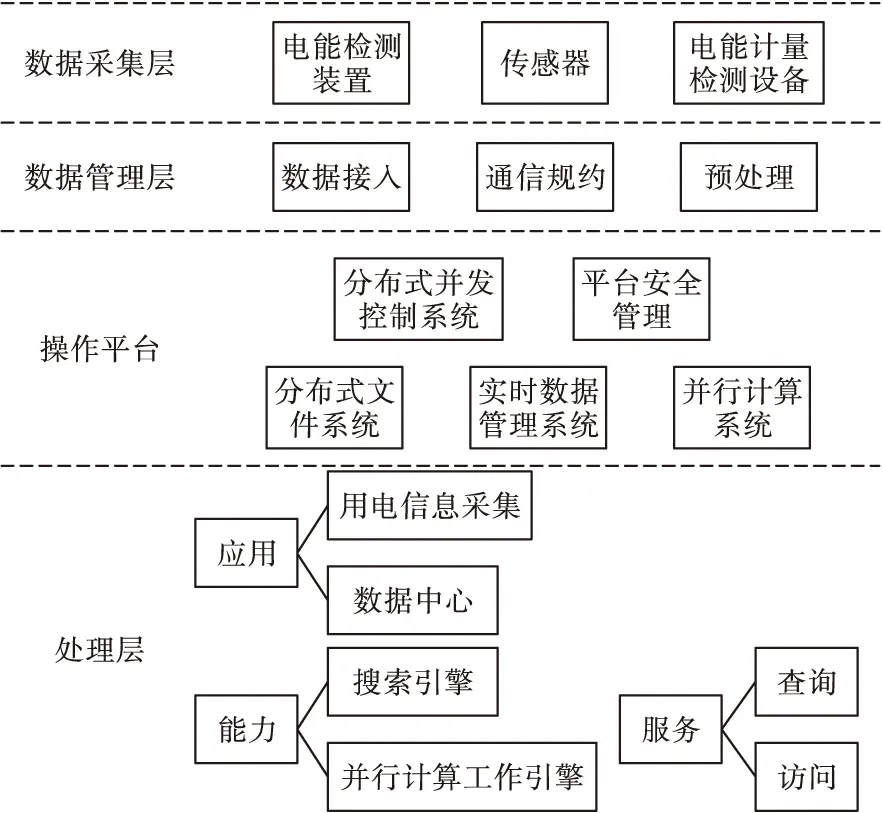
图1 基于云计算的信息采集整体架构图
由图1可知,信息采集的整体架构共有四层,分别为处理层、操作平台、数据管理层以及数据采集层,具体介绍如下:
(1)数据采集层采集电能计量装置中各种数据,通过电力电能检测装置和电力电能计量检测设备以及各种传感器实现,包括底层数据的采集,输出电力电能计量,实现测量、记录和发送各种电量,如发电量、供电量和用电量等。不同型号专变终端和用户设备等均可作为计量设备被使用。
(2)数据管理层负责实时数据如何接入和研究参数等,以及通过偏序约简算法对电力电能计量信息数据的预处理。偏序约简算法是把相同内容的序列视为一个约束动作,根据数据管理层中攻击者截获的信息,判断已等效的约束动作是否达到冗余状态,然后约简此刻状态空间。偏序约简算法以同一动作序列建立等价关系,在一定程度上可以减少安全协议状态空间,提高约简速度和检测效率。偏序约简算法计算公式为
Syj=Pij+Qij
(1)
式中:Pij为偏序约简状态迁移节点;Qij为偏约简状态后继节点。根据式(1)可计算出偏序约简状态空间内最佳约简效果,实现电力电能计量信息数据的预处理。
(3)操作平台分为五个模块,具体如下所示:①分布式文件系统可实现电力电能计量信息的存储,该系统扩展性高,能够灵活配置业务。②海量实时数据管理系统基于云计算实现存储和管理大量实时数据,目前通用数据库存储和处理实时用电信息数据时具有局限性,而该系统通过简化数据模型、扩展分布式存储资源解决上述问题,以保证整体流程顺畅运行。系统采用内存和磁盘组合存储的分布式数据处理思想,电力电能计量信息为实时数据,使用内存存储实现信息存储与检索,首先通过实时数据库对其进行实时处理存储,形成历史数据文件块,再通过并行计算系统分割和压缩文件块,最终实现数据存储;存储用户与重要负荷电表数据文件采用磁盘存储方式,存储采用文件与数据结合方式实现,检索技术使用哈希表数据结构。③并行计算系统使用MapReduce并行模式完成用电信息的统计与分析。④分布式并发控制系统实现即时刷新数据。⑤平台安全管理系统负责管理整个操作平台的安全,具体功能为系统、用户和权限管理,以及报警等安全监测功能。
(4)处理层分为能力模块、服务模块、应用模块以及终端采集和通信模块,具体如下所示:①能力模块含有搜索引擎和并行计算工作引擎,分别负责文档存储、索引、搜索和电力系统的计算与应用,为数据搜索和电力系统业务应用提供技术基础。②服务模块提供数据访问接口以及数据查询和监控访问等服务,多种接口均可封装为不同访问方式,适用范围广。③应用模块。采用云计算信息平台,实现电力电能计量信息采集等功能,应用在电力系统为建设智能电网提供技术支持。④终端采集和通信模块。主要包括主站服务器、信息采集基站和两台终端。主站服务器也叫总部服务器,主要负责存储和处理数据;信息采集基站也叫中转站,主要负责汇总采集的信息;两个终端包括用户智能化费控计量装置和电力线路上的电压与电流采集装置。
