
基于模型融合的车辆跟驰模型研究
2023-04-19 06:38:48吴至锦曹从咏
智能计算机与应用 2023年3期
吴至锦, 曹从咏, 孔 进, 陈 鑫
(南京理工大学 自动化学院, 南京 210094)
0 引 言
车辆跟驰(Car Following, CF)是微观驾驶中最基本的行为,车辆跟驰模型是交通流理论的基础。20 世纪60 年代初期,Chandler、Herman 和Gazis 等学者提出并改进了GM 模型,开创了微观交通流理论的研究[1-2]。 Michaels 等学者[3]、Kometani 等学者[4]分别提出了心理-生理类模型和安全距离模型。 2000年,Treiber 等学者[5]基于自动驾驶技术提出了智能驾驶员(IDM)模型。 IDM 模型是目前较为完整、简单的无事故理论跟驰模型,且该模型数值模拟得到的结果与实测数据一致性高。 以上模型都可以统称为模型驱动跟驰模型,其特点是有严谨的定义且具有严格的推导过程,所运用的公式可解释性强[6]。
随着数据采集设备的更新与计算机技术的发展,研究者可以获取高精度、大样本、瞬时车辆运动数据,推动了数据驱动跟驰模型的快速发展。Kehtarnavaz 等学者[7]首先通过车辆速度、车间距、方向盘角度与车头角度等数据构建了前馈神经网络的跟驰模型,使得车辆能够进行自适应跟驰。 随后,国内有贾洪飞[8]、李德慧[9]和徐学明[10]等学者分别使用前馈神经网络、模糊神经网络与混合神经网络模拟单一车道的车辆跟驰行为。 近年来,随着美国“Next Generation Simulation”[11](NGSIM)的交通仿真工程数据的开源,越来越多的学者采用NGSIM 的数据开展研究。 Wei 等学者[12]基于NGSIM 车辆轨迹数据,使用支持向量机建立了车辆跟驰模型。 刘亚龙[13]采用随机森林算法在NGSIM 数据集上建立车辆跟驰模型,并与Gipps 模型进行了对比。 丁点点等学者[14]使用线性组合的方式将Gipps 模型和BP 神经网络模型耦合起来并在NGSIM 数据集上进行实验,结果表明耦合模型在预测速度时能够综合考虑真实性和安全性。
当前学者研究的数据驱动车辆跟驰模型涉及到神经网络、支持向量回归、随机森林、K 近邻等多种机器学习方法,也有学者将机器学习方法与模型驱动跟驰模型结合起来,但鲜有学者将多种机器学习方法组合起来构建车辆跟驰模型。 为此,本文基于NGSIM 车辆跟驰实际场景,以多种机器学习方法为基础,使用Stacking 的方式融合多种机器学习方法的优点,建立一个基于多学习器组合而成的车辆跟驰模型。
1 Stacking 模型融合原理
Stacking 是一种分层模型集成框架。 以两层为例,第一层由多个基学习器组成,其输入为原始训练集,第二层的元学习器则是以第一层基学习器的输出作为特征加入训练集进行再训练,从而得到完整的Stacking 模型。 本文所使用的Stacking 框架如图1 所示。

图1 Stacking 框架图Fig. 1 Stacking frame diagram
要得到Stacking 模型,关键在于如何构造第二层的特征(下记为元特征,meta feature)。 在构造元特征时,为了充分利用数据集并且使模型具有一定的泛化性能,Stacking 对于原始训练集常常采用类似于K 折交叉验证[15]的划分方法。
