
基于两阶分区的MapReduce实验室系统负载均衡研究
2023-04-26 08:21郑文丽熊贝贝程立勋蔡伊娜包先雨
计算机测量与控制 2023年4期
郑文丽,熊贝贝,2,程立勋,蔡伊娜,2,包先雨
(1.深圳市检验检疫科学研究院,广东 深圳 518045;2.深圳海关食品检验检疫技术中心,广东 深圳 518000)
0 引 言
在数字化信息时代背景下,通过实验室系统存储和处理海量数据,已成为日常检验检测工作不可或缺的一部分[1]。而随着实验室系统智慧化的要求,改进存储和处理技术在大规模数据高效采集领域中越发重要。其中,MapReduce是一种处理大规模数据集的分布式框架,拥有拓展性强和容错率高的特点。通过Mapper和Reducer对海量的检测数据进行拆分和归类,与传统构架相比,能更高效地处理数据。而Hadoop框架源于Apache Nutch,集合了HDFS(hadoop distributed file system),YARN(yet another resource negotiator)和MapReduce,是具备高容错性、高拓展性和低成本特点的分布式软件框架,广泛应用于各种领域,包括分布式搜索[2-3]、模式识别[4-5]、计算机机器学习[6-7]和文献聚类[8-9]等。
MapReduce框架主要运用于大型云平台的海量数据库存储的应用场景中,可解决数据采集高频、数据类型多样、数据来源复杂以及用户需求响应及时等难点痛点。同时,根据不同场景的业务应用流程,云平台的设计与开发通常采用分层式管理并按需优化,这为大数据的分流工作提出了新的挑战。王立俊等人[10]在设计气象大数据云平台时,其总体架构共分为基础设施层、数据管理与处理层和应用层,实现了更快的数据采集以及更优的数据处理功能。鉴于气象数据属于典型的时序性数据,其数据流量高达6万次/秒,利用MapReduce这种高性能的分布式计算框架则可以大幅简化数据处理流程。在该云平台中,其MapReduce任务包括了3个任务阶段,分别为Map阶段、Shuffle阶段以及Reduce阶段,这3个阶段可连接为链式工作流。数据流在Map阶段,依据数据的不同属性和特点进行处理之后,形成不同长度的数据块,以相应的规则映射成键值对,这些键值对就是实例化的Map任务。经过Map阶段处理后的分片数据,生成
MapReduce除了在云平台系统运用方面有很多理论研究基础,在其框架的改良优化方面也有着广泛的研究成果,胡东明等人[11]在MapReduce框架下提出了一种负载均衡的Top-k连接查询算法。该算法不仅在MapReduce框架下实现了Top-k连接查询算法,还通过提前终止机制和负载均衡机制来增强其数据连接处理性能。由于Map任务和Reduce任务可以并行处理的特点,能尽量避免了链接MapReduce作业的初始化开销,降低了数据处理成本。该算法流程包括直方图构建、提前终止机制、数据过滤、负载均衡机制4个步骤组成,其中提前终止、数据过滤都在Map阶段实现,Reduce阶段则通过Top-k连接查询算法完成数据清洗。在数据过滤阶段,Map任务会处理每个记录,因为针对每个作业会形成不同的过滤机制。通过了数据过滤机制的记录则进入到Reduce阶段,并使用启发式任务调度算法对每个记录的Reduce任务进行数据调度,将这些任务依次分配给连接总数较低的Reducer进行处理。该算法利用了Map阶段输出的键值对以及连接值进行分组,将其按照自定义分区程序的结果分配给Reduce任务。MapReduce的并行化处理大大降低了算法的总执行时间,但采取不同Top-k算法则产生不同的任务执行时间,经比较,最终选用了P-TKJ算法,相较于RSJ算法获得了更快的执行速度,并随着数据集的增大,其效率的优势越明显,使得MapReduce框架下不仅实现了海量数据的Top-k连接查询算法,还提高了CPU的利用效率。