海量电力电能计量信息采集系统硬件部分的底层数据利用模糊特征采集方法获取[12],在云计算的环境下可得利用采集方法获取的统计变量TJB计算公式如下:
TJB=Sjz×(gml-glm)
(2)
式中:Sjz为云计算结构数据组;gml与glm均为云计算关联特征量。在云计算技术下,利用式(2)可得到电力电能计量信息采集系统的统计结果。根据智能电网全覆盖、全服务和全费控制的要求,必须对上述四种硬件配置进行合理的配置。
1.2 电力电能计量信息采集系统软件设计
基于采集到的海量电力电能计量信息采集系统软件,使用偏序约简方法进行预处理。偏序约简方法主要是当有两个独立事件最终导致同一个结果时,只对其中一个事件进行分析处理。给出电力电能计量信息采集系统软件部分属性偏序约简算法的具体步骤:
步骤一:在电力系统设定一个三元组:
X=(U,W,V)
(3)
式中:X为运行状态;X与U均为集合;X包含全部状态;U包含全部对象,也称为论域;W=C∪{D},D∉C,其中D和C分别描述两种属性,前者为决策,后者为条件;其中:
(4)
式中:V描述属性w的值域,即∀w∈W,Vw∈VO,VO为初始属性值域。此三元组也称电力系统信息决策表。
步骤二:使用上述定义决策表Vci∈U,VDi∈C(i∈[1,n],i为正整数),条件属性为ci,Vci描述中间转换状态,VDi描述终止状态,初始状态设为O,VDi通过变换O得到,该变换经过所有变迁关系c1,c2,…,cn实现。
步骤三:若一个状态量内有多个对象,经过变换后它们的状态量也为同一个,但变换中状态量不同。决策表中的对象拥有一样的状态值或者在一个范围内都可以称状态量相同。变换通过经过变迁关系ci+1,ci+2,…,ci+n实现,设有ui∈U满足以上条件变换。
步骤四:经过一个或相同的多个变迁关系变换后,这些对象依然为同一个状态量,上述条件成立则去掉其他冗余对象只保留其中一个对象。
给出一个偏序约简算法的定理:依靠D划分等价类{D1,D2,…,Di},Di={u1,u2,…,ui}(t∈Z),对象为决策表中的数据。假设在一个等价类内有不止一个数据分片DSk(k=1,2,…,n),则对这些DSk进行约简,得到的结果就为最后的约简结果,表达式如式(5)所示:
(5)
式中:Wk为在第k个数据分片内求出的约简属性集;Wkj为通过第k个数据分片求出的第j个属性,j=1,2,…,r。
根据偏序约简算法的定理,设该决策表内有n个包含m个条件属性和一个决策属性D的对象,该决策表如表1所示。
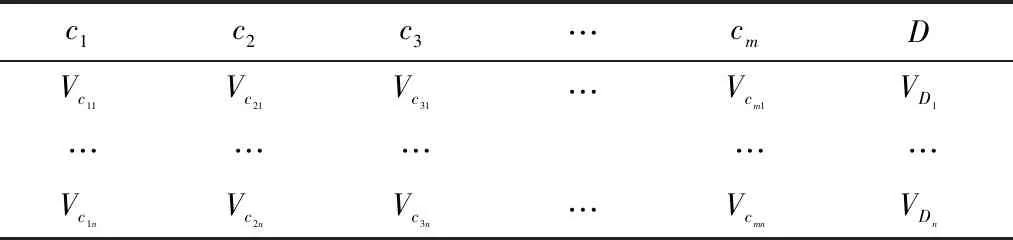
表1 电力系统信息决策表
并行化是MapReduce模型突出的优点,与偏序约简算法的特点相结合能够根据决策属性的取值将电力电能计量信息集进行等价类划分,然后约简其中各对象。算法能独立处理并发事件,MapReduce模型拥有很多map函数,它们可以使约简同时独立开展。设E的值有k种,则E的分割等价类如式(6)所示:
