
基于机器学习与特征工程的恶意链接检测研究
2023-04-10 01:29何智帆姜和芳刘涛姚兴博
科技风 2023年9期
关键词:机器学习
何智帆 姜和芳 刘涛 姚兴博


摘 要:随着互联网技术的飞速发展,人们对互联网的需求日益增加,同时互联网安全问题也逐渐引起人们的重视。其中,恶意URL(Malicious URLs)是网络安全研究的重要内容,因此实现对恶意URL的有效侦测对网络安全至关重要。本文介绍了恶意URL检测的应用背景及实现步骤,根据其攻击方式,归纳总结了两种常用的攻击方法,然后介绍了机器学习及特征工程在该领域中的应用情况,最后总结了现有方法不足之处,并对未来的研究方向做出了展望。
关键词:互联网安全;恶意URL检测;机器学习;特征工程
Abstract:With the rapid development of Internet technology,people's demand for the Internet is increasing day by day,and at the same time,the Internet security problem has gradually attracted people's attention.Among them,malicious URL (Malicious URLs) is an important part of network security research,so it is very important to realize the effective detection of malicious URL for network security.This paper introduces the application background and implementation steps of malicious URL detection,and summarizes two common attack methods.Then this paper introduces the application of machine learning and feature engineering in this field,finally summarizes the shortcomings of the existing methods,and discusses the future research direction.
Keywords:Internet security;Malicious URL detection;Machine learning;Characteristic Engineering
1 概述
随着互联网以及移动互联网的发展,越来越多的Web应用出现在应用市场上,人们利用链接便利地访问网上资源。但与此同时,不法分子会寻找其中的漏洞进行违法行为,恶意URL(Malicious URLs)便是其中之一。恶意链接检测任务[1-2]通常是对陌生的网络链接进行检测并判断其是否属于恶意链接。URL作为访问网络资源的入口,常常会被不法分子们通过某些手段所利用,如恶意URL中涉及恶意程序以及脚本等,恶意程序会在用户的计算机上下载脚本或者执行命令,这极大地侵害了用户计算机安全。除了在个人领域遭到威胁之外,近些年互联网公司中也相继发生各种安全威胁,恶意网站是网络安全中重要的威胁,它是病毒、蠕虫和其他恶意代码在线传播重要工具。恶意URL可以通过电子邮件链接、浏览器弹出窗口、文本消息、页面广告等进行形式传递,指向不可靠网站的链接,或者嵌入了非法下载内容。在当今的网络安全态势下,如何应对网络攻击与保障信息安全,必须纳入网络安全人员的考虑之中。这对人们日常生活、企业的经营发展以及政府的机密信息安防都有着重要的影响。
想要对恶意URL实现有效的检测,首先需要了解其常见的攻击形式,本部分整理了两种常见的恶意URL攻击形式,包括XSS攻击和SQL注入。
1.1 XSS攻击
XSS攻击(Cross Site Scripting)[5]是另一种广为人知的Web攻击方式。XSS攻击类型有三种,分为反射型XSS、存储型XSS以及DOM型XSS,其中反射型XSS与存储型XSS一般通过构造URL请求或者在服务器植入恶意脚本实现网络攻击,用户访问服务器时就会接收到恶意脚本。DOM型XSS攻击其实是流量劫持,通过提供一个网关截取用户信息,实现脚本攻击。
1.2 SQL注入
