
基于正向软标签的轻量级关系抽取
2023-04-29 22:47宋函宇欧阳丹彤叶育鑫
吉林大学学报(理学版) 2023年2期
宋函宇 欧阳丹彤 叶育鑫


摘要: 针对关系抽取模型规模越来越大、 耗时越来越长的问题,提出一种知识筛选机制,利用筛
选出的正向软标签构造轻量级关系抽取模型. 首先,利用知识蒸馏提取出知识并将其存储在软标签中,为避免知识蒸馏中教师与学生间差距大导致的知识难吸收问题,使用教师助手知识蒸馏模式; 其次,使用标签的余弦相似度筛选出正向软标签,在每步蒸馏中都动态赋予正向软标签更高的权重,以此削弱知识传递中错误标签导致的影响.
在数据集SemEval-2010 Task 8上的实验结果表明,该模型不仅能完成轻量化关系抽取任务,还能提升抽取精度.
关键词: 轻量级关系抽取; 知识筛选; 正向软标签; 知识蒸馏; 余弦相似度
中图分类号: TP391.1 文献标志码: A 文章编号: 1671-5489(2023)02-0317-08
Lightweight Relation Extraction Based on Positive Soft Labels
SONG Hanyu1,2,OUYANG Dantong1,3, YE Yuxin1,3
(1. College of Computer Science and Technology,Jilin University,Changchun 130012,China;
2. FAW-Volkswagen Automotive Co.Ltd,Changchun 130011,China;
3. Key Laboratory of Symbolic Computation and Knowledge Engineering ofMinistry of Education,Jilin University,Changchun 130012,China)
收稿日期: 2022-01-04.
第一作者简介: 宋函宇(1996—),女,汉族,硕士研究生,从事自然语言处理的研究,E-mail: hanyu.song@faw-vw.com.
通信作者简介: 欧阳丹彤(1968—),女,满族,博士,教授,博士生导师,从事基于模型诊断和语义网的研究, E-mail: ouyd@jlu.edu.cn.
基金项目: 国家自然科学基金(批准号: 42050103; 62076108; U19A2061).
Abstract: Aiming at the problem that the scale of relation extraction model was getting larger and larger,and the time consumption was getting longer and longer,
we proposed a knowledge filtering mechanism to construct a lightweight relation extraction model by using the positive soft labels selected.
Firstly,knowledge distillation was used to extract knowledge and store knowledge in soft labels. In order to avoid the problem of
difficult absorption of knowledge caused by the large gap between teachers and students in knowledge distillation,we used teacher assistant knowledge distillation pattern.
Secondly, the cosine similarity of labels was used to filter the positive soft labels and the positive soft labels were dynamically given higher weight in each step of the distillation,
so as to weaken the influence caused by the wrong labels in the knowledge transfer. The experimental results on SemEval
-2010 Task 8 dataset show that the proposed mode can not only complete the task of lightweight relation extraction,but also improve the extraction accuracy.
Keywords: lightweight relation extraction; knowledge filtering; positive soft label; knowledge distillation; cosine similarity
关系抽取是自然语言处理领域的一个重要分支,是根据两个实体所在的上下文语义判断它们之间存在的关系. 近年来,使用深度神经网络去捕捉语义特征已成为解决关系抽取问题的发展趋势[1-3]. 为获得高精度的抽取结果,可利用不同类型的神经网络组件有机组合在一起,或使用庞大的预训练语言模型[4-7]通过构造复杂的抽取模型更精准地捕获语义特征. 例如,文献[8-9]均使用图卷积神经网络结合其他的网络组件构建模型. 文献[8]在图卷积神经网络的基础上结合了依赖树; 文献[9]用注意力机制结合图卷积神经网络,为神经网络的节点分配权重. Alt等[10]使用微调预训练模型GPT(generative pre-trained transformer)[11]的方法,利用預训练语言模型在语言处理中的优势去挖掘更有价值的语义特征,从而更好地完成关系抽取任务.
虽然近年来关系抽取模型的精度越来越高,但抽取模型的规模呈现越来越大的趋势,所需要的计算资源和消耗的时间也越来越多. 为解决该问题,人们提出了如剪枝[12-13]、 量化[14]、 知识蒸馏[15]等技术进行模型轻量化,力求构造出轻量级模型. 剪枝是通过改变神经网络模型的原有结构,舍弃一部分神经元的方式达到轻量化的目的; 量化是将较高精度的数据降低为低精度的形式,从而降低计算成本,但会面临丢失关键数据的风险; 知识蒸馏是基于教师-学生的模式,让学生模仿教师处理问题的能力,学生不需要改变自身的结构,也不需要改变数据类型.
