
基于深度学习的地层沉积正演模拟代理模型构建与应用
2023-04-29 00:44:03刘彦锋段太忠龚伟廉培庆张文彪黄渊
沉积学报 2023年3期
刘彦锋 段太忠 龚伟 廉培庆 张文彪 黄渊

关键词 生成对抗神经网络;代理模型;深度学习;地层沉积过程正演模拟
0 引言
地层沉积过程正演模拟比传统的基于统计学的建模能更真实地刻画地下地质体的分布规律,但条件化方面仍需改善。地层沉积过程正演模拟以质量守恒为基础,考虑了沉积物的供给、产生、搬运、剥蚀和再沉积等地质作用,模拟结果符合地质规律[1]。正演模拟的输入参数有初始地形、海平面曲线、沉积物搬运系数、沉积物供给曲线、基底沉降曲线、碳酸盐岩生产的相关系数,以及这些系数随时间和空间的变化等[2]。由于这些输入参数很难通过现有的观测手段获得,使得模型存在较大不确定性,与井数据和地震解释数据吻合难度大,导致该建模技术在实际油藏地质建模中应用推广缓慢。
地层沉积反演模拟技术提高了地层沉积过程模拟的实用性。Lessenger et al.[3],Cross et al.[4]提出了地层沉积反演模拟的基本框架,认为地层沉积反演模拟包括地层沉积正演、模拟结果和观测数据之间的比较,以及自动调整正演参数的最优化算法。基本思路是:以有限的、能反映地层分布特征的观测数据,比如井上钻遇的沉积微相、地震层位解释等,反推地层沉积正演模拟的输入参数,实现模拟结果与观测数据吻合,然后进行地层空间展布的预测。地层沉积模拟的基本过程是从一组初始的过程参数开始执行正演模拟,将模拟结果与观测数据比较,优化算法按照一定的策略调整过程参数,再次执行正演模拟,直到模拟结果与观测数据的吻合度达到门槛值。前人在这些方面做了很多研究,涵盖正演模拟技术、比较技术和优化算法等[5?11]。
在反演系统中,通常正演模拟的计算量很大,是最耗时的计算部分。代理模型是工程问题中常用的一个优化方法。当实际问题计算量很大、不容易求解时,可以使用计算量较小、求解速度快的代理模型替代原模型,加速优化过程,比如多项式法、二次响应曲面和克里金方法等。尽管代理模型是复杂系统反演的常见处理方式[12?13],但针对沉积模拟代理模型的相关研究未见报道。
与油气藏渗流、地下水流动、数值天气预报等模型类似,地层沉积反演模拟也是一个复杂的非线性系统,本质上求解这些复杂系统都是大规模高度非线性问题的优化问题,需要借助高效的优化算法反复进行迭代求解,其中单次正演模拟求解耗时长、非线性强是影响问题快速求解的主要瓶颈。对于这类问题,代理模型是用另外一种更快的数学方法产生与原模型误差最小的结果,以达到快速迭代。目前,已经有一些替代正演模拟的方法,这些模型替代非线性较弱的模型时效果较好,对复杂性强的模型仍无法替代[14],深度神经网络具有很强的模式表达能力,为代理模型构建提供了新的途径,也为快速的地层沉积反演模拟提供了可能。
最近几年发展迅速的生成对抗人工神经网络方法具有很强的模型生成能力,已经用于模拟复杂地质模型的生成和油气藏数值模拟中替代模型的建立。神经网络主要分为判别网络和生成网络,判别网络建立高维参数向低维参数的映射,常用于分类、聚类和判别问题等;生成网络建立低维参数向高维参数的映射,常用于回归和模型生成问题。复杂三维地质建模可以通过生成网络实现。常见的生成网络有贝叶斯网络、变分自编码器、玻尔兹曼机、生成对抗网络等,其中生成对抗网络的应用最广泛。
