
基于社会结构视角的网络个人信息披露影响因素研究
2023-04-29 00:00:00缪晓雷
陕西理工大学学报(社会科学版) 2023年3期





[摘要] 网络个人信息是互联网时代的重要资源,如何保护和披露个人信息受到个体心态和技术发展等多方面影响。从社会结构视角出发,使用中国综合调查数据(CGSS2017)进行实证研究分析发现:上网者的个人信息披露具有显著的个体行为差异,且对于模型的贡献度最高,而社会结构因素对于个人信息披露的影响同样显著,其中社会阶层越高个人信息披露程度越高,年龄的增长对于个人信息披露具有倒U型影响。研究结果支持了个体行为差异和社会结构差异的共存,并回应了隐私悖论理论,同时,社会阶层和生命历程同样是解释隐私悖论问题的重要因素。
[关键词] 个人信息披露; 个体行为; 社会结构; 隐私悖论
[中图分类号]C913.4 [文献标识码]A [文章编号]2096-4005(2023)03-0044-09
[收稿日期]2023-01-09 [修订日期]2023-03-03
[作者简介]缪晓雷(1984— ),男,黑龙江哈尔滨人,博士后,助理教授,研究方向为社会网络与社会资本。
[基金项目]陕西省哲学社会科学重大理论与现实问题研究项目(2022ND0174)
中国互联网络信息中心(CNNIC)第51次《中国互联网络发展状况统计报告》显示,截至2022年12月,我国网民规模达10.67亿,较2021年12月增长3549万,互联网普及率达75.6%。随着互联网与数字技术的发展,信息已经成为重要的资源类型,信息的获取、传递和保护是数字社会和虚拟社会重要的议题[1-2]。对上网者而言,网络信息有三个主要方面:个人信息、交往信息和浏览信息。相关的学术研究从信息内容与信息隐私两方面展开,在信息隐私方面,个人信息多关注信息安全和信息保护[3],交往信息多关注信息价值和信息资源[4],浏览信息多关注信息权利和信息筛选[5]。尤其在大数据时代,个人的信息和数据面临着隐私透明化、信息商品化、身份标签化等现实问题[6]。
一直以来,上网者对于网络个人信息拥有两方面权利:一方面是进行自我披露、自我保护的个人信息权[7],另一方面是进行自我选择、自我保留的信息被遗忘权[8]。本文关注的是上网者对于自身信息是否具有披露意愿、是否具有保护措施的个人信息权[9]。上网者选择是否披露个人信息、披露多少、披露的意愿如何,是个人信息权的综合表现。在讨论个人信息披露时,巴恩斯(Barnes)基于美国的研究提出了著名的隐私悖论(privacy paradox)理论[10],即上网者虽然表现出比较关注个人信息的安全和隐私问题,但这种态度却不会影响其隐私披露的意愿和行为。研究表明,社交需要、自我呈现和个性化服务为隐私悖论的成因提供了支持[11]。自从隐私悖论被提出以来,传播学、心理学、管理学等学科的研究者对于其成因、表现和解决办法都有过大量的研究[12-14]但多聚焦于个人行为视角,本文试图从社会结构视角出发,进一步思考影响上网者披露个人信息的因素。
一、文献综述与理论假设
上网者选择是否披露个人信息,是权衡信息披露代价与信息披露收益之后的理性决策[15]。在数字经济和共享经济时代,上网者的个人信息不仅是个人信息权和隐私权的表现,也可以作为一种商品,具有使用价值和交换价值[16]。而且,由于传播技术渗透、隐私自主选择、法律合理范畴、平台责任缺失等综合因素的影响,个人信息和隐私不得不“让渡”于他人或平台,成为一种资源或商品[14]。