
基于频域特征变分自编码器的轴承故障诊断研究
2023-04-26 08:38邓明洋李长征
计算机测量与控制 2023年4期
邓明洋,李长征,杨 浩
(西北工业大学 动力与能源学院,西安 710072)
0 引言
机械设备在使用的过程中,随着时间的推移,由于一些因素如机械疲劳、操作不当、维护不当等,导致零部件发生破损而产生故障。损坏的机械设备继续运行很可能会导致严重的事故发生,而造成巨大的损失。机械故障诊断技术是一种了解和掌握机器在运行
过程的状态,确定其整体或局部正常或异常,早期发现故障及其原因,并能预报故障发展趋势的技术。运用机械故障诊断技术能够有效的减少安全隐患,避免造成重大损失[1-3]。
基于数据驱动的机械故障诊断是通过对监测信号进行分析,并设计算法进行故障诊断。传统的故障诊断方法是从信号的时域、频域以及时频域进行分析,这类方法的可解释性强,能够很好地阐述某些故障的现象和原因,但需要深入的专业领域知识,并且因为信号本身是经过十分复杂的调制过程形成的,分析方法特别是定量指标存在难以泛化的困难。随着机器学习技术的深入研究,在机械故障诊断领域也得到了广泛的应用。基于机器学习的故障诊断方法的基本流程是,首先通过人工提取一些常用的特征,如时域特征、频域特征、时频域特征等,然后对特征进行筛选,消除冗余信息,达到更好的诊断效果,最后挑选相应的机器学习算法进行训练以及测试故障诊断的效果。相对传统方法,它不需要太过专业的知识[4]。得益于算力的提升以及数据量的增长,深度学习在故障诊断领域也开始广泛应用。深度学习进行故障诊断无需对数据进行人工的特征提取[5],一类方法是将原始信号进行直接输入网络通过一维卷积进行故障诊断[6],另一类方法对原始数据经短时傅里叶变换或者小波变换后转换成图像,输入网络通过二维卷积进行故障诊断[7],但这两类方法对不同分布的数据则需要重新进行训练网络,且网络参数巨大。
自编码器可以看作一种自动提取特征的神经网络,编码网络将原始数据作为输入,通过神经网络压缩为对应的特征,然后解码网络将特征解码为原始数据[8]。对不同分布的数据,使用自编码器进行特征提取,输入到轻量的故障诊断模型进行诊断。这种方法可以共用特征提取网络,且故障诊断模型的参数量小,此外还可以探索不同分布数据的相关性。
