
自动化特征工程综述
2023-04-19 06:39:00吴勇宣谢志伟石胜飞
智能计算机与应用 2023年3期
吴勇宣, 韩 珣, 谢志伟, 石胜飞
(1 哈尔滨工业大学 计算学部, 哈尔滨 150001; 2 四川警察学院 智能警务四川省重点实验室, 四川 泸州 646000;3 黑龙江农垦职业学院, 哈尔滨 150025)
0 引 言
伴随着多种多样的数据采集方式的发展与使用,海量数据的产生速度正在加快。 近年来,机器学习发展迅速,就需要基于机器学习的数据模型来分析和预测科研和工业领域中的大批量数据。 在预测模型中,特征工程是机器学习的一个极具挑战性的研究方向,对于提高模型准确性起着至关重要的作用[1]。 特征工程是将已给定的学习任务中的原始特征空间转换来提高模型的性能,在图像[2]、音频[3]和广告[4]等许多领域都得到了广泛应用。 但是,在特征工程中的应用实践中,面临着很多问题,具体阐释如下:
(1)时间花销大:在机器学习任务模型中,传统特征工程常常会占用超过一半的时间和计算资源。
(2)需要领域经验:在特定领域,需要人工把领域经验添加到特征空间中,工作量大且不可扩展。
(3)任务需求量大:机器学习模型的爆发性增量需求,使得特征工程任务量变大,再由人工参与所有特征工程任务迹近不可能。
因此,特征工程的自动化应运而生,自动化特征工程(Automated Feature Engineering)是自动化机器学习(Automated Machine Learning)[5]中的一个重要方向,其目的在于无需使用领域知识以及人工参与的情况下,就能自动生成高质量的特征来提高数据模型的性能。 自动化特征工程可实现机器学习任务流程的部分自动化,改善可操作性,且省去大量人工参与时间,从而提高效率。
在时间维度上,早期的自动化特征工程研究虽然未能创建一个实现多元化测量与评估的框架,但也在众多分支领域上取得了不小的进展[6-15]。 近年来,陆续涌现出许多自动化特征工程框架[16-23],能够为机器学习模型目标行为的捕捉预测和预测性能的提升提供了基础数据,也使得工业问题的决策流程变得更为顺畅高效[24-31],还为特征工程的一些问题给出了标准化的执行步骤[32-36],不仅降低了任务的计算资源消耗、而且省去了人工添加特征。 本文主要围绕自动化特征工程中3 种方案,分别是:基于扩张缩减(Expansion-reduction)的策略,以进化为中心(Evolution -centric) 的策略和性能引导搜索(Performance-based exploration)的策略。 对此拟展开研究论述如下。
1 基于扩张缩减的策略
特征生成的方法之一是把所有转换简单地应用于所有的数据,并对所有生成的特征空间进行求和,这将导致特征空间生成大量特征,虽然其中一部分特征可以对任务目标有效果提升作用,但是训练模型若要使用这种庞大的特征空间去进行训练却极为困难。 基于此,就可应用特征选择方法来筛选特征空间,该方法则称为扩张缩减法。 扩张缩减的设计结构如图1 所示。

图1 扩张缩减结构图Fig. 1 The expansion-reduction architecture