现有研究从两种角度分析披露个人信息从而形成隐私悖论的原因:首先是计划行为理论,认为上网者对于个人信息的披露带有预期,能够带来一定的好处和收益[17];其次是隐私计算理论,认为上网者可以理性地衡量个人信息披露的风险与收益,进而决定其行为[18]。也有研究从沟通隐私管理、社会交换理论、社会影响过程、使用满足理论等方面论述个人信息披露的影响因素[19]。然而,现有研究大多关注个体行为意图、个体行为态度、个体行为决策等方面。社会学研究则更加关注由于社会结构因素引起不同个体之间的差异与联系。社会学家布劳(Blau)认为,社会结构包括纵向的阶层不平等和横向的群体异质性,而个体的行为是建立在已分化的社会位置及其对社会关系的影响之上的[20]。因此,本文在个体行为视角的基础上,提出两个基于社会结构视角的因素:基于纵向结构不平等的社会阶层视角和基于横向结构异质性的生命历程视角。通过以上三个视角来综合分析网络个人信息披露的影响因素。
(一)个体行为视角
从个体行为视角来衡量个人信息披露的意愿和结果,在现有研究中取得了大量的成果。其中,感知风险和隐私关注是两个重要的影响因素。感知风险因素是基于隐私计算理论提出的,上网者被认为是可以衡量自身风险与收益的理性行动者,当感知到个人信息和隐私披露具有潜在的风险时,上网者会降低信息披露的意愿,甚至拒绝披露,引起个人信息回避、认知冲突等负面结果[21-22]。然而,感知风险可以提升上网者的隐私关注水平。隐私关注是对于隐私侵犯的意识与评估,上网者的媒介素养及其对社交网络的信任度也对隐私关注有显著影响[23]。因此,研究者经常将感知风险与隐私关注两个因素综合讨论,且发现二者在影响个人信息披露意愿和行为的过程中存在链式因果,即感知风险可以通过提升隐私关注降低个人信息的披露意愿和行为[24]。本文基于隐私关注的个体行为视角,提出假设1:
H1:上网者的隐私关注程度越高,则个人信息披露程度越低。
(二)社会阶层视角
社会阶层的差异是影响上网者网上行为的重要因素。其中最典型的例子是数字鸿沟研究,个体的社会经济地位越高、所在地区经济水平越高,则越可能接入和使用互联网,并倾向于学习型、研究型等适用于个人发展的使用方式[25-26]。对于个人信息披露而言,同样可以用数字鸿沟理论进行解释,即社会阶层的差异会导致上网者不同的网络使用方式,进而影响个人信息披露;也可以用虚实转换理论进行解释,即实体空间中社会阶层和社会资源的不平等,会形塑个体的行为方式,进而影响上网者在网上的行为结果[27]。现有研究发现,新闻使用和社交使用可以提升上网者的隐私心理需要、提升个人信息权意识,这是对于数字鸿沟理论的进一步推演[28]。对于隐私保护的研究表明,经济越发达的地区,其居民越重视隐私保护;社会经济地位越高的群体则更注重自我隐私的保护[29]。因此,社会阶层视角是影响个人信息披露的重要因素,基于此提出假设2:
H2:上网者的社会阶层越高,则个人信息披露程度越低。
(三)生命历程视角
生命历程反映的是不同年龄群体之间的异质性,是影响个体行为结果的重要因素。基于总体趋势而言,中国居民的隐私安全感随年龄的变化呈现U型结构,即青少年群体和老年群体的隐私安全感较高,而中青年群体的隐私安全感较低。世代分析的结果表明,二十世纪七十年代前出生的群体相对于二十世纪八十年代后出生的群体隐私安全感更高[30]。对于隐私安全感的研究可能并不能直接得出上网者的个人信息披露情况,对此,有研究发现年龄与信息披露之间存在负相关关系,年轻群体更倾向于保护个人信息[19]。可见,现有研究并没有得到一致的结论,个人信息披露与年龄之间可能存在无关、线性、非线性等多重复杂的关系。另外,上述研究都是将年龄作为区分不同群体的关键变量,分析群体间网络使用行为的异质性,忽略了不同年龄之间的数字鸿沟问题,如个人特征、阶层特征等会直接影响不同年龄群体的网络使用方式[31]。
