
基于强化学习的多智能体泛化性研究
2023-04-21 13:10何召锋
计算机技术与发展 2023年4期
郭 鑫,王 微,青 伟,李 剑,何召锋
(北京邮电大学,北京 100088)
0 引 言
从智能机器人[1],交通信号控制[2],动态频谱分配[3],到智能电网经济调度[4],实时竞价[5]等众多领域,多智能体强化学习算法都取得了不错的成果。但在复杂的场景下,使用强化学习的方法仍然具有挑战性。因为现实世界的复杂性,训练时和测试时的环境通常会发生一些变化,这样的环境要求智能体具有泛化到不可见状态的能力。近年来,在解决多智能体强化学习泛化性方面,学者们也做了大量研究。
深度确定性策略梯度算法(M3DDPG)[6]、值的极小化极大化算法(Qmixmax)[7]、Romax[8]等采用了极小极大化的思想考虑最坏情况并优化最小化目标。此外,文献[9]将基于核的强化学习与深度强化学习结合起来,文献[10]通过多数投票决定每个智能体的行动,而忽略了智能体间的交互。文献[11]中多智能体深度确定性策略算法(MADDPG)随机使用训练的多个策略网络。但是这些方法计算量太大,局限性强,没有发挥不同策略的优势。
该文关注到集成方法在泛化性方面的优越性能,提出基于人类偏好的角色策略集成方法。主要贡献在于:
(1)将多智能体强化学习与集成方法结合,使得智能体学习多种策略,在不同情况应用不同的策略,充分发挥各策略的优势,有效提升了智能体的泛化性。
(2)结合生命史理论和集成算法,综合考虑短期利益和长期回报,解决了训练中过度探索和无效训练的问题,使得智能体能快速找到最优策略。
(3)提出角色参数共享机制,相比于传统的全部智能体共享参数,创新在于为智能体动态地划分角色,同角色的智能体共享参数。该方法不仅提高了效率,而且实现了多智能体算法的可扩展性。
(4)在包含合作、竞争和混合场景的多智能体粒子环境中,实验结果表明该算法相比现有多智能体强化学习算法在泛化能力和训练速度方面都有很大的提升。
1 多智能体强化学习相关工作
1.1 多智能体强化学习
通常,多智能体强化学习过程可以表示为马尔可夫博弈[12],记作(N,S,O1,…,ON,A1,…,AN,Γ,R1,…,RN),包括智能体集合i∈N={1,2,…,N}、状态空间S、联合观测空间O,以及联合动作空间A。智能体i仅可得到关于当前状态S的局部观测Oi。转移函数Γ定义了基于当前状态和动作所能到达的下一状态的分布S×A→S';而S×A×S'→R定义了智能体i在t时刻接收到的奖赏函数。算法的学习目标是找到一组使每个智能体均可获得最大累计奖赏Ri的策略π=(π1,π2,…,πN),γ是折扣因子,T是一个执行周期的步长。
1.2 集成算法
在集成算法中,多个策略被训练,然后智能体从它们集成的多个候选动作中选择动作。集成方法起源于单智能体强化学习,例如利用Q值函数、网络结构和策略的集成。文献[13]提出了各种聚合动作的方法来帮助智能体选择更好的行动,如多数投票、加权投票、等级投票、波尔兹曼乘法等。Bootstrapped DQN[14]、UCB[15]、DBDDPG[16]等通过集成Q值使智能体拥有更好的动作。之后,集成的方法不断发展,在多智能体强化学习中也开展了大量研究。文献[9]将基于核的强化学习与深度强化学习结合起来,整合了两种算法的优点。文献[10]通过智能体的多数投票决定智能体的行动。文献[11]使用多个行动-评估(actor-critic)结构,并在每个事件中随机选择其中之一。文献[17-19]也将集成方法应用在多智能体系统中。
2 基于人类偏好的多智能体角色策略集成算法
本节首先介绍了基于人类偏好的策略集成方法,然后根据肯德尔系数,介绍了角色共享参数机制的细节。该方法的概述如图1所示。

图1 基于人类偏好的多智能体角色策略集成方法
2.1 基于人类偏好的策略集成方法
集成学习通过结合多个策略完成学习任务。传统的集成学习方法通过随机、大多数投票,均值等机制获得唯一的结果,但这些方法都没有发挥每个策略的优势。在这部分,将介绍如何发挥每个策略的优势使得训练更快,效果更好。

(1)
依据生命史理论[20-21],考虑到即时奖励的重要性,从这M个较大的长期回报内选择具有最大的即时奖励的动作,如下式所示:
(2)
其中,ki为智能体选择的动作对应的策略的下标。之后,在更新阶段,智能体的M套策略只需要随着每次的选择更新ki策略,如下式:
(3)

