
结合主动学习与关系图卷积神经网络的社交机器人检测
2023-04-29 14:17:41徐开元周安民陈艾琳代金鞘贾鹏
四川大学学报(自然科学版) 2023年5期
徐开元 周安民 陈艾琳 代金鞘 贾鹏

摘要: 社交机器人一直在应用中不断发展,并且为了逃避现有的检测方法,变得更加先进和复杂,较大地影响了原有部分社交机器人检测方法的效果.检测社交机器人成为了一项漫长而又艰巨的工作.在社交机器人检测领域中,目前存在着已公开相关数据集较少的情况,需要人工标注大量的数据.本文提出了一种结合主动学习与关系图卷积神经网络(RGCN)的检测方法——ALRGCN,用以解决人工标注大量数据成本较高的问题.其主要思路是利用主动学习方法来扩充标记数据集,以最大化人工标注的价值.主动学习利用种子选择算法构建初始训练集以及不确定性采样方法筛选出较高信息熵的样本,交由分类模型进行训练,旨在通过专业人员的经验来人工标注一些分类器难以分类的数据.鉴于社交机器人通常以集群的形式出现,本文引入了RGCN来捕捉其网络结构特征.RGCN可以有效地分析节点及其相邻节点的属性,进而帮助该节点进行分类.实验在TwiBot-20数据集上进行,通过对比进行使用的基线实验,ALRGCN在 F 1上取得了2.83%的提升.实验结果证明,ALRGCN在标注样本更小的情况下可以更有效地检测出社交机器人.
关键词:社交机器人检测; 主动学习; RGCN; 社交网络
中图分类号: TP391 文献标识码:A DOI:10.19907/j.0490-6756.2023.053001
收稿日期: 2022-07-01
基金項目: 四川省科技厅重点研发项目(2021YFG0156)
作者简介: 徐开元(1998-), 男, 硕士研究生, 研究方向为社交机器人检测. E-mail: xuky11@163.com
通讯作者: 周安民.E-mail: zhouanmin@scu.edu.cn
Social bot detection based on active learning and relational graph convolutional neural networks
XU Kai-Yuan, ZHOU An-Min, CHEN Ai-Lin, DAI Jin-Qiao, JIA Peng
(School of Cyber Science and Engineering, Sichuan University, Chengdu 610065, China)
Social bots have been evolving over time, and they have become more advanced and sophisticated while avoiding existing detection methods. This has made some of the original social bot detection methods no longer superior and detecting social bots has become a long and arduous task. The field of social bot detection currently suffers from a small number of publicly available relevant datasets and requires manual annotation of a large amount of data. This paper propose ALRGCN, a detection framework that combines active learning with Relational Graph Convolutional Neural networks (RGCN), to address the problem of high cost of manually labeling large amounts of data. The main idea is to use active learning methods to expand the labeled dataset and maximize the value of manual labeling. Active learning uses a seed selection algorithm to construct an initial training set and an uncertainty sampling method to filter out samples with high information entropy for training by a classification model, aiming at classifying data that are prone to misclassification by a professional's experience. Given that social bots usually appear as clusters, this paper introduces RGCN to capture its network structure features. RGCN can effectively analyze the attributes of a node and its neighboring nodes, which in turn helps that node to perform classification. The experiments are conducted on the TwiBot-20 dataset, and ALRGCN achieves a 2.83% improvement on F 1 compared to the baseline experiments conducted for use. The experimental results demonstrate that ALRGCN can be more effective in detecting social bots with smaller labeled samples.
Social bot detection; Active Learning; RGCN; Social networks
1 引 言
社交机器人是一种人为控制的自动化软件,用于在社交网络中传播各种信息.但是随着应用的发展,这项技术遭到了滥用.社交机器人更多地被用来窃取个人信息,传播错误信息,进而欺骗和操控社交网络上的用户.以往的检测方法从检测账户信息开始,通过账户上所填写的个人信息作为特征,对正常用户账户和社交机器人账户进行分类.而后演变至对账户发布的推文内容及其时间序列进行分析 [1] .但是,社交机器人检测是一个对抗性的过程,社交机器人为了避免现有的检测方法,变得更加先进和复杂.为了增加自己的可信度,社交机器人会对正常的用户进行身份盗窃,抓取正常的个人信息对自己的账户信息进行完善.社交机器人也会学习其他正常用户的动作序列特征,在行为模式上表现也更像正常的用户,而不是像在早期呈现出简单的单一活动规律.现如今社交机器人已经能够发布和正常用户具有类似时间模式的内容,并与正常用户在网络上进行互动 [2] .这些都使得社交机器人检测变得极为复杂,也使得已有的部分检测方法变得不再有效.面对如此迫切的情况,急需要提出新的社交机器人检测方法.
