
基于Attention-BiLSTM模型的对话式文本抑郁识别研究
2023-04-27 04:00:42薛之芹张贯虹王见贤范义飞
电脑知识与技术 2023年7期
薛之芹 张贯虹 王见贤 范义飞


关键词:文本分类;抑郁识别;情感分析;注意力机制;BiLSTM
0 引言
抑郁症是现代社会日益严重的公共健康问题之一,其特征有显著且长期的情绪抑郁、认知障碍、思维迟缓等。随着激烈的社会竞争等因素影响[1],人们所面临的生活负担和心理压力日益严重,导致抑郁症的患病率持续增长,抑郁症患者自杀风险也是正常人的25倍以上[2-3]。由此可见,目前抑郁识别仍然是一项非常具有挑战性的任务。
传统的抑郁识别方法主要包括基于词典和机器学习的情感分析方法。Ran Li等人[4]创建了一个与抑郁相关的情感词典来研究健康者与抑郁症患者之间的差异。实验结果表明,构建的抑郁症词汇对抑郁症患者有较好的识别效果。Anu Priya等人[5]采用机器学习算法来确定五种不同的焦虑、抑郁和压力的严重程度。数据收集采用标准问卷,测量焦虑、抑郁和压力的常见症状(DASS-21)。随后,应用了五种不同的识别技术——决策树、随机森林树、朴素贝叶斯、SVM和K-近邻算法来进行预测,随机森林模型被确定为最佳模型,最终在DAIC-WOZ 数据集上的F1 值达到0.766。但随着网络快速发展,词语更替速度飞快,基于情感词典的方法需要耗费大量资源去更新词典;基于机器学习的方法依赖于人工对文本进行标注。相比于以上两种方法,基于深度学习的方法能够快速高效地处理大量数据,自动提取出文本的情感特征,具有较好的泛化能力。
Heinrich Dinkel等人[6]提出了一个基于文本的多任务Bi-GRU网络,通过预训练的词嵌入来模拟病人在临床访谈中的反应。使用了一种新的多任务损失函数,旨在建模抑郁症的严重程度和二元健康状态。将多任务建模与预训练句子嵌入相结合,即Word2Vec、FastText、ELMo 和BERT 用于基于文本的抑郁建模,分类器采用具有注意机制的Bi-GRU模型。独立研究了单词和句子级的单词嵌入以及使用大数据预训练进行抑郁检测。最终在DAIC-WOZ验证集上的F1值为0.84。M.Niu等人[7]提出了一种基于图注意网络(HCAG) 的层次上下文感知模型进行抑郁检测,所提出的层次上下文感知结构可以捕获答案中的关键信息,该模型在DAIC-WOZ数据集上的F1值为0.77。虽然基于深度学习算法进行抑郁识别的方法不需要人工干预,分类精度较高,但是需要使用一个大规模的数据集来训练模型,抑郁症患者临床对话这样的场景研究目前较少,往往很难提取出显著的特征,识别效果较差。
針对上述问题,为了提高抑郁识别的准确性,本文提出了一种基于Attention-BiLSTM 的抑郁识别模型。实验结果表明,与上述相似文本实验相比,该模型显著提高了文本抑郁倾向识别的准确率。
1 相关工作
1.1 Bi-LSTM 模型
LSTM(Long Short-Term Memory)模型[8]是深度学习中的一种常见模型,广泛用于文本分类、图像处理中。然而,LSTM模型不能全面包含文本的上下文特征依赖信息。在文本抑郁倾向情感识别研究中,词语与上下文都有着不同程度的语义关联性,并且抑郁症正负样本量不多,所以双向处理至关重要。综上所述,本文将采用Bi-LSTM (Bi-directional Long Short-TermMemory)[9]模型,用相互独立的两个隐层,从正反两个方向同时对文本数据进行处理,从而捕捉到文本中的双向语义依赖。
1.2 Attention 机制
在对话式文本的抑郁识别任务中,Seq2Seq任务是一项重要的任务。Seq2Seq任务包含两部分:编码器(Encoder)和解码器(Decoder)。文本单词对应的词向量被输入编码器中,产生文本对应的隐含向量表示,然后通过解码器对文本对应的隐含向量进行逐个字符的解码,生成目标文件。然而,对于较长的文本,编码器和解码器很难做到全部记忆的功能,而且不是所有的单词对抑郁识别都能起到作用,因此在该分类任务中融入Attention机制。本文采用的是Bahdanau注意力机制[10],具体计算过程如下:假设编码器的输出向量为si,i = 0,1,2,...,S - 1,其中S是编码器输入系列的长度。解码器当前的隐含层输出为hj,j = 0,1,2,...,j - 1,其中T是解码器输出系列的长度。首先,将si 和hj 拼接,然后对拼接之后的向量做线性变换,取Tanh激活函数,并使用vT 做点积,最后输出score值:
最后,将隐藏层的结果和归一化后的结果在特征方向上做拼接和线性变换,并且使用tanh函数作为激活函数输出最终的注意力值:
Attention机制通过引入一个网络能够在Bi-LSTM 中对重要的单词加以不同的权重,在抑郁识别分类中,使得文本特征在保留最有效信息的基础上,最大限度地解决信息冗余的问题,从而提高分类的准确率。
2 对话式抑郁数据集
由于适合使用深度学习算法来研究抑郁倾向的公开数据集非常有限,目前比较广泛使用的是精神压力访谈语料库DAIC-WOZ (Distress Analysis InterviewCorpus-Wizard of Oz)以及扩展版E -DAIC(Extended-DAIC) [11-12]。该系列语料库是用于精神压力状况诊断的临床访谈,如焦虑、抑郁和创伤后应激障碍。它包含了从总共278次临床访谈中收集的约74小时的数据,并且为每个参与者提供了两个标签:一个标签是抑郁或者非抑郁的二元诊断,1代表具有抑郁倾向,0 代表不具有抑郁倾向;一个标签是PHQ-8抑郁量表问卷得分。PHQ-8量表是大型临床研究中抑郁症的有效诊断和严重程度测量方法,包含八项患者健康问卷抑郁量表的抑郁评分。PHQ-8总分≥10分的参与者,即被认为有抑郁症状。本文实验采用的数据为DAIC-WOZ中的对话语料部分,除去动画虚拟采访者Ellie的话语,将参与者的对话语料提取出来并进行拼接,部分数据格式如图1所示。
2.1 数据预处理
首先,采用去掉停用词、标点符号、最常见和最罕见的单词等技术。其次,一些参与者的回答过于口语化,不利于模型训练,所以对这些话语进行了规范化处理。最后,采用词形还原技术,把单词的词缀部分删掉,提取主干部分,将每个任意变形的单词还原为它的词根单词,方便计算机进行后续处理。
2.2 数据增强
由图2原始数据分布情况可知,由于DAIC系列抑郁数据集的样本量总共只有278条,而且抑郁人群在总样本的占比较少,所以需要对原始数据进行数据增强,从而扩充样本。现有NLP的数据增强有两种方法,一种是EDA加噪法[13],另一种是回译法[14]。根据对话式文本的特点以及几种方法的比对,该实验最终选择EDA加噪法中的同义词替换方法来进行数据增强。
为了保证对话式文本在进行同义词替换后,依旧保持参与者所表达的语义,本实验将替换的单词数量设置为20,并且使用Python NLTK模块中的WordNet 词汇数据库来查找同义词。此外,为了能够有效扩充样本的总数量,本实验将同义词替换增强技术应用于整个训练数据集,处理后的初始训练集由175个训练样本加倍到350个样本。
3 抑郁识别模型构建
本文提出的Attention-BiLSTM模型结构如图3所示,主要由以下部分组成:
文本嵌入层:实验选择预训练好的FastText语言模型完成对词性的向量化表示,词向量维度设置为300维。
Attention层:该层为特征权重学习层。采用有效的特征学习策略,根据输入数據计算不同特征对下游任务的不同贡献程度,使模型不仅能够全面地表达语义,也能够着重于关注有助于抑郁识别的文本向量。
Softmax层:使用Softmax 函数对已生成的文本向量进行归一化处理,得到文本向量在抑郁或非抑郁类型下的概率分布,具体计算过程如下:
其中,i 为1时表示抑郁状态,i 为0时表示非抑郁状态,ω和b 分别为权重和偏置量。
4 实验分析
4.1 实验环境
本文实验基于Windows10 系统,采用了Py⁃Torch1.11.0网络框架和Python3.7版本的编程语言进行深度学习网络的训练,CUDA版本为11.3,显卡为GTX 1080Ti,显存大小为11GB。
4.2 参数设置
模型的性能好坏会受到各种参数的影响。本文通过实验,对比不同Epochs、Dropout和Learning Rate等参数后,最终筛选出了以下最佳参数:
4.3 对比实验
本文采用了以下几种对比实验:
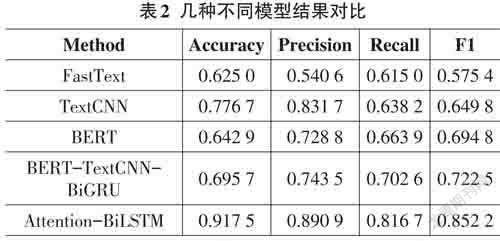