(4)
由于训练阶段可以随意取得每一个动作的即时奖励,但测试阶段无法轻易获得即时奖励,为了解决这一问题,该文提出了一个辅助预测奖励网络。该网络为多层感知器网络,通过训练阶段的即时奖励训练网络对于每一个动作的预测值。其损失函数如下式所示:
(5)
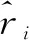
2.2 角色参数共享机制
针对智能体学习多个策略引发的计算消耗大的问题,本算法引入角色共享机制解决该问题。角色被理解为接受信息、加工信息和发送信息的抽象对象。角色参数共享机制认为:角色是按照策略执行行为的统一体,所以将策略相近的智能体划分为同一角色。在这部分,将介绍如何利用肯德尔系数,衡量智能体之间的相关性,然后智能体动态地划分为不同的角色,同角色的智能体学习和使用同一套策略。
智能体间的相关性可通过分析它们的即时奖励的序列的相关性得到。例如:智能体i和智能体k的即时奖励的序列如下式:
(6)
肯德尔系数的计算公式如下式所示:
(7)

定义1 强相关:设定阈值G,如果两个智能体的肯德尔系数值大于阈值G,则定义这两个智能体具有强相关性。
定义2 最大相关:对于智能体i,计算相关性。通过最大值T(i,k)得到智能体i和智能体k有最大相关性。
如果两个智能体的肯德尔系数值同时满足定义1和定义2,则这两个智能体被划分为同一角色,学习和使用同一套策略。
2.3 基于人类偏好的多智能体角色策略集成算法
在基于人类偏好的多智能体角色策略集成算法中,训练阶段,同角色的智能体共同训练M个策略网络以及一个辅助预测奖励网络。更新阶段,只更新执行动作的策略网络。在测试评估阶段,由于集中训练和分散式执行,通过辅助预测奖励网络选择动作。算法流程具体如算法1所示。
算法1 基于人类偏好的多智能体角色策略集成(HPMARPE)算法。
初始化:具有N个智能体的E个并行环境,经验回放缓冲区D,策略网络π,辅助预测奖励网络f。
(1)for episode=1toN,进行迭代:
(2)fort=1 toT,进行迭代:
(3)form=1 toM:
(6)结束
(7)选择动作和策略
(8)执行行动,智能体得到奖励r,同时转移到新状态st+1
(9)将(o,a,r,k,o')存入经验回放缓冲区
(10)for agent=1 ton,进行迭代:
(11)采样经验(o,a,r,k,o')
(12)更新策略网络
(13)通过最小化损失Lr更新网络f
(14)结束
(15)更新目标网络:
(16)结束
(17)结束
3 实 验
3.1 实验环境
该文采用的是多智能体粒子环境[11]。在合作、竞争、混合场景下分别进行了实验,实验用到的场景如图2所示。
图2(a)为漫游者-塔的合作场景。该任务包含N+M个智能体,L个目标地,其中包含N个漫游者,M个塔。漫游者和塔随机配对,漫游者的目标是到达正确的目的地,然而不知道目的地的位置,配对的塔指挥漫游者到达指定的目标地,依据他们与正确的目标地的距离获得奖励。
图2(b)为捕食者-猎物的竞争场景。在该场景下,速度较快的捕食者追逐速度较慢的猎物。每当捕食者追逐到猎物时,猎物受到惩罚,捕食者获得奖励。
图2(c)为物理欺骗的混合场景。在该场景中,N个智能体相互合作对抗敌对智能体,他们的目标都是到达目的地,但敌对智能体不知道目的地在哪。合作的智能体中只要有一个到达目的地,则所有智能体获得奖励,敌对智能体受到惩罚。