(6)
式中:Ecmi为第i个属性上第m个对象的值。
等价类内含有电力数据集,对其使用map函数完成约简过程。
使用map函数偏序约简算法的具体步骤如下:
步骤一:将数据集中的记录分别作为一个对象,对其从初始状态经过变迁关系转换成决策状态。
步骤二:若步骤一中处理结果为单个对象,则求其经历状态集合,否则求所有对象的经历状态并集。
步骤三:统计上述结果,若存在步骤二中的情形,解码中间状态量的集合并输出,得到对应的最终结果;若不存在,则以上结果就为全部条件属性。由此完成电力电能计量信息采集系统软件设计,结合硬件部分,设计基于云计算的电力电能计量信息采集系统。
2 实验分析
将本文系统应用于某供电区域,分别验证本文系统的电力电能计量信息采集情况和查询功能,并对本文系统信息预处理效率进行实验分析,以及对实现本文系统信息存储的分布式文件系统的工作性能进行实验分析。
对该供电区域使用本文系统采集的月度电量进行查询记录,分别查询供电量、售电量与用电量,查询结果如表2所示。

表2 某区域月度电量查询表 亿kW·h
通过表2可知,应用本文系统能够准确采集和查询电力电能计量信息,满足电力系统自动化要求,提供记录分析与查询服务,大幅度提升工作效率,推进电力行业发展进程。
在该供电区域中选取4组采集到的电力电能计量信息数据,数据规模相同,编号从1到4,比较不同节点数的信息预处理加速比性能,4组信息数据中选取不同节点数的约简时间对比结果如图2所示。

图2 不同节点数约简效率对比
由图2中可知,本文系统的信息预处理约简效率随节点数的增加而增加,但由于每个节点间存在线程调度等开销,导致效率不能达到理想状态,不呈线性增加。不过由此可以推测出当数据规模较大时,节点数随之增加,便可以使信息预处理的约简时间大大缩短,表明使用本文系统进行数据预处理在时间效率上有极大的优势。
本文系统实现信息采集过程中,采用Hadoop分布式文件系统(HDFS)完成电力电能计量信息的有效存储,为此从分布式文件系统的运行时间和吞吐量两个工作性能指标来衡量本文系统的信息存储优势。其中相同数据采集过程中的不同操作所用的运行时间可准确反映采集效率的高低,采集效率是综合电力电能计量信息采集的重要指标之一,为了更好地匹配电力电能计量信息采集的可靠性能与准确性能,需要对分布式文件系统文件大小与运行时间的关系进行验证,分布式文件系统运行时间对比结果如图3所示。
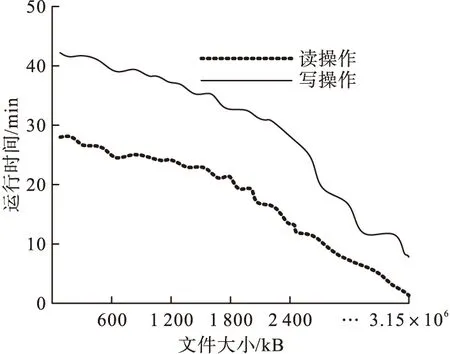
图3 分布式文件系统运行时间
由图3可知,HDFS处理数据的时间随着文件增大越来越少,尤其读能力较为优越。主要原因为HDFS的处理模式为单次写而多次读,从而大量节省信息数据传输时间。