因此,生命历程视角首先要考虑不同年龄群体的内部特征,特别是青少年群体与老年群体。对于青少年群体的研究表明,未成年人更倾向于在社交网络中披露个人信息,但年龄越大的未成年人披露意愿越低[32]。对于老年群体的研究表明,其对于信息的敏感程度以及是否有过隐私被侵犯的经历,对其隐私关注有显著的正向影响,隐私关注度越高则个人信息披露意愿越低[33]。结合数字不平等理论以及现有研究的主要结论,本研究认为,青少年群体由于接入互联网程度更高、互联网使用与自身生活联系更加紧密,更可能对个人信息进行披露。随着年龄的增加,老年群体的隐私安全感更低、个人信息保护意识更强,从而该群体的个人信息披露程度降低。总体而言,呈现非线性的变化趋势。由此,本文提出基于生命历程视角的非线性假设3:
H3:随着上网者年龄增长,个人信息披露程度呈现非线性变化趋势。
二、数据来源与测量方法
本文使用中国综合社会调查(Chinese General Social Survey 2017,以下简称CGSS2017)数据分析网络个人信息披露的影响因素。该数据与国际社会调查项目(International Social Survey Programme,简称ISSP)合作,设置了专门模块询问被访者的社会网络与互联网使用情况。其中互联网使用部分对于被访者的个人信息披露情况进行了较为详细的询问。经过样本筛选和缺失值处理,本研究得到总样本3911个,其中使用互联网的样本量为2122个,不使用互联网的样本量为1789个。
(一)因变量
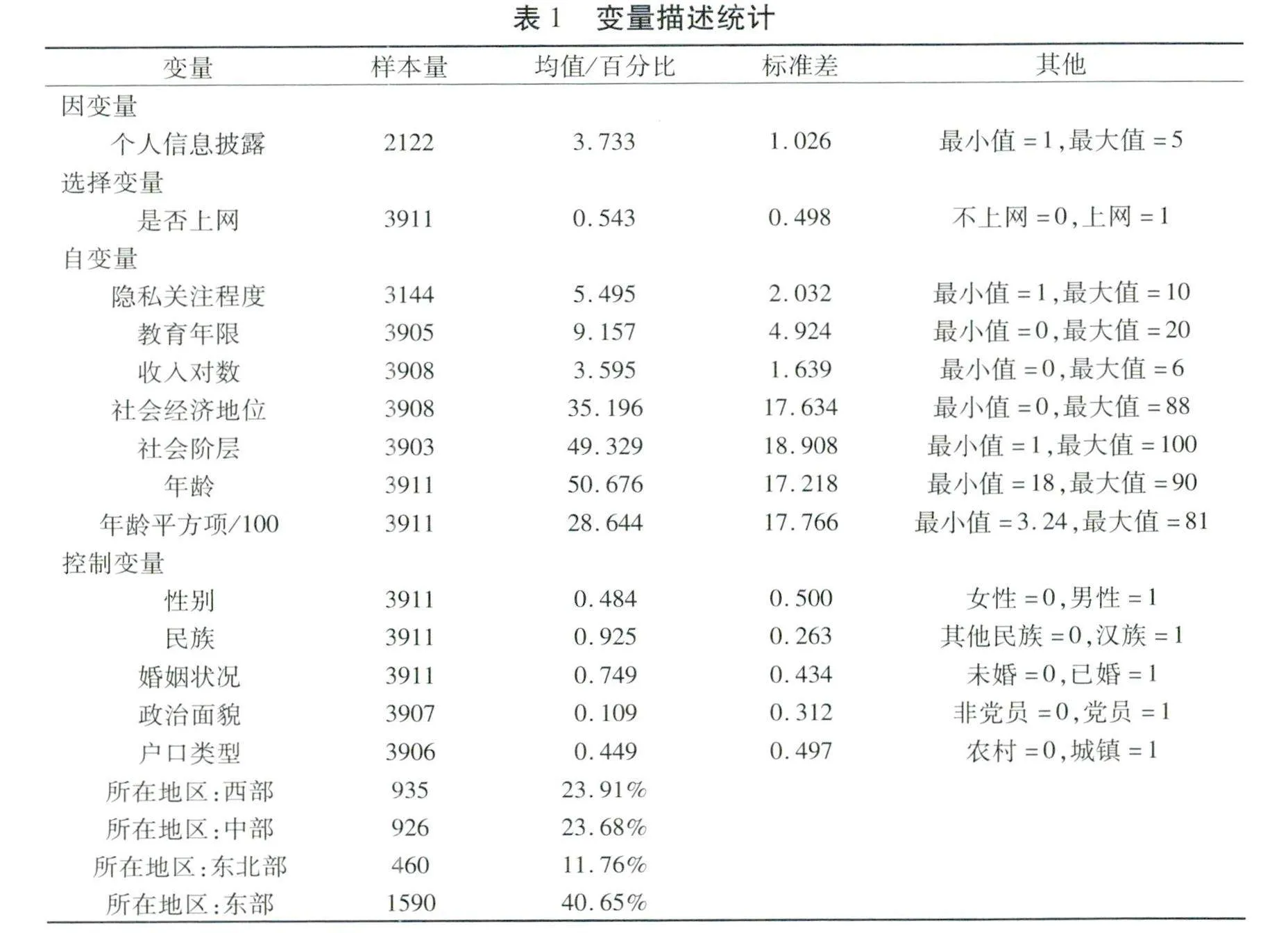
本研究将上网者的个人信息披露作为因变量。在CGSS2017中,“有些网站要求您注册个人信息之后才能登录,当需要注册时,您填写的个人信息真实度”这一问题,为被访者提供的选项分别是“都是真实的、大部分都是真实的、一半是真实的、大部分都是虚构的、几乎全都是虚构的”,每个选项对应的赋值分别为1-5。将该变量进行反向赋值,即个人信息的披露程度越高,则该变量的赋值越高,最终得到均值为3.733,标准差为1.026,取值范围1-5的定序变量。
(二)选择变量
CGSS2017中首先询问了“您第一次上网是哪一年”,将从来没上过网的被访者赋值为0,同时跳过后面互联网使用情况的问卷。这样实证分析模型就会遇到样本删截,并产生样本选择偏误的内生性问题[34]。为了应对这一问题,本研究将是否上网作为选择变量,即回答不上网的样本赋值为0,回答上网的样本赋值为1。选择变量将用于样本选择模型中进行分析,观察样本删截是否造成了系数估计的偏差。选择变量的描述结果发现,被访者的上网比例为54.26%,不上网比例为45.74%。考虑到该数据为2017年时的上网比例,且包括城市与农村地区的样本,该分布可以被接受。同时进行两个步骤的实证分析:第一步针对54.26%的上网群体进行分析,得到具有网民代表性的结果;第二步针对45.74%的不上网群体使用个人因素、阶层因素和地区因素进行分析,再分析全样本的结果,以解决上述因素造成的非随机样本选择偏误问题。
(三)自变量
根据理论假设,本研究的核心自变量主要有三个部分:隐私关注、社会阶层和年龄。首先,隐私关注通过询问被访者是否担心自己的行为在互联网上被查看。CGSS2017分别设置了“我担心在网上我的个人隐私被泄露、我担心政府查看我在网上的行为、我担心公司查看我在网上的行为”三个问题,并用取值1-5分别代表“非常不符合、不符合、无所谓符合不符合、符合、非常符合”。本文通过主成分因子分析法,提取出三个问题中的公因子,并转换为均值5.495、标准差2.032、取值范围1-10的定距变量。该变量取值越高,则说明被访者的隐私关注程度越高。
