
基于随机森林的帕金森疾病诊断模型构建研究
2023-04-21 13:10王小科晏峻峰
计算机技术与发展 2023年4期
王小科,晏峻峰
(湖南中医药大学 信息科学与工程学院,湖南 长沙 410208)
0 引 言
帕金森疾病(Parkinson’s disease,PD)为慢性进展性运动障碍病症,可受诸多复杂因素导致锥体外系功能性障碍,且随着人类寿命的延长,PD患者的数量也在不断增加[1]。PD具有持续静止性颤动、肌肉强直、运动障碍等临床表现,同时还伴有语言和发声受限的问题[1-2]。目前新型的帕金森诊断方法包括:基于手绘图特征诊断帕金森病、步态分析和面部表情分析诊断PD,这些研究取得了一定的成果,但是也存在检测过程复杂,对病人身体产生物理损伤等问题,不易进行大范围的PD检测。近年来,大量研究学者提出了各种非侵入性的方法来检测帕金森病的症状。其中在PD的病症表现中,发现几乎所有的PD患者会出现并发症引起的声带损伤,从而出现某种程度的语音障碍[3],因此,检测语言障碍是实现高准确率的PD疾病诊断的可靠手段。
该文采用UCI公开的Speech帕金森语音数据集,首先针对数据集中存在噪声样本以及非均衡数据的问题,使用SVM SMOTE过采样技术均衡数据集,接着采取信息增益特征选择数据集中的八个特征作为最优特征组合并构建RF模型。为进一步提升算法的性能,使用网格搜索与交叉验证相结合的方式寻找RF最优参数,进一步提高了模型的分类准确率。
1 相关研究
近年来在基于语音信息的PD诊断方面的研究,首先是对语音数据提取特征,然后采用机器学习建模的方式进行分类。B.E.Saker等人设计了一个用于数据收集的计算机辅助系统,将参与实验人员的发声数据采集出来,并设计合理的实验方法,从中分析提取出具有较大PD信息的属性特征。Little等人[4]对语言障碍的检测则是通过提取其中的非线性特征,进一步对患者病情的发展情况做出判断。目前国内外从事基于语音信息PD诊断的学者,数据大部分来自这两位研究人员。在特征提取和特征压缩方面,主要研究方法为:主成分分析(Principal Component Analysis,PCA[5])、穷举法[6]、基于局部学习的特征选择法[6]、启发式特征选择等[6]。在疾病诊断模型方面,主要研究方法为:最邻近节点算法(K-Nearest Neighbor,KNN[6])、贝叶斯网络(Naive Bayes,NB[7])、随机森林(Random Forest,RF[7])、最小均方误差回归[8]、BP神经网络[8]、支持向量机(Support Vector Machine,SVM[5,9])等。Kursun等[10]通过基于信息的方法进行排列分析,以得到最佳数据,文献中采用皮尔逊相关系数方法来优选数据;Chen[11]等人使用PCA降维方法,然后再采用模糊K近邻方法进行重新采样的估计方法;通过生物启发算法,如Olivares等基于蝙蝠算法设计的生物极限学习机可以进行分类试验,但是,该方法只能采用梅尔顿倒谱系数,并没有考虑到数据遗漏的问题;李勇明等提出了基于语音样本重复剪辑和随机森林的帕金森诊断算法对帕金森数据样本进行分类诊断,达到了较好的分类准确度,但该方法语音特征较多,效率低下;张琼等人[12]采用改进PSO-SVM算法对不同性能的粒子动态分配惯性权重和学习因子,提高支持向量机模型的学习能力和泛化能力,提高了对疾病的识别精度;郭东伟[13]采用样本约简算法和3种特征降维算法分别结合3种机器学习分类算法对样本分类,得出ELM+NNGIR+KPCA的最佳组合模型;谭言丹[14]设计基于AdaBoost的特征筛选方法并开发基于正则化损失函数的XGBoost来实现最终病情诊断;罗正潮[15]通过中文语音识别PD患者情况,通过发声分析、韵律分析和轮替运动分析提取出患者身体状况的语音特征,使用XGBoost算法提高了中文PD识别的优势;马超等人[16]利用混沌理论和高斯变异方法改进樽海鞘算法,有效地解决了模型的参数设定和最优特征选择问题;张小恒等人[17]提出两步式稀疏迁移学习算法:采用语音段特征同时优选的快速卷积稀疏编码算法和采用联合局部结构信息分布对齐算法,在保持各自样本结构信息的同时最小化分布误差,从而显著提高了算法的准确率。
2 研究方法
2.1 方法总述
算法整体流程如图1所示。

