
基于金融领域的因果事件抽取算法研究
2023-04-13 11:40:06席建文
现代计算机 2023年3期
席建文
(西南民族大学电子信息学院,成都 610041)
0 引言
因果事件抽取技术是信息抽取领域重要的研究方向。而金融领域中含有大量的因果事件,这些因果事件直接地反映了一个经济事件对另一个经济事件的影响程度,这对于领域决策和分析具有一定的指导作用,为知识问答、数据预测、因果推断等应用提供数据来源。但由于中文语言的复杂性、描述方式的多变性,真实文本中因果情况复杂难解,有大量的多因多果的情况,增加了抽取因果事件的难度。
为了解决金融领域因果抽取的难题,我们构建了金融领域中的因果数据集,对因果事件中的组成结构进行定义,方便从因果句中抽取因果事件。同时研究了如何更准确地抽取因果关系,并提出了基于BERT 改进pipeline 结构的因果事件抽取模型PUBERT。
1 相关工作
本文相关的工作主要分为因果事件数据集的构建和因果事件关系抽取研究。
针对因果事件标注的数据集目前主要有两种标注方式,一是以词级别的标注,将事件标注为词语的形式,包括SemEval-2007 task 04[1]、SemEval-2010 task 8[2]、CaTeRS[3]和中文因果标注数据集CEC[4]等,另一种是以长句或长文段的标注方式,如Fincausal[5],将因果事件标注为一个完整的句子或者段落。
事件因果关系抽取上的研究最早可追溯到20 世纪90 年代,早期研究围绕基于规则的方法展开。Grishman 等[6]提出了PROTEUS 工具,使用语法和语义信息自动抽取文本中的时序关系和因果关系。Kaplan等[7]将文本表示为命题的集合,每个命题包含一个谓词(通常为动词)和多个论元,通过定义命题模板的方式抽取命题中的因果关系。Garcia[8]提出了COATIS 工具,该工具使用包含23 个因果性动词的语言学模板自动地从法语文本中抽取因果关系。
2000 年后,因果关系抽取研究逐渐转移到基于统计与机器学习的方法上来。Girju[9]提出了使用C4.5 决策树判断“NP1-Verb-NP2”元组是否构成因果关系。Chang等[10]采用无监督的方法从文本中学习短语指示因果关系的概率与词对出现在因果关系中的概率,作为额外特征训练贝叶斯分类器,判断因果关系是否成立。2007 年,SemEval-2007 task 04[1]中提出了常见语义关系分类任务,其中包含因果关系。Girju等[11]使用SVM 在该任务上取得了当时最佳的效果。Sil 等[12]提出了PREPOST 系统,使用基于RBF 核的SVM 结合PMI 特征判断因果关系是否成立。付剑锋等[13]提出使用层叠条件随机场的方法,在事件序列上同时标注多个因果关系对。Silva 等[14]将CNN 应用于因果关系抽取任务中。这一系列的研究将因果关系抽取建模为分类任务,输入是已经抽取好的事件或实体及其上下文,判断它们是否构成因果关系,而并未关注原因、结果事件或实体本身的抽取工作。
随着自然语言处理技术的发展,一些研究者开始尝试使用序列标注模型解决因果关系抽取问题。Dasgupta 等[15]提出将因果关系抽取建模为序列标注任务,在文本中直接标注出原因提及与结果提及的短语。Li 等[16]提出使用带有自注意力机制的双向LSTM-CRF 模型,结合经过领域迁移的词向量应用于因果抽取任务。基于序列标注模型的因果抽取方法是一种端到端的方法,可直接由文本得到因果事件和实体对,为因果关系抽取研究指明了新的方向。
本工作分为四个部分,第一部分介绍金融领域因果数据集的建设和数据统计情况;第二部分介绍实验方案,由事件抽取和因果关系抽取构建的整体pipeline 结构;第三部分进行对比实验设计,并对结果进行分析;第四部分为总结。
2 数据集构建
本节目的是构建金融领域的因果事件数据集,包括数据来源的选择、数据处理过程、标注规范的定义,以及对数据集的样本情况进行统计分析。
2.1 数据来源
为使得数据集尽量贴合真实情况,我们从多个信息来源中获取数据,包括腾讯新闻、搜狗新闻的金融新闻和CCKS(China Conference on Knowledge Graph and Semantic Computing)金融因果事件比赛数据。
本工作针对上述来源的文本进行分句,收集因果触发词方式,构造AC 自动机进行快速匹配,得到一批候选因果事件句子的数据。
例如:
“报告要点产品价格变动分析:油价下跌,甘氨酸、醋酸续涨原油价格下跌,主要因为OPE增产叠加美油产量持续增加”
“国际贸易保护愈演愈烈,贸易摩擦升级,多国减少进口贸易量,导致特钢出口难度进一步加大”
“近期棉花价格上涨,推动二道绒价格上涨,并进一步传导至棉浆粕”
2.2 标注定义与规范
我们使用标注工具label-studio,在经过规则筛选的候选数据集合中进行因果标注。任务定义为:在给定句子中,标注出事件片段、触发词,并标注出两两成对的事件片段之间是否存在因果关系。关于标注做出以下定义:
事件片段定义为:描述了事物发展、状态、动作的片段,形式可为词语、短句、短语等,如“洪灾”“各国经济增长”“供需失衡”等。
因果关系定义为:在逻辑、语法结构的表达上体现并能推理出来事件A 使得事件B 发生的情况,如“洪灾对CPI 的影响主要在食品项,会导致粮食、蔬菜等价格阶段性上涨”,其中事件“洪灾” 与事件“粮食、蔬菜等价格阶段性上涨”有因果关系。
触发词定义为:在语句描述中为指示或说明了两事件之间具有因果关系的词或短语,如“导致”“因为”“影响”“将会”“由于”“随着”等。
因果数据构建难以快速发展的原因在于真实情况中文本的复杂性,而标注中往往需要一定程度的语言逻辑判断,同时难免会带有个人的主观性,所以我们需要对标注因果事件的标注边界有一个统一的规范。给出以下三条标注规范:
(1)触发词必存原则:一条有效的因果事件数据样本中应该至少包含一个触发词;
(2)语义完备性原则:为了使得事件具有完备的语义,片段必须体现实际的动词、名词,指示代词忽略掉;
(3)语言简明性原则:对于事件,在不影响理解语义的情况下,选择最短的片段作为边界。
2.3 数据集统计分析
为了避免数据集的构建出现漏标错标的情况,我们采用两人交叉标注,最后通过人工校验并整理,获得金融领域共计4000 条带有因果关系的数据集,对数据集做以下分析:
2.3.1 触发词统计
我们统计了所有触发词的频次,列出具有代表性的频次top10的触发词如下:
导致(1681)、影响(765)、由于(605)、预计(567)、使(394)、随着(230)、有望(255)、推动(244)、因为(118)、如果(66)。
2.3.2 因果事件长度统计
对数据集文本从样本数量、文本平均长度、事件平均长度、触发词平均长度进行了统计,结果如表1所示。

