
语音识别中的Conformer模型压缩研究
2023-04-13 23:20:37卢江坤许鸿奎张子枫周俊杰李振业郭文涛
计算机时代 2023年4期
关键词:深度学习
卢江坤 许鸿奎 张子枫 周俊杰 李振业 郭文涛

摘 要: 针对使用Conformer模型的语音识别算法在实际应用时设备算力不足及资源缺乏的问题,提出一种基于Conformer模型间隔剪枝和参数量化相结合的模型压缩方法。实验显示,使用该方法压缩后,模型的实时率(real time factor, RTF)达到0.107614,较基线模型的推理速度提升了16.2%,而识别准确率只下降了1.79%,并且模型大小也由原来的207.91MB下降到72.69MB。该方法在模型准确率损失很小的情况下,较大程度地提升了模型的适用性。
关键词: 深度学习; 模型压缩; 模型量化; 模型剪枝; Conformer
中图分类号:TP319 文獻标识码:A 文章编号:1006-8228(2023)04-16-07
Abstract: Aiming at the problem of insufficient computing power and resources in the actual application of speech recognition algorithm using the Conform model, a model compression method based on the combination of interval pruning and parameter quantization of Conformer model is proposed. Experimental results show that the real time factor (RTF) of the compressed model is 0.107614, which is 16.2% higher than the reasoning speed of the baseline model, while the recognition accuracy is only 1.79% lower, and the size of the model is reduced from 207.91MB to 72.69MB. This method greatly improves the applicability of the model with little loss of accuracy.
Key words: deep learning; model compression; model quantization; model pruning; Conformer
0 引言
端到端(end-to-end,E2E)语音识别系统将整个识别网络简化成一个单一的网络结构, 在训练时只需要注意整个系统的输入和输出,大大减少了对语音识别系统构建的难度[1-3]。随着Transformer模型在计算机视觉、自然语言处理等领域展现出来出色的性能[4],Dong等人首次将具有自注意力机制的深度神经网络Transformer模型引入到语音识别领域[5]。文献[6]提出一种模型结构Conformer,将卷积模块加入到Transformer模型的编码器部分,从而达到增强识别效果的目的。
不断加深的神经网络迅速增加了数据量,这将花费更大的存储资源和计算开销。仅8层的AlexNet[7]就需要至少7.29亿次浮点型计算,需要占用约233MB内存。庞大的网络参数极大地限制了模型在算力有限的设备上部署[8]。因此需要对这些大型神经网络模型进行压缩,降低模型大小和计算成本[9]。
早期Babak Hassibi等人使用来自误差函数的所有二阶导数来判断哪些不重要的参数来进行剪枝,进而提升模型的泛化能力和推理速度[10]。Hao Li 等人在卷积神经网络中剪去对输出精度又很小影响的通道大大降低了计算量并且对原始精度影响较小[11]。这些剪枝操作在使精度下降一定范围内,推理速度提升不明显并且参数存储空间较大,而使用模型量化技术则能显著减少参数存储空间并加快运算速度。Gong等人提出将k-means聚类用于量化全连接层参数,将原始权重聚类成码本,为均值分配码本中的索引,只需存储码本和索引而不许存储原始权重信息[12]。Wu等人将k-means聚类拓展到卷积层,将权值矩阵划分成很多块,再通过聚类获得码本[13]。Choi等人分析了量化误差和loss的关系,提出了基于海森加权k-means聚类的量化方法[14]。