该方法的早期经典模型有FICUS[37],模型的扩张过程是通过定义运算函数(加法、减法、乘法和除法等)来形成潜在特征空间,缩减过程将使用信息增益引导波束搜索。 早期的扩张缩减模型只能生成相对简单的新特征,并不能生成高阶特征组合,这也限制了后续机器学习模型任务的性能。
大多数的扩张缩减模型采用预定义的运算函数生 成 特 征。 Kanter 等 人[38]提 出 Deep Feature Synthesis(DFS),DFS 的扩张过程是使用一组预定义的运算函数,用于连接表和构建新特征,缩减过程是使用截断奇异值分解(Truncated SVD)进行特征选择。 该模型的不足即在于预定义的函数会用到所有的原始特征空间,因此模型计算时间相对较长。 此后,DAFEE[39]对DFS 方法进行了改进。 在扩张过程中,对实体之间的关系做连接合并等操作,如此一来则改善了DFS 不能生成部分复杂特征的弊端。
在扩张缩减方法中,虽然大多数方法试图通过构造运算函数和算子来生成优质特征,但近年来已有研究工作实现了通过分析特征间关系来生成特征。
AutoLearn[40]的扩张过程是通过回归分析特征对来生成相关特征,缩减过程是通过稳定性搜索(Stability Based Selection)和信息增益算法筛选特征空间,该模型的局限性是回归拟合未能考虑类别信息、即没能挖掘不同类别中2 个特征间的不同关系。LBR[41]则对AutoLearn 进行了改进。 LBR 的扩张过程是在回归拟合特征对前,基于标签对特征进行了分类、且一并考虑到特征对的类别信息,在缩减过程中, 使 用 最 大 信 息 系 数( Maximal Information Coefficient)进行特征筛选,却仍不能避免回归拟合过程计算资源开销过大的缺陷。
扩张缩减法的特征生成方式总体上是构建运算函数或者回归分析特征。 这些方式实现起来相对容易,代价是很难学习到不同的转换方式去生成特征,同时因为特征数量的超线性复杂度,几乎不可能去递归扩张缩减模型。 所以扩张缩减模型的性能优劣也严重依赖于特征选择模块。 因此扩张缩减模型在可伸缩性的层次上较为极端。
2 以进化为中心的策略
和扩张缩减方法相比,一次生成一个新特征,而后进行训练和评估,由此确定新特征是否值得保留,这种方法叫做以进化为中心法。 以进化为中心的设计结构如图2 所示。 该方法虽比扩张缩减方法更具有拓展性,但是在效率上却更慢,因为方法中涉及到模型的训练和评估,以及可以生成的整个特征空间。而且由于生成特征的实践成本并不低,使得该方法只有在未添加深度变换的情况才具有可行性。
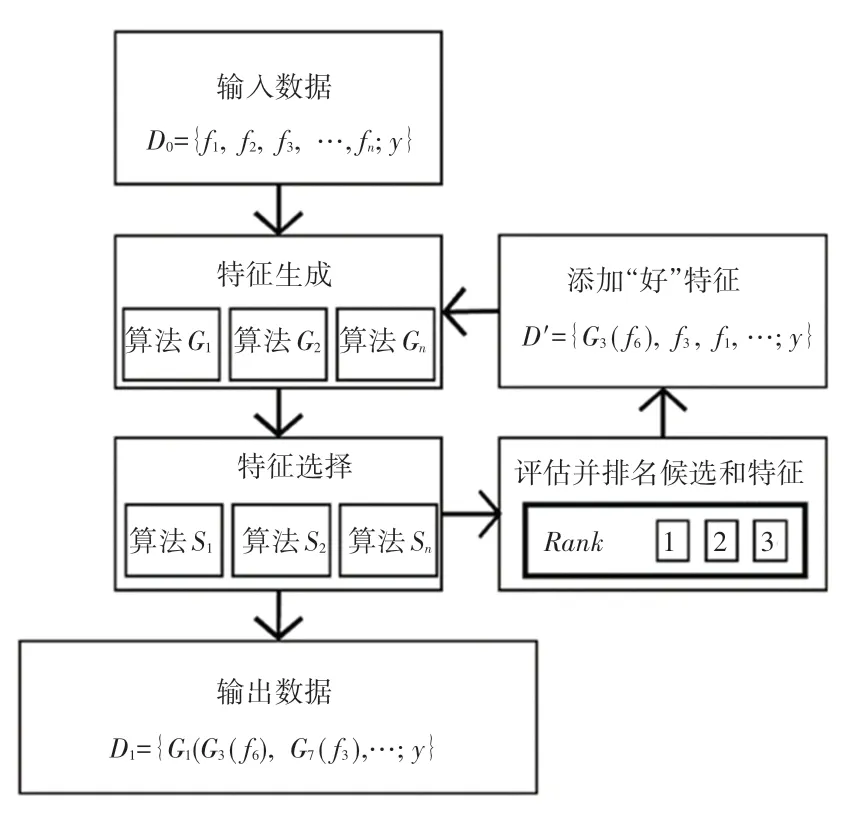
图2 以进化为中心结构图Fig. 2 The evolution-centric architecture
该方法的早期模型有FEADIS[42]。 通过使用预定义的运算函数生成潜在的特征空间,再使用贪婪算法从潜在的特征空间中随机地选择特征来做进化,此后反复迭代,直到模型的性能不再提升为止。该方法的不足是多轮迭代需要耗费大量的时间和计算资源。
以进化为中心模型同样有以预定义的运算函数和算子生成特征的方法。 ExploreKit[43]模型提出一项使用可扩展的多阶算子生成特征和多维度信息排序以及迭代评估的框架,模型的特征生成部分是使用当前特征空间的多阶算子组合来生成大量候选特征,进化过程是利用多维度指标对特征排序逐一进行评估。 该模型的重要性就在于该框架能学习到基于分类目标的、从特征分布到特征工程方式的蕴含经验的多分类器。