越来越多的研究人员使用大量的已经标记过的数据,利用复杂的神经网络进行分类训练.这种方法存在的问题是,需要使用大量经过专家人员人工标记的样本进行模型训练.一方面,像推特这类在线网络社交平台上存在着难以计数的未标记用户,手工标注大量的样本数据是一项成本高且容易出错的任务.另一方面,如果使用无监督学习,得到的准确率往往很低,并且鲁棒性很差 [3] .
为解决上述存在的问题,本文提出了ALRGCN,这是一种结合主动学习和关系图卷积神经网络(Relational Graph Convolutional Neural networks,RGCN)的检测方法.主动学习通过选择性的标记较少数据,能够以较快速度提升模型的检测效果,一定程度上解决标注成本较大的问题.另一方面,由于社交网络的特殊结构,社交机器人需要关注数以增强自身的影响力进而引导舆情.本文通过使用节点的账户特征和发送的推文作为关系图的节点特征,不同样本实例之间的关注与被关注关系构建图的边,整体构建了RGCN的模型,来同时捕获节点特征和图形结构特征,进而对社交机器人账户和正常用户进行分类.本文的贡献如下.
(1) 提出了一种结合主动学习和RGCN的社交机器人检测方法.ALRGCN通过采样策略筛选出含有较高信息熵的未标记实例,进而由人工进行标注,再加入至RGCN网络的训练集中进行再训练,提高分类的效果.这是目前为止,首次提出在社交机器人检测领域将主动学习和RGCN相结合的方法.
(2) 本文在公开数据集上测试结果,实验表明本文的方法能够在较少标记样本的情况下更有效地出检测社交机器人.
2 相关工作
近年来,社交机器人检测研究方法的主要思路可以分为两种:基于特征提取的社交机器人检测和基于图结构的社交机器人检测.此外,为了解决研究过程中存在的需求样本量大、标记难的问题,本文还引入了主动学习方法.
2.1 基于特征提取的社交机器人检测
早期社交机器人检测中的大部分方法都是在账户级别检测机器人.这类方法为了保证训练得到的精确度较高,需要收集大量的数据进行训练,包括账号信息、活动记录、帖子的内容和情感、网络结构和时间使用模式等内容.
一些学者呼吁研究机器人的一些行为模式,这样的优势在于:行为模式很容易被编码为各种特征,用以学习正常用户和社交机器人行为的差异之处.这样的方法有时也能揭示出机器人行为的一些新的规律.Gong等人 [4] 结合了新引入的时间序列特征和从用户活动中提取的一组常规特征,发现时间序列特征在检测系统中起着至关重要的作用.另外一些学者通过分析账号发布的推文内容,将研究从账号级转入到推文级.转向推文级的检测方法使得训练数据的数量级远大于其他方法,让社交机器人检测问题更易于使用深度学习模型.然而,用于文本分类的传统深度学习技术完全依赖于文本特征进行分类.仅仅使用推文文本并不能很好地预测社交机器人帐户,利用帐户元数据、网络结构信息或时态活动模式等其他特征的组合,可以获得更健壮和准确的结果 [5] .
然而,基于特征提取的社交机器人检测方法也存在着如下的限制:(1) 从账户内容中提取特征是一项费时费力的工作;(2) 特征提取方法并不是通用的,只能检测出特定特征所定义的特定类别的社交机器人.如果提取的特征质量低,分类系统的性能会自动降低.
2.2 基于图结构的社交机器人检测
为了克服基于特征提取方法中的局限性,研究人员尝试基于图划分的方法检测社交机器人.Cao等人 [6] 认为,社交机器人账户存在着与正常用户之间的关注关系,因为他们需要和大量正常的用户进行互动以增强自己的可信程度.然而已有的集群检测方法难以识别出社交机器人用户.
随着卷积神经网络(Convolutional Neural Networks, CNN)的不断发展,研究人员尝试努力将这种风靡的模型用于编码处理图形结构.Kipf [7] 提出的图卷积神经网络考虑了图结构上的谱卷积,能够利用节点的特征并聚合节点邻域的特征,但是其需要计算完整的拉普拉斯图,这样会导致每一层中的单个节点的输出嵌入完全依赖于前一层的所有相邻节点.为了解决上述方法存在的缺陷,Hamilton [8] 提出了Graph Stage节点嵌入算法,Hamilton使用神经网络学习图结构中节点的嵌入,并且可以从节点的领域聚合信息.此后,Alhossein [9] 首次尝试使用图卷积神经网络对社交机器人进行检测,利用账户之间相互的关注关系构建图进而对节点进行分类.Alhossein等人的实验结果验证了使用图结构进行检测的有效性.
互联网中的图数据存在多种节点类型和多种边类型,而图卷积神经网络(Graph Convolutional Network, GCN)难以处理不同类型的边,这对节点分类的效果造成了影响.Schlichtkrull [10] 提出了基于关系图的卷积神经网络模型RGCN.RGCN引入了一个边类型的转换,依赖于边的类型和方向可以更好地处理图数据中多种边类型的情况.Feng [14] 则将RGCN引入到社交机器人检测中,通过从关注和被关注关系构建异构图的边,使用账户的信息和推文作为节点的属性,有效提高了社交机器人检测的精度.