本文提出一种基于Conformer的模型压缩算法,使用模型剪枝算法对编码器的卷积层部分进行通道剪枝。以L1范数作为判断标准对等间隔编码器进行剪枝,避免了对模型的过度破坏,又保证了剪枝质量,再结合模型量化算法对模型进行量化,最终达到提升模型推理速度和减小模型的大小的目的。经实验表明,在模型识别准确度下降很少的情况下大大提升了模型的推理速度并且模型的大小也减少了65.05%。
1 模型结构
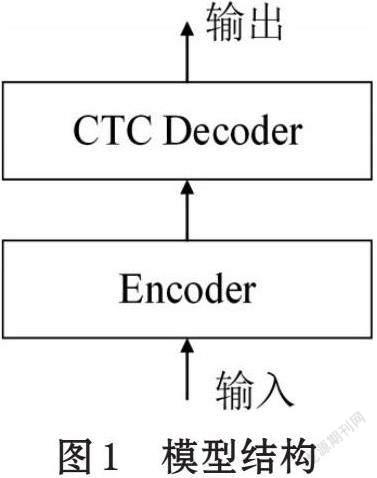
语音识别模型使用编码器-解码器(Encoder-Decoder)结构,如图1所示,编码器部分将语音输入序列映射到特征序列,生成指定长度的向量。解码器部分对输入向量进行解码,根据语义向量生成指定的序列。
本文编码器使用Conformer结构编码[6],解码器使用CTC(connectionist temporal classification)进行解码[15]。
1.1 Conformer结构
本文所使用的Conformer结构是在Transformer结构的基础上增加卷积模块,以加强模型对局部和全局依赖性建模的效果,增强语音识别模型的性能[6]。如图2所示,Conformer结构由归一化层、前馈层、卷积层和多头注意力层组成。
多头注意力层中使用注意力机制在输入的大量信息中选择关键信息加以处理。如公式⑴,使用信息提取的方法将维度为[dm]的输入映射到一组查询[Q]、键[K]和值[V]的矢量输出,其中查询[Q]和键[K]的维度是[dK],值[V]的维度是[dV]。然后再利用[softmax]函数来获得值的权重,最后返回值的加权总和[Z]。
卷积层由Layer Norm、Batch Norm、Pointwise卷积、Depthwise卷积、GLU激活层和ReLU激活层组成。Pointwise 卷积运算负责将深度卷积的输出按通道投影到新的特征图上;Depthwise卷积不同于原始卷积,一个卷积核负责一个通道,独立地在每个通道上进行空间卷积。
前馈层使用ReLU激活函数来进行线性变换,并且通过使用Dropout来减少过拟合发生进而帮助训练更深层次的网络。前馈层作用是更新注意力层输出向量的每个状态信息,如公式⑵,其中[W]表示权重,[b]表示偏差,[x]表示输入。
1.2 解码器结构
解码器使用CTC Decoder,对Encoder部分的输出进行前向计算,再由[softmax]计算得到结果。
解码算法为CTC Prefix Beam Search算法,该算法对输入一帧的数据给出当下各种字符的概率,然后利用这一层的概率展开搜索,选取搜索空间中最优的k条路经的前缀,并把这些前缀挨个输入到模型中,同时把相同的前缀路径合并,不断重复最终得到最优解。
基于CTC Loss训练的模型不用进行强制对齐,可以通过学习,直接将语音映射成对应的字符,并且引入空白标签Blank实现自动对齐,解决了输入音频数据和输出文本数据长度不一致的问题。
2 模型剪枝
卷积层和全连接层的输入和输出之间都存在密集连接,而删除冗余的连接可以达到提升模型推理速度的目的。模型剪枝是指在训练好的模型上设计对模型参数的评价准则,通过该准则删除不重要的参数来减小模型RTF达到提升模型推理速度的目的。模型剪枝可以分为非结构化剪枝和结构化剪枝[9,16]。
2.1 非结构化剪枝
非结构化剪枝可以将网络任何位置的参数剪掉,本质是对单个神经元的权重进行剪枝来减少神经元之间的连接。如图3所示,这样剪枝操作可以对模型的权重参数稀疏化。
虽然非结构化剪枝使模型可以在非常精密的模式下进行剪枝且可以实现很高的裁剪率,但这种剪枝方式对模型推理速度提升并不会产生明显的效果。
2.2 结构化剪枝
结构化剪枝不同于非结构化剪枝,它更专注于相对完整的网络结构进行修剪,可以修剪整个神经元,如图4所示,这样修剪之后会使模型的通道数减小,从而提升模型整体的推理速度,但不可避免的会造成精度损失。
3 模型量化
模型量化是指将高精度浮点表示的网络参数包括权重、激活值、梯度和误差等用低精度来近似表示。通常使用8位整型作为统一的位宽,也可以根据经验或一定策略自由组合不同的位宽,可以有效地减少参数存储空间与内存占用空间,加快模型运算速度降低设备能耗。但同时也会导致部分信息的损失,造成模型识别精度的下降。模型参数量化可分为对称量化和非对称量化[9] 。
3.1 对称量化
对称量化的算法是通过一个收缩因子将32位浮点型数据中的最大绝对值映射到8位整型数据的最大值,将32位浮点型数据中最大绝对值的负值映射到8位整型数据的最小值,将零点限制为0,收缩因子[Δ]如式⑶所示,[xmax]和[xmin]分别表示模型中32位浮点型参数的最大值和最小值,[absxmax]表示取参数中最大值的绝对值,[absxmin]表示取参数中最小值的绝对值。