由于故障信号是极具复杂,通过自编码器进行提取故障信号的特征,然后根据特征重构出原始信号,在网络规模小的时难以收敛[9]。为了解决这个问题,一些学者提出使用信号频谱作为自编码器的输入,取得了较好的效果。赵志宏等[10]提出了使用故障信号作为输入,重构的是信号频谱,提取出信号的频域特征,从故障信号到对应频谱,相当于只重构信号的部分特征,通过这种方法取得了很好的分类效果。但这种方法使用自编码器将数据样本编码为确定性向量,对噪声的抗干扰性不强[11-14]。
针对上述问题,本文提出采用变分自编码器提取信号频域特征。首先将原始信号输入网络提取频域特征分布,对特征分布加入噪声然后采样得到特征向量,对特征向量重构频谱[15]。这种方法使得特征向量具有一定的不确定性,因此使得特征表示更为鲁棒。进一步,应用局部异常因子算法对信号特征的离群点进行检测和剔除。最后,以频域特征作为输入构建分类算法对不同类型的轴承故障进行分类并验证算法的有效性。
1 相关理论基础
1.1 变分自编码器
自编码器(AE,autoencoder)是一种人工神经网络,用于学习未标记数据的有效编码,属于无监督学习方法,通过尝试从编码中重新生成输入来验证和改进编码。自编码器通过训练网络来学习一组数据的编码,即特征表示,通常用于数据降维[9]。
自编码器的结构如图1所示,自编码器由编码器(Encode)和解码器(Decode)两个部分组成。编码器用于将输入映射到相应的编码,解码器用于将编码重建原始输入。给定输入空间X∈X和特征空间h∈F,定义映射f,g使得输入的重建误差最小[11]:
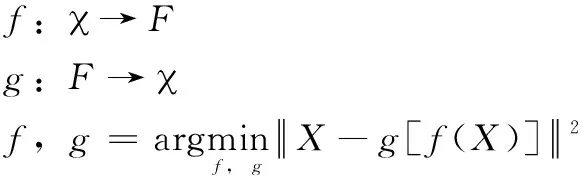
变分自编码器[14](VAE,variational auto-encoders)与自编码器架构有相似之处,但在过程和数学公式方面存在着显著差异。普通自编码器将输入编码成特征空间中的某个确定点;而变分自编码器,将输入编码成特征空间中的概率分布。变分自编码器模型训练过程分为四步:首先,将输入编码成在特征空间中的分布;第二,在这个分布中随机采样特征空间中的一个点;第三,对采样点进行解码计算出损失;最后,损失通过网络进行反向传播优化网络参数。