2.3 主动学习
主动学习作为机器学习的一个分支,主要是针对数据标签较少或打标签“代价”较高这一场景而设计的.Settles [11] 的文章详细地介绍了主动学习:“主动学习是机器学习的一个子领域,在统计学领域也叫查询学习或最优实验设计”.主动学习方法能够提高样本及标注的收益,最大化模型的性能,是一种从样本的角度提高模型性能的方案.Wu等人 [12] 提出了一种结合主动学习和深度学习的社交机器人检测方法,使用主动学习方法扩展标记数据,实验结果证明了引入主动学习方法的有效性,但是没有考虑到结合社交网络中的图结构对样本进行分析.
虽然基于图划分的方法克服了基于特征提取方法的部分局限性,但是这两种方法都存在着如下的缺点:首先,为了保证检测能有较高的精度,需要获取大量的已标记数据进行训练.然而在实际的业务场景或者生产环境中,获得大规模的数据样本的成本很高.其次,目前缺少统一的标注标准,不同人员对相同数据的标注也可能存在着偏见.总之,手工标注样本需要丰富的经验支持和大量的时间成本.如何通过较少人工成本来获得较大价值的标注数据,进一步地提升算法的效果就成为了值得思考的问题.综合考虑之下,本文在基于图划分的方法中引入主动学习模块,构建了ALRGCN的整体框架.
3 研究方法
为了解决社交机器人检测领域中存在的已标记数据集较少的问题,本文结合社交网络的结构特征,提出了基于主动学习和关系图神经网络相结合的ALRGCN检测框架.ALRGCN有三个关键的组成部分,分别为主动学习、特征编码与组合、关系图卷积神经网络训练算法.在本节内容中,依次介绍ALRGCN的三个组成部分,并对本文研究过程中使用的方法进行说明.
3.1 主动学习过程
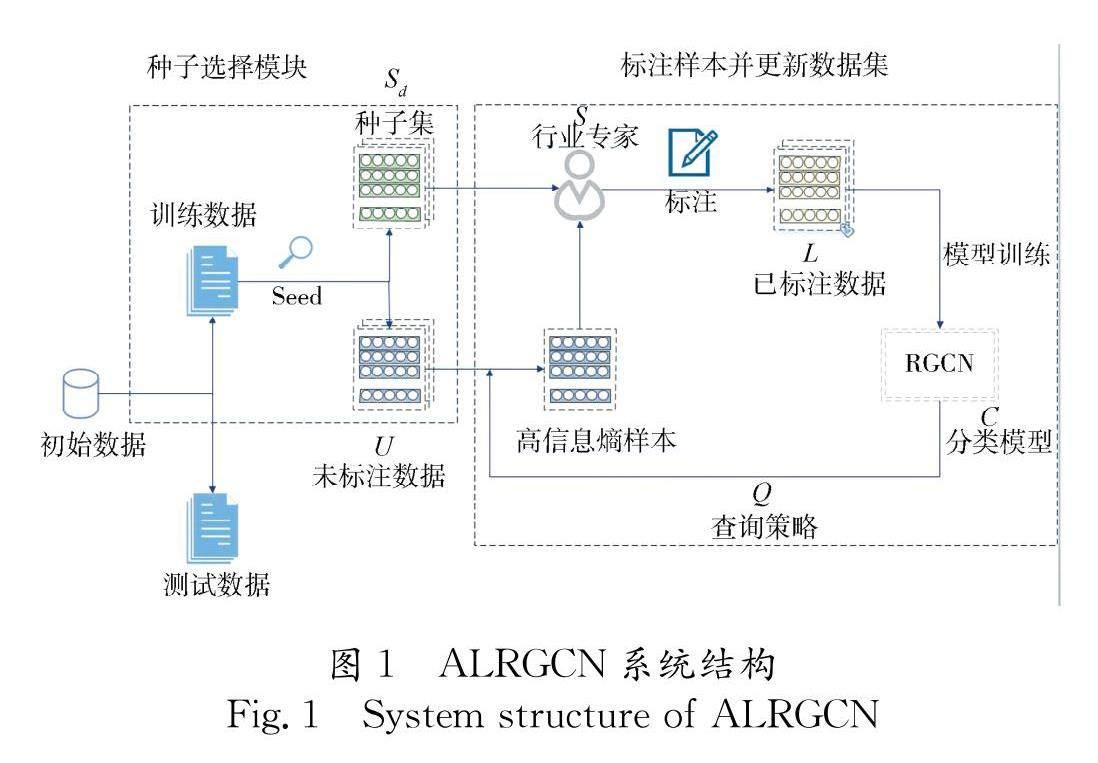
在进行分类任务的建模过程中,通常包括有样本选择、模型训练、模型预测和模型更新等4个步骤.本文则将主动学习领域中的标注候选集提取和人工标注这两个步骤加入整体流程.ALRGCN中主动学习流程的框架如图1所示.