相比于其他方法,生成对抗网络具有更强的模式生成能力,可以生成更逼真的模型,但存在样本需求量的问题,不适合样本少的情况。对于地下地质类问题,难以获取真实的三维模型作为样本,通过正演模拟方法合成样本是深度学习技术在该领域落地应用的主要方式。在沉积反演模拟系统中,样本通过正演模拟器生成,不存在样本不足的问题。使用生成对抗网络,有望提高反演的收敛速度,解决目前的效率问题。
本文在地层沉积反演模拟基本框架、生成对抗网络基本原理介绍的基础上,提出了基于生成对抗网络的地层沉积代理模型构建方法,并通过实例研究说明该方法的可行性,最后讨论了该方法存在的局限性和未来发展的方向。
1 生成对抗网络代理模型构建方法
1.1 地层沉积反演模拟基本框架
地层沉积反演模拟包括生成三维模型的正演模拟器、模拟结果与观测数据比较的误差计算器,调整正演模拟输入参数的全局优化器。优化器是整个系统的核心驱动力,它根据误差计算器的响应不断调整正演模拟输入的参数,使模拟结果与观测数据吻合度最高。
地层正演模型的输入参数考虑了边界条件和初始条件,它们描述了可容空间、沉积物剥蚀、供给、生产、搬运、堆积以及压实作用等。输出结果是模拟的地层和一系列的古环境条件,比如整个演化历程的古地貌、沉积间断等。区别于碎屑岩地层,碳酸盐岩沉积体系的形成、演化和消亡,除了受构造活动、海平面变化、气候条件、海洋环境和水动力条件等多种作用于碎屑岩沉积体系的共同因素的直接或间接的控制外,还受体系中生物与生态因素的重要控制[15?17]。此次采用了自主研发的碳酸盐岩地层沉积正演模拟方法,它考虑了最新的碳酸盐岩工厂、生态可容空间和层序地层学等基本原理,建立了基于环境能量和生物碳酸盐产能的地层沉积正演模拟方法和软件系统,可以模拟台缘带、缓坡、孤立台地以及复杂地形下的碳酸盐岩沉积体系等[18],限于篇幅问题,具体的正演模拟方法不再展开。
模拟结果与观测数据的比较方法依赖于观测数据的多少及类型,往往是较少的观测资料,比如少量的几口钻井资料、分辨率较低的地震解释资料等。为了降低地震资料引起的不确定性,本文选择井上的解释的沉积相与实际模拟的过井处沉积相的均方根误差作为反演的目标函数。对于复杂非线性且不可求导的非线性系统,需要采用启发式优化算法,比如模拟退火、差异演化、粒子群算法等,通过多参数下的优化算法收敛性能对比,基于数值梯度的复合多重形优化算法(SCE-UA)在多参数反演方面具备更多优势[19]。
由于整个地层沉积反演模拟系统非线性极强,收敛难度大,需要的迭代次数很多,导致效率较低。提出了基于生成对抗网络沉积模拟代理模型构建方法,替代其中的正演模拟过程,充分利用神经网络全程可微分的性质,提高整个反演系统的收敛性能。
1.2 生成对抗神经网络方法
生成对抗神经网络为地质建模提供了新方法。随着深度学习等人工智能技术的发展,地质建模技术也朝着智能化方向快速发展。由于生成神经网络与地质建模之间的高度相似性,这项技术在地质建模领域快速落地应用。在多层神经网络框架下,地质建模是一个生成问题,油气藏地质建模通常是输入稀疏的、高精度的井点数据,在稠密的、相对低精度的地震数据约束条件下建立高精度三维网格模型,可以视为生成神经网络问题,其中由Goodfellow et al.[20]提出的生成对抗神经网络(Generative Adversarial Networks,GAN)是解决这类问题的主要方式。