变分自编码器的目标是使用参数化分布pθ(x)模拟或近似x的真实分布p(x)。设z为潜空间变量,为x更本质的描述。通过联合分布边缘化z表示x:
根据链式规则,方程可以重写为:
pθ(x)难处理导致pθ(z|x)很棘手,变分自编码器采用神经网络来近似后验分布:
qΦ(z|x)≈pθ(z|x)
通过深度神经网络优化参数Φ,使得qΦ(z|x)可以很好的估计pθ(z|x)。通过这种方式将整体问题转换到自编码器框架中,其中条件似然概率分布pθ(x|z)由解码器计算,而近似后验概率分布qΦ(z|x)由编码器计算。
对于深度学习问题,需要定义一个可微的损失函数,以便通过反向传播来更新网络权重。对于变分自编码器,其思路是通过优化解码器模型(生成模型)参数减少输入和输出之间的重建误差,以及参数Φ使得qΦ(z|x)尽可能地接近pθ(z|x)。重构误差使用均方误差,衡量两个分布差异使用Kullback-leibler散度[15]。DKL(qΦ(z|x)||pθ(z|x))具体的表达形式为:
通过变形移项可以将等式重写为:
log(pθ(x))-DKL(qΦ(z|x)||pθ(z|x))=
Ez~qΦ(z|x)(log(pθ(z|x))-DKL(qΦ(z|x)||pθ(z)))
目标是最大化pθ(x)项,以提高生成的数据质量,并最小化真实后验和估计后验的差异。定义证据下界(ELBO,evidence lower bound)损失函数,可以写成:
LθΦ=-Ez~qΦ(z|x)(log(pθ(z|x)))+
DKL(qΦ(z|x)||pθ(z))
鉴于Kullback-leibler散度的非负性质,有如下性质:
-Lθ,Φ≤log(pθ(x))
问题可以概括为,使用神经网络求解最佳参数将此损失函数最小化:
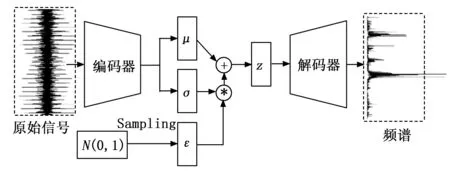
变分自编码器的框架如图2所示,通过重参数化技巧,将随机向量ε作为外部输入注入到潜空间中,将随机性排除在更新过程之外。

图2 变分自编码器结构
关于潜空间的主要假设可以看作为一组多元高斯分布,可以描述为:
z~pθ(z|x)=N(μ,δ2)
鉴于噪声项满足ε~N(0,I)和⊙定义为元素的乘积,重参数化将上述方程修改为:
z=μ+σ⊙ε
1.2 频域特征变分自编码器
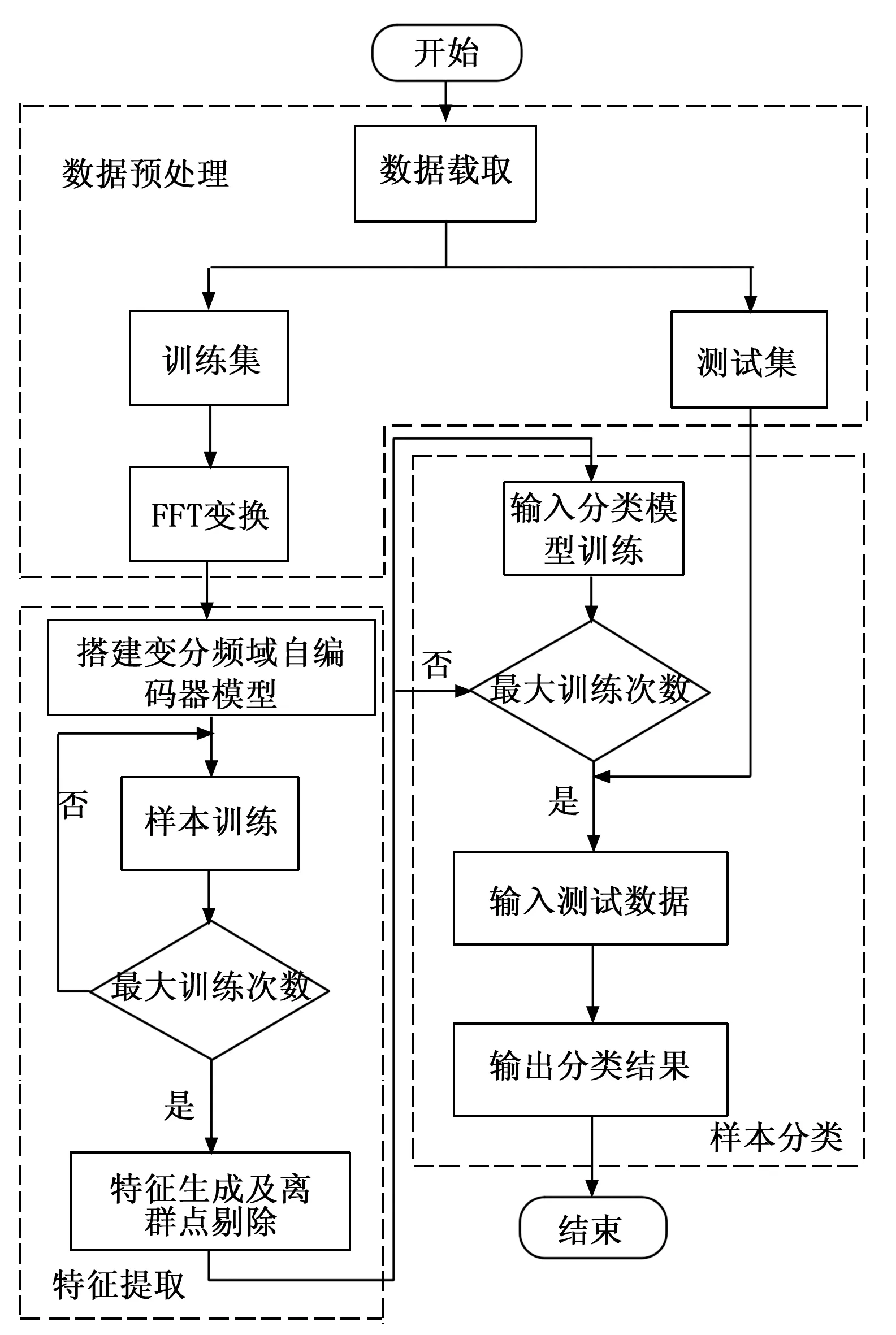
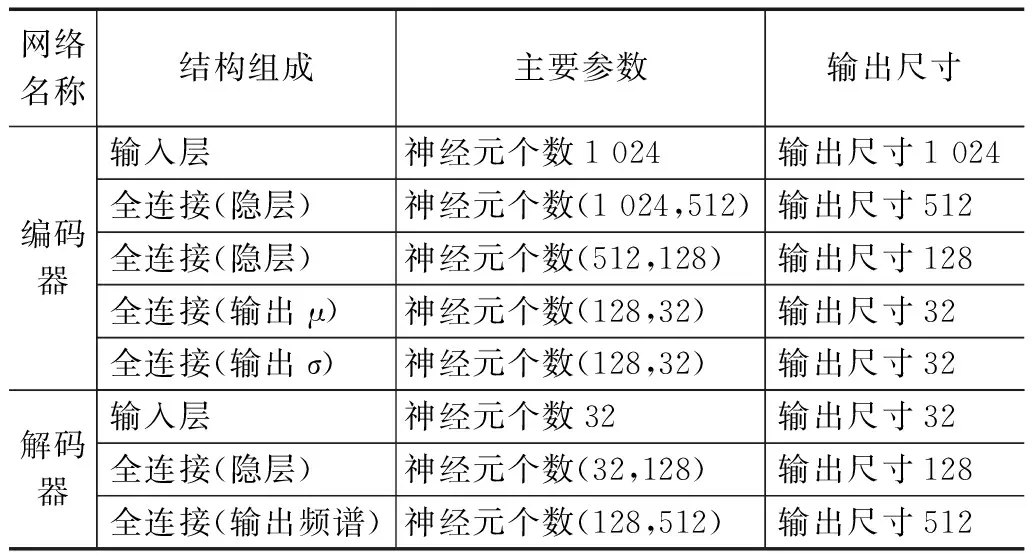
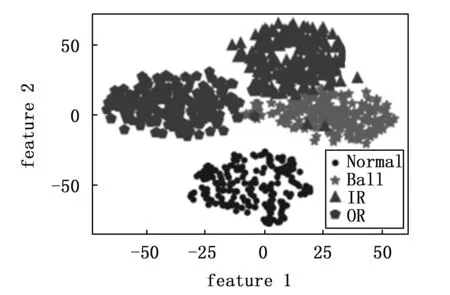
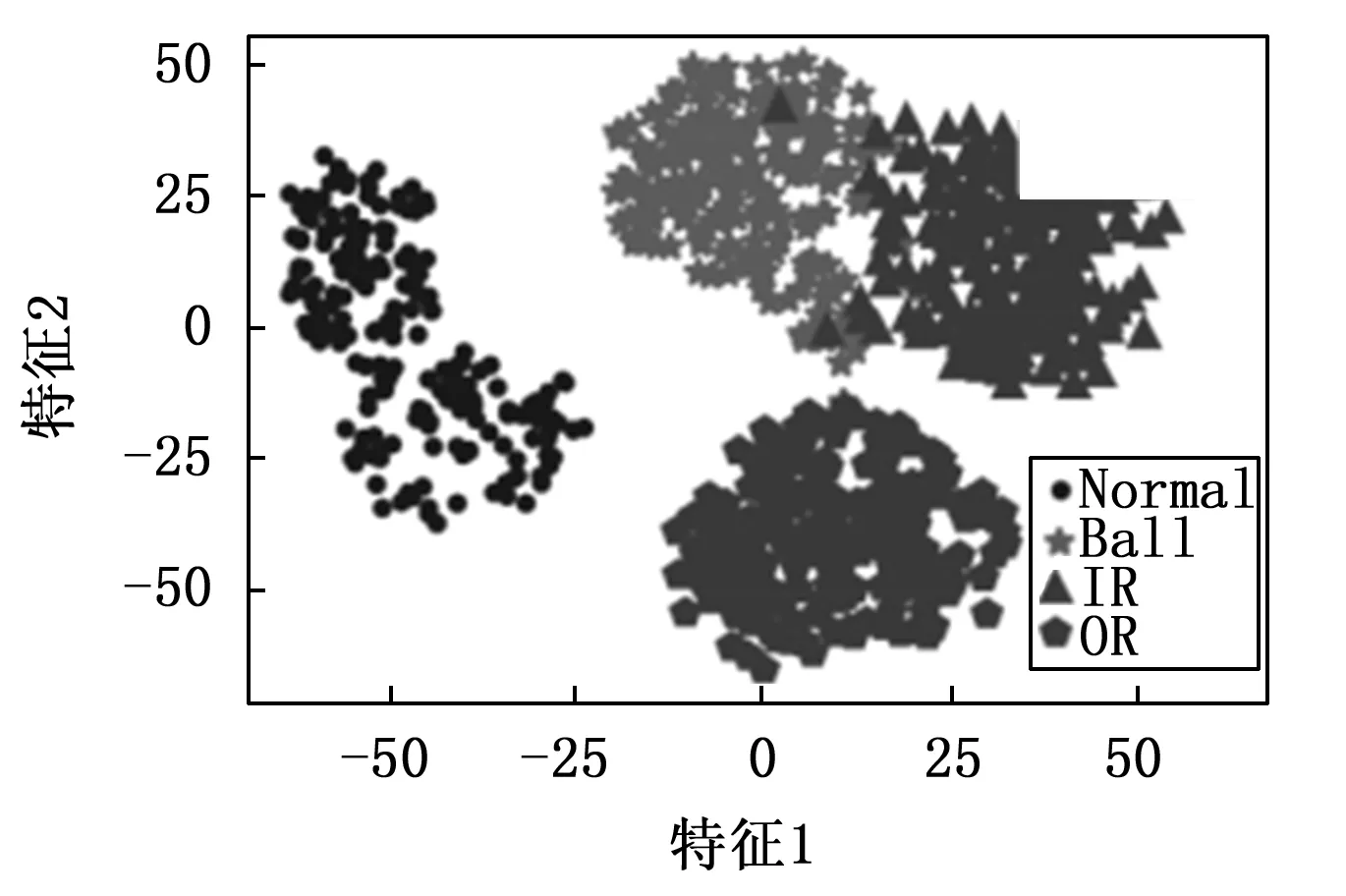
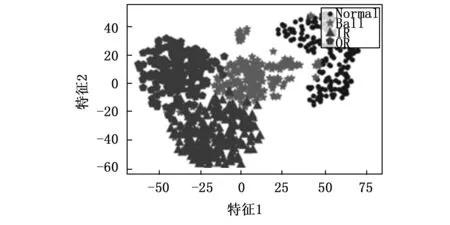
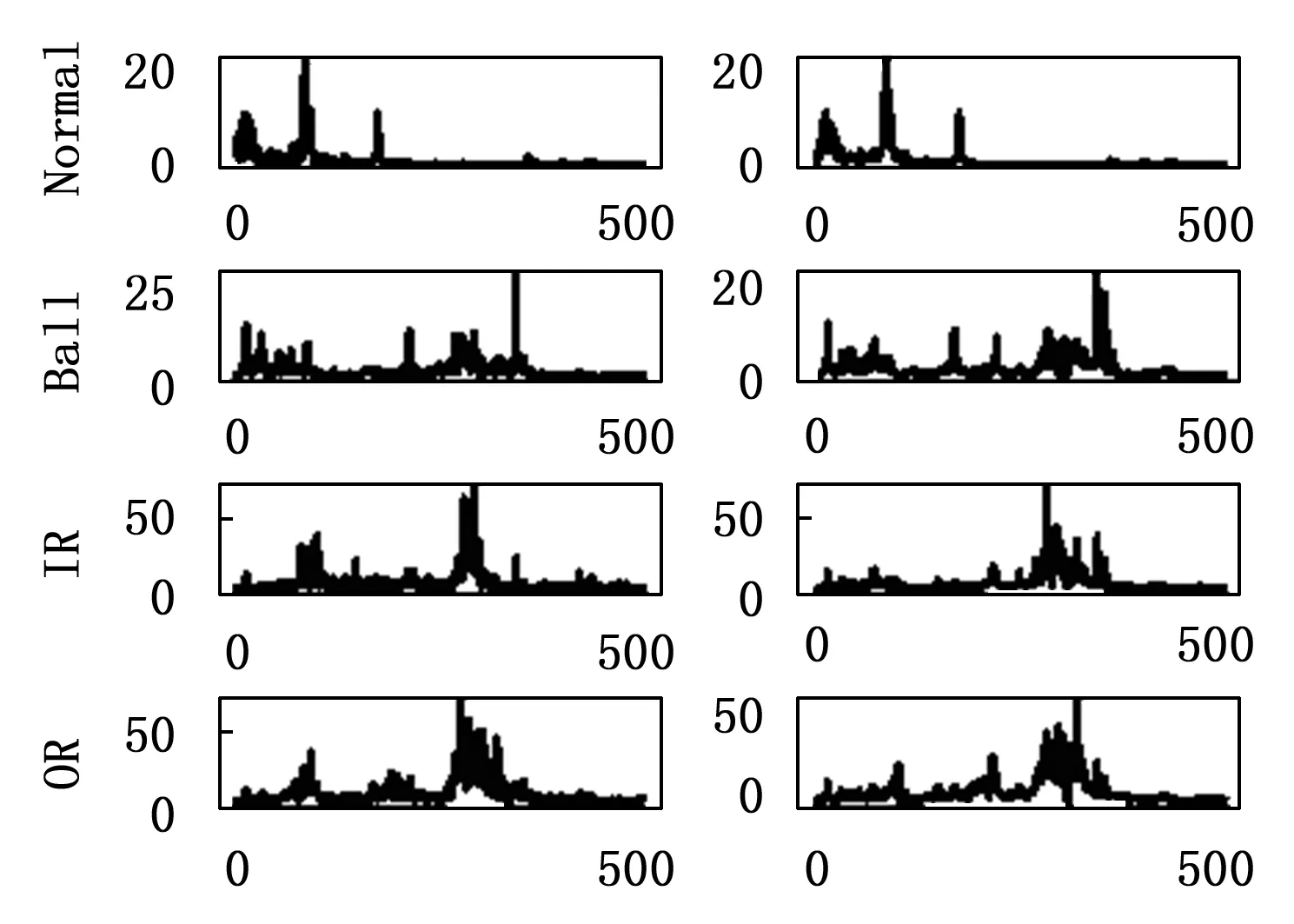
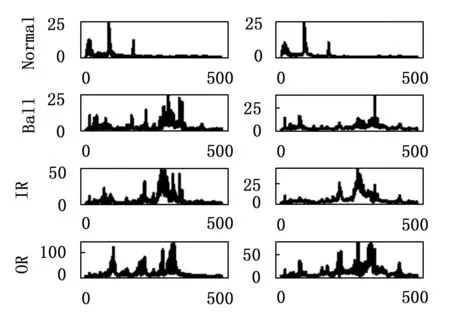
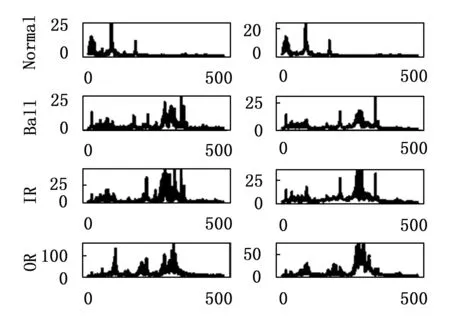
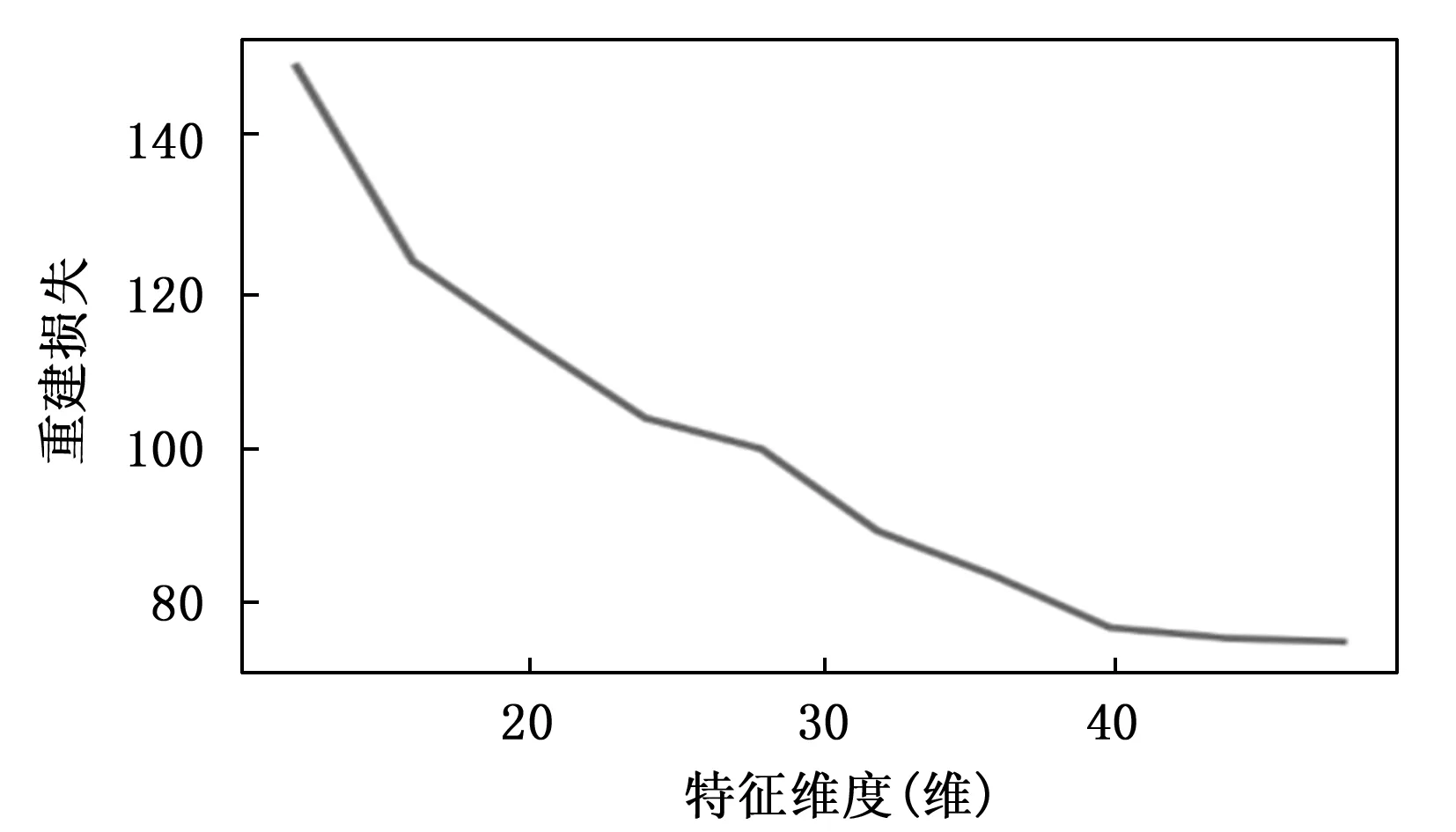
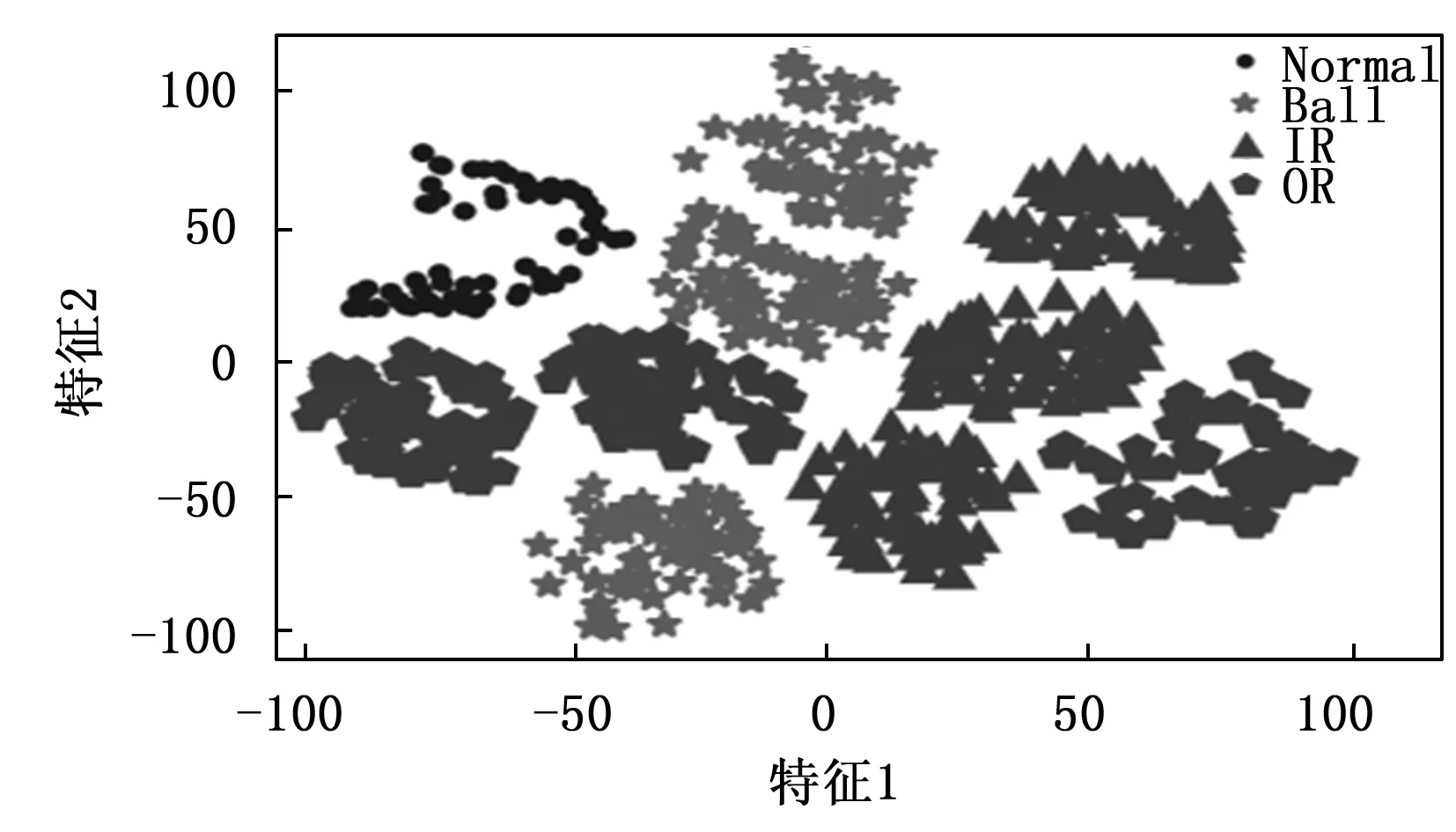
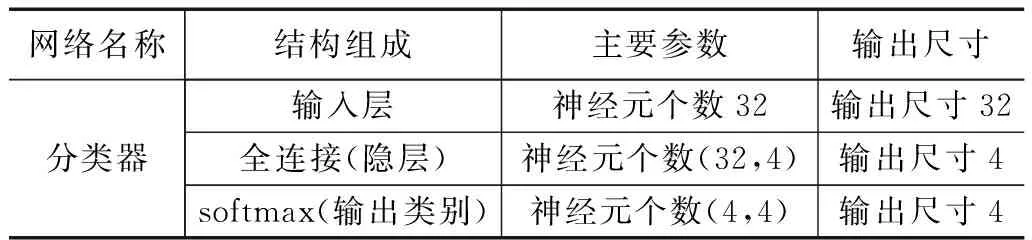
传统的自编码器的目标输出一般为原始信号,且网络结构一般是对称的。通过自编码器提取特征,使用特征分类的过程,即故障诊断过程如图3所示。分类过程只使用了编码网络的输出。所以在保证分类模型的复杂度时,加深解码网络的层数,构建非对称自编码器,使得特征提取的效果更好。此外通过压缩的特征进行重建原始信号,必然会有一定的信息损失。频谱是时域信号在频域下的表示方式,通过对时域信号x(t)进行傅里叶变换得到f(w)=|A(W)|*e(jφ(w)),其中|A(W)|为幅值谱,e(jφ(w))为相位谱,广义上的频谱就是对幅值谱的另一种叫法,从时域信号到幅值谱存在一定的信息损失。计算机在处理的过程中是对采样的信号进行处理,由采样定理可知,给定采样率fs,完全重构频带的限制为B 图3 自编码器分类任务 频域特征变分自编码器的框架如图4所示,输入为原始的时域信号,通过编码器得到频域特征的概率分布,通过对频域特征的概率分布进行重采样得到频域特征向量,解码器对特征向量进行重建频谱。可以看出编码器和解码器为非对称的结构。 