其次,被访者的社会阶层通过教育年限、收入水平和社会经济地位进行测量。其中,教育年限根据CGSS2017问卷对于被访者最高受教育程度的调查进行赋值,得到取值范围0-20的定距变量。收入水平根据被访者在前一年的总收入进行计算,为了避免收入分布右偏产生的影响,将收入水平变量进行对数运算,得到取值范围0-6的定距变量。社会经济地位根据被访者的具体职业编码进行赋值,得到取值范围0-88的定距变量。为了在实证模型中对三个理论假设进行比较,研究将教育年限、收入水平和社会经济地位进行主成分因子分析,得到一个能够代表被访者社会阶层的因子得分,经过转换后得到均值为49.329、标准差为18.908、取值范围1-100的定距变量。
最后,对于生命历程视角的测量,本文使用被访者的年龄变量。根据CGSS2017询问的被访者出生年份,得到在2017年时被访者的实际年龄。由于本研究提出了非线性假设,即随着年龄的增长,因变量个人信息披露程度先提升再下降。因此,为了观察年龄变量是否存在非线性影响,本文加入了年龄变量的平方项。为了避免年龄平方项的取值过大,造成回归系数的解读困难,本文将年龄平方项除以100,再进入模型计算。
(四)控制变量
基于现有研究对于上网者个人信息披露的影响因素分析,研究主要对被访者的个人特征、身份特征、地区特征进行控制。其中个人特征主要有性别、民族等人口学变量,身份特征主要有婚姻状况、政治面貌、户口类型等变量,地区特征控制了被访者所在的省份,将其合并为西部、中部、东北部和东部四个区域。上述所有的变量描述统计结果如表1所示。
三、实证研究结果分析
基于理论假设,本研究进行实证研究的目标是分析个体行为视角、社会阶层视角和生命历程视角对于因变量个人信息披露的影响。由于“是否上网”这一变量产生了样本删截,3911个总样本中有45.74%为不上网样本,54.26%为上网样本。因此,为了应对样本选择问题,实证研究被分为两个部分:第一部分只针对上网群体进行分析,第二部分使用样本选择模型,对所有样本进行分析,并观察样本选择问题是否存在。
(一)上网群体的模型结果
表2展示了上网群体的个人信息披露回归模型结果。其中,模型1为个体行为视角,加入了隐私关注程度作为解释变量;模型2为社会阶层视角,加入了社会阶层作为解释变量;模型3为生命历程视角,加入了年龄和年龄平方项作为解释变量;模型4为加入所有变量的全模型。所有模型中均加入了控制变量。由于因变量个人信息披露为取值范围1-5的定序变量,可以近似作为连续变量使用多元线性回归模型(OLS)进行分析。
根据模型1的结果可知,隐私关注程度作为解释变量时,其系数为负向且显著。说明上网者的隐私关注程度每提升1个单位,则个人信息披露程度降低4.6%。该结果支持了假设1,即上网者的隐私关注程度越高,则个人信息披露程度越低。
根据模型2的结果可知,社会阶层变量作为解释变量时,其系数为正向且显著。说明上网者的社会阶层每提升1个单位,则个人信息披露程度提升0.4%。该结果与假设2“上网者的社会阶层越高,则个人信息披露程度越低”得到相反的结果,即较高社会阶层的上网者不仅没有表现出低程度的个人信息披露,反而表现出较高程度的个人信息披露。研究认为,这正是隐私悖论在实证研究中的发现,虽然高阶层群体在实体空间具有更高的受教育水平和收入水平,不愿意披露个人信息,但在互联网上由于信息商品化、平台利益推动等因素,造成高阶层群体更愿意披露个人信息。