生成对抗网络是一种适用于任意形式复杂分布的无监督对抗式深度学习方法。它一般由两个模块构成:生成模型(Generative Model,简写为G)和判别模型(Discriminative Model,简写为D)组成,生成模型也称为生成器,判别模型也称为判别器。生成模型G根据一系列特征,可以是数值或者字符串等,来生成一组数据,生成的数据可以是图片、影像、声音等,也可以是地质模型。生成的数据和真实数据相比要尽可能相似。判别模型D判断生成模型输出的结果是否和真实数据相似,其目标是将生成数据和真实数据尽可能分开。G和D两个模型在对抗性训练中共同进步,G生成的数据越来越逼真,D的辨别能力越来越强。GAN训练终止的条件和一般的网络有所区别,并非以损失函数达到某一阈值作为终止条件,而是人工判断生成模型的结果逼真程度是否还在持续改善。如果持续多轮迭代不再改善则终止训练。
生成对抗网络是目前深度学习地质建模中主要采用的神经网络[21],为替代模型建立提供了新途径。对于标准的生成对抗网络,需要输入一个低维的随机数序列得到高维的网络层,与非条件地质建模过程较为相似,即通过变差函数、训练图像或目标体长宽高等输入参数得到一系列三维模型实现,这些实现不考虑与井点数据或地震约束数据的吻合情况,但能够体现较为合理的地质模式。生成对抗网络深度学习体现了类似过程,通过学习地质模式,利用训练后的生成器可以得到满足地质认识的模拟结果。由于神经网络固有的线性化性质,按照这种方式建立的代理模型,具备更好的反向求导和快速收敛特征。
1.3 基于生成对抗网络的代理模型构建方法
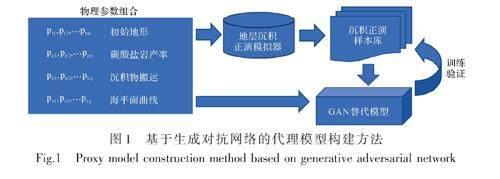
深度学习模型的训练需要大量的样本,不断扰动沉积正演模拟器的输入参数,可以获得大规模沉积模拟模型作为深度学习的样本。沉积模拟的输入包括初始地形、碳酸盐岩产率、沉积物搬运、海平面曲线、构造沉降等相关参数,改变任意的输入参数都可能产生不同的结果。采用生成对抗神经网络框架进行训练,其中生成器接收与沉积模拟一样的输入参数,产生二维或三维模拟结果,判别器输入二维或三维模型,输出真或假,其中训练后的生成器即为最终需要的沉积模拟代理模型(图1)。具体构建步骤如下。
步骤一:分析具体的地质问题,搭建反演模拟基本框架。根据钻井和地震解释的地层特征,结合区域地质特征,确定目标地区可能的地层特征和沉积相展布规律。通过反复的正演模拟测试,确定初始地形和构造沉降的基本特征,以及沉积物搬运、碳酸盐岩产率、水体能量相关参数的数值区间,为样本生成提供基础。
步骤二:基于沉积正演模拟器生产大规模样本。选择对模拟结果敏感的参数,且尽量涵盖更大的解空间,通过超立方采样的方式,产生不同的参数组合,开展正演模拟,建立样本库。一个样本包括输入的参数和正演模拟的结果,其中模拟结果是二维或三维的相模型,通过离散数值(比如a1、b1、b2、c1、c2、c3,c4共7种相类型)的矩阵表达。随机选择其中的80%作为训练集,20%作为测试集。
步骤三:基于生成对抗网络的代理模型构建。根据样本数据特征及生成对抗网络的要求设计生成网络和判别网络的结构,为了更好地捕捉地质模式并增加效率,采用全卷积式网络,即网络的核心处理单元均采用卷积和转置卷积层,每个卷积层和转置卷积层配套标准化层和非线性层,不采用全连接层。在训练集上对网络进行训练,在测试集上对训练后的生成器和判别器进行测试,如果生成器或判别器的效果不再改进,则停止训练。如果训练后网络无法生成合理的地质模型则调整网络结构,甚至回到步骤二生成更多的样本,直到生成器满足要求。