经典的知识蒸馏[15]方法由一个学生模块和一个教师模块组成. 教师模块通过软标签的形式向学生模块传授自己的分析结果,学生通过对软标签知识的学习模仿教师的行为,力求接近教师的结果. 目前,经典蒸馏策略的改进已有很多,如Fukuda等[16]摒弃单个教师的传统方法,采用多个教师联合指导的方式,使学生可以向多个教师进行学习; Mirzadeh等[17]认为教师和学生之间在规模上存在巨大差异,这种差异可能会使学生对知识的吸收与理解不理想,因此引入教师助手的概念,教师首先指导教师助手,在教师助手通过学习知识、 拥有能传授知识的本领后,让教师助手直接指导学生. 教师助手在规模上比教师更接近学生,所传递的知识更容易被学生吸收,对蒸馏的结果更有益.
使用知识蒸馏的轻量级关系抽取框架的关键在于知识的传递,知识的质量会影响被指导者能力的提升. 文献[16-17]均使用原生软标签作为知识参与学习. 被提取出的知识代表了教师及教师助手的抽取能力,但教师对实体间关系的判断也不是完全正确的,也会存在错误、 偏差. 原生软标签中存储的知识可能存在与事实相悖的部分. 知识中存在的错误会误导学生学习,阻碍学生进步. 因此,需要一种知识筛选机制,对知识的正确与否进行判断. 本文在构建轻量级关系抽取模型过程中使用余弦相似度鉴别软标签的正确性. 当余弦相似度接近1时,说明软标签的正确性很高,可为软标签赋予较高的权重,使其能对学生模型产生很大程度的正向影响,本文将具有此正向意义的软标签称为正向软标签; 反之,当余弦相似度的值接近于0时,根据相似度更新权重的机制会赋予软标签较低的权重,降低其指导作用,避免错误标签的误导.
1 构建模型
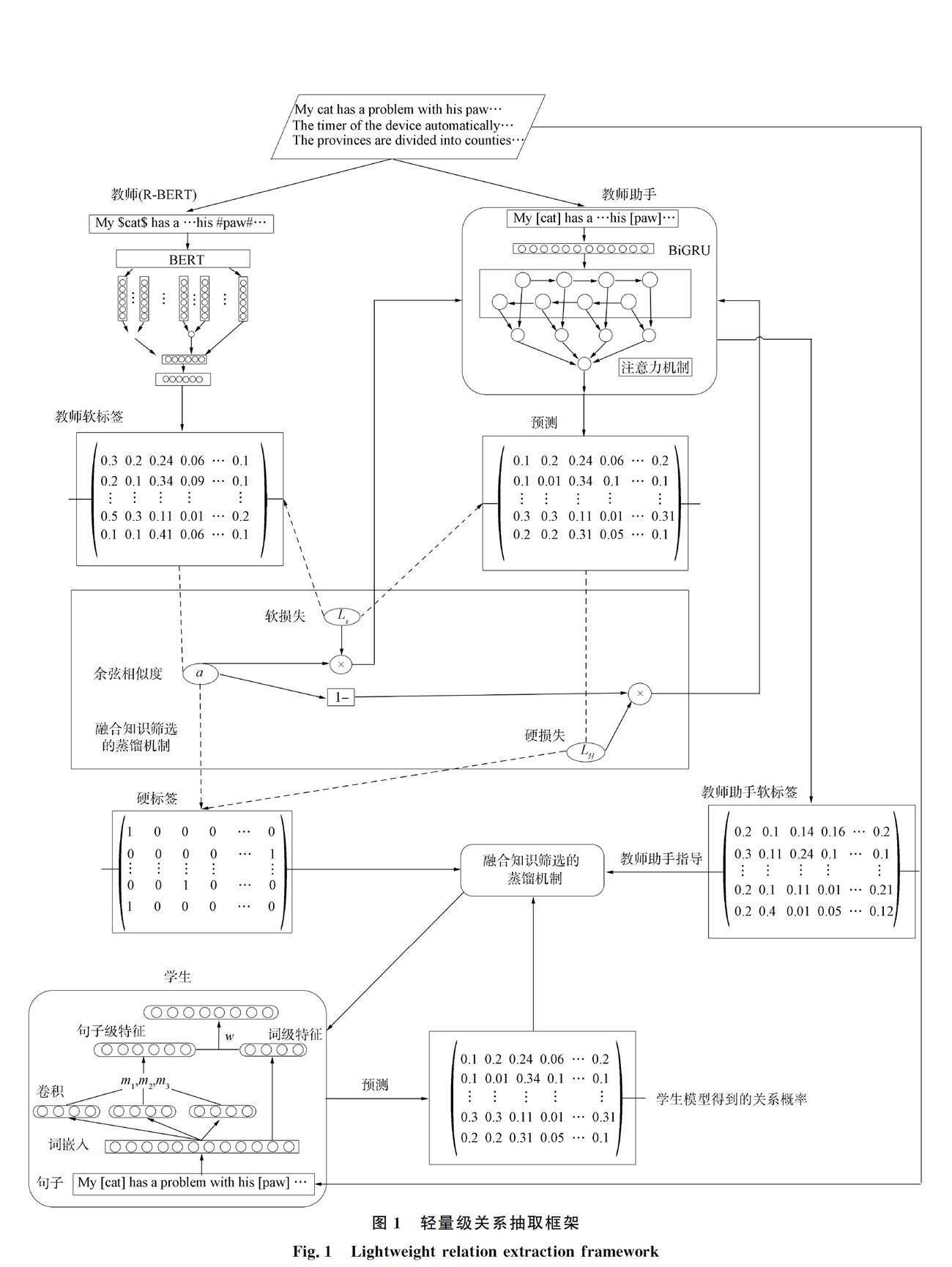
本文结合教师助手的蒸馏模式和知识筛选策略共同构造一种轻量级关系抽取框架,其结构如图1所示. 该框架主要由教师模块、 教师助手模块、 学生模块和融合知识筛选的蒸馏机制组成. 首先,教师模块根据样本数据得出具有经验知识的教师软标签; 其次,教师软标签经过知识筛选策略的过滤,区分出与代表事实硬标签相似度较高的正向软标签,从而在正向软标签指导教师助手进行训练时为其分配较高的权重. 教师助手在指导学生模型时也输出其软标签,同理,教师助手软标签在进行知识筛选后,根据筛选结果更新指导学生模型训练时的权重.