在实验室系统中引入MapReduce框架[12],可以极大简化分布式程序,集中精力于数据处理的任务本身,提高实验室系统数据处理的效率[13]。实验室系统在执行MapReduce任务时,数据是以键值对输入,并在Mapper节点时进行聚合处理,最终根据哈希值函数Shuffle至各Reducer节点进行Sort和Reduce。在风力发电行业中,其实验室监测数据包含设备的状态参数、气象环境、地理信息等,数据体量较大,类型多。虽然Hadoop平台能够满足大数据的基本需求,但在运营效率方面仍有待提高。王林童等人[14]提出了基于MapReduce的多源数据并行关联查询的优化方法,主要是针对风电大数据进行存储预处理,尽量使具有关联关系的数据存储在同一存储节点中,之后采用哈希分桶算法对数据存储进行优化,并在查询时利用MapReduce框架的并行性特点,最终对数据可以采用并行优化的查询与计算。具体而言,该系统首先对具有相同属性(时间、地点、设备号等)的风电数据进行归并的预处理,在关联查询的基础上数据清洗之后得到风电时序数据合并表。合并表按照关联字段的哈希值分配到不同的“桶”中,同一个“桶”中的数据即存储到同一个数据节点中,实现本地化的存储优化。当用户使用该系统进行数据查询时,设计在Map阶段完成风电数据的查询、过滤、筛选等操作,尽量减少Reduce阶段的操作,此时就大大降低了传输时延,提升了数据查询效率。文献[15]则利用MapReduce框架,构建了一个基于物联网的细胞生物学智慧云实验室系统,该模型共包括四层:实验设备层、IT基础设施层、控制层以及数据分析层。实验设备层主要工作为自动采集不同实验仪器设备上产生的数据,采集后的实验数据交由IT基础设施层进行存储,在控制层可对这些存储的数据进行查询,而在数据分析层,则针对数据种类应用不同的分析方式进行筛选;通过4个层级的相互作用,为实时根据用户的需求进行针对性调整和优化提供了极大的便利。
在这个过程中,如果原始数据分布不均,易出现数据倾斜的问题,引发Reducer节点负载不均衡,导致整个MapReduce任务的执行时间过长。因此,基于MapReduce的实验室系统负载均衡成为近期国内外学者们的研究热点。
1 基于两阶分区的MapReduce负载均衡算法
针对原始数据分布不均导致的数据倾斜问题,国内外学者从不同角度提出了解决方案。杜鹃等人提出了一种利用快速无偏分层图抽样算法的负载均衡算法,在小规模数据上运行良好,但未在大型真实的复杂数据集中运用、验证[16]。陶永才等人提出了MR-LSP(MapReduceon-line load balancing mechanismbasedon sample partition)算法,对原始数据进行采样分析,通过分析结果进行负载均衡的分区分配Reducer节点的策略,但该算法忽略了数据采样率不高时的情况[17]。在马青山等人[18]提出的DSJA(data skew join algorithm)算法从数据关系表中的连接键出现频率的角度出发,区分数据是否产生连接倾斜的情况,再分配到相应的Reducer节点中进行处理,但该算法仅考虑了Reduce端输出的负载均衡,未考虑Map端到Reduce端的输入阶段的负载均衡处理。M.A.Irandoost 等人提出的LAHP(learning automata hash partitioner)算法[19]是根据学习自动机策略,在作业执行阶段,对数据键值进行调配各个Reducer节点的数据量;但该算法只考虑了数据偏度高,而未考虑数据采样率高的情形,且只优化了执行阶段,忽略了计算时间对流程的影响。Elaheh Gavagsaz 等[20]提出的可拓展的高偏度数据的随机采样模型SBaSC(sorted-balance algorithm using scalable simple random sampling )对高偏度数据进行了随机采样,通过采样中键值近似分布推算数据的分布,从而进行负载平衡的分配;该算法在基于Spark的网络数据中得到了较好的效果,但未能泛化至不同的数据集,存在一定的局限性。黄伟建[21]等使用并行随机抽样贪心算法,缩短了采样阶段的执行时间,但当MapReduce输入数据量较大时,准确性不够且负载效果较差。