图1中包含有:Seed表示种子选择算法,将初始的训练集划分为 U 和 S d 两部分; U 表示训练集中不需标注的部分; S d 表示初始未标注训练集,依赖于种子选择算法构成,包含训练集中一些最具代表性的实例; S 表示依赖于专家经验对未标记的数据进行标记; L 表示进行标注过后的训练集,由两部分组成:第一部分由 S d 经过标记后得到,作为初始模型的训练集.第二部分则是在每次训练的迭代过程中,分类器选取 U 中不确定性最高的样本,将其人工标注后加入到 L 中,利用主动学习更新的标记数据对RGCN进行再训练; Q 表示查询策略,从 U 中通过采样方法获得更有价值的样本数据; C 表示本文使用的RGCN模型,其中包含有模型的训练和预测两部分.
主动学习算法用于进行账号种子选择以及标记和更新数据集中.首先,在关系图卷积神经网络训练开始之前,主动学习算法通过种子选择算法创建初始的未标记数据集 S d .其次,在RGCN进行训练的迭代过程中,主动学习使用基于信息熵的不确定性采样的方法选取熵较大的样本实例进行标注后更新标记数据集 L . 接下来,对主动学习的这两个部分进行说明.
(1) 种子选择算法.常见的神经网络通过给人为的给定数据的索引来划分生成初始的训练集和测试集.通过这种类似于随机选择的方法得到的训练集,训练数据不具有一定的代表性和多样性,可能会使模型训练得到的准确度较低 [13] .本文使用种子选择算法来生成初始的标记数据集 L ,以此来提升模型的精度.
如图2所示,图2中的每个圆表示一个样本实例,黑线表示进行分类的决策边界. A 更加远离决策边界,这将被认为是最具有代表性的.但是,查询 B 会得到更多关于整个数据分布的信息,更能得到某类数据的一些划分特征.本文使用基于密度权重的代表性采样策略,在使用代表性采样策略的时候,将样本数据的稠密性考虑进去.如式(1)所示.
I(u)= argmax φ(u)·( 1 k ∑ k i=1 sim (u,v i)) (1)
其中, φ(u) 表示使用的代表性采样策略; k 表示类别的个数; v i 表示分类簇中某类元素中的一个具有代表性的元素;sim是用以计算信息密度的函数,计算得到的信息密度结果越高,给定的元素实例和其余的数据就越相似,即数据更为稠密.
信息密度的计算方法如式(2)所示.
sim (x,y)= 1 d+1 = 1 ∑ n i=1 (x i-y i) 2 +1 (2)
此处 d 为欧几里德距离.通过计算各个节点的基于信息密度的代表性,再进行排序.在每个分类簇中按比例选取样本,得到的样本集合作为初始未标注训练集 S d .
(2) 标注和更新样本.在获得初始未标注训练集 S d 后还需要利用专业人员的经验对 S d 中的样本进行标注,得到初始训练数据集 L ,此后对RGCN模型进行初始训练.而后在RGCN每次训练的迭代过程中,使用不确定性采样策略从 U 筛选出最高不确定性的样本实例对其标注,用于更新标记的训练数据集 L .
基于不确定性的采样策略将模型中难以区分的样本数据提取出来,提供给专业标注人员进行标 注,从而达到以较快速度提升算法效果的能力.不确定性采样方法的关键就是如何描述样本或者数据的不确定性.由于社交机器人检测是一个传统的二分类问题,可以选择信息熵较大的样本数据作为待定标注数据.信息熵的计算方法如式(3)所示.
H(u)= arg max u-∑ i P θ(v i|u)· ln P θ(v i|u) (3)
通过排序,可以得到含有较高信息熵的样本.由于本文使用的样本具有真实的标签,通过查询使用真实样本标签对上述这些通过信息熵选出的样本进行标注,以减少人为标注对于实验检测结果的影响.通过上述的标注步骤后,在每次迭代的过程中,将标注好的数据添加到已标注的训练集 L 中,构成新的训练数据集 L .
3.1 特征编码与组合
受到BotRGCN [14] 的启发,本文从内容特征、账户特征和相邻特征等三个方面形成样本的综合描述.接下来,对这三个方面进行如下说明.
(1) 内容特征: Dickerson [15] 提出可以通过研究账户发送的推文中含有的情感内容来提高社交机器人检测模型的预测精度.本文使用预训练模型RoBERTa对用户的所有推文进行编码,将通过训练得到的向量,作为用户推文文本的整体特征.