其中,在函数[clampa,b,x]中,[a]表示最小值,[b]表示最大值,而当首选值[x]比最小值要小时,则使用最小值;当首选值[x]介于最小值和最大值之间时,用首选值;当首选值[x]比最大值要大时,则使用最大值。
如图5所示为参数量化对应参数值的范围,a表示参数浮点型的最大绝对值。对于32位浮点型参数如果均匀分布在0点左右,那么映射后的值也会均匀分布,若分布不均匀,则映射后不能充分利用。
3.2 非对称量化
非对称量化可以很好的处理32位浮点型数据分布不均匀的情况,通过收缩因子和零点,将32位浮点型数据中的最小值和最大值分别映射到8位整型数据中的最小值和最大值。加入零点之后会将32位浮点型数据中的0量化映射到[0,255]中的某個数,不会出现浮点0量化后直接映射到0的情况,可以无误差的量化32位浮点型数据中的0,从而减少补零操作在量化中产生额外的误差。式⑽为收缩因子,式⑾中的z表示零点位置的取值。
其中,[xQ]表示最终量化所得到的值。如图6所示,为非对称参数量化参数映射的取值范围,将浮点型的参数[xmin,xmax]映射到整型的[0,255]数值区域,此时的零点映射到8位整型数值区域[0,255]中的某个值。
4 实验
4.1 实验数据
实验用到的语音数据来自于北京希尔贝壳科技有限公司出版的中文语音数据集AISHELL-1,该数据集由400名中国不同口音区域的发言人参与录制,采样率为16kHZ,包含178 h的普通话音频及文本。
4.2 实验配置
实验所使用的电脑操作系统为Ubuntu20.04.2LTS,硬件配置为Intel i7处理器,16GB运行内存,GPU为NVIDIA RTX 2060(6GB显存)。
本实验基于WeNet语音识别工具包[17]来进行,使用Fbank特征,编码器有12个Conformer Blocks,注意力头数设置为4。训练使用CTC loss与Attention loss 联合优化训练,避免 CTC 对齐关系过于随机,并可以使训练过程更加稳定, 取得更好的识别结果。
使用的组合损失如式⒁所示,[x]表示声学特征,[y]为对应标注,表示CTC loss,表示Attention loss,[λ]表示平衡CTC loss和Attention loss的系数并且[λ∈0,1][18-19]。
4.3 评价标准
在数据集AISHELL-1上进行实验,采用字错率(character error rate, CER)作为评价模型识别准确性的指标。如式⒂所示,字错率就是将插入I、替换S和删除D的词的总个数除以标准的词序列中词的总个数的百分比。
实时率RTF表示处理单位时长语音数据所需要的时间,如式⒃所示,该值越小表示模型处理语音的效率越高,即模型推理的速度越快。
其中,T表示所有音频总时间,单位是秒;t表示模型识别所有音频所用时间,单位是秒。
4.4 实验结果
本实验以在数据集AISHELL-1上训练得到的Conformer模型作为基线模型,对编码器部分Conformer Blocks中的卷积层进行剪枝。以L1范数作为剪枝的判断标准,对权重进行排序,按照不同的剪枝比例对卷积层进行剪枝,然后再对模型的线性层进行模型量化,以实验A和实验B的结果对比来验证模型压缩方法的有效性。
4.4.1 实验A
以L1范数为标准,采用传统的剪枝模式对模型编码器中全部Conformer Blocks的卷积层以不同的剪枝比例进行剪枝,结果如表1和图7所示,可以看出对模型进行剪枝操作后模型的RTF下降推理速度提高,但是模型的准确率也随之下降。随着剪枝比例的提升,模型的准确率急剧下降,在剪枝比例为0.35时,模型的CER已经达到53.58%,此时模型CER过高,不适合实际应用。
对模型完成以不同剪枝比例剪枝后,再对该模型进行8位整型量化,结果如表2和图8所示,量化后的模型推理速度得到提升,随着模型剪枝比例的增加,模型识别的CER也在提升。
如图9所示比较了剪枝模型和剪枝加量化后的模型的CER,图10比较了剪枝模型与剪枝加量化模型的RTF,从这两个图中可以看出对模型量化之后模型的准确率下降不明显,但模型的推理速度有很大提升。
4.4.2 实验B
在模型编码器中以L1范数为标准,使用改进的剪枝算法对编码器进行剪枝,按照Conformer Blocks排列的顺序等间隔对第1、3、5、7、9和11个Conformer Blocks中卷积层进行通道剪枝并进行参数量化,结果如表3和圖11所示,随着剪枝比例的提升,模型的RTF逐渐下降,模型的CER不断上升。
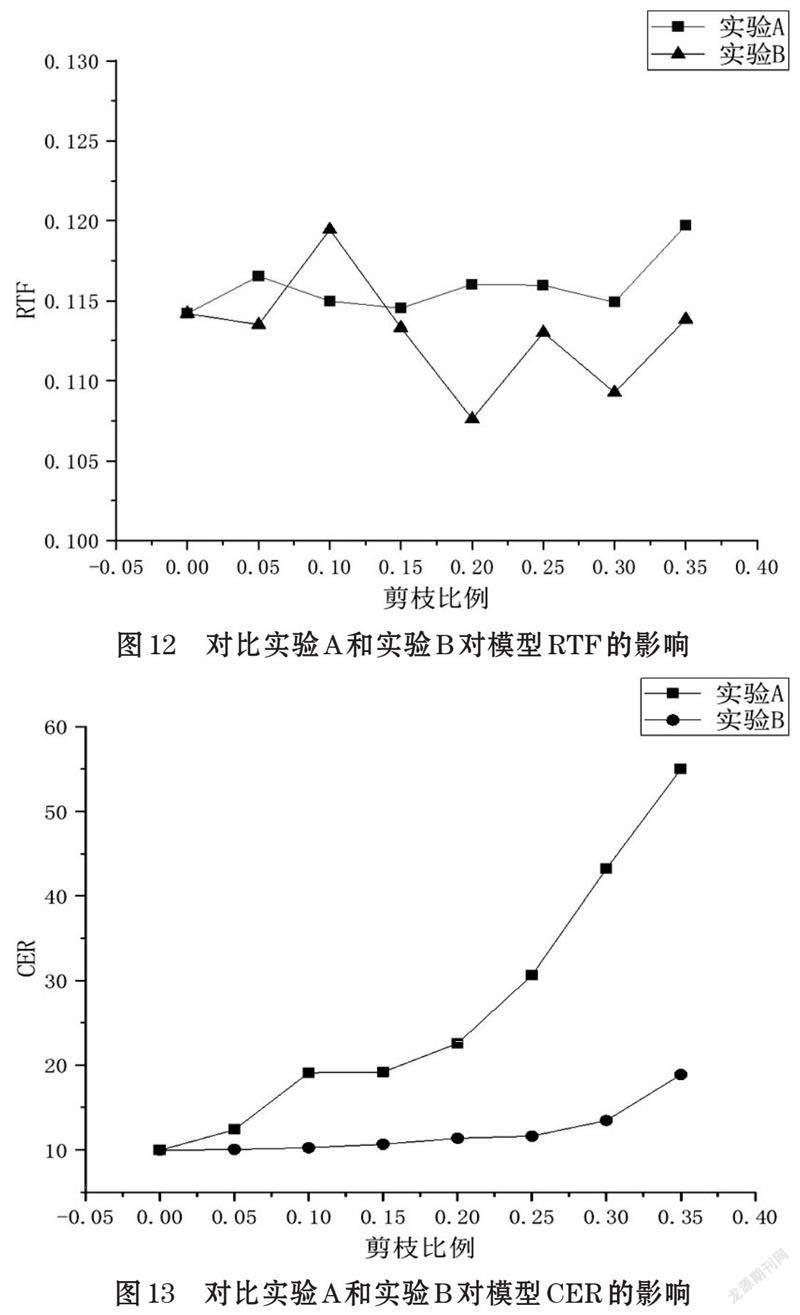
如图12所示,分别比较了两个实验对模型RTF的影响,可以看出随着剪枝比例的增加,模型的RTF都受到了影响,但实验B中的模型RTF较实验A下降明显,在剪枝比例大于0.15的情况下实验B中模型的RTF均小于实验A中模型的RTF。在图13中可以看出随着剪枝比例的增加,模型识别的准确率均发生了下降,并且对比两个实验,实验A中模型CER的变化更为明显,在剪枝比例不断增加的情况下其模型的CER均大于实验B中模型的CER,并且在实验B中,剪枝比例为0.2时模型压缩的效果最好。