同时,神经网络也可以用来生成和进化特征空间。 LFE[44]提出基于多层感知机分类器的自动化特征工程模型。 LFE 可以从过去的经验中学习转换方法的有效性,考查所有特征组合的随机样本为,每个组合找到范例,并进化出最有用的特征。 该方法的不足之处主要表现在只能适用于分类数据集中。
以进化为中心的方法中,也有实现分析特征间关系 的 研 究 成 果。 SAFE[45]的 特 征 生 成 采 用XGBoost 去挖掘特征之间的关系,利用信息增益比过滤特征组合,并使用预定义的算子生成特征,进化部分采用皮尔森系数和平均增益来筛选特征,选择良好特征去做迭代进化。 该方法的分布式计算优化可以缓解以进化为中心的迭代时间消耗。
以进化为中心的生成特征方式与扩张缩减策略大致相似,而有关特征选择的方式却并不相同。 迭代处理虽然可以让模型表现得更加优秀,但相伴而生所带来的时空复杂度和过拟合问题也不容忽视。因此以进化为中心在复杂度的问题上较为极端。
3 性能引导搜索的策略
到目前为止,已经讨论了自动化特征工程的2种方法,这2 种方法在生成新特征的数量和所需时间形成较大的对比,且由于2 种方法各自的局限性,都会面临一定的性能瓶颈。 此外,上述2 种方法往往很难生成复杂的特征变换,这往往直接关系着新特征的质量。 近年来,针对这些问题,又研发提出了性能引导搜索的策略。
性能引导搜索的基础框架[46]是使用有向无环图(DAG)的层次结构,也可以称作变换图。 该框架的作用是对给定的数据集通过变换图系统地枚举自动化特征工程的方法,转换图的节点表示通过对数据集应用变换函数来获得不同形式的数据集,数据集转换的过程就是把所有的转换函数应用于全部可能特征,同时生成多个附加特征,基于此再对可选特征进行选择和训练评估。
因此,性能引导搜索框架通过每个转换函数批量创建新特征,这在一定程度上可以视作就是扩张缩减和以进化为中心这2 种方法的中间体,避免了因极端策略导致的后果。 性能引导搜索的核心思想在于:完整的转换图本身将包含欲求解问题的全局解,但遍历全图的做法并不可取,因此框架将会选择搜索精度的最高点。 RAAF[47]在探索方法上进行了优化,使用了模拟退火法启发式的探索,从而优化了性能引导搜索可能导致的过拟合结果。
性能引导搜索框架的重点不仅在于构建转换图,还在于图的搜索策略。 强化学习搜索策略可以依靠经验学习和强化学习优化探索策略[48]。 把自动化特征工程任务转化为异构转换图(HTG)的优化问题,并在HTG 上使用了Q 学习来支持特征工程细粒度的高效探索,该方法还能将已有数据集的知识应用到新的数据集上。 这种探索方式,会持续监控在给定的转换图上应用每个转换操作所产生的性能改进的奖励,学习一种策略来优化这种奖励,而策略也相当于行动效用函数。 在优化奖励的过程中,通过探查到行动的及时回报来学习这种行动效用函数。 CAFEM[49]在特征转换图的基础上,使用了双深度Q 学习(DDQN)的方法来做进一步探索,通过深度神经网络估计状态动作值以及贪婪的方法获取接下来的动作。