为解决上述问题,Xu等[22]提出的两阶分区算法在数据偏度较低时通过CC(cluster combination)调度方案实现负载平衡,在数据偏度较高时则通过CSC(cluster split combination)调度方案,可比传统的MapReduce减少60%的运算时长。在该算法中,一个数据处理作业被分为了两个阶段,一是制定分区方案,二是执行MapReduce作业。在制定分区方案中,CC调度方案主要思路是选择具有最大数量的键值对的数据块调度给当前最小工作量的键值对的Reducer,这种启发式算法使用了标准差这一评价指标来自适应地衡量所有Reducer的负载量。当标准差高于设定的阈值后,将对数据块进行再分配。其分配的方式基于对数据块所含键值对数量的降序排序,并对Reducer也进行工作量进行降序排列,接下来则将两个表中的首位进行匹配,以确保整个MapReduce系统的负载均衡。CC调度方案可以解决数据量轻度倾斜的情况,但面对数据量极度倾斜的情况,就无法实现较好的效果。针对这样的情况,该算法又提出了第二种情况的方法,即CSC调度方案。面对包含着较多数据记录的数据块,CSC采用的是划分的方式,将较大的数据块划分成较小的数据块。由于在MapReduce框架下,每个数据块都对应着一个Reducer,因此在对较大数据进行划分的时候,需要额外分配一个Reducer。与CC类似,CSC在进行数据块分割的时候也是采用启发式算法解决这个NP-Hard(non-deterministic polynomial hard)问题,偏度较大的数据块将被分成n块(n为Reducer的总数),以确保整个MapReduce系统保持负载平衡。在分区任务完成之后,该算法便执行MapReduce任务。在MapReduce任务阶段主要是对数据集进行采样,不同的数据则有不同的特点,因此,不同的数据集则采用不同的采样方法,如对预训练过的数据集,则采用区间分布;对于全新的数据集,则采用随机抽样的方式。该算法为了具备更强的泛化性能,采取了随机抽样的方式,并利用Map任务和Reduce任务的并行处理特点,先对数据集进行预处理,利用键值中位数估值的概率进行分布。首先对数据集进行均匀的数据采样,再针对采样中出现键值的概率分布进行统计,基于统计结果,拟合不同的概率分布,并根据相应概率分布对数据块进行抽样,以解决数据偏度和采样率都较高的问题。虽然该两阶分区算法在解决数据偏度和采样率都较高的问题中都有相当好的性能表现,但在执行MapReduce作业,该算法也存在着以下的缺陷:
1)由于两次MapReduce任务采用了串行的执行方式,导致整体任务的执行时间长。
2)在采样率较高时,由于抽样数据会在执行阶段进行重复的MapReduce作业,处理时间过长。
3)执行CSC调度方案时,资源利用率较低,导致出现了部分Reducer节点出现空转的情况。
为了解决上述算法执行时间较长及负载不均衡的问题,本文提出了一种基于MapReduce框架下两阶分区的改进算法。该算法主要工作为:
1)对MapReduce任务的流程进行并行化处理。
2)在采样率高的情况下,将采样阶段输出数据进行回收。
3)在原始数据偏度较高的情况下,提出ICSC(improved cluster split combination)算法。本文提出的算法可以在算法速率提高且执行时间缩短的同时,有针对性地解决高偏度,高采样率情况下数据倾斜的问题。改进后两阶段的流程如图1和图2所示。
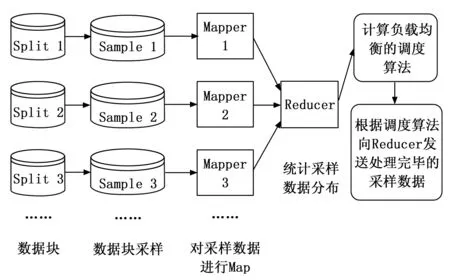
图1 采样阶段流程

图2 执行阶段流程
在采样阶段,与优化前的两阶分区算法不同的是,之前是先进行采样数据进行数据统计再划分数据块,优化后则是先对数据块进行划分,并对划分后的数据块进行采样后与数据集的概率分布进行比对,当某一个数据块的采样率很高(超过设定的阈值)时,就不需要再重新对数据块进行采样而直接使用采样出的数据。低于采样率阈值的数据块则需要再进一步采样,但也是增加而非重新分配。这样的做法不仅能够降低时间开销,同时也降低了系统对于数据取用的I/O成本。
而在MapReduce执行阶段,本文算法除了使用其并行处理的特点,在数据被划分为不同数据块后被分配给不同的Mapper,由于数据块在采样阶段就出现了处理速度不一致的情况,因此如果采用串行方式则会大大拖累不需要重采样的数据块,增加时间开销。本文算法通过直接处理和计算系统负载均衡的方式并行处理数据块,并在分配好数据块的Reducer之后再进行不同数据偏度方式进行调度。对于偏度较低的数据块,本文依然沿用了两阶分区算法中的CC调度方式,而针对偏度较高的数据块则采用了优化了CSC调度方式的ICSC方法,具体的过程在第2节中进行详细地阐述。
2 算法设计
2.1 两阶并行的设计