图4 频域特征变分自编码器 离群点(outliers)也称为异常值,是与其他观测值有显著差异的值。形成离群点的因素是多种多样的,可能是数据采样过程中噪声引入的误差,也可能是研究对象固有存在各种偶然因素引起的[16-17]。不管何种原因导致离群点出现,都会对数据的分析造成一定的影响。对于故障检测而言,离群点表征某种故障发生时,几率较小的情况,离群点提供了重要的信息,需要单独讨论。而为了让诊断模型泛化性能更好,选择丢弃这些异常值来进行实验。 局部异常因子(LOF,local outlier factor)[18-19]是一种无监督的离群检测方法,采用局部的方法能够对不同密度聚类的离群点进行识别。相关概念如下: 1)点p的第k距离:给定正整数k,定义d(p,o)为点p和点o∈D之间的距离,点p的第k距离定义为k-distance(p)使得: (1)至少有k个点o′∈D满足d(p,o′)≤d(p,o)以及 (2)至多有k-1个点o′∈D满足d(p,o′) 2)点p的第k距离邻域:给定点p的第k距离,点p的第k距离邻域包含所有与点p距离不超过点p的第k距离的点。 Nk(p)={q∈D|d(p,q)≤k-distance(p)} 其中:|Nk(p)为Nk(p)集合中的点数,有|Nk(p)|≥k。 3)点p相对于点o第k可达距离:令k为一个自然数,则点p相当于点o的第k可达距离定义为: reach-distk(p,o)=max{k-distance(o),d(p,o)} 4)点p的局部可达密度定义为: 局部可达密度为点p与其第k距离邻域点的平均可达距离的倒数。表示的是从点p的邻近点到达点p的平均可达性,对于重复点时,这个值变得无穷大。 5)点p的局部离群因子表达为: 局部离群因子为点p第k距离邻域点平均局部可达密度与点p的局部可达密度之比,这是密度值之比,有如下结论: (1)LOFk(p)~1表示点p和邻近点具有相似的密度; (2)LOFk(p)<1表示点p比邻近点的密度更高(内点); (3)LOFk(p)>1表示点p的密度低于邻近点的密度(离群点)。 LOF是通过点p和它邻域点的相对密度来判断是否为异常点。相对密度通过局部异常因子来衡量,异常因子明显大于1的表示离群点,密度通过平均局部可达距离倒数表达,距离越大表明密度越小。