性能引导搜索的重点则在于探索策略的训练。因为完整的变换图是包含问题的全局解,但同时也是无界的。 探索策略直接决定最终模型的复杂度和特征质量。 目前的强化学习探索方式主要是Q 学习。 Q 学习在缺乏明确探索行为的情况下可以不断学习其他算法。 这种方式也称为学会学习(learning to learn)或者元学习(meta-learning)[50]。
4 自动化特征工程研究评析
自动化特征工程在计算和决策方面都具有较强的挑战性,不仅因为可以构造的预选特征数量是无限的,而且也因为要对每个新特征进行训练和验证,这是代价非常昂贵的步骤,也是目前很多模型亟待解决的焦点问题。 由于代价昂贵,则只能设置一定的阈值就停止训练,而无法达到模型的性能上限。 即使在中等规模的数据集上,常规的以进化为中心的自动化特征工程模型都要几天的时间才能完成。 更大的问题是,从一个评估试验到另一个评估试验的结果基本没有可重用性。 以扩张缩减的方法虽然可以避免多轮迭代,但是这种减少执行次数来训练验证尝试的方式本身就会存在可扩展性的问题和速度瓶颈。
近两年的自动化特征工程的研究聚焦于性能引导搜索的策略,尽管此策略已经展现出在可扩展性和特征质量方面的长足优势,但却依然难以避免源于性能驱动所导致的过拟合、以及随即带来的泛化问题。 由于现如今的数据量在不断增加,对时间和空间的复杂性的要求很高,同时业务的快速变化也对模型的灵活性和扩展性提出了更高的要求,因此,自动化特征工程还面临着如下挑战:
(1)适用性:自动化特征工程的工具需要让非专家更方便地使用,因此,最终的模型应该是具备优良的用户友好性。 此外,自动化特征工程的算法性能不应依赖大量的超参数优化,而应使算法能够适配更多的数据集。
(2)高性能:考虑到自动化特征工程模型在特征生成和特征选择的过程中,时空复杂度很高,特征维数也较多,因此实现算法分布式计算来提高模型性能是必要、且重要的,这就使得在模型的特征生成和特征选择部分要做到并行计算。
(3)解释性:自动化特征工程模型在实际的应用中,高效益的新特征需要有可解释性[51],而不是直接使用深度学习隐式的构建特征,从而容易导致过拟合。
5 结束语
本文针对自动化特征工程进行探讨研究。 首先介绍了自动化特征工程的背景,接着根据自动化特征工程的不同发展方向进行了综合论述,最后针对自动化特征工程发展做了研究简析。 对于了解自动化特征工程的发展脉络有着一定借鉴和参考价值。
猜你喜欢
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
家庭影院技术(2019年8期)2019-08-27 02:44:56
当代陕西(2019年10期)2019-06-03 10:12:04
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
电子制作(2017年23期)2017-02-02 07:17:06
西北工业大学学报(2015年4期)2016-01-19 03:31:47
燕山大学学报(2015年4期)2015-12-25 02:19:45
中国塑料(2015年4期)2015-10-14 01:09:28
火炸药学报(2014年1期)2014-03-20 13:17:29
振动工程学报(2014年4期)2014-03-01 01:15:41