根据Apache官方文件所述,当系统批处理数据且执行MapReduce任务时,Mapper和Reducer的任务可以进行一定程度的并行处理。其中,Mapper需完成Map的子任务,并将输入的键值对进行归类。而Reducer需要完成的任务主要分为3个子阶段:Shuffle、Sort和Reduce。Shuffle阶段的职责为根据提供的哈希函数将Map任务的结果分别传输到各个Reducer节点上,同时也是唯一一个可以和Map任务同时进行的子任务。因此,Shuffle子任务的结束时间至少晚于Map任务的结束时间。Sort阶段是各个Reducer将收到的数据进行排序、统合的过程。最后的子阶段Reduce则是对数据进行计算,并将结果输出到HDFS的过程。在Hadoop的MapReduce框架下,可根据Map的任务进度,通过调整Slowstart参数,对Shuffle的开始时间进行自定义。这种若参数设置为1.00,则为串联运行,Shuffle子任务将在Map任务全部完成后再执行。
在两阶分区的算法中,由于执行阶段Shuffle子任务并不依赖于Map任务的完成,而是依赖于上一个阶段——采样阶段的Reducer结果所产生的分区方案,因此采样阶段和执行阶段并非两个相互独立的任务,所以没有利用调整Slowstart参数来进行并行化。但在MapReduce任务中,Map任务的执行时间往往远长于Shuffle任务的时间,所以若执行阶段的Map和Shuffle并行处理,会导致Shuffle任务的执行时间被拉长。基于此,本文提出在第一阶段得到采样结果后便开始第二阶段的Shuffle任务,通过并行化流程来减少Mapper节点的空转导致的资源浪费。具体流程如图3所示,实线箭头标识了串行工作时段,虚线箭头标示了并行工作时段。本文算法将原有的流程做两方面更改:首先,让执行阶段MapReduce的Map任务随着采样阶段Map任务的结束立刻开始;其次,让执行阶段MapReduce的Shuffle任务随着采样阶段的分区方案的计算完成而立即启动,通过并行化的方式缩短整体任务的执行时间。

图3 MapReduce流程优化前后对比
2.2 采样阶段的设计
在两阶分区算法中,第一次MapReduce任务的结果只用来规划执行阶段各Reducer节点的负载分配,在数据计算完毕后分区处理后则被舍弃。该算法的设计在数据采样率较高的时候,由于对同样的数据进行相同的多次操作,就会造成计算资源严重浪费,增加数据使用开销。针对这样的问题,本文对上述算法进行了以下改进:将第一阶段数据块采样输出的结果重新Shuffle至对应的Reducer节点上。因此,到了执行阶段的MapReduce,则可直接使用采样数据块,而不必对同一数据块进行重复作业,使采样数据得到充分利用,且节省了存储资源与计算资源。
2.3 分区调度阶段的设计
根据数据偏度情况,本文采用了两种不同的分区调度算法。在偏度较低时,则继续沿用Xu等人[22]提出的CC(cluster combination)调度算法,对采样结果进行分区。在偏度较高时,在执行CC(cluster combination)调度算法,大数据块会导致负载不均衡。因此,上述文献中提出一种CSC(cluster split combination)调度算法来执行分区。该调度算法先对大数据块进行拆分,由多个Reducer节点分别处理,当所有Reducer完成各自的任务后,还需要一个Reducer进行额外的合并任务。此时,其它Reducer会陷入空转的状态;同时,如果所有的Reducer都参与到最后一次Reduce任务中,任何一个节点的故障都会导致最后一次Reduce任务无法进行,致使MapReduce任务执行失败,如图4所示。
为此,本文提出的ICSC算法,如图5所示。其主要思想是将Reducer节点的工作量进行一定程度的压缩,使得这些Reducer完成工作的总时间与其他不参与处理大数据分片的Reducer节点保持一致,减少节点的空转时间,更好地利用计算资源,也达到了数据并行处理使得系统优化的效果。同时,由于执行时间对齐,该算法产生的结果并不会因为任何一个节点的故障而执行失败,意外产生的情况能够独立执行作业进行处理,提升了系统的稳定性。为实现以上功能,ICSC算法的伪代码如下:
ICSC(Clusters C, Reducers R){
average = C.size/R.count;
C.sort();
largeC = new Array();