表1 因果事件长度分布 单位:字
2.3.3 多因果事件分布统计
我们对单因果和多因果数据分布情况进行统计说明,内容如表2所示。

表2 因果事件分布 单位:条
其中单因果表示一条数据中只含有一对因果事件,如“市场乙二醇供应量的增加导致中国乙二醇进口量出现下降”。
多对因果表示一条数据中包含有多对独立(非连锁)因果事件,如“美国等西方国家指责伊朗进行核活动是为了发展核武器,但伊朗坚称其核活动仅用于和平目的”。
多因多果表示一条数据中含有一因多果或多因一果事件,如:“美国页岩气供给的增加和美国、中国原油进口量回落导致原油大幅下跌”(多因一果);“厄尔尼诺可能导致巴西、印度的蔗糖减产,东南亚的橡胶及棕榈油减产,阿根廷大豆增产、印度、澳大利亚的小麦减产”(一因多果)。
连锁因果表示一条数据中含有关系为:事件既为关系对中的果事件,同时也为另一个因果关系对中的因事件,如“随着冬季国内气温下降,建筑工地开工受到明显影响,对建材需求进一步萎缩,钢材冬储行情迟迟未能启动,国内钢材货价格出现下降,越来越多的钢企提出下调焦炭价格要求”。
3 模型
本工作针对因果事件关系的抽取主要采用pipeline 的结构,固而分为两部分进行构建:事件抽取和关系抽取。
3.1 pipeline结构
模型流程如图1 所示:文本数据输入-> 事件抽取模块-> 关系抽取模块->输出抽取结果。针对给定的句子,先进行事件抽取,得到事件实体,然后将得到的事件实体信息输入到关系抽取模型中,最终得到正确的因果关系对。
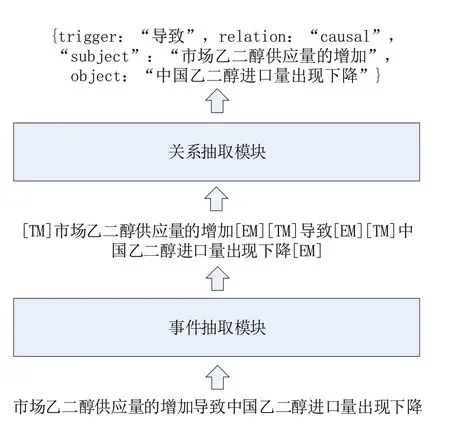
图1 整体抽取模型结构
3.2 事件抽取模块
本研究的事件抽取模块采取命名实体识别BIO 的方式,使用BERT+CRF 结构有效地抽取事件和触发词。如图2所示。