基准测试从吞吐量单方面进行,吞吐量是衡量电力电能计量信息采集的重要工作性能指标之一,基于对电力用户的测试,根据信息采集过程中用户的HDFS覆盖数量确定覆盖范围,计算吞吐量是否有效,若没有错误或意外测试结果,说明吞吐量良好,其中吞吐量越大表明工作性能越好,计算公式如下:
(7)
式中:Aa为分布式文件系统信息采集列表;Hh为用户集合;Bb为项目总集合。分别测试不同大小文件的读、写操作吞吐量,其中大文件为一个3 GB的文件,小文件为10 000个单个大小为300 kB的文件。分布式文件系统吞吐量对比结果如图4所示。
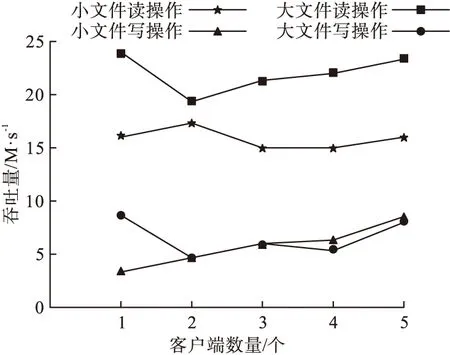
图4 分布式文件系统吞吐量
由图4可知,HDFS读操作性能较好,且处理大文件比小文件工作性更好。客户端数量的变化对HDFS影响较大,使系统性能出现波动,但随着客户端数量逐渐增加,吞吐量也逐渐呈稳定升高趋势,证明HDFS具有较高的读、写操作能力,其中处理大文件的读操作能力最好,写操作能力相比之下较低,也从侧面说明HDFS适用于计算复杂度不高的文件,当复杂度较高时写操作可能会出现一定延迟。
3 结 论
设计基于云计算的电力电能计量信息采集系统,通过检测装置采集信息数据,偏序约简算法再对采集到的信息进行预处理。大量的电能数据占用存储空间,读取和录入效率越来越低,因此本文设计一种新的电力电能计量信息采集系统,实现电能信息的整体管理。通过实验证明本文系统能自动采集电力电能计量信息,且能准确提供信息查询服务。在数据预处理实验中,本文所采用的偏序约简算法的工作效率随节点数量的增加而升高,实验选取的节点数中15个节点的算法时间性能最好。分布式文件系统性能实验中,验证了文件越大此系统的工作效率越高,且工作性能越好;读性能优于写性能,均有较高的可扩展性,因此电力电能计量信息采集系统适合高吞吐量、文件较大且计算复杂度较低的电力电能计量信息数据,为电力电能计量信息的采集系统提供了技术支持,从根本上节约人工与时间成本。
电力电能计量信息采集系统设计工作还在不断发展中,对于未来的研究,可以针对该系统采集电力电能信息的准确率和效率做更加深入的探讨。
猜你喜欢
奥秘(创新大赛)(2020年1期)2020-05-22 02:42:38
小学科学(学生版)(2019年10期)2019-11-16 08:55:02
成都信息工程大学学报(2019年2期)2019-08-28 10:00:46
小哥白尼(趣味科学)(2019年12期)2019-06-15 10:56:32
数学年刊A辑(中文版)(2018年1期)2019-01-08 01:58:24
天津师范大学学报(自然科学版)(2018年4期)2018-09-11 08:07:02
人大建设(2018年2期)2018-04-18 12:17:00
自动化学报(2018年2期)2018-04-12 05:46:01
成都信息工程大学学报(2017年1期)2017-07-21 14:14:11
浙江大学学报(理学版)(2016年5期)2016-09-16 03:00:01