LOF是通过点的第k距离邻域来计算,不必全局计算,因此称作局部异常因子。LOF不会因为数据的数据簇的分散情况而误判。 本文提出的故障诊断模型的整体流程如图5所示,它包含数据预处理、特征提取、样本分类3个部分。每个部分的具体作用如下: 图5 故障诊断模型流程 1)数据预处理部分对原始数据进行截取,划分训练集和测试集以及对训练集使用FFT求取频谱; 2)特征提取部分使用训练集训练频域特征变分自编码器,然后使用局部异常因子算法对每一簇的离群点进行剔除得到特征训练集; 3)样本分类即为选定分类器,使用特征训练集进行训练,使用测试集经频域特征变分自编码器提取特征,输入分类器进行分类。 本文的滚动轴承实验数据来自凯斯西储大学(CWRU)轴承数据中心[20],实验装置如图6所示,实验装置由2HP电机(左)、扭矩传感器/编码器(中)、功率计以及电子控制设备(未显示)组成。使用放电加工将单点故障引入测试轴承,在不同损伤程度以及不同负载下采集了多组的振动信号。选取了风扇端轴承在采样频率为12 kHz及负载为0 HP的实验数据。如表1所示,数据的类别分别为正常状态(Normal)、滚动体故障(Ball)、内圈故障(IR)、外圈故障(OR),其中每种故障包含0.007、0.014和0.021三种不同的损伤程度如表1所示,共10种类型的数据。 图6 滚动轴承实验装置 表1 实验数据故障类型 使用滑动窗口方法生成训练集和测试集样本,设定窗口长度为L,窗口的重叠率为R,则可计算出滑动的步长S为: S=(1-R)*L 分别使用滑动窗口法对上述类别数据进行截取,同时通过FFT求取数据的频谱,每种数据生成2 000个样本,把不同损伤程度与正常数据分别组合为数据集A(0.007)、数据集B(0.014)、数据集C(0.021)。 实验所采用的编程环境为Google Colaboratory,是Google提供的一个Jupyter Notebook式的交互环境,搭载python3.7、tensorflow2.8.2。构建频域特征变分自编码器模型进行特征提取,模型具体参数如表2所示,主要参数中的神经元个数括号中第一个参数表示前一层节点的个数,第二参数表示当前层的节点数。