for (i = 1; i <= C.size; i++){
if (C[i - 1].size >= average){
largeC.add(C[i - 1]);
C.remove(i - 1);
}
}
// n为参与到包含split的reduce任务的节点数量。
n = ceiling(largeC.size/average)
for (i = 1; i <= n; i++){
R[i - 1].assign(largeC.split(n));
}
R.sort();
while(!C.empty){
C.assign(R);
R.sort();
}
}
算法1 ICSC算法伪代码

图4 CSC调度

图5 ICSC调度
3 试验与分析
3.1 试验验证
为模拟实验室系统的数据收集和处理过程,本试验采用WordCount算法和人工生成的数据,在同构环境下以固定大小的输入数据进行实验验证本文提出的算法。由于实验室系统的实际应用环境下,数据属性中的偏度和采样度是影响数据处理阶段的主要因素,因此本文通过控制变量法,验证在不同数据偏度和采样度的情况下,ICSC算法可在实验室系统的数据处理阶段有效减少耗时,达到流程优化的效果。
具体而言,试验以JAVA JDK 11.0.13编制程序模拟12节点的集群,在同构环境下使用WordCount算法处理128 MB人工数据。在实验室系统的环境中,节点间的传输采用100 Mbps带宽。测量时间使用currentTimeMillis函数来测量自采样阶段Mapper到Reducer完成最后一个任务为止的时间差值。 通过试验得出结果如表1和表2所示。

表1 数据偏度在不同方式下对耗时的影响

表2 采样度在不同方式下对耗时的影响
3.2 比较分析
为了更好地比较ICSC算法与CC和CSC调度法的耗时效果。根据在上述结果(表1和表2)的基础上分别以输入数据偏度和采样率为自变量,以各自的执行时间为因变量,得出不同算法条件下,各自的偏度和采样度的效率,如图6和图7所示。

图6 偏度与时间对比

图7 采样度与时间对比
如图6所见,当数据偏度大于0.1时,ICSC算法采样时间更少,且偏度愈大优势更明显,通过测算,在处理偏度为1.5的数据时,对比CSC算法,ICSC算法可节约10%的执行时间;但当数据偏度小于0.1时,由于ICSC在最后需要进行一次额外的Reduce以合并被拆分的大数据块,因此执行时间是会稍大于CC和CSC调度法所耗时间。
同样在图7中,可以看到在不同采样度的环境下,ICSC与两阶分区中算法的执行时间对比。3种算法均在采样度为0.1左右时执行效率最高;而在0.1及以上时,ICSC算法比其它两种算法执行时间更短。这是因为在本地性较高的环境下,ICSC通过节省第二轮MapReduce的数据处理量以达到更优的执行时间。
4 结束语
本文针对两阶分区算法中在实验室系统的实际数据处理场景中存在的不足,对其调度算法和执行流程进行改进。实验结果证明,改进后的算法在数据存在高偏度和高采样度的情况下,均可有效地减少了Mapper和Reducer节点空转的时间,弱化了Reducer节点间的依赖性,缩短MapReduce的执行时间,优化了实验室系统数据处理阶段的流程,从而高效地实现MapReduce框架下的实验室系统中数据处理的负载均衡。但值得注意的是该算法在本地性较差的环境下仍有待改进,即数据采集系统与数据处理系统之间需要一定时间开销的情况,因为在这样条件的环境下,数据处理节点间的传输时间远大于MapReduce作业的计算时间,此时节点间的传输时间成为ICSC算法执行时间的主要影响因素。而ICSC算法主要针对计算时间进行优化,在执行时间的优化效果较为逊色,这也是本研究下一步工作努力的目标和方向。
猜你喜欢
环球时报(2022-03-29)2022-03-29
大学数学(2021年2期)2021-05-07
电脑爱好者(2020年18期)2020-09-26
知识经济·中国直销(2018年7期)2018-07-27
电脑爱好者(2017年9期)2017-06-01
噪声与振动控制(2017年1期)2017-03-01
系统工程与电子技术(2016年2期)2016-04-16
电子器件(2015年5期)2015-12-29
电测与仪表(2015年8期)2015-04-09
电测与仪表(2015年7期)2015-04-09