图2 多智能体粒子环境
3.2 对比算法
为了验证所提的基于人类偏好的多智能体角色策略集成(HPMARPE)模型的泛化性和可扩展性,该文与DIRS-V[10]、MADDPG-S[11]、MADDPG-R[11]进行比较。
(1)DIRS-V:在该方法中,每个智能体通过所有智能体的多数投票决定每个智能体的行动。
(2)MADDPG-S:该方法为多智能体深度确定性策略算法,每个智能体仅训练一个策略。
(3)MADDPG-R:针对智能体的泛化性问题,该方法同样提出策略集合的思想,每个智能体训练多个策略,优化策略集合的整体效果,在测试时,随机选用其中的子策略。
3.3 结果分析
为了验证算法的有效性,本节主要从泛化性、训练效率、可扩展性来对比评估算法的优越性。
(1)智能体的泛化性。
为了验证该方法训练的智能体的泛化性,将训练多次得到的智能体的策略随机组合进行测试,以此来评估智能体在面对其他智能体新的策略时的性能。竞争、合作、混合场景下实验结果分别展示在表1~表3中。表1展示了猎物被捕捉的次数,从表中可看出,经过HPMARPE训练的智能体对抗使用单一的策略的敌对智能体时,整体取得了最好的效果。表2展示了合作场景下的漫游者距离目的地的距离,距离越小,效果越好。从表中可知,合作的智能体都使用基于人类偏好的多智能体角色策略集成算法(HPMARPE)时,智能体配合良好,取得了最好的效果。这是符合预期的结果。表3显示的是复杂的混合场景下智能体和敌对智能体的成功率,差值越大,效果越好。与竞争和合作环境下的实验结果相一致,在该场景,合作的智能体使用HPMARPE对抗单一策略的智能体会取得最好的效果。

表1 捕食者-猎物场景下的测试结果

表2 合作场景下的测试结果

表3 混合场景下的测试结果
综上,使用集成策略的智能体优于使用单一策略的智能体。然而,使用基于人类偏好的策略集成方法的智能体又显著优于使用其他策略集成的智能体。
(2)角色参数共享方法的性能。
图3为算法中不同的角色参数共享下的训练结果。阈值G对智能体的角色划分起着重要作用。为了研究该方法在不同的阈值G下的影响,分别设G=0、0.3、0.5、0.7和1.0。G=1.0意味着每个智能体都是一个单独的角色,这时算法为无共享机制,所有智能体学习自己的多个策略。而G=0表示所有智能体同属于一个角色,共享同一套策略。从图3可以看出,G=0.7时算法在图中取得了最佳性能。事实上,过小的阈值G将一些弱相关的智能体归入同一角色,这使得智能体共享一些模糊的策略,因此妨碍了他们的学习。过大的阈值G会把智能体分成多个角色,每个智能体训练数据单一,这使得它很难达到最优性能。上述的实验结果表明采用一个合适的阈值G,一方面会避免无效训练,另一方面增加了数据的多样性,从而算法性能获得提升,因此需要适当的阈值G将智能体进行分类。
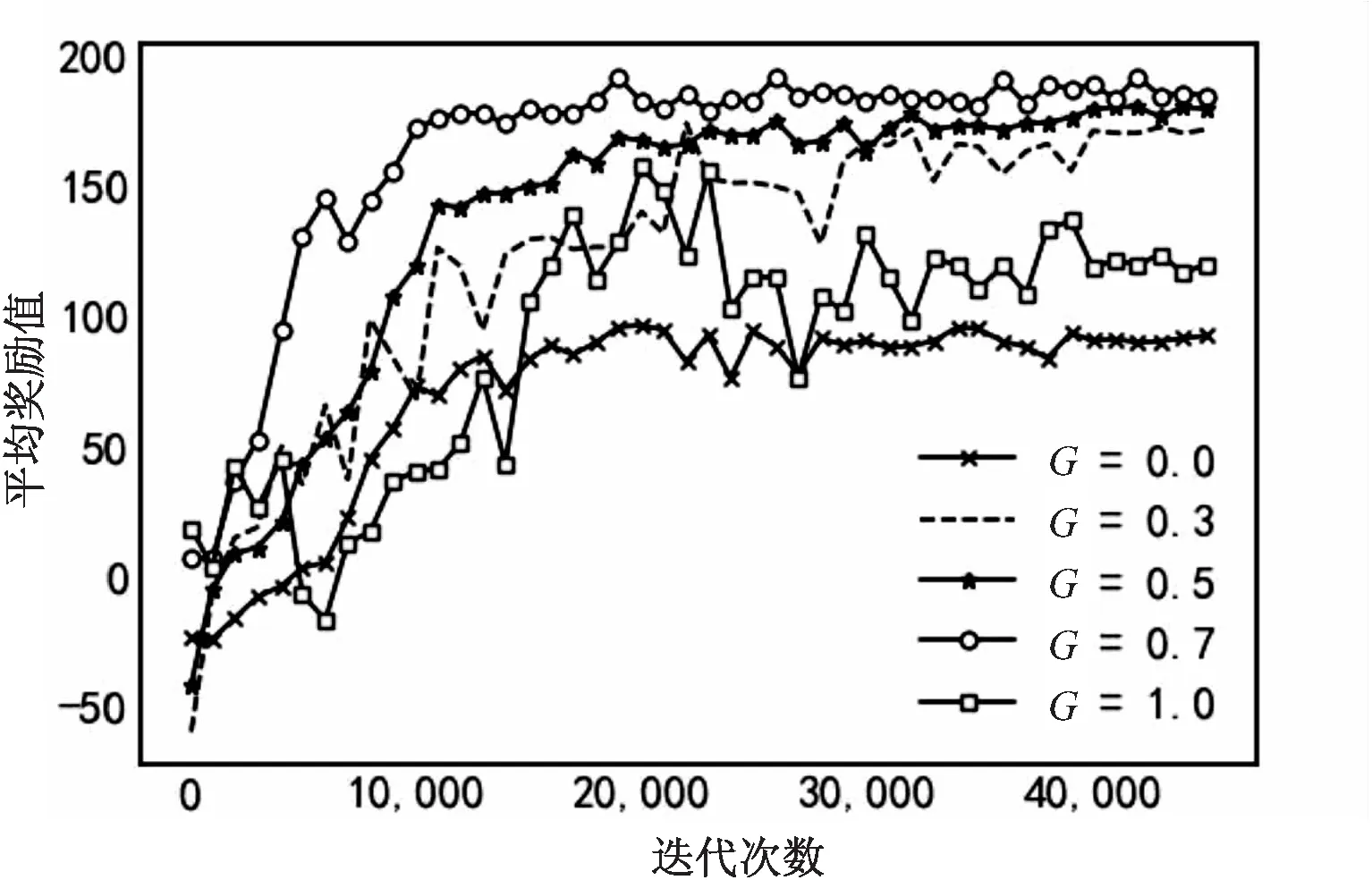
图3 角色划分的影响
(3)训练效率。
此外,角色参数共享机制还影响了算法的训练效率,从图3不同阈值下算法的收敛变化比较中可以看出,G=0.7时算法最先达到收敛,大概在10 000迭代次数左右,G=0.5时算法在20 000迭代次数左右收敛,其余阈值下,20 000步之后仍然未达到收敛。这是因为,合适的阈值下,同角色下的不同智能体共同学习和训练,使得学习效率大大提高,从而可以在更少的迭代次数下收敛。该实验结果验证了角色参数共享机制可以有效提升训练效率。
(4)可扩展性。
为了检验角色参数共享方法在可扩展性方面的影响,在训练环境上学习模型,在智能体数量与训练环境不同的场景上对学习到的策略进行测试,没有额外的再训练,以此来确定该方法的可扩展性。表4显示了在合作场景中的实验结果,表中N*N代表环境中的智能体数量。实验结果表明:当测试环境中智能体的数量增加时,该方法(HPMARPE)显著优于MADDPG,其成功率只有小幅波动,而MADDPG方法训练的智能体成功率大幅下降,且智能体数量增加越多,性能下降越多。这是因为,在该方法中,当环境中新增智能体时,该智能体依据自己的目标和动作的奖励值确定所属角色,从而可以采用该角色在训练环境下学习与训练的多套策略,在不同情况下做出不同的应对,以此来保持性能稳定。