根据模型3的结果可知,年龄与年龄平方项作为解释变量时,年龄的系数为正向且显著,而年龄平方项的系数为负向且显著。这说明年龄对于上网者的个人信息披露存在显著影响,且这种影响是倒U型的非线性趋势,其拐点约为39岁(100×0.025÷0.032÷2)。也就是说,小于39岁的群体,年龄越大则个人信息披露程度越高;大于39岁的群体,年龄越大则个人信息披露程度越低。该结果在一定程度上支持了假设3,即生命历程是一种非线性影响因素。
根据模型4的结果可知,当加入所有变量后,全模型的解释力得到显著提升。观察每个解释变量可知,隐私关注程度、社会阶层和年龄及年龄平方项的变量保持显著,说明三组影响因素是稳健的,对于因变量个人信息披露同时存在解释力。
基于回归模型,研究使用夏普利分解(Shorrocks-Shapely decomposition)的方法[35],分解每一组解释变量对模型的贡献度,结果如表3所示。由于夏普利值的数值较小,为了更精确地展示结果,表中将夏普利值乘以100进行展示。根据夏普利分解的结果可知,本文提出的三组假设,即个体行为视角假设、社会阶层视角假设、生命历程视角假设,其模型贡献度指标均远高于其他控制变量,说明三种视角相对于其他因素为因变量提供了更多的解释力。其中,个体行为视角的隐私关注程度变量模型贡献度最高,为40.51%;其次为生命历程视角的年龄与年龄平方项变量,模型贡献度为26.94%;最后是社会阶层视角的社会阶层变量,模型贡献度为19.98%。三组变量的贡献度均远高于其他控制变量。夏普利分解的结果支持两点发现:第一,隐私关注程度是影响个人信息披露的最重要因素,这点与现有研究发现保持一致;第二,社会结构是不可忽视的因素,社会阶层代表的社会不平等,生命历程代表的社会异质性,对于个人信息披露均有重要影响。以上结果表明,对于隐私悖论的解释和隐私保护的研究,不能只停留在个体行为层面,引入社会结构层面的因素是非常必要的。
然而,虽然多元线性回归模型(OLS)的结果支持了个体行为差异和社会结构差异对于个人信息披露存在显著影响,但仍存在两个较为明显的问题:一是样本选择问题,即多元线性回归模型(OLS)中的样本仅为上网群体,存在可能的内生性问题;二是模型解释力问题,从表2可知,模型1到模型4的解释力均不到10%。为了得到更好的结果,需要使用其他模型进一步验证。
(二)样本选择模型结果
根据数字不平等理论[31],个体差异、阶层差异以及地区经济水平差异,都是决定个体是否上网并成为网民的重要因素。因此,是否上网并不是随机出现的,这导致不上网的被访者不回答上网行为部分的问卷时,产生了样本选择的内生性问题。本文使用样本选择模型来应对可能存在的内生性问题。样本选择模型是赫克曼(Heckman)提出的解决样本选择偏误的方法[36],使用二阶段模型进行分析:第一阶段首先使用公式(1)进行Probit回归,其因变量为是否上网的二分变量,自变量为对是否上网产生影响的解释变量,然后通过公式(2)计算出逆米尔斯比率(inverse Mill’s ratio,简称IMR),对系数的偏差进行控制;第二阶段使用公式(3)将逆米尔斯比率加入到多元线性回归模型(OLS)回归方程中,可以通过逆米尔斯比率系数的显著性判断是否存在样本选择问题。同时,加入的逆米尔斯比率能够识别估计量的偏误,得到解释力更好的结果。
样本选择模型的结果如表4所示。其中,模型5为加入了隐私关注程度作为解释变量的个体行为视角,模型6为加入了社会阶层作为解释变量的社会阶层视角,模型7为加入了年龄和年龄平方项作为解释变量的生命历程视角,模型8为加入所有变量的全模型。样本选择模型的设置与表2中多元线性回归模型(OLS)的设置基本一致,不同之处在于加入了逆米尔斯比率变量,该变量是通过赫克曼第一阶段的Probit回归得到的。限于篇幅的原因,本文只展示了第二阶段的回归结果。