图1 算法整体流程
由于该文所使用的数据集存在非均衡数据和样本噪声的问题,使用SVM SMOTE过采样技术在没有引入更多数据的情况下平衡二分类数据;使用信息增益特征提取根据信息增益大小排序选取得到8个特征作为最优特征组合;构建RF帕金森疾病诊断模型,并使用网格搜索和交叉验证相结合的方式进行参数调优;最后使用该模型对测试集进行样本分类。
2.2 SVM SOMTE

(1)输入整个数据集,SVMs-K的数量,Extrapolation Borderline-SMOTE的过采样率α%。

(3)将t从1到K循环。


(7)输出支持向量机的集合F(x)=sgn(∑tf(x))。
2.3 信息增益特征选择
信息增益通过计算信息熵而来,量化了信息去除不确定性的程度,可以通过信息增益的大小为变量排序进行特征选择。信息量与概率两者之间呈单调递减关系,概率越小,信息量越大。
2.3.1 信息量
其中,u表示发送的消息,ui表示发送信息u的一种类型。
2.3.2 先验熵
信息熵表示信息量的数学期望,是信源发出信息前的平均不确定性,也称为先验熵。信息熵的定义如下所示:

当ui中某一种类型的概率为1时,即没有发送消息的不确定性,信息熵Ent(U)=0;
当ui对应的概率相同时,即概率都为1/k,信息熵Ent(U)=log2k。
2.3.3 后验熵
信息熵Ent(U)表示在发出信息U之前存在的不确定性,在接收搭配信息V之后,信息U的不确定性会发生改变,即后验熵,它是接收到一定的信息后,对信息U进行的后验判断,定义如下:

考虑所有信息V时,得到的后验熵的期望(又称条件熵)如下,Ent(U|V)是指在V结束之后存在对信息U的平均不确定性,通常由随机干扰引起。

2.3.4 信息增益
信息增益是指先验熵与后验熵差值部分,表示信息消除不确定性的程度,定义如下:
Gains(U,V)=Ent(U)-Ent(U|V)
特征选择原理:对数据集选择特征时,以目标标量作为信息U,由特征变量作为信息V,代入公式计算信息增益,以信息增益的值按照大小顺序来确定特征的顺序,以此进行特征选择。信息增益越大,表示变量消除不确定性的能力越强。
2.4 随机森林
随机森林(Random Forest,RF)主要思想是在原始的数据集上随机挑选P个样本作为训练集以生成相应数量的决策树,在挑选最佳属性时,RF并非像决策树一样让所有的属性都参与选择,而是随机选择Q个属性用于构建决策树,然后将这些决策树构成一个森林,RF中每一棵决策树之间是独立无关联的。当RF构建完成之后,输入新的数据样本,决策森林中的所有决策树均会做出判断并将输出最多的类别作为最终的模型诊断类别。
具体实现过程如下:
(1)对原始训练集M使用bootstrap方法,在M中有放回随机选取X个样本集合,构成X个分类树,每次没有被选中的数据样本构成K个袋外数据;
(2)假设有ma个变量,在决策树的所有节点处均随机抽取mt变量(mt,n,ma),然后在mt挑选分类能力最强的变量,最后通过测量每一个分类点确定变量分类的阈值;
(3)所有决策树均可以得到最大限度的生长,也无需任何修剪;
(4)将生成的所有分类树构成RF并输入新的数据进行分类判断,根据树分类器的投票结果作为输出类别的判别。
3 实验过程及分析
实验总共包括三个部分:(1)针对数据集中存在噪声样本以及非均衡数据的问题,使用SVM SMOTE过采样技术对数据进行均衡处理。(2)使用信息增益特征提取算法对该数据集进行特征提取,选取八个特征作为最优特征组合,将样本映射到更加低维的特征空间,减少了系统的计算时间,同时提高了模型的准确率。(3)构建RF帕金森疾病诊断模型,由于RF参数n_estimators的取值范围过大,首先使用学习曲线的方式学习参数n_estimators的大致范围,接着使用网格搜索和交叉验证相结合的方式寻找RF模型的最佳参数组合,进一步提升了诊断模型的准确率。
3.1 数据集及预处理
3.1.1 实验数据
该数据集是由英国牛津大学的Max Little[4]与科罗拉多州丹佛市的国家语音和语音中心联合建立。由三十一个患者发送固定的元音‘a’,其中二十三人属于PD患者,八人健康,从而得到一组生物医学语音检测信息,总计197条信息,23个属性特征以及1个标签。属性分别为:平均声部基频MDVP:Fo(Hz),最大声部基频MDVP:Fhi(Hz),最小声部基频MDVP:Flo(Hz),基频变化的几个度量MDVP:Jitter(%)、MDVP:Jitter(Abs)、MDVP:RAP、MDVP:PPQ、Jitter:DDP,振幅变化的几个度量MDVP:Shimmer、MDVP:Shimmer(dB)、Shimmer:APQ3、Shimmer:APQ5、MDVP:APQ、Shimmer:DDA,语音状态中噪声与音调分量之比的两种测量NH、HNR,两种非线性动态复杂性测量RPDE、D2,信号分形缩放指数DFA,基频变化的三种非线性测量spread1、spread2、PPE,姓名name。标签为status,1表示患者,0表示健康。
3.1.2 数据预处理
在该数据集中姓名name属性列描述患者的姓名,对实验没有实质的用途和意义,所以在数据集中将姓名属性列移出,即所使用的数据集为22个属性列,1个标签列。另外,由于数据集的特征取值范围各不相同,该文将数据做归一化处理,将数据映射到0-1之间,使得特征之间持有相同的度量尺度。公式如下:
其中,xmin和xmax是指要归一化数据的最小边界和最大边界。x为原始数值,xscale为归一化处理之后的数值。
3.1.3 SVM SMOTE均衡数据集
该语音数据样本标签严重不平衡,其中标签为1的样本数量为147,标签为0的样本数量为48。从数据角度来看,造成数据稀疏问题:数据的缺失导致模型对稀疏数据刻画能力不足,无法对此类样本进行分类;从分类器的角度看,会造成决策边界偏移问题:因为多数类样本数量远大于少数类样本数量,导致学习的分类界限更偏向于多数类,造成决策边界的偏移,最终使得模型的分类性能下降。SVM SOMTE算法的核心思想是聚合各种支持向量机,通过向正确的方向构建合成少数样本来修正初始决策边界,再以插值的方式为少数样本生成合成样本以达到均衡数据集的目的。图2为数据集均衡前数据集各属性和标签的数据分布直方图,图3为数据集均衡后各属性和标签的数据分布直方图,两图中最后一个直方图为标签数据分布图。