RoBERTa是一种预训练语言模型,具有对未标记文本数据进行预处理的能力,提供了每条推文文本的丰富特征表示 [16] 对于每个Tweet文本的词,本文使用了基于大型文本语料库的预训练语言模型进行编码表示.如式(4)所示.
P content =φ( 1 L n ∑ L n i=1 ∑ L t j=1 RoBERTa (w j)) (4)
其中, L n 为每个检测样本所发布的推文总数; L t 为每条推文所含有的单词个数; w j 为每条推文中的每个单词; φ 是优化函数.
(2) 账号特征: 从用户的个人信息中直接进行提取, 包括用户的关注者数量和被关注者数量等数值特征,也包括发布的个人简介、说明等含有文本信息的内容.本文同样使用RoBERTa模型对于其中的文本信息进行处理得到向量,而后拼接其中的数值特征,整体部分作为用户账号特征的向量表示.
对于个人信息中的简介等文本特征,同样使用RoBERTa进行编码得到向量.如式(5)所示.
P profile =φ( 1 L n ∑ L n i=1 ∑ L t j=1 RoBERTa (a j)) (5)
其中, L n 为每个检测样本中含有的文本内容的总数; L t 为每条文本内容中所含有的单词个数; a j 为每条文本内容中的每个单词.考虑到社交机器人账户在引导舆论时,常常会发表和自己个人资料并不符合的内容,为了检测这种现象,需要计算出个人资料和发送推文的相关程度.本文使用哈达玛积来计算用户推文和用户个人资料的关联程度,并将其作为用户的另一个新的特征.计算过程如式(6)、式(7)所示.
P content ′ =P content ⊙P profile (6)
P profile ′ = Concat ((P content P profile ), num ) (7)
此处的⊙表示哈达玛积乘法;表示矩阵加法.之后对于账号中的数值特征num,将其与得到的账号信息的向量拼接.
(3)相邻特征: RGCN需要使用一个节点与相邻节点之间的关注关系和被关注关系构建图结构.使用相邻节点的内容特征和账号特征构建向量,并将所有相邻节点的向量拼接,形成一个完整的向量.从而对自身节点的判断提供支持.
3.2 关系图卷积神经网络训练算法
模型的主体框架如图3所示.和传统的图卷积神经网络相比,RGCN最大的区别在于处理边的种类,依赖边的类型和方向来构建图,解决了利用GCN处理图结构中不同边关系对节点分类结果产生影响的问题.
在RGCN中,节点的更新方式如式(8)所示.
h (l+1) i=σ(∑ r∈R ∑ j∈N r i 1 c i,r W (l) rh (l) j+W (l) 0 h (l) i)
(8)
其中, N i r 表示节点 u i 的关系为 r 的相邻节点集合; c i,r 是一个正则化常量,其中 c i,r 的取值为 |N i r| , W r (l) 是线性转化函数,将同类型边的邻居节点,使用一个参数矩阵 W r (l) 进行转化, W r (l) 的个数也就是边类型的个数; h (l) i 标识的是节点 u i 的第 l 层节点表示; h (l) j 则是节点 u i 的所有邻居节点的第 l 层节点表示.
在本文的网络结构中,使用关注和被关注的关系作为节点之间边的属性,来构建异构图,而后使用第3.4节中得到的特征作为网络训练的初始向量,训练的结果通过softmax层进行分类.
P={P content′ ,P profile′ } (9)
R i= softmax (φ(P)) (10)
整体的网络结构使用损失函数进行优化.损失函数如式(11)所示.
Loss=-∑ m i=1 (R ilog(R i)+(1-R i)log(1-R i)) (11)
4 实验及评价
本文评估了所提出的ALRGCN检测框架的性能.首先,对于工作中的实验设置进行描述.其次,进行了实验以验证本文提出的模型在检测社交机器人方面的有效性与优越性.最后,对于本文工作中使用的主动学习的有效性进行评估.
4.1 实验设置
4.1.1 数据集 由于训练数据集获取较难、标注成本较大,社交机器人检测领域中一直缺乏具有多样性的、数据丰富的数据集.本文使用了在2021年提出的 TwiBot-20 [17] 数据集,这是目前已知的,唯一的已公开的、含有用户关注关系以及大量文本内容的数据集.该数据集中含有总计229 573个推特账户,包括他们发布的33 488 192条推文、 8 723 736 个用户属性项以及455 958个关注关系.每条数据中包含有推文、资料、关注关系三个方面的总共42个初始字段.
4.1.2 评价指标 本文采用模型精度、召回率和 F 1值 作为评价指标,这些评价指标可以通过式(12)~式(14)计算.通过使用这些指标来判断一个模型能否有效的检测出社交机器人.
Precision = TP TP+FP (12)
Recall = TP TP+FN (13)
F1 -measure=2× Precision×Recall Precision+Recall (14)
其中, TP 表示被正确预测为社交机器人的用户数; FP 表示被错误预测为社交机器人的正常用户数; FN 表示被错误地预测为普通用户的社交机器人的数量.