训练模型时,批次大小为50,采用Adam优化器,学习率设置为0.000 1,迭代次数500次。 表2 变分频域特征提取自编码模型参数 自编码器是一种无监督的学习网络,在分类任务前进行特征提取,同时需将数据集划分为训练集和测试集,从表2可以看出特征的维度为32,为了直观地展示,将提取到的32维特征使用t-SNE算法进行二维可视化。在数据集A、B、C分别使用训练集进行训练,使用测试集进行验证,通过t-SNE算法得到如图7~9所示的结果。 图7 数据集A的特征降维结果 图8 数据集B的特征降维结果 图9 数据集C的特征降维结果 从图7~9可以看出,3种不同损伤的数据集通过频域特征变分自编码器提取特征,对提取的特征进行t-SNE聚类算法可以明显看出数据集分为四类,类与类之间存在着清晰的界线。此外,有少部分点被t-SNE算法映射别的簇中。 3种数据集的频谱重建的效果如图10~12所示,可以看出重建频谱与原始频谱在形状上是相似的,但是原始频谱中的毛刺被消除了,相当于多个混有噪声的频谱进行平均,说明频域特征变分自编码器能够提取大部分频域特征。 图10 数据集A原始频谱和重建频谱 图11 数据集B原始频谱和重建频谱 图12 数据集C原始频谱和重建频谱 通过对信号进行编码压缩成特征,然后对特征解码还原信号,还原信号的好坏,在一定程度上取决于特征数量,特征数量越多表明表达信息越完整,但是提取特征以及解码特征所需要的计算量也大,所以在保证提取大部分特征的同时也需要对计算量折中,训练集A上不同特征维度对重建损失影响效果,如图13所示。考虑计算量以及性能提升选取了32作为特征空间维度大小。 图13 重建误差随特征维度的关系 此外对数据集A、B、C合并,即把相同类型不同损伤程度的归为一类,通过频域特征变分自编码器对10种故障数据特征进行提取,对提取的数据进行t-SNE算法进行可视化,结果如图14所示。数据的颜色标注和图9~11一致,可以看出数据集存在明显聚类,且不同损伤的数据集之间分布不同。 图14 10类故障数据特征降维结果 为了讨论频域特征变分自编码器+分类模型,对不同分布的识别性能。使用数据集A、B、C的训练集作为训练,利用数据集A、B、C的测试集对分类效果进行验证,分类网络采用一层全连接层以及一层softmax层,具体分类网络的参数如表3所示。 