根据模型5和模型6的结果可知,逆米尔斯比率的系数显著,说明通过个体行为视角和社会阶层视角分析个人信息披露情况时,存在样本选择偏误。当控制了逆米尔斯比率之后,隐私关注程度变量的系数仍然为负向且显著,社会阶层变量的系数仍然为正向且显著,说明在考虑了样本选择偏误问题之后,自变量仍然有显著的影响。模型5的结果进一步支持了假设1,模型6的结果进一步支持了隐私悖论的存在。
根据模型7的结果可知,逆米尔斯比率的系数不显著,说明通过生命历程视角分析个人信息披露的模型中,不存在样本选择偏误问题。被访者是否上网,在年龄层面都会对因变量产生显著影响。不过控制了逆米尔斯比率之后,样本选择模型中的系数略有提升,使得年龄的拐点变为42岁(100×0.025÷0.030÷2),说明小于42岁的群体,年龄越大则个人信息披露程度越高;大于42岁的群体,年龄越大则个人信息披露程度越低。
根据模型8的结果可知,逆米尔斯比率的系数不显著,说明全模型中不存在样本选择偏误问题。同时,隐私关注程度、社会阶层、年龄和年龄平方项变量的系数仍然都显著。结果一方面验证了多元线性回归模型(OLS)回归结果的稳健性,在考虑样本选择问题时仍能够对因变量产生显著影响;另一方面由于模型的系数是考虑了内生性问题之后的结果,提升了模型整体的解释力。
△个人信息披露/△年龄 = 0.022-2×0.028×0.01×年龄(4)
为了进一步展示生命历程视角的倒U型非线性变化趋势,我们使用模型8的预测值作为纵坐标,年龄作为横坐标,如图1所示。其中,散点图表示样本年龄在18-90岁的区间中均有取值,曲线图表示随着年龄的增长,个人信息披露的变化呈现倒U型趋势。根据模型8的年龄与年龄平方项系数,个人信息披露在年龄变量上的边际效应为公式(4)所示,即随着年龄的增长,在拐点42岁前因变量个人信息披露程度有缓慢的增长,在拐点42岁后因变量个人信息披露程度则开始下降,并且年龄越大,下降的趋势越快,结果再次支持了假设3。同时,图1中加入了年龄曲线的置信区间,可以直观地发现年龄的倒U型变化趋势是稳健且有解释力的。
四、结论与讨论
本文基于社会结构视角,对上网者个人信息披露行为的影响因素进行分析。由于个人信息的披露、保护和筛选等行为,不仅是个体的自我选择和判断,也是个体所处的社会结构和宏观背景决定的。特别是在大数据和共享经济时代,信息作为一种商品,是否被披露和分享有时并不被上网者的自我选择所决定,出现了隐私悖论问题[10]。基于现实背景和理论思考,本文提出了个体行为、社会结构和生命历程三个分析视角,得到了两个主要结论:
第一,上网者的个人信息披露具有显著的个体行为差异。风险感知和隐私关注程度是影响个人信息披露的重要因素,风险感知被认为是隐私关注的前提,构成风险感知提升隐私关注,进而降低个人信息披露意愿的因果链条。使用全国抽样调查数据(CGSS2017)进行验证。本文结果一方面支持了现有研究对于隐私关注程度与个人信息披露的负相关关系,另一方面发现隐私关注程度作为主要的个体行为因素,在个人信息披露影响模型中的贡献度最大,其解释力高于其他因素。
第二,社会结构差异对于个人信息披露的影响同样显著。即将社会学的整体视角和结构视角引入到个人信息披露影响之中。虽然现有研究在使用调查数据时,会控制性别、年龄等人口学特征变量,但并没有将社会结构作为主要考虑的因素。本文的实证研究结果表明,从社会结构不平等出发的社会阶层观支持了社会阶层的提高可以提升上网者的个人信息披露程度,从社会结构异质性出发的生命历程观支持了年龄对个人信息披露程度具有倒U型的非线性影响。同时,社会阶层和年龄变量对于模型的解释力同样较强,说明本文选择的社会结构差异因素与个体行为因素同样重要,是研究个人信息披露问题中不可忽略的因素之一。