本文共使用两次融合知识筛选的知识蒸馏机制,第一次是教师使用软标签中的知识构建一个能力出众并且规模适中的教师助手; 第二次是由教师产生的教师助手借助其软标签将有价值的知识输送给学生模块. 两次知识蒸馏相结合的模式比传统只用一次蒸馏的方法更能促进知识的吸收. 教师助手作为学生与教师间的桥梁角色具有平稳过渡二者之间差距的作用,可避免一次蒸馏知识吸收率较低的问题.
1.1 教师模块
教师向学生传授知识,通过知识指导学生进行优化. 因此,教师模块(teacher)需具备出色的抽取能力,这样才能给学生模块正确的指导. 本文使用R-BERT(bidirectional encoder representation from transformers)關系抽取模型[18]作为教师. 模型中的预处理部分BERT[19]使用基础的BERT,由12个Transformer[20]编码器、 12个自注意力头和768个隐藏单元构成.
2 实验和结果分析
2.1 数据集和评价指标
本文使用的数据集是SemEval-2010 Task 8[23],其中共有10 717个句子,该数据集被分成两部分: 8 000个数据作为训练集,2 717个数据作为测试集. 数据集中的每个句子都包含两个实体,两个实体之间对应一种关系. 该数据集共有9种明确的关系和1种Other关系. 当两个实体的关系不属于9种关系中的一种时,则将其归为Other关系.
实验中考虑关系的方向性问题,例如会区别Message-Topic(e1,e2)与Message-Topic(e2,e1). 本文采用关系抽取经典评价指标F1值作为评价指标.
2.2 参数设置
教师模块和Att-BiGRU模块均使用Adadelta算法进行优化,其中教师模块的学习率为0.000 02,Att-BiGRU模块的主要参数列于表1. Att-BiGRU模块使用的词嵌入是GloVe[24]词嵌入. 学生模块(CDNN)的主要参数列于表2.
2.3 实验结果分析
为避免无关因素对实验结果的影响,实验中能在CPU设备上进行的实验均在同一台电脑上完成. 对于在CPU上需要较长时间才能完成的实验,换为1080Ti的GPU设备进行实验. 本文通过以下3个指标对轻量级框架进行检验: 参数数量、 运行时间和抽取精度.