步骤四:基于深度学习代理模型的地层沉积反演模拟。将步骤三训练得到的代理模型(即对抗神经网络中的生成器)带入地层沉积反演模拟系统,以计算结果与观测数据的误差最小为目标,采用全局优化器不断调整代理模型的输入参数,直到得到最优结果。将反演得到的最优参数带入代理模型,得到最终的地质模型。
地层沉积正演模拟器有很强的灵活性。理论上,可以构建代表任意参数个数和参数区间的代理模型,但它需要样本太多、网络的深度也太大,训练难度大,甚至不可能。但是,针对一定的情况,参数空间会大大减小,需要的样本也会减少。针对常见的几种碳酸盐岩沉积环境类型,比如斜坡、镶边台地、孤立台地等类型,可以训练出有针对性、同时又不失一般性的神经网络代理模型。下面将以巴哈马滩碳酸盐岩沉积为例,介绍地层沉积模拟代理模型构建方法及其在反演模拟系统中的应用。
2 实例应用
2.1 巴哈马滩反演模型基本框架搭建
巴哈马滩是国内外研究碳酸盐岩地层沉积的热点地区,在其西缘斜坡有几口科学钻探井和实测的地震剖面,前人在该地区开展了大量研究[22?24]。台地整体形态、初始地形、构造沉降速度、沉积演化过程等都有比较清楚的认识,也有沉积过程定量模拟的相关研究,但都侧重于沉积过程的控制因素分析,缺少精细的沉积过程建模研究。结合地质分析和前人研究成果[25?26],用地层沉积正演的方法检测地区地震解释剖面,初步获取该地区碳酸盐岩海平面变化、构造沉降、碳酸盐岩产率等参数,搭建了该地区的地层沉积过程模拟基本框架。沉积模拟范围为32 km×32 km,时间跨度为5.3 Ma,平面网格数为129×129,总时间步数为100。
通过正演模拟的参数尝试,获取了主要参数的分布区间,为生成大量样本和代理模型构建奠定了基础。地层沉积正演模拟要输入的参数有初始地形、构造沉降、海平面变化曲线、碳酸盐岩产率相关参数、沉积物搬运参数等34个。根据对该地区前期的资料分析认为初始地形和构造沉降的不确定性较低,而海平面曲线、碳酸盐岩产率和沉积物搬运的相关参数不确定性较大,建立反演模拟系统时确定性较强的参数给了较小的变化区间,不确定性较大的参数给了较大的变化区间(表1)。这34个参数中,第1~4个参数与初始地形有关(沿着斜坡方向均匀分布的个4点,用来插值生成初始地形),第5~11个参数与海平面曲线有关(分别是表示三级和四级海平面旋回的正弦函数的振幅、周期和相位,以及海平面基准值),第12~16个参数与构造沉降有关(沿着斜坡方向均匀分布的4个点,用来插值生成构造沉降面),第17~20个参数与沉积物搬运有关(分别是势能和动能在X和Y方向的搬运系数),第21~26个参数与产率有关(分别是势能产率最大幅度、势能产率递减系数、透光带厚度,动能产率系数,动能产率基准值,势能产率权重),第27~32个参数与水体动能有关(动能幅度、波浪能下降系数、地形消浪能系数、浪基面、风能系数),第33个参数为地层挠曲系数,第34个参数为生物群落系数,各个参数更详细的介绍可以参考文献[18]。
2.2 基于沉积正演模拟的大规模样本库建立
纳入全部34个可调整的物理参数,并通过随机抽样生成了大量的样本,构建了深度学习所需的数据库。样本为沉积相剖面相模型及相对应的34个输入参数,沉积相取值0~7,其中0表示背景值,数字1~7对应图2中图例中的a1、b1、b2、c1、c2、c3、c4,表示不同的相类型,该相类型的划分方案同时考虑了沉积物的水体深度和水体能量。模型以二维矩阵形式表示,矩阵尺寸为100×129,建立了地层沉积过程正演模型样本库。通过人工和自动筛选,去除模拟结果明显不真实不合理的样本后,该数据库共计纳入训练样本416 079个,约占总样本的83%;测试样本83 167个,约占总样本的17%。训练样本和测试样本相互独立,保证深度学习模型不会陷入过拟合。从训练样本中随机抽取几个样本(图2),可以看出它们具备不同的沉积相结构样式,体现了样本包含的沉积模式的多样性,这9个样本采用的正演模拟参数具体见附表1。