4.2 实验结果与分析
本文共进行了三个部分的实验.实验1评估了本文提出的ALRGCN检测方法的性能,将ALRGCN与设置的基线实验的结果进行对比,验证了ALRGCN整体模型在社交机器人检测中的优越性.实验2通过修改初始训练集大小,分析ALRGCN在不同大小训练集的情况下的分类性能,验证主动学习可以通过选择尽可能少的高质量标注样本使模型达到尽可能好的性能.实验3则是在基线实验的基础上引入了主动学习,目的是为了探讨引入主动学习方法的有效性.
4.2.1 对比实验 在本实验中,ALRGCN算法的训练集是通过3.1.1节中的种子选择算法得出.实验优化器使用AdamW,dropout设置为0.3,学习率为10 -3 ,节点向量维度为128,权重衰减项为5·10 -3 ,迭代次数设置为120.初始的训练集大小设定为整个数据集大小的20%,在每次训练迭代中,根据信息熵采样,每次选择10个测试集中的样本使用其真实的样本标签进行标记,并将标注好的样本添加至训练集中.本文使用了一系列的检测社交机器人的方法作为基线实验对提出的ALRGCN算法的效果进行评估.
在对比实验中使用所有数据的80%作为训练集,剩余部分作为测试集.每个方法进行40次重复试验取其平均值得到其结果.实验得到的结果表1所示.
结果证明,本文提出的ALRGCN方法在TwiBot-20数据集上取得了明显的进步.ALRGCN算法的精度可以达到89.86%,优于进行对比所使用的基线.同样的,对比原使用的BOTRGCN模型,实验结果在精度和 F 1上均获得了一定的提升,精度提升接近5%, F 1提升接近3%.由于ALRGCN充分利用了主动学习选择的高信息熵实例,再经过人工的标注,减少了异常值的出现频率并减缓了模型训练迭代过程中的噪声积累问题,使得分类器的性能在迭代过程中不断提高,并提升了最终的模型性能.而在实验样本的行动逻辑更为复杂、行动模式表现得更像人类正常用户的行为模式时,其他算法的检测性能可能会下降,而主动学习算法可以借助相关人员的专业经验,对相关数据进行标注,对于模型性能反而可能会有更为明显的提升.在有限标记实例的情况下,ALRGCN能够使用更小的标记样本更加有效地检测出社交机器人.
4.2.2 参数评估实验 本文分析ALRGCN中初始训练集 L 的大小对模型的分类性能产生的影响,以验证主动学习能够通过选择尽可能少的、高质量的样本标注使模型达到尽可能好的性能.
折线图4描述了初始标记数据集对ALRGCN分类性能的影响.在将初始 L 从200到3000的过程中, F 1值以较快的速度得到提升,并且能够快速接近模型分类能达到的最佳值.这是由于本文在使用种子选择算法中使用基于密度权重的代表性采样策略,使得模型在训练的过程中可以快速提取到正常用户和社交机器人之间的代表性的特征并学习两者之间的差异,使得模型的分类性能随着初始标记数据集 L 大小的提升获得了较快的提升.召回率和精度的波动则是因为每个实验中通过主动学习选择的普通用户和社交机器人的数量分布不同造成的.
图3也能说明ALRGCN具有较强的学习能力,在只需要较少初始标记实例的情况下就可以获得与使用大量初始标记实例进行 训练后相同的性能.由于 L 相对于数据集的大小来说规模非常小,因而可以得出结论:ALRGCN使用主动学习在一定程度上缓解了人工标注数据较为困难、成本大的问题.