表3 样本分类网络模型参数 使用数据集A、B、C的训练集为训练数据,数据集A、B、C的测试数据验证的结果。诊断结果如表4所示,实验结果表明分类的效果很好,准确率可以达到98%以上。 表4 轴承故障诊断实验准确率 % 此外,区分损伤程度即将故障位置相同但损伤程度不同划分为不同类,即表1所示的10种故障类型。使用同样的方法进行特征提取,输入到10分类的网络分类,结果如表4所示,实验表明达到相同分类效果所需要的分类网络层数明显增多。图14的特征分布可以看出,不同损伤程度数据相似,说明可以通过进一步探究不同损伤程度数据之间的联系。 本文将变分自编码器和频域特征提取自编码器进行结合提出了一种频域特征变分自编码器,使得特征具有一定的不确定性,特征的鲁棒性更强。对提取的特征进行t-SNE二维可视化,发现部分点被t-SNE映射到别的簇中,引入局部异常因子算法对离群点进行检测和剔除,以防止分类器过拟合。在不同损伤程度的数据上进行泛化分类实验,实验表明仅通过两层轻量神经网络可达到98%以上的分类准确率。本文方法所提取的特征对信号具有优异的表达,通过对故障特征进行分类,降低了故障诊断模型的复杂度。同时也可以进一步探讨不同损伤程度的故障、以及不同工况下的故障的区别和联系,对后续研究有一定的参考价值。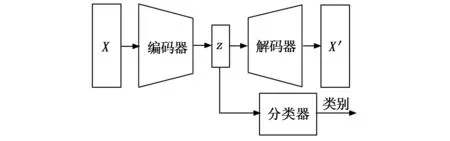
1.3 局部异常因子算法
2 故障诊断模型
3 故障诊断实验
3.1 实验数据介绍与预处理

3.2 特征提取实验及分析
3.3 故障诊断实验及结果分析

4 结束语
猜你喜欢
舰船科学技术(2022年22期)2022-12-13成都信息工程大学学报(2018年3期)2018-08-29雷达学报(2018年3期)2018-07-18电子设计工程(2017年20期)2017-02-10中国房地产业(2016年9期)2016-03-01火控雷达技术(2016年1期)2016-02-06电子器件(2015年5期)2015-12-29作文评点报·低幼版(2015年5期)2015-05-30电测与仪表(2015年3期)2015-04-09西安交通大学学报(2014年8期)2014-04-16