表3列出了轻量级框架中不同模块的模型参数数量. 蒸馏操作不影响模块待训练的参数总数. 由表3可见,教师R-BERT的参数总数远大于教师助手模块和学生模块的参数总数,教师助手模块和学生模块的总参数更接近.
模型待训练的参数数量会影响模型的运行时间,表4列出了各模块的模型训练时长和测试所用的时间. 训练是在GPU设备上完成的,测试是在CPU设备上完成的. 表4中训练时长是处理一次训练数据所用时间,测试时长是处理一次测试数据所用时间.
由表4可見,本文使用的知识蒸馏并未耗费很长时间,是一种时间成本较低的构建轻量级关系抽取模型的方法. 教师助手模型的测试时间和训练时间约是学生模型的4倍和3
倍. 轻量级模型的运行时间与重量级R-BERT模型之间的差距较悬殊,在训练阶段R-BERT的耗时约是其44倍,测试阶段R-BERT的耗时约是其2 718倍.
将框架中的各模块在数据集SemEval-2010 Task 8上进行关系抽取能力的实验,以F1值作为性能的评价标准,实验结果列于表5.
由表5可见,教师模型具有出色的关系抽取能力,学生模型的抽取能力远低于教师模型,Att-BiGRU模型的抽取水平位于二者之间. 知识筛选机制从教师模型中筛选出的有价值的知识供给Att-BiGRU学习,吸收知识从而获得提升的Att-BiGRU模型成为教师助手模型. 教师助手模型比Att-BiGRU模型的F1值提升了0.23. 教师助手模型负责将教师的知识进行解读并传递下去,所传递的知识同样也要经过软标签的筛选,计算出与硬标签的相似度并以此为依据对不同的软标签赋予不同的指导权重,获得不同权重的知识数据将在后续学生模型的训练中发挥作用. 学生模型只需使用较低的计算成本处理软标签,即能从中学习经验. 利用教师助手的软标签进行学习是一种轻量化的学习方法,对于学生模型,在轻量化操作后,其F1值较之前提升了1.47.
通过分析3种不同类型的实验数据表明,本文提出的轻量化关系抽取框架能在使用小规模模型并消耗较低的运行时间成本情况下,有效提升关系抽取的性能.综上所述,针对关系抽取模型规模日趋庞大、 运行时间日逐渐增多的问题,本文使用一种知识筛选机制,并将其用于教师助手知识蒸馏模式中,筛选出的正向软标签用于构造轻量级关系抽取模型. 通过本文轻量级关系抽取框架得到的轻量级模型在计算资源有限、 时间要求较高的场景中具有强大的竞争优势. 该框架能使重量级的模型在花费较少计算成本的情况下完成轻量化的转变.
参考文献
[1] CAN D C,LE H Q,HA Q T,et al. A Richer-but-Smarter Shortest Dependenc
y Path with Attentive Augmentation for Relation Extraction [C]//Proceedings o
f the 2019 Conference of the North American Chapter of the Association for Comp
utation Linguistics: Human Language Technologies. [S.l.]: Association for Computation Linguistics,2019: 2902-2912.
[2] ZHU H,LIN Y K,LIU Z Y,et al. Graph Neural Networks with Generated Parameters for Relation Extraction [EB/OL].
(2019-02-02)[2021-02-01]. https://arxiv.org/abs/1902.00756.
[3] LEE J,SEO S,CHOI Y S. Semantic Relation Classifica
tion via Bidirectional LSTM Networks with Entity-Aware Attention Using Latent Entity Typing [J]. Symmetry,2019,11(6): 785-1-785-9.
[4] LIU Y H,OTT M,GOYAL N,et al. RoBERTa: A Robustly
Optimized BERT Pretraining Approach [EB/OL]. (2019-06-26)[2021-08-18]. http://arxiv.org/abs/1907.11692.
[5] LAN Z Z,CHEN M D,GOODMAN S,et al. ALBERT: A Lite
BERT for Self-supervised Learning of Language Representations [EB/OL]. (2020-02-09)[2021-08-21]. https://arxiv.org/abs/1909.11942.
[6] RAFFEL C,SHAZEER N,ROBERTS A,et al. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer [J]. M
achine Learning,2020,21: 140-1-140-67.