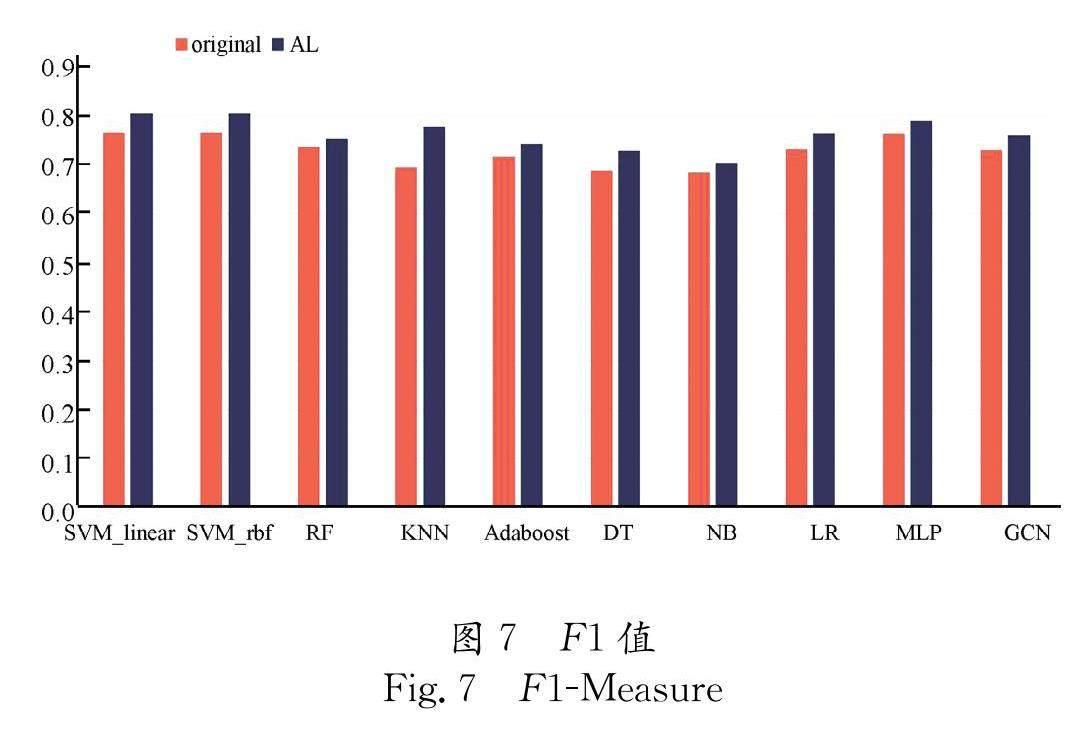
4.2.3 评估主动学习的有效性 为了进一步验证所提出的主动学习结合关系图卷积神经网络模型的有效性,本文在基线检测方法的基础上加入主动学习,来比较处理前后的分类器性能.本文在主动学习的过程中,使用种子选择算法得到初始的标记训练集 L .此外,在每次训练的迭代过程中,使用样本的真实标签对由不确定性采 样筛选出的高信息熵样本进行标记.同样,设置的初始标记训练集大小为整个数据集的20%,每组实验都独立重复了40次,最后的结果进行平均.实验结果如图5~图7所示.
结果显示,朴素贝叶斯(Naive Bayes,NB)的实验精度略有下降,这可能是因为NB要求样本属性之间相互独立,这个假设在社交机器人检测中往往是不成立的,因而会使得检测的精度降低.而在大多数的分类模型下,使用主动学习后都提升了模型的准确率.另外,使用主动学习后各个模型的召回率和 F 1均得到了一定程度的提升,这是因为在进行基线实验不使用主动学习的情况下,往往是通过比例按照数据的下标来划分训练集与测试集,这样的方法接近于随机选择,造成了数据的不平衡分布,使得不能很好地捕捉到一些具有代表性的社交机器人账户的特征.这就导致社交机器人的检测性能不佳,召回率较低.主动学习算法则是通过种子选择算法和选择具有较高信息熵的代表性实例进行人工标注后再训练,使得模型能更好地学习到正常用户和社交机器人之间的代表性的特征,并且一定程度上减缓了数据分布不平衡的问题,大大提高了召回率,进而增加了 F 1值,使得最终模型的分类效果获得了一定提升.通过对实验结果的分析,可以得到:结合主动学习算法用以提升模型检测性能的方法是有效的.
5 结 论
本文提出了一种结合主动学习和RGCN的社交机器人检测方法.这是目前为止,首次在社交机器人检测领域提出将主动学习和RGCN相结合的方法.本文使用种子选择算法构建初始训练集、在每一次的迭代过程中筛选信息熵较大的样本实例进行人工标注、并通过RGCN进行训练.实验结果表明,ALRGCN可以显著提高标注用户数据的效率,可以有效地检测社交机器人,与其他常用的检测方法相比,具有更好的性能.
然而,本文研究还有待进一步的改进.本文使用预训练模型对文本内容进行编码.但是由于相关数据集的缺失,难以利用样本的时态活动模式等其他特性来结合文本内容进行一个整体的分析.未来考虑在含有时态活动模式等的数据集上尝试使用其他模型,用以揭示社交机器人的一些行动规律.
参考文献:
[1] Kudugunta S, Ferrara E. Deep neural networks for bot detection [J]. Inform Sciences, 2018, 467: 312.
[2] Cresci S, Di Pietro R, Petrocchi M, et al . The paradigm-shift of social spambots: Evidence, theories, and tools for the arms race [C]//Proceedings of the 26th International Conference on world Wide Web Companion. Perth, Australia:WWW, 2017: 963.
[3] Li Z, Zhang X, Shen H, et al . A semi-supervised framework for social spammer detection [C]//Pacific-Asia Conference on Knowledge Discovery and Data Mining. Cham: Springer, 2015: 177.
[4] Gong Q, Chen Y, He X, et al . DeepScan: exploiting deep learning for malicious account detection in location-based social networks[J]. IEEE Commun Mag, 2018, 56: 21.