SQL注入[5-7]通过修改SQL语句侵害数据库信息。一般来说,互联网企业会将用户信息和自身提供的资源存放在服务器中。在B/S(Browser/Server)开发模式下出现的Web应用中,用戶获取资源只需在浏览器端使用简单点击或填写操作,就可以获取服务器资源,而底层的实现原理就是利用SQL语句操作数据库。
2 恶意URL检测方法
URL是互联网上资源的一种定位标志[8],一个完整URL的一般形式为:
[协议]://[主机号]:[端口号]/[文件路径]?[查询]
下表以一条URL为例,具体介绍其组成形式。
根据上表可以清晰地了解一般URL的组成成分,这是因为人脑可以对其进行分词,并对各个部分的含义进行猜测,如上述链接中的“webclub”我们会理解为“网页部门”。但是URL在机器中就是一串连续的字符串,机器也无法像人类一样对其含义进行猜测。因此我们要在机器学习的过程中完成以下两部分:URL分词与其向量表示。
传统的恶意URL检测方法比如黑名单技术[9]、规则技术[10],它们的检测能力已经呈现下降趋势,难以应对新型的网络攻击手段。近年来,随着人工智能研究的逐渐火热,机器学习技术在众多领域也能大放异彩,这为网络安全的巩固带来了新的思考,研究者们也提出了许多相应的解决策略,其中基于机器学习[11]以及特征工程[12]的恶意URL检测是一大研究方向,也是一项基础而重要的技术。
2.1 基于机器学习的恶意URL检测方法
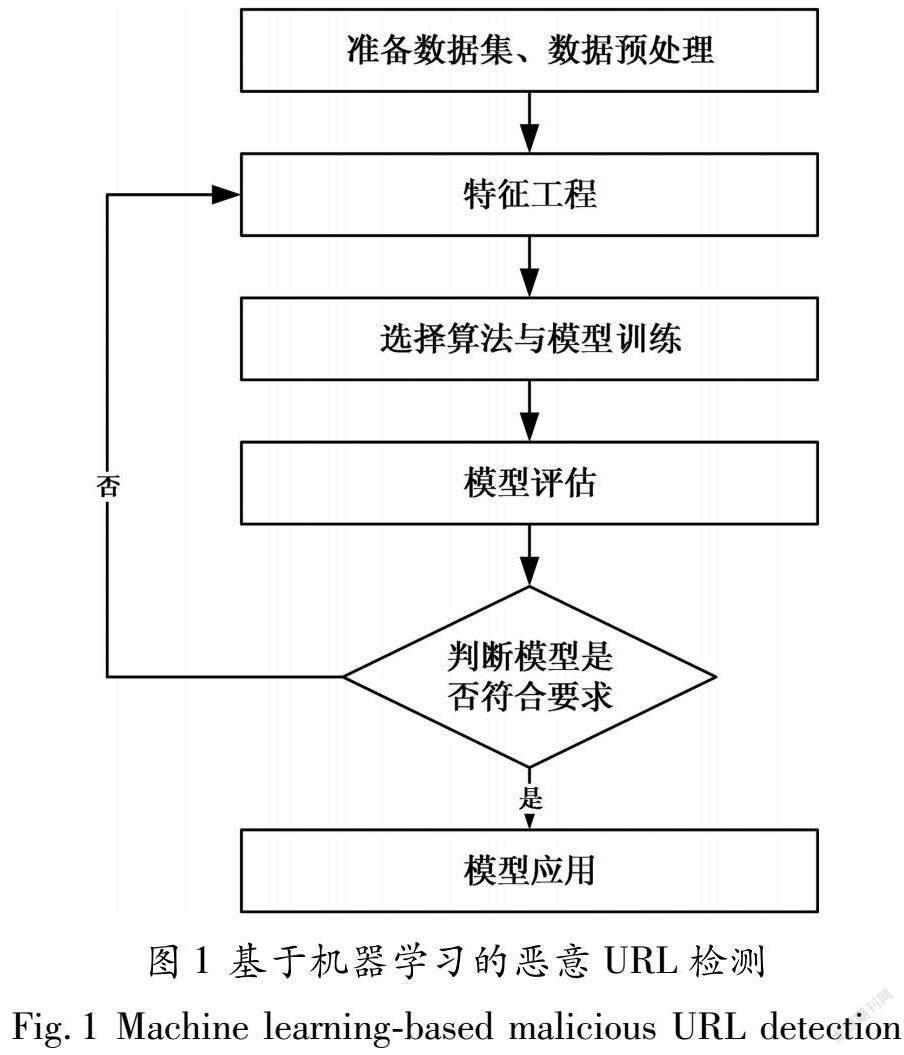
基于机器学习的恶意URL检测实现过程如下:
(1)获取具有正常请求和恶意请求的数据集。
(2)对数据集进行预处理,包括划分训练集、测试集等。
(3)对原始数据集进行特征抽取,并转化为向量形式,以输入模型。
(4)选择合适的机器学习的算法,使用特征矩阵训练检测模型。
(5)根据测试集计算模型的准确度,判断是否需要继续优化。
(6)将训练完的模型导出并应用,输入一条URL,判断其是否为恶意URL。
以上步骤总结为流程图如图1所示:
2.2 基于特征工程的研究方法
在机器学习模型训练的过程中,获取优质的特征信息至关重要,特征工程模块是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程,特征工程的好坏会直接影响机器学习的效果。在恶意URL检测中,该模块的任务是将原始URL数据进行特征提取,并转化成机器学习算法或模型能够读取的数据,即向量。一般的技术路线如图2所示,其中特征抽取常用的方法包括字典特征提取(sparse矩阵、one-hot编码等)、文本特征提取(CountVectorizer、TfidfVectorizer等),特征预处理主要是做无量纲化处理,包括归一化、标准化,特征降维主要包括特征选择(删除低方差特征、相关系数)和主成分分析PCA等。
在此我们主要将现有的基于特征工程的方法分为三类:
2.2.1 基于URL分词
在深度学习的自然语言处理(Natural Language Processing,NLP)领域,学者们根据分词任务的不同,将现有工具分为三类。其一,在中文领域常见的工具有jieba、THULAC、pynlpi和snowNLP等;其二,在英文领域常见的工具有NLTK,Spacy等。其三,观察URL不难发现URL中常出现一些特殊符号,因此可选用特殊符号作为分隔符来进行分词,即调用re包。
2.2.2 基于文本的URL特征提取
周磊等[2]在研究时,建立了一个检测模型,并设计了两种URL数据形式:仅依靠URL文字特征和联合URL文字特征与远程主机信息,在实验结论中,仅依靠URL文字特征就能达到97%的准确率,同时减少了访问远程主机的开销,在计算和内存需求方面都很轻便。
2.2.3 基于特殊字符的特征提取
在Warner G和Solorio T[8,13]研究中,使用URL文本的特殊符号作为分词标准,利用剩下的单词构建语料库词典,然而这种分词技术忽略了文本中特殊字符本身的重要意义。此外,恶意URL中出现特殊符号的数量和种类较多,频率也比较高,所以这会成为URL分类的一个重要特征。
结语
本文主要分为两部分对恶意URL检测方法进行研究,分别是基于机器学习以及基于特征工程的方法。总体来看,现有的方法已经能解决绝大多数问题,但是仍然存在以下不足之处:
(1)目前绝大多数检测方法仍基于原始字符串以及恶意网站的链接,缺乏对网页内容的直接判断。如果可以把网页内容同样作为判断依据,则可大大提升对恶意网站的屏蔽效果。