以5 折划分为例,首先将原始训练集分为5 份,分别记为f1、f2、f3、f4和f5。 划分完成后,第一次使用f1~f4的数据来训练基模型,对f5以及测试集的数据进行预测,f5的预测值f5′作为该基模型对f5生成的元特征,测试集的预测结果t5留作备用;第二次使用f1~f3与f5的数据来训练基模型,对f4及测试集的数据进行预测,f4的预测值f4′作为该基模型对f4生成的元特征,测试集的预测结果t4留作备用。将上述操作继续重复3 次,得到基模型对原始训练集生成的5 个元特征f1、f2、f3、f4、f5以及基模型对测试集预测得到的5 个预测结果t1、t2、t3、t4、t5, 将上述5 个元特征垂直组合起来得到该基模型的训练结果,同时对于测试集,将上述5 个预测值取平均值,作为测试集的输出进入到第二层模型中。 对于其他基模型,也采用相同的方法生成元特征,从而构成用于第二层模型训练的完整元特征集。 具体训练流程如图2 所示。
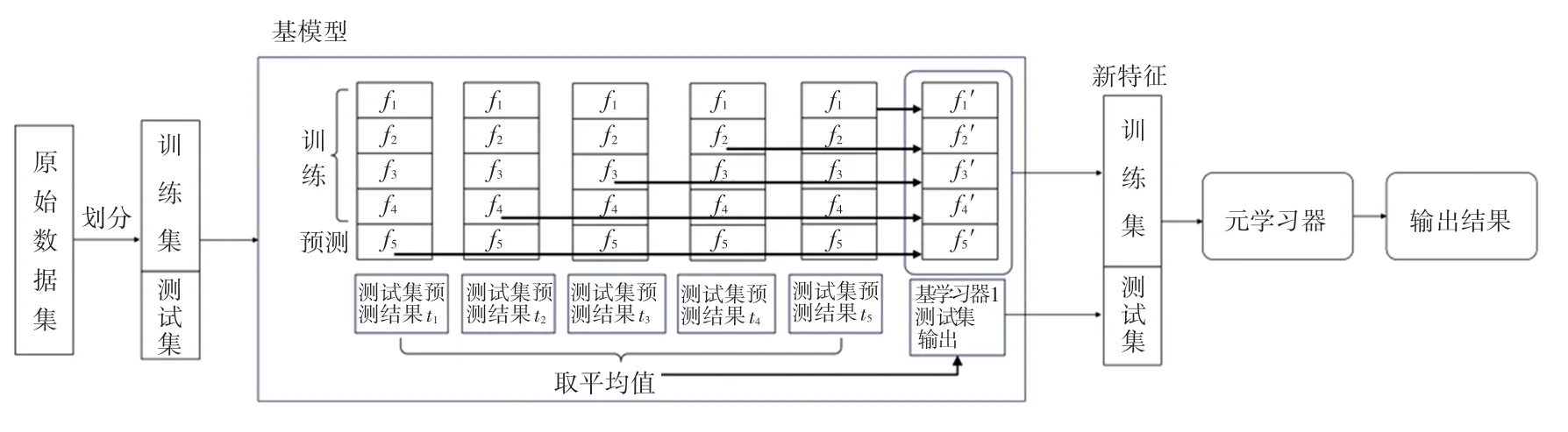
图2 Stacking 训练流程图Fig. 2 Stacking training flow chart
2 数据来源与预处理
2.1 数据来源
研究数据采用了NGSIM 中研究人员于2005 年4 月13 日下午4 点至4 点15 分在I-80 路段收集的车辆轨迹数据。 论文选取的研究路段如图3 所示。
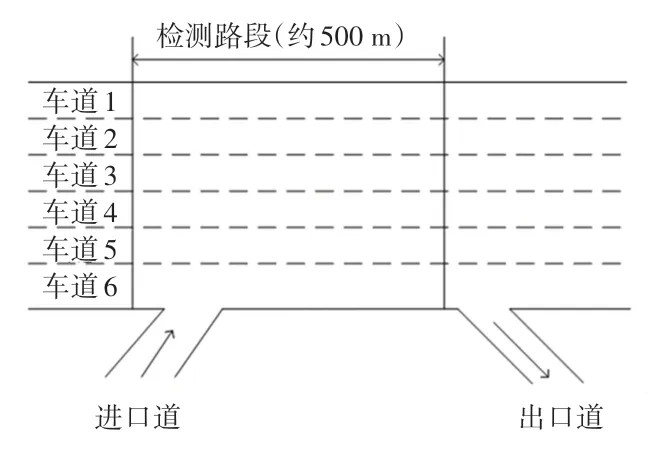
图3 I-80 路段示意图Fig. 3 Schematic diagram of section I-80
研究区域长度约为500 m,包括6 条高速公路车道,还有一个入口匝道位于研究区域内。 该车辆轨迹数据不仅提供了研究区域内每辆车辆的精确位置,也包括该车辆的车道位置和相对于其他车辆的位置,每条数据间隔时间为0.1 s。
2.2 数据预处理
为保证用于模型训练的车辆轨迹数据包含充足的、完整的有关车辆跟驰行为的信息,本文使用以下3 条基本规则对上述数据集进行筛选,以挑选出合适的车辆跟驰数据:
(1)为了减少车型不同所导致的跟驰特性的差异,仅筛选出小型车的车辆轨迹数据。
(2)数据处理时,将主车与前导车作为一个跟驰对。
(3)满足跟驰时间大于等于26 s、车头间距小于等于125 m 以及车头时距小于等于5 s 这3 个条件的跟驰对为本文研究所需的有效跟驰对。 经过筛选后的部分跟驰车辆数据见表1。

表1 跟驰车辆数据Tab. 1 Car following data
原始数据集根据上述3 条原则进行筛选后,共获得有效数据57 928 条,其中共有1 192 个有效跟驰对,训练集与测试集的比例为7:3。
3 车辆跟驰模型的建立
在建立基于Stacking 的车辆跟驰模型前,首先要确定影响跟驰行为的关键变量。 本文使用t时刻跟驰车辆的速度vn(t)、 加速度an(t)、 车头间距sn(t)、前导车的速度vn+1(t)、 加速度an+1(t) 五个指标作为模型输入特征,以下一时刻跟驰车辆速度vn(t +Δt) (Δt=1 s)作为模型输出。 同时,为了解决特征之间量纲不同、数据处于不同数量级的问题,在建模时将5 个特征进行归一化处理,归一化后所有的特征数据均在0 ~1 之间。 归一化处理中需用到的数学公式分别为:
其中,Xstd表示标准化结果;X表示需要归一化的数据;X.min(axis=0) 表示每列中的最小值组成的行向量;X.max(axis=0) 表示每列中的最大值组成的行向量。 式(2)中,max 表示要映射到的区间最大值,本文中取1,min 表示要映射到的区间最小值,本文中取0。
单条车道上的车辆跟驰情形如图4 所示,基于Stacking 的车辆跟驰模型示意如图5 所示。
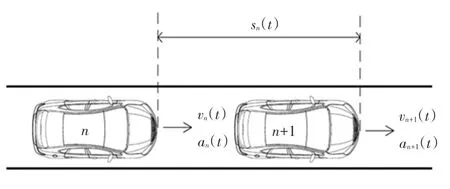
图4 车辆跟驰示意图Fig. 4 Vehicle following diagram
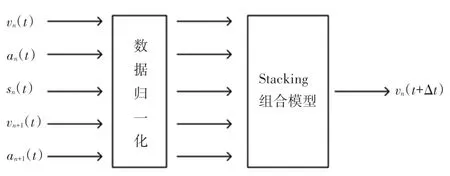
图5 基于Stacking 的车辆跟驰模型Fig. 5 Vehicle following model based on Stacking
4 基学习器和元学习器的选择
4.1 基学习器的选择
为构建基于多学习器融合的车辆跟驰模型,首先需要确定用于模型融合的基学习器。 本文主要考虑了8 种不同的学习器,包括以Boosting 方法为核心的自适应提升算法(Adaptive boosting ,AdaBoost)[16]、梯度提升决策树(Gradient Boosting Decision Tree,GBDT)[17]和 由 GBDT 改 进 而 来 的 LightGBM(LGBM)[18]、极端梯度提升决策树(Extreme Gradient Boosting,XGBoost)[19]算法;以Bagging 方法为核心的随机森林(Random Forest,RF)[20]算法;以统计学习VC 维理论和结构风险最小化原理为基础的支持向量机回归(SVR)[21]算法;以具有前向结构的人工神经网络为基础的多层感知机(MLP)算法以及通过搜索与当前观测值相似的历史数据进行匹配计算的K 近邻(K- Nearest Neighbor,KNN)算法。
研究使用Python 的sklearn、lightgbm 库对上述学习器进行了实现,并且使用sklearn 的网格搜索方法(GridSearchCV)确定上述8 种学习器的参数。 经网格搜索后,各模型在本文2.2 节数据集上的超参数设置以及预测精度见表2。

表2 8 种学习器的训练结果Tab. 2 Training results of eight basic learning devices
根据单个学习器的预测结果和选择基学习器时‘好而不同’的原则[22],本文首先排除了效果欠佳的AdaBoost 模型。 对剩余7 种学习器的预测数据使用MIC最大信息系数[23]进行相关性分析,如图6 所示。从图6 中可以看出,学习器之间的MIC相关性系数普遍较高,造成这种现象的主要原因是各个学习器自身的学习能力较强,预测精度较高。 其中,LGBM 和XGB 模型是以Boosting 为核心的算法且都从GBDT模型的基础上改进而来,因此在基学习器的选择时本文选取了这3 种模型中精度最高的LGBM 模型。