2.3 基于生成对抗网络的代理模型构建
通过测试,选择了改进后的卷积对抗神经网络GLS-GAN[27]。原始GAN要最小化生成分布与真实分布的KL散度,同时要最大化两者的JS散度,在数值上会导致梯度不稳定(通常存在梯度消失和梯度爆炸的可能),并且KL散度具有不对称性,降低了生成器的多样性,会造成模式坍缩问题。GLS-GAN具备损失敏感的自适应损失函数,在训练过程中自动调整损失函数,如果某些区域的真实样本和生成样本已经很接近,则生成器的优化重点就转移到真实样本和生成样本依然差异很大的区域,给GAN提供“按需分配”的建模能力,解决了原版GAN及其衍生算法的梯度消失和模式坍缩问题。
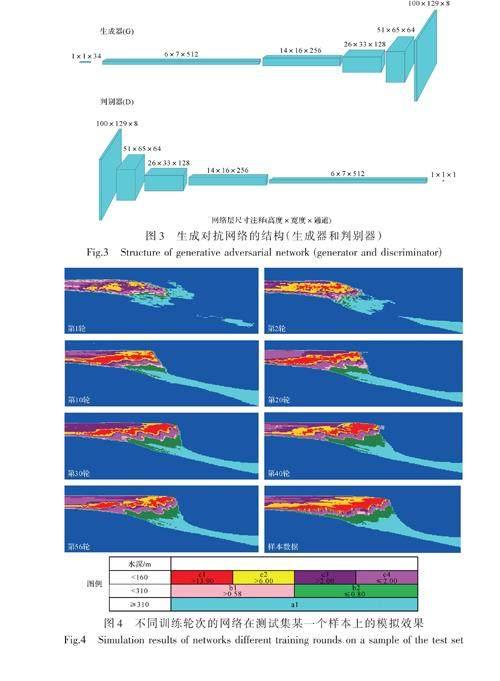
为了保持物理参数和正演结果的一一对应关系,我们在训练生成器时还需要考虑逐个像素的均方误差(Mean Square Error, MSE)。整个网络均由卷积Conv2D单元和转置卷积ConvTranspose2d单元组成,不包含全连接层,每个单元配套一个批量标准化层BatchNorm2d和非线性化层ReLU,通过大量测试推荐采用5~8个卷积层,生成网络和判别网络的具体结构如图3。
利用上述416 079个训练样本,进行56轮次的迭代训练,取得了比较理想的效果。将不同训练阶段的网络应用在测试集的同一套参数上,可以看出不断优化的模拟效果,相序关系变得更加合理(图4)。把最终训练后的网络应用在测试集,随机抽取几个模型,都具备合理的沉积相分布模式(图5),这6个样本的输入参数见附表2。可见相同输入参数下LS-GAN模型的输出与地层沉积过程模型的输出一致性很强,虽然没有达到完全相同,但是基本实现了合理的相带组合特征。通过34个参数生成符合条件的相模型本身是个难度很大问题,GLS-GAN很大程度上改善了模式坍缩问题,但训练难度大、收敛过程不稳定是GAN类方法自身的属性,无法完全避免。另外,网络结构、样本数量,样本质量等也会影响最终的效果。目前认为形成的替代模型可以用于下一步的反演模拟。
2.4 基于代理模型的反演模拟
在开始真实观测数据反演模拟之前,先从测试集中随机选择样本进行参数反演。该样本的参数及其沉积过程模型模拟结果都是已知的,可以用于验证参数反演是否有效。在水平方向等间距设置了6个虚拟测井,作为反演系统的观测数据。用观测数据与模拟结果的均方根误差作为目标函数,优化器采用上述提到的SCE-UA算法[19]。
用SCU-UA进行了500 000次迭代优化,得到了预期的效果(图6)。图6a展示了参数的真实值(灰色虚线)和SCE-UA 算法得到的最优参数值(蓝色实线),图6b展示了SCE-UA优化过程中目标函数的变化,图6c展示了替代模型LS-GAN给出的地层沉积相,其中虚拟测井位置上的沉积相用真实值(即沉积过程模型模拟值)代替。模拟结果表明,随着优化过程的进行,目标函数稳定下降并不再降低,表明SCEUA算法已经收敛。然而反演所得到的参数值与参数的真实值有较大差异,且互不相同。这一结果表明地层沉积过程的参数反演是一个高度复杂的问题,存在多个局部极小值。