(2)目前的分类指标较为单一,除了将某一链接定义为恶意链接之外,还可以对其所属类型进行进一步分类,例如属于仿冒网站或是黑客入侵等。
参考文献:
[1]李泽宇,施勇,薛质.基于机器学习的恶意URL识别[J].通信技术,2020,53(02):427-431.
[2]周磊.基于深度学习的恶意URL检测方法[D].长江大学,2021.
[3]贾雪鹏.钓鱼网页联合特征与智能检测算法研究与实现[D].西安工业大学,2018.
[4]邹联扬.基于深度学习的钓鱼网页检测方法研究[D].西安科技大学,2020.
[5]罗超超.基于深度学习的SQL注入和XSS攻击检测技术研究[D].中国工程物理研究院,2020.
[6]张登峰.基于机器学习的SQL注入检测[D].重庆邮电大学,2017.
[7]陈君新.基于机器学习的XSS攻击检测技术研究[D].浙江工业大学,2018.
[8]M.X,L.H,X.L.A Refined TF-IDF Algorithm Based on Channel Distribution Information for Web News Feature Extraction[C].In:2010 Second International Workshop on Education Technology and Computer Science,2010:15-19.
[9]Khan F,Ahamed J,Kadry S,et al.Detecting malicious URLs using binary classification through adaboost algorithm[J].International Journal of Electrical and Computer Engineering(IJECE),2020,10(1):997-1005.
[10]M.S K,B.I.Frequent rule reduction for phishing URL classification using fuzzy deep neural network model[J].Iran Journal of Computer Science,2021,2(4):85-93.
[11]Kumi S,Lim C,Lee S.Malicious URL Detection Based on Associative Classification[J].Entropy,2021,23(2):1-12.
[12]N.S G,Anjali M.Feature Engineering Framework to detect Phishing Websites using URL Analysis[J].International Journal of Advanced Computer Science and Applications(IJACSA),2021,12(7).
[13]X.P,J.C,Y.X,et al.Which Feature is Better? TF*IDF Feature or Topic Feature in Text Clustering[C].In:2012 Fourth International Conference on Multimedia Information Networking and Security,2012:425-428.
作者简介:何智帆(1980— ),男,汉族,广东兴宁人,学士,会计师,研究方向:電力计量管理;姜和芳(1994— ),女,汉族,山东烟台,学士,助理工程师,研究方向:电能量数据管理;刘涛(1980— ),男,汉族,湖北石首,博士,高级工程师,研究方向:电力计量自动化。
*通讯作者:姚兴博(2004— ),男,汉族,江苏徐州人,本科,研究方向:智能数据处理与信息安全。
猜你喜欢
电子技术与软件工程(2016年22期)2016-12-26
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
活力(2016年8期)2016-11-12
科学与财富(2016年28期)2016-10-14
电脑知识与技术(2016年20期)2016-08-19
电脑知识与技术(2016年12期)2016-06-14
科教导刊·电子版(2016年10期)2016-06-02
科教导刊·电子版(2016年10期)2016-06-02
电脑知识与技术(2016年3期)2016-04-07