实证研究的结果也回应了隐私悖论问题,即为何关注隐私问题的群体反而更容易披露隐私。虽然社交需求论[11]、个体心态论[12-13]、隐私让渡论[14]等诸多理论可以解释这一问题,但是缺少从整体和结构层面的、具有“社会学想象力”的因素分析。本文采用的社会结构视角为隐私悖论问题提供了两方面的理论启示:一方面是阶层悖论,社会阶层变量的模型结果并没有支持理论假设,说明高社会阶层群体虽然有更强的保护个人信息和自身隐私的动机与能力,但在互联网使用过程中,却表现出更愿意披露个人信息的行为,这正是隐私悖论理论在不同社会阶层中的体现。另一方面是年龄悖论,年龄变量与个人信息披露之间呈现倒U型曲线,这不仅同时支持了本文的非线性假设,也在一定程度上支持了隐私悖论理论。意味着青少年群体虽然网络接入和网络使用的程度更高,但相比年长群体,个人信息披露程度更低。因此,对于隐私悖论的形成机制和影响因素,还需要今后更进一步的研究探讨其复杂的因果关系。
[ 参 考 文 献 ]
[1]邱泽奇.数字社会与计算社会学的演进[J].江苏社会科学, 2022(1):74-83.
[2]陈云松,郭未.元宇宙的社会学议题:平行社会的理论事业与实证向度[J].江苏社会科学, 2022(2):138-146.
[3]高德胜,季岩.人工智能时代个人信息安全治理策略研究[J].情报科学, 2021,39(8):53-59.
[4]WILLIAMS D.On and Off the’Net:Scales for Social Capital in an Online Era[J].Journal of Computer-Mediated Communication, 2006,11(2):593-628.
[5]刘少杰.网络化时代的权力结构变迁[J].江淮论坛, 2011(5):15-19.
[6]周林兴,韩永继.大数据环境下个人信息治理研究[J].情报科学, 2021,39(3):11-18.
[7]王利明.论个人信息权的法律保护——以个人信息权与隐私权的界分为中心[J].现代法学, 2013,35(4):62-72.
[8]李涵.网络环境下个人信息“被遗忘权”研究[J].当代传播, 2016(3):75-79.
[9]肖梦黎.大数据背景下个人信息保护的更优规制研究[J].当代传播, 2018(5):91-94.
[10]BAMES S. A Privacy Paradox: Social Networking in the Unites States[J]. First Monday, 2006,11(9):1312-1394.
[11]刘婷,邓胜利.国外隐私悖论研究综述[J].信息资源管理学报, 2018,8(2):104-112.
[12]强月新,肖迪.“隐私悖论”源于过度自信? 隐私素养的主客观差距对自我表露的影响研究[J].新闻界, 2021(6):39-51.
[13]黄燕萍,刘冰.网络社交隐私悖论:用户隐私态度与行为的背离[J].中国出版, 2022(10):50-53.
[14]卢家银.无奈的选择:数字时代隐私让渡的表现、原因与权衡[J].新闻与写作, 2022(1):14-21.
[15]朱侯,刘嘉颖.共享时代用户在线披露个人信息的隐私计算模式研究[J].图书与情报, 2019(2):76-82.