[5] Fazil M, Sah A K, Abulaish M. DeepSBD: a deep neural network model with attention mechanism for socialbot detection[J]. IEEE T Inf Foren Sec, 2021, 16: 4211.
[6] Cao Q, Sirivianos M, Yang X, et al . Aiding the detection of fake accounts in large scale social online services [C]// Proceedings of the 9th USENIX Symposium on Networked Systems Design and Implementation.San Jose, CA:USENIX Association,2012: 197.
[7] Kipf T N, Welling M. Semi-supervised classification with graph convolutional networks[EB/OL].[2022-05-20]. https://arxiv.org/pdf/1609.02907.pdf.
[8] Hamilton W L, Ying R, Leskovec J. Representation learning on graphs: methods and applications[EB/OL].[2022-05-20].https://arxiv.org/abs/1709.05584v2.
[9] Ali Alhosseini S, Bin Tareaf R, Najafi P, et al. Detect me if you can: spam bot detection using inductive representation learning [C]//Companion Proceedings of the 2019 World Wide Web Conference. San Francisco, USA:Association for Computing Machinery, 2019: 148.
[10] Schlichtkrull M, Kipf T N, Bloem P, et al . Modeling relational data with graph convolutional networks[C]//European Semantic Web Conference. Cham: Springer, 2018: 593.
[11] Settles B. Active learning literature survey [J]. Madison, USA:University of Wisconsinmadison, 2010.
[12] Wu Y, Fang Y, Shang S, et al . A novel framework for detecting social bots with deep neural networks and active learning [J]. Knowl-Based Syst, 2021, 211: 106525.
[13] Zhang X, Bai H, Liang W. A social spam detection framework via semi-supervised learning [C]//Pacific-Asia Conference on Knowledge Discovery and Data Mining. Cham: Springer, 2016: 214.
[14] Feng S, Wan H, Wang N, et al . BotRGCN: twitter bot detection with relational graph convolutional networks [C]//Proceedings of the 2021 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining. Netherlands:Association for Computing Machinery, 2021: 236.
[15] Dickerson J P, Kagan V, Subrahmanian V S. Using sentiment to detect bots on twitter: Are humans more opinionated than bots?[C]// Proceedings of the 2014 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2014). Beijing, China:IEEE, 2014: 620.
[16] Feng S, Wan H, Wang N, et al . Twibot-20: a comprehensive twitter bot detection benchmark[C]//Proceedings of the 30th ACM International Conference on Information & Knowledge Management. Queensland, Australia:Association for Computing Machinery, 2021: 4485.
[17] Yuan X, Schuchard R J, Crooks A T. Examining emergent communities and social bots within the polarized online vaccination debate in Twitter [J]. Social Media+ Society, 2019, 5: 2056305119865465.
[18] Stukal D, Sanovich S, Bonneau R, et al . Detecting bots on Russian political Twitter[J]. Big Data, 2017, 5: 310.
[19] Fu H, Xie X, Rui Y. Leveraging careful microblog users for spammer detection [C]//Proceedings of the 24th International Conference on World Wide Web. New York,USA:Association for Computing Machinery, 2015: 419.
[20] Yang K C, Varol O, Hui P M, et al . Scalable and generalizable social bot detection through data selection [C]//Proceedings of the AAAI Conference on Artificial Intelligence. [S.l.]:AAAI,2020, 34: 1096.
[21] Ellaky Z, Benabbou F, Ouahabi S, et al . Word embedding for social bot detection systems [C]// Proceedings of the 2021 5th International Conference on Intelligent Computing in Data Sciences (ICDS).Fez, Morocco: IEEE, 2021: 1.
[22] Battur R, Yaligar N. Twitter bot detection using machine learning algorithms [J]. Int Sci Res (IJSR), 2018, 8: 304.
[23] Liu L, Jia K. Detecting spam in chinese microblogs-a study on sina weibo [C]//Proceedings of 8th International Conference on Computational Intelligence and Security. Guangzhou, China: IEEE, 2012: 578.
[24] Park S, Lee K. The gravy value: a set of features for pinpointing bot detection method [C]// Proceedings of theInternational Conference on Information Security Applications. Cham:Springer, 2020: 142.
猜你喜欢
东方教育(2016年16期)2016-11-25 03:06:31
化学教与学(2016年10期)2016-11-16 13:29:16
电脑知识与技术(2016年24期)2016-11-14 00:32:08
人间(2016年28期)2016-11-10 22:12:11
计算机教育(2016年7期)2016-11-10 08:44:58
企业导报(2016年20期)2016-11-05 18:53:13
戏剧之家(2016年19期)2016-10-31 19:44:28
新闻前哨(2016年10期)2016-10-31 17:46:44
课程教育研究·学法教法研究(2016年21期)2016-10-20 19:07:31
科技视界(2016年21期)2016-10-17 18:35:21