[7] SONG K,TAN X,QIN T,et al. MASS: Masked Sequence t
o Sequence Pre-training for Language Generation [EB/OL]. (2019-07-21)[2021-03-01]. https://arxiv.org/abs/1905.02450.
[8] ZHANG Y H,QI P,MANNING C D. Graph Convolution over Pruned Dependency Trees Im
proves Relation Extraction [C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing.
[S.l.]: Association for Computational Linguistics,2018: 2205-2215.
[9] GUO Z J,ZHANG Y,LU W. Attention Guided Graph Convolutional Networks for Relation Extraction [C]//Annual Meeting of the Associat
ion for Computational Linguistics. [S.l.]: Association for Computational Linguistics,2019: 241-251.
[10] ALT C,HüBNER M,HENNIG L. Fine-Tuning Pre-trained Transformer Language Mode
ls to Distantly Supervised Relation Extraction [C]//Proceedings of the 57th Annual Meeting of the
Association for Computational Linguistics. [S.l.]: Association for Computational Linguistics,2019: 1388-1398.
[11] RADFORD A,NARASIMHAN K,SALIMANS T,et al. Improving Language Understanding
by Generative Pre-training [J/OL]. (2018-01-01)[2021-08-18]. https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf.
[12] HASSIBI B,STORK D G. Second Order Derivatives for Network Pruning: Optimal
Brain Surgeon [C]//Advances in Neural Information Processing Systems. New York: ACM,1992: 164-171.
[13] LECUN Y. Optimal Brain Damage [J]. Neural Information Proceeding Systems,1990(2): 598-605.
[14] COURBARIAUX M,BENGIO Y,DAVID J P. Training Deep N
eural Networks with Low Precision Multiplications [EB/OL]. (2015-09-23)[2021-08-11]. https://arxiv.org/abs/1412.7024.
[15] HINTON G,VINYALS O,DEAN J. Distilling the Knowledge in a Neural Network [J]. Computer Science,2015,14(7): 38-39.
[16] FUKUDA T,SUZUKI M,KURATA G,et al. Efficient Know
ledge Distillation from an Ensemble of Teachers [C/OL]. (2017-08-20)[2021-07-21]. https://icia-speech.org/archive_vo/Interspeech_2017/pdfs/0614.PDF.
[17] MIRZADEH S I,FARAJTABAR M,LI A,et al. Improved Knowledge Distillation via
Teacher Assistant [J]. Proceedings of the AAAI Conference on Artificial Intelligence,2020,34(4): 5191-5198.
[18] WU S C,HE Y F. Enriching Pre-trained Language Model with Entity Information for Relation Classification [C]//
Proceedings of the 28th ACM International Conference on Information and Knowledge Management. New York: ACM,2019: 2361-2364.
[19] DEVLIN J,CHANG M,LEE K,et al. BERT: Pre-t
raining of Deep Bidirectional Transformers for Language Understanding [C]//The North American Chapter of
the Association for Computational Linguistics: Human Language Technologies. [S.l.]: Association for Computational Linguistics,2018: 4171-4186.
[20] VASWANI A,SHAZEER N,PARMAR N,et al. Atte
ntion Is All You Need [C]//Annual Conference on Neural Information Processing Systems. New York: ACM,2017: 5998-6008.
[21] PENG Z,WEI S,TIAN J,et al. Attention-Based Bidirectional Long Short-Term
Memory Networks for Relation Classification [C]//Proceedings of the 54th Annua
l Meeting of the Association for Computational Linguistics. [S.l.]: Association for Computational Linguistics,2016: 207-212.
[22] ZENG D J,LIU K,LAI S W,et al. Relation Classification via Convolutional Deep Neural Network [C]//
Proceedings of the 25th International Conference on Computational Linguistics: Technicl. [S.l.]: Association for Computational Linguistics,2014: 2335-2344.
[23] HENDRICKX I,SU N K,KOZAREVA Z,et al. SemEval-2010 Task 8: Multi-way Class
ification of Semantic Relations between Pairs of Nominals [C]//Proceedings of the 5th International Workshop on Semantic Evaluation.
[S.l.]: Association for Computational Linguistics,2010: 33-38.
[24] PENNINGTON J,SOCHER R,MANNING C. Glove: Global Ve
ctors for Word Representation [C]//Conference on Empirical Methods in Natural Language Processing.
[S.l.]: Association for Computational Linguistics,2014: 1532-1543.
(責任编辑: 韩 啸)