采用类似的方法进行真实观测数据的反演。将代理模型加入地层沉积反演模拟系统,替换传统的地层正演模拟器,实现参数反演。选择4口科考钻井的人工解释的沉积数据为观测数据,将钻井穿过网格的像素均方根误差为目标函数,SCE-UA为反演优化算法,进行参数反演。对于真实数据,我们并不知道测井以外区域的沉积相,也不知道真实的物理参数的值,因此只能靠专家经验判断结果是否合理。从反演结果可以看出,使用替代模型反演得到的地层沉积相的层序结构明显,分布较为合理(图7)。与基于正演模拟器的反演方法相比,结果一致性较强,效率有大幅提升(图8)。
3 适应性分析
相比传统的SCE-UA算法驱动下调直接采用正演模拟器反演,基于深度学习代理模型的反演在效率方面有大幅提升。选取全部34个参数参与优化,为了使SCE-UA算法充分收敛,使用SCE-UA直接优化地层沉积过程模型往往需要不间断执行一个月。相比之下,基于神经网络代理模型的优化过程在普通计算机上仅需数分钟即可完成。基于深度学习代理模型的地层沉积反演模拟在效率方面有了大大提高,但也存在一定的局限性。
代理模型依赖于正演模拟器,而且需要一定的限制条件。代理模型缺乏正演模拟器所拥有的模拟能力完备性,尽管生成样本时已经考虑了模型的泛化性能,但是由于沉积模拟的参数根本无法穷尽,特别是初始地形和构造沉降参数,因此只能构建限定条件下的模型代理。这也是代理模型方法逊于传统反演系统的地方。
基于深度学习代理模型构建可以进一步推广应用。本文实例研究展示的是斜坡和镶边类型的碳酸盐岩沉积在二维剖面上的代理模型,其实也可以进行孤立台地、潟湖等更复杂地形条件的下的代理模型构建。也有望推广到三维沉积模拟,不过神经网络的结构、需要的样本数量等具体参数也需要进一步探索。本文展示的是针对碳酸盐岩地层沉积正演模拟的深度学习代理模型构建方法,理论上该方法可以用于其他领域的正演模拟替代模型构建,比如油气藏渗流模型、地下水流动模型等。
4 结论
(1) 地层沉积过程反演模拟系统是在优化器的驱动下,不断调整正演模拟输入参数,提高模拟结果与观测数据的吻合程度,大大增加了沉积过程模拟建模方法的实用性,但是存在反演系统非线性强、耗时长、效率较低的问题。
(2) 生成对抗网络具有较强的模式生成能力,在一定条件下,利用该方法建立的碳酸盐岩地层沉积过程模拟系统的代理模型,具有较强的泛化能力。
(3) 将代理模型带入沉积模拟反演系统,替换正演模拟器,可以大大提高反演的效率。通过巴哈马滩西缘斜坡现代沉积的反演模型实例,验证了该方法的可行性。
猜你喜欢
中等数学(2022年5期)2022-08-29 06:07:38
沉积与特提斯地质(2019年1期)2019-07-16 08:41:30
趣味(数学)(2018年12期)2018-12-29 11:24:00
现代营销(创富信息版)(2018年8期)2018-09-08 08:51:50
沉积与特提斯地质(2018年4期)2018-07-16 08:27:30
石油地球物理勘探(2017年4期)2017-12-18 07:14:55
石油地球物理勘探(2017年2期)2017-11-23 06:02:04
南方文学(2016年4期)2016-06-12 19:58:50
学生天地(2016年23期)2016-05-17 05:47:15
中国塑料(2015年11期)2015-10-14 01:14:16