图2 SVM SMOTE均衡前数据分布直方图

图3 SVM SMOTE均衡后数据分布直方图
3.2 实验环境与参数设置
3.2.1 实验环境
PD诊断模型运行在windows10系统PyCharm2021.3.2平台下,基于Anaconda开发环境下Python3.8编写运行。实验以70%的PD数据集作为训练集,30%作为测试集,根据测试集的分类结果对模型进行评估。
3.2.2 信息增益特征选择选取最优特征组合
该文采用的语音数据集包含196个样本,22个特征,1个标签。与样本量相比,特征数量相对较多,大胆假设这些特征中必然存在无关特征和冗余特征,这些特征对算法毫无意义,无法提升算法的性能。另外。还存在一些冗余特征可以由其他特征推断而来,这种情况下,可以通过特征选择减少数据的特征维度,过滤数据噪声提高模型精度,同时降低学习任务的难度。信息增益特征选择通过比较特征值划分数据集所获取的信息增益,选取信息增益最高的特征划分数据集。具体流程为:(1)根据公式计算原始信息熵H;(2)选取一个特征,用特征值进行分类并计算类别的信息熵,以一定的比例加和得出该划分方式下的信息熵H';(3)计算信息增益,即H-H';(4)根据(2)、(3)计算所有特征属性对应的信息增益,保留信息增益较大的特征属性。经过算法选择后选取出的最优特征数量为8,分别为MDVP:Fo(Hz),MDVP:Fhi(Hz),MDVP:Flo(Hz),Shimmer:DDA,HNR,spread2,PPE,D2。
3.2.3 随机森林参数优化
构建RF模型,使用网格搜索[13-14]参数寻优寻找RF全局最优参数组合时,由于参数n_estimators搜索的范围较大,倘若网格搜索遍历的步长较小且要包含最优解,那么会出现计算量过大而降低电脑运行速度等问题。通过刻画参数n_estimators学习曲线的方式编码绘制RF参数的学习曲线,确定参数大致取值范围,再使用网格搜索在该范围内进行精细搜索,进一步获得包括参数n_estimators在内的参数的最优组合。图4为参数n_estimators的学习曲线,由图可知参数的最优值大致在25左右,因此确定网格搜索该参数的范

图4 参数n_estimators学习曲线
围为20到30。对于其他参数由于在参数n_estimators确定后的取值范围较小,可直接使用网格搜索寻找最佳值。经网格搜索计算,该参数的最优组合为n_estimators=25,criteriion=“gini”。
3.3 评价指标
使用准确率(Accuracy)、灵敏度(Sensitivity)、特异度(Specificity)作为算法的判断指标,以此来检验文中模型的合理性。准确率指数据中被正确诊断的病人数量与总样本数的比例;而灵敏度又叫真阳性比例,即实际发病且被准确诊断的病人所占比例;特异度又称为真阴性率,是指实际无病并能准确检测的病历所占比例。具体包括:
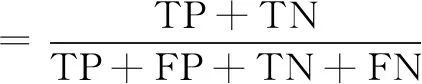


其中,TP为真阳性例数,TN为真阴性例数,FP为假阳性例数,FN为假阴性例数。
3.4 结果分析
表1分别为经过SVM SMOTE算法均衡数据集、通过特征提取以及网格搜索交叉验证优化RF参数后的模型评估指标。由表可知,原始RF算法的准确率、灵敏度和特异度分别为92.38%、96.54%、80.17%;经过SVM SMOTE算法均衡数据之后,准确率提升至94.76%,灵敏度和特异度也分别提高至94.37%和97.33%;特征提取获取最优参数组合后,模型的准确率、灵敏度和特异度分别为96.02%、94.93%和95.42%;利用网格搜索寻得RF的最佳参数之后,RF模型的准确率、灵敏度和特异度分别为96.59%、94.81%和95.49%。

表1 RF诊断模型结果对比 %
为了验证所提出方法的有效性和先进性,基于SVM SMOTE和信息增益提取目标特征子集之后构建的RF模型,就多项指标与现有研究中具有代表性的模型,如SVM、KNN、NB、XGBoost、DT进行了详细对比,表2展示了对比结果。

表2 不同分类器性能对比 %
从表中可以看出,RF模型实现了最佳的准确率,其灵敏度稍低于DT,其特异度低于KNN,然而当指标数值在85%到95%的范围时,即可判定该指标性能良好。可见,文中模型具备较好的泛化性能。
4 结束语
文中数据来源于kaggle官网,由英国牛津大学的Max Little[6]与科罗拉多州丹佛市的国家语音和语音中心合作创建。通过使用SVM SMOTE均衡算法均衡数据集使得样本达到平衡,特征选择根据信息增益的大小排序选取得到8个特征,进而建立了基于RF的PD疾病诊断模型,并使用网格搜索和交叉验证相结合的方式进行参数调优进一步提高模型的准确率。与传统RF相比,PD诊断模型在准确率、灵敏度和特异度上的表现均有提高,实验的有效性得以证明。
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20
电子制作(2019年19期)2019-11-23
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
电子制作(2018年19期)2018-11-14
电子制作(2017年23期)2017-02-02
西北工业大学学报(2015年4期)2016-01-19
振动工程学报(2014年4期)2014-03-01