4.4.3 对比结果
对比在剪枝比例为0.2时的不同模型性能(表2)。表4中,实验A中只进行剪枝的模型较基线模型的RTF降低0.00191,CER上升了12.58%,实验A中剪枝加量化的模型较基线模型的RTF下降0.01232,CER上升了12.93%;仅采用实验B中的剪枝方法所得到的模型与基线模型相比RTF下降了0.00974,CER上升了0.81%,而使用实验B中的剪枝加量化方法所得的模型,与基线模型相比RTF下降了0.02074,CER上升了1.71%,推理速度提升了16.2%。
基线模型的大小为207.91MB,压缩后的模型大小为72.69MB,仅为基线模型大小的34.95%。由此可以看出,使用本文提出的模型压缩方法的有效性。
5 结束语
本文针对在语音识别任务中的Conformer模型在资源受限设备上算力不足及资源缺乏的问题,提出了结合模型剪枝和模型量化的模型压缩技术来提升模型的推理速度和减小模型大小。实验表明,以L1范数作为判断标准在剪枝比例为0.2时,用本文所提出的间隔剪枝和模型量化相结合的模型压缩方法对基于语音识别的Conformer模型进行压缩时效果最好,压缩后的模型较基线模型的RTF下降了0.02074推理速度提升了16.2%,字错率CER却只下降了1.71%且模型大小仅为基线模型的34.95%,此时的模型在精度下降很小的情况下推理速度有较大的提升,模型大小缩减明显,更适合于实际应用的需要。
参考文献(References):
[1] Graves A, Jaitly N. Towards end-to-end speech recogni-tion with recurrent neural networks[C]//International conference on machine learning.PMLR,2014:1764-1772
[2] Miao Y, Gowayyed M, Metze F. EESEN: End-to-end speech recognition using deep RNN models and WFST-based decoding[C]//2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU). IEEE,2015:167-174
[3] Lu L, Zhang X, Renais S. On training the recurrent neural network encoder-decoder for large vocabulary end-to-end speech recognition[C]//2016 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP). IEEE,2016:5060-5064
[4] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems,2017,30
[5] Dong L, Xu S, Xu B. Speech-transformer: a no-recurrence sequence-to-sequence model for speech recognition[C]//2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE,2018:5884-5888
[6] Gulati A, Qin J, Chiu CC, et al. Conformer: Convolution augmented transformer for speech recognition. Proceedings of the 21st Annual Conference of the International Speech Communication Association. Shanghai,2020:5036-5040
[7] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[J]. Advances in neural information processing systems,2012,25:1097-1105
[8] 高晗,田育龙,许封元,等.深度学习模型压缩与加速综述[J].软件学报,2021,32(1):25
[9] 吴卫贤,赵鸣,黄晓丹.基于量化和模型剪枝的卷积神经网络压缩方法[J].软件导刊,2021,20(10):6