FastText:FastText模型将整个对话文本作为特征来预测参与者是否具有抑郁倾向[15]。将DAIC-WOZ系列数据集经过预处理后输入FastText模型中,识别的准确率为0.625 0,F1值为0.575 4。由于FastText模型更适合用于大型数据集中,DAIC-WOZ系列数据集的规模较小,很容易造成过拟合,所以训练效果并不理想。
TextCNN:相比于分类方法较为简单的FastText 模型,TextCNN 模型通过使用多个大小不同的卷积核,可以提炼出句子内部及句子之间的相互关系[16]。将DAIC-WOZ 系列数据集经过预处理后,输入TextCNN 模型中,识别的准确率为0.776 7,F1 值为0.649 8。相较于FastText模型,TextCNN的训练效果优于FastText模型,但是其中的卷积和池化操作会丢失对话文本间的顺序和位置信息等内容,不利于对话式文本的抑郁倾向识别。
BERT:BERT模型可以获取动态的编码词向量,具有较强的泛化能力[17]。将DAIC-WOZ系列数据集输入BERT模型中,识别的准确率为0.642 9,F1值为0.694 8。由此可见,BERT模型并不适合用于该数据集的分类,因为BERT模型适用于在大规模语料上进行无监督训练,而且BERT模型的时间和空间复杂度都非常高,需要大量的算力。
BERT-TextCNN-BiGRU:基于上述模型的不足之处,将BERT、TextCNN和BiGRU模型进行融合[18]。首先使用BERT预训练模型将对话文本映射为向量表示,然后在情感特征提取层使用TextCNN模型和Bi⁃GRU模型共同对向量矩阵提取特征信息。将DAIC-WOZ 系列数据集输入该模型中,识别的准确率为0.695 7,F1值为0.722 5,比单模型的BERT有所提升,但并未取得良好的效果。
Attention-BiLSTM:经过上述模型可以得出,BERT模型并不适用于对话式文本抑郁倾向的识别研究。所以针对这种稀疏的文本,在情感特征提取层采用了将Attention机制与Bi-LSTM进行结合的方法,形成一种新的抑郁情感识别模型,学习对抑郁检测有高度贡献的显著单词的权重和重要的隐藏特征。最后,采用Softmax分类器对结果进行分类,识别的准确率高达0.917 5,F1值为0.852 2。
综上所述,几种不同的模型对比结果如表2所示:
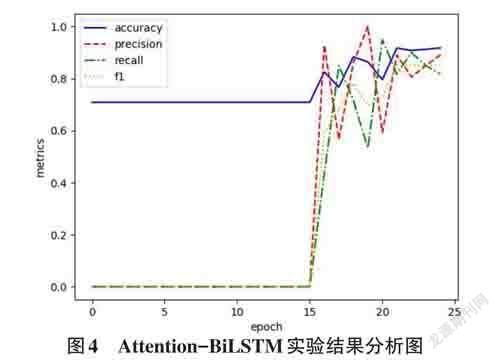
Attention-BiLSTM 模型实验结果分析如图4 所示。初始训练准确率较高的原因是该抑郁数据集的正负样本不平衡。在刚开始训练时,网络中所有的权重都是随机初始化,开始几轮训练基本没有将权重训练好,经过分类器后输出的标签值更容易趋近于占比较大的抑郁样本,直到后面权重训练好后,各项指标才慢慢开始变化。
5 结论
目前,深度学习模型在情感分析领域非常流行,本文提出了一种基于Attention-BiLSTM模型的对话式文本识别抑郁倾向的方法。该模型利用预训练的FastText模型,将对话文本中的单词转换为对应的向量,并使用同义词替换方法增强向量的情感特征。然后使用BiLSTM网络提取正向和反向的上下文信息,并且融入Attention机制学习对抑郁检测有高度贡献的单词权重和重要的隐藏特征。最后,采用Softmax 分类器进行分类。本实验的F1值达到了0.852 2,相较于其他模型取得了较好的提升。
本文的研究为今后的工作指出了另外一个方向,将参与者的语音、面部神情以及眼睛注视方向等特征融入模型中训练。因此,下一阶段的目标是在现有实验的基础上,实现多模态的情感分析,从而进一步提高抑郁识别的准确性。
猜你喜欢
数字技术与应用(2019年2期)2019-05-14 08:25:10
现代电子技术(2018年8期)2018-04-13 06:36:32
软件工程(2017年11期)2018-01-05 08:06:09
智能计算机与应用(2017年5期)2017-11-08 12:11:51
计算机应用(2016年12期)2017-01-13 01:24:36
物联网技术(2016年11期)2017-01-12 19:41:22
电子技术与软件工程(2016年22期)2016-12-26 21:36:42
预测(2016年5期)2016-12-26 17:16:57
电子技术与软件工程(2016年22期)2016-12-26 12:56:34
数字技术与应用(2016年9期)2016-11-09 23:23:56