表4 合作场景下的可扩展性测试结果
(5)超参数的影响。
为进一步评估策略集成方法的影响,图4显示了在合作场景中不同数量的策略进行集成的实验结果。K是策略的数量,不同数量的策略使智能体有不同规模的行动集。从结果中可以看出,设置过大的K对性能的影响很小。此外,如果策略的数量大于动作空间的尺寸,它甚至会导致性能下降。

图4 合作场景中策略数量的影响
4 结束语
该文研究了多智能体强化学习的泛化性问题,提出了一种基于人类偏好的多智能体角色策略集成算法。该方法首先使用基于人类偏好的策略集成的思路,综合考虑即时奖励和长期回报,解决了智能体策略改变引发的泛化性问题,同时提出角色参数共享机制,根据历史行动的即时奖励将智能体动态分为不同的角色,智能体按角色共享参数,减少计算资源的同时实现了可扩展性。该算法在多智能体粒子环境的多个场景上进行了实验,与其他现有的方法相比,在泛化性和训练效率上,都有极大的提高。
猜你喜欢
制造技术与机床(2019年9期)2019-09-10
西南交通大学学报(2018年6期)2018-12-18
文苑(2018年23期)2018-12-14
文苑(2018年19期)2018-11-09
文苑(2018年17期)2018-11-09
文苑(2018年21期)2018-11-09
河北遥感(2017年2期)2017-08-07
汽车零部件(2017年3期)2017-07-12
自动化博览(2017年2期)2017-06-05
衡阳师范学院学报(2016年3期)2016-07-10