[16]DAVIES S G. Re-Engineering the Right to Pirvacy: How Privacy Has been Transformed from A Right to A Commodity[M]. Cambridge, MA: MIT Press,1997.
[17]SMITH H J, DINEV T, XU H.Information Privacy Research: An Interdisciplinary Review [J].MIS Quarterly, 2011,35(4):989-1015.
[18]XU F, MICHAEL K, CHEN X.Factors Affecting Privacy Disclosure on Social Network Sites: An Integrated Model[J].Electronic Commerce Research, 2013,13(2):151-168.
[19]王彦兵,郑菲.国外SNS用户个人信息披露实证研究的影响因素及其理论评述[J].情报杂志, 2016,35(5):201-207.
[20]BLAU P M. Inequality and Heterogeneity: A Primitive Theory of Social Structure[M].New York: Free Press, 1977.
[21]彭国超,程晓,刘彩华.基于元分析的网络用户个人信息披露意愿影响因素研究[J].现代情报, 2022,42(11):111-120.
[22]王文韬,张帅,李晶,等.个人信息回避行为的驱动因素研究[J].现代情报, 2018,38(4):29-34.
[23]张学波,李铂.信任与风险感知:社交网络隐私安全影响因素实证研究[J].现代传播(中国传媒大学学报), 2019,41(2):153-158.
[24]李锦辉,颜晓鹏,张俊杰,等.年轻群体微信使用的隐私披露行为影响机制研究:隐私犬儒主义的中介效应[J].新闻与传播评论, 2023,76(1):87-101.
[25]ROBINSON L, COTTEN S R, ONO H, et al.Digital Inequalities and Why They Matter[J].Information, Communication amp; Society, 2015,18(5):569-582.
[26]郝大海,王磊.地区差异还是社会结构性差异?——我国居民数字鸿沟现象的多层次模型分析[J].学术论坛, 2014,37(12):88-95.
[27]边燕杰,缪晓雷.论社会网络虚实转换的双重动力[J].社会, 2019,39(6):1-22.
[28]卢家银.社交媒体对青年网民个人信息权意识的影响研究[J].新闻与传播研究, 2018,25(4):17-38.
[29]储节旺,李安.新形势下个人信息隐私保护研究[J].现代情报, 2016,36(11):21-26.
[30]王俊秀,刘洋洋.中国居民隐私安全感的变化及其影响因素——基于年龄—时期—队列分析[J].江苏行政学院学报, 2021(6):67-76.
[31]PAUL DIMAGGIO, et al.From Unequal Access to Differentiated Use: A Literature Review and Agenda for Research on Digital Inequality[Z].Princeton,2003.
[32]邓胜利,王子叶.国外未成年人社交网络隐私行为研究综述[J].信息资源管理学报, 2021,11(4):112-120.
[33]曹高辉,刘畅,任卫强.移动应用情境差异化视角下中老年用户隐私关注影响因素研究[J].信息资源管理学报, 2021,11(6):27-39.
[34]陈云松,范晓光.社会学定量分析中的内生性问题——测估社会互动的因果效应研究综述[J].社会, 2010,30(4):91-117.
[35]SHORROCKS A. Inequality Decomposition by Factor Componets[J].Econometrica, 1982,50(1):193-211.
[36]HECKMAN J. Sample Selection Bias as A Specification Error[J].Econometrica, 1979,47(1):153-161.
[责任编辑:陈 曦 ]
A Research on Online Personal Information Disclosure Factors Based on the Perspective of Social Structure
MIAO Xiaolei
(School of Humanities and Social Science, Xi’an Jiaotong University, Xi’an 710049, Shaanxi)
Abstract: Online personal information is an important resource in the Internet era, and its protection and disclosure are affected by individual mentality, and technological development factors. From the perspective of social structure, the empirical study used data from the 2017 Chinese General Social Survey (CGSS2017). Two main findings are illustrated: first, the disclosure of personal information of Internet users has the highest model contribution, shows significant individual behavioral differences. Second, social structural factors also have a significant impact on the disclosure of personal information. Social strata will increase the level of disclosure of personal information. The increase of age has an inverted U-shaped effect on the disclosure of personal information. The findings support the coexistence of differences in individual behavior and social structure, and respond to the privacy paradox theory. Social class and life course are important factors in explaining the privacy paradox.
Key words: Disclosure of Personal Information;" individual behavior;" Social structure; The privacy paradox