[10] Hassibi B. Second Order Derivatives for Network Pruning:Optimal Brain Surgeon[C]//CiteSeer.CiteSeer,1992:164-171
[11] Li H, Kadav A, Durdanovic I, et al. Pruning filters for efficient convnets[J]. arXiv preprint arXiv:1608.08710,2016
[12] Gong Y, Liu L, Ming Y, et al. Compressing Deep Convolutional Networks using Vector Quantization[J]. Computer Science,2014
[13] Wu J, Leng C, Wang Y, et al. Quantized convolutional neural networks for mobile devices[C]//Proceedings of the IEEE conference on computer vision and pattern recognition,2016:4820-4828
[14] Choi Y, El-Khamy M, Lee J. Towards the limit of network quantization[J].arXiv preprint arXiv:1612.01543,2016
[15] Graves A, Fernández S, Gomez F, et al. Connectionist temporal classification:labelling unsegmented sequence data with recurrent neural networks[C]//Proceedings of the 23rd international conference on Machine learning,2006:369-376
[16] Gao Z, Yao Y, Zhang S, et al. Extremely Low Footprint End-to-End ASR System for Smart Device[C]// 2021
[17] Zhang B, Wu D, Yang C, et al. Wenet: Production first and production ready end-to-end speech recognition toolkit[J]. arXiv e-prints,2021: arXiv: 2102.01547
[18] Watanabe S , Hori T , Kim S , et al. Hybrid CTC/Attention Architecture for End-to-End Speech Recognition[J]. Selected Topics in Signal Processing, IEEE Journal of,2017,11(8):1240-1253
[19] Kim S, Hori T, Watanabe S. Joint CTC-attention based end-to-end speech recognition using multi-task learning[C]//2017 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE,2017:4835-4839
*基金項目:山东省重大科技创新工程(2019JZZZY010120); 山东省重点研发计划(2019GSF111054)
作者简介:卢江坤(1996-),男,河北邢台人,硕士研究生,主要研究方向:语音识别。
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27 19:23:52
中国远程教育(2016年11期)2016-12-27 18:07:31
现代商贸工业(2016年25期)2016-12-26 09:58:02
江苏教育·中学教学版(2016年11期)2016-12-21 11:45:08
江苏教育·中学教学版(2016年11期)2016-12-21 11:36:29
现代情报(2016年10期)2016-12-15 11:50:53
考试周刊(2016年94期)2016-12-12 12:15:04
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