图2 事件抽取模块
3.3 关系抽取模块
为了更好地抽取出因果关系,同时充分利用事件抽取结果的语义信息,通过在输入层融合实体信息(包括类型信息和边界信息)来实现关系的预测。
首先在输入层实体前后插入自定义字符“TM”“EM”,当文本经过BERT 模型后,我们得到每个字的上下文表示作为中间层的向量。然后,将事件A 的前后两个字符“TM”“EM”向量相加求平均获得新向量“E_A”,在事件B和触发词C 上进行相同的操作得到新向量“E_B”和“E_C”,再将三个向量拼接,输入到最后的liner层+softmax层后,即可得到最终的关系分类。
在训练过程中,我们会对除了正确组合以外的所有实体构成负样本进行训练,来提高模型对正确关系组识别的准确度。
如下图3所示。

图3 关系抽取模块结构
充分利用触发词的作用,将两个事件中心位置最近的触发词作为一对,但触发词表示向量与事件表示向量之间的位置拼接受到实际位置的影响,我们认为这里包含的语义信息将为进一步的关系识别提供更好的抽取效果。
4 实验与分析
4.1 实验环境
操作系统为Ubuntu16.04,使用Python 编程语言和Pytorch 深度学习框架,其中GPU 型号为GeForce GTX 2080Ti。
4.2 评估指标
对模型进行评估时,采用以下指标:
其中:TP为预测中正确的关系个数;TP+FP为预测的关系个数;TP+FN为数据中真实的关系个数。评估pipeline 的结果时,需要对整体结构进行评估,故而除了预测的关系类型要求正确,预测的实体类型也必须正确,才认为预测的关系为正确。P、R、F1 公式不变,但按照更严格的标准进行计算。
4.3 实验效果分析
表3所示为实验结果。通过将PUBERT 和另外两种模型进行对比,可以看到PUBERT 有更好的表现,在金融领域复杂因果事件环境中,基于就近规则的BERT+Rule 模型难以处理多因多果的情况,而引入触发词语义信息的PUBERT模型能够更好地理解因果事件之间的关系,在抽取上有明显提升。

表3 实验效果对比
5 结语
PUBERT 以pipeline 结构搭建了独特的关系抽取模型,不仅充分利用了事件抽取所得到的信息,而且能够很好地识别事件之间的因果关系,相比较于BERT+MTB 和BERT+Rule 方法,其在金融因果数据集上有更好的表现。当然,受限于pipeline 结构本身,其结果比较依赖于事件抽取的效果,容易造成误差积累,这些不足是我们下一步研究需要解决的问题。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
南大法学(2021年6期)2021-04-19 12:28:02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
制造技术与机床(2019年10期)2019-10-26 02:48:08
电子制作(2018年18期)2018-11-14 01:48:06
高中生·天天向上(2018年7期)2018-07-23 10:06:52
湘江法律评论(2016年0期)2016-06-15 20:29:32
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
小学教学参考(2015年20期)2016-01-15 08:44:38
新高考·高二数学(2015年11期)2015-12-23 18:17:44