图6 基学习器之间的MIC 系数Fig. 6 MIC coefficient between base learners
此外,KNN、SVR 和LGBM 模型因为算法的实现机理有着很大的区别,从图6 中也可以看出KNN模型与SVR、LGBM 模型之间的相关性相较于其他模型之间的相关性偏低,因此本文最终确定KNN、SVR 和LGBM 三个模型作为模型融合的基学习器。
4.2 元学习器的选择
为了发挥不同模型的性能,本文首先考虑了在选择基学习器时未使用到的MLP、XGB、GBDT、RF、AdaBoost 这五种模型。 此外,为了探究不同元学习器对于模型精度的影响,还选取了LASSO[24]、线性回归这2 种多元线性回归模型。 以上备选元学习器均在以KNN、SVR 和LGBM 为基模型的基础上进行对比验证,对比结果见表3。
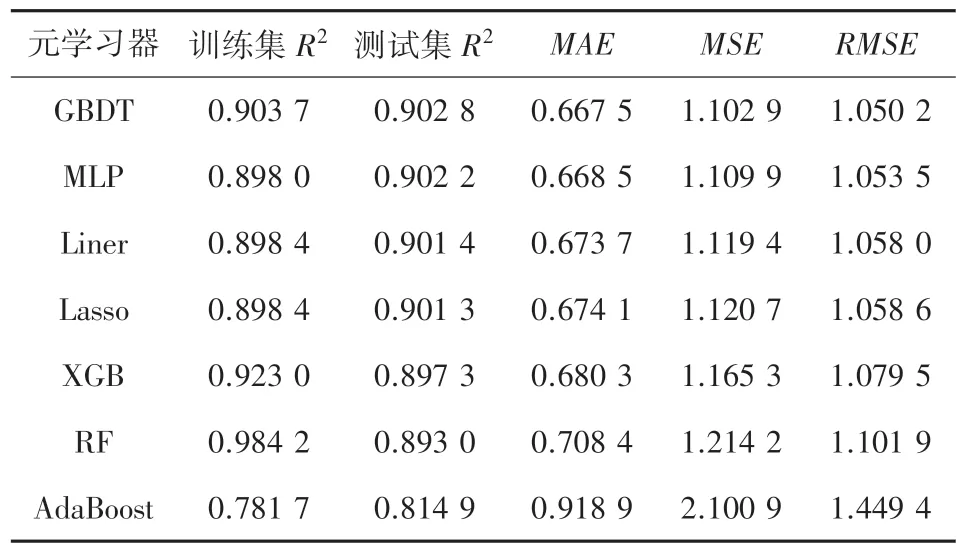
表3 不同元学习器的预测结果Tab. 3 Prediction results of different meta learners
由表3 可以看出,由GBDT 模型作为元学习器时拟合的精度最高。 如果以RF、XGB 作为元学习器,均产生了一定的过拟合现象,即相较于GBDT、MLP 和多元线性回归模型,上述2 种元学习器在训练集的拟合优度上升而测试集的拟合优度下降。 此外,AdaBoost 模型在作为元学习器时仍展现出了较差的结果。 为此,本文确定以GBDT 模型作为元学习器。
5 实验结果分析与讨论
5.1 实验结果分析
以4.1 节与4.2 节的研究为基础,将LGBM、SVR 和KNN 作为基学习器, GBDT 作为元学习器构建融合模型(下称本文模型),并在车辆跟驰数据上进行训练与仿真,得到本文模型的MAE、MSE、RMSE指标分别为0.667 5、1.102 9、1.050 2,在训练集、测试集上的R2分别为0.903 7 和0.902 8,计算耗时280.6 s。部分仿真结果如图7 所示,由仿真结果可以看出,本文模型能够较为准确地预判跟驰车辆的速度变化趋势。
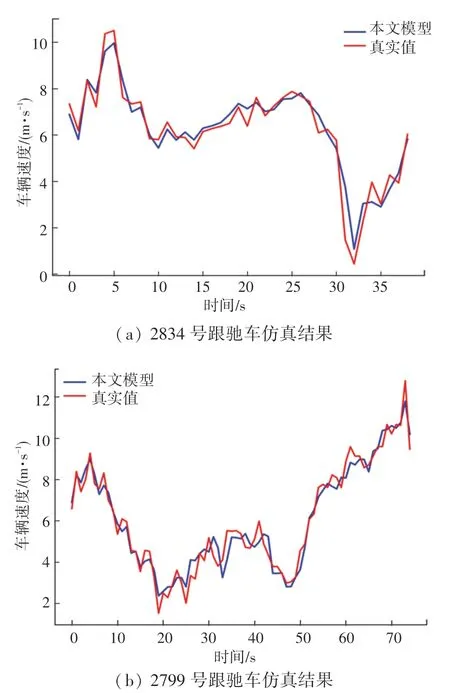
图7 本文模型仿真结果Fig. 7 The simulation results of the combined model selected in this paper
5.2 本文模型与IDM 模型的对比
为了证明本文所建跟驰模型的有效性,选择了IDM 模型与本文模型进行结果仿真对比。 IDM 模型的具体表达式为:
其中,αn表示车辆加速度;vn(t) 表示跟驰车t时刻的车速;Δ vn(t) 表示t时刻跟驰车与前导车的速度差;Δ sn(t) 表示t时刻的车头间距;表示期望车速;σ表示加速度指数(本文取值为4);a表示期望最大加速度;b表示舒适减速度;S*为期望车头间距;表示静止安全距离;T表示安全车头时距。
为了避免 IDM 模型中的期望跟车距离S*(vn(t),Δ vn(t)) 出现负值[25],并将模型的输出由加速度转化为下一时刻的车辆速度,将式(3)~(4)改写为:
本文取时间步长Δt为1 s,安全车头时距T为1.6 s[26]。 对于其他参数,本文使用遗传算法在2.2节数据集的基础上进行参数标定,最终得到=14.069 6,a=0.260 5,b=1.299 8,=4.773。 本文模型与IDM 模型的各项误差指标见表4。

表4 本文模型与IDM 模型对比评价Tab. 4 Evaluation between the proposed model and IDM model
由表4 可知,本文模型相较于IDM 模型预测效果更好,误差指标均有明显改善:MAE、MSE、RMSE三项指标分别降低了0.305 6、3.230 4 和1.031 5,意味着本文模型的预测结果更加接近真实数据,能够适用于车辆跟驰模型。
为了更加直观地将模型结果进行对比,选择了测试集中2886 号与1998 号跟驰车真实数据,绘制了仿真结果对比图,如图8 所示。
由图8(a)的结果可以看出,IDM 模型在第7 s和第26 s 均没有很好地判别出车速的突然上升,而本文模型对于此种极端值的预测效果更好。 这表明使用Stacking 的方式可以使模型挖掘出数据之间的潜在关系,弥补传统跟驰模型的不足,更好地对车辆的急加减速状况进行预判。 综合图8(a)和图8(b),本文模型的仿真结果相较于IDM 模型与真实数据更加贴合,具有更高的精度。

图8 本文模型与IDM 模型仿真结果对比Fig. 8 Comparison between the proposed model and the simulation results of IDM model
6 结束语
研究采用Stacking 模型融合的方法,选用KNN、LGBM 和SVR 模型作为基学习器,以GBDT 模型作为元学习器构建车辆跟驰模型,通过对比证明了本文模型的优越性。 本文总结了所选模型综合效果最优的3 个原因:
(1)KNN、LGBM 和SVR 三种基学习器在单一模型的情况下预测性能较强,可以提高模型的整体性能。
(2)使用Stacking 模型融合的方式可以进一步挖掘跟驰数据的潜在关系,弥补传统跟驰模型的不足。
(3)KNN、LGBM 和SVR 在预测机理方面存在很大不同,采用差异性大的算法作为基学习器能够充分发挥每个算法的优势,使得融合模型有更好、更稳健的预测性能。
本研究存在的不足有2 点。 一是在选择基学习器时采用了人工的方式,效率偏低;二是在对基学习器进行参数调优时选择了近似于穷举的网格搜索方法,增加了参数调优的工作量与时间。 在未来的研究中,希望能在对基学习器进行调参和选择时结合优化算法,提升研究效率。
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
管子学刊(2022年2期)2022-05-10 04:13:10
中北大学学报(自然科学版)(2022年2期)2022-05-05 09:04:08
管子学刊(2022年1期)2022-02-17 13:29:10
小太阳画报(2018年3期)2018-05-14 17:19:26
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
阅读与作文(小学低年级版)(2016年12期)2016-12-22 19:35:04
少年博览·小学低年级(2016年9期)2016-11-24 06:21:37
