
融合注意力机制的通道拓扑细化改进的图卷积网络
2023-04-06 04:38李昊璇李旭涛
测试技术学报 2023年2期
李昊璇,李旭涛
(山西大学 物理电子工程学院,山西 太原 030006)
人工智能(Artificial Intelligence)已被我国政府提升为国家战略,推动 AI 技术进步是我国抢占科技竞争主动权的重要举措。人类动作识别是人工智能中重要的分支之一,基于深度学习的骨架动作识别方法主要分为:基于循环神经网络(Recurrent Neural Network,RNN)、基于卷积神经网络(Convolutional Neural Network,CNN)和基于图卷积网络(Graph Convolutional Network,GCN)3类。早期基于深度学习的研究方法主要使用RNN和CNN来提取关节之间的显式特征。如Du等[1]使用RNN并逐层融合特征来识别骨架动作,但相近的动作却难以识别准确;Fan等[2]设计了3阶段的CNN网络,通过特征提取、通道融合、多任务集成学习进行动作分类,但这些方法过多地关注了周围物体及无关背景,或是使用庞大的网络,同时学习到很多无关的特征,准确率不能满足使用的需求。
近年来,基于骨架数据的图结构研究多了起来,原因在于图对骨架数据的优质表达,只关注对人体动作识别有效的人体姿势,通过对不同关节运动变化的学习,准确地学习每一动作的特征,使其在骨架动作识别方面大放光彩。基于图的结构,Yan等[3]在2018年首先提出时空图卷积网络(Spatial Temporal Graph Convolutional Network,ST-GCN)利用图卷积网络来识别骨架动作。之后,在图卷积领域的研究愈发多了起来,如基于GCN进行了更加充分的研究,更多的基线网络被提出[4-6]。
基于图卷积的研究大多以ST-GCN为基线网络,如多流图卷积网络(Multi-Stream Adaptive Graph Convolutional Network,MS-AAGCN)[7],通道拓扑优化(Channel-wise Topology Refinement Graph Convolution Network,CTR-GCN)[8],使用10层时间空间交替的卷积来提取特征,这无疑会增加网络训练的难度和复杂度。其中部分网络,如JB-AAGCN以关节、骨骼及其各自的运动流分别训练网络,然后探索不同的融合方式将其融合,增加了无形的训练时间,加大了训练难度。双流图卷积网络(Two-Stream Adaptive Graph Convolutional Network,2s-AGCN)上的每次训练需要用4个GPU训练一天,这使得在大规模数据集上的参数调整异常艰难。
Zhang等[9]利用一阶关节信息作为输入,无法将相互联系的关键点建模综合考虑。基于此,本文提出B-V模块(Bone Velocity)在数据的预处理部分利用关节信息得到二阶骨骼信息,并利用骨骼信息得到骨骼的运动信息,有利于识别肢体协同的动作,增强数据的表达能力。
先前的网络几乎都是静态非拓扑的网络结构,静态即表示关节中的参数α是不可学习的,非拓扑即没有矩阵来学习关节之间的特征。本文提出拓扑细化图卷积特征融合模块(Channel-eise Topology Feature Combination Graph Convolution,CTFC-GCN),极大地提高了本文所提出网络在空间特征上的表达。
在长时间跨度的骨架视频动作识别上,时间流之间的联系至关重要,虽然Zhang等[9]将空间最大池化和时间最大池化用于聚合时间流的特征,但时间流的特征聚合在池化之前是重要的,本文提出时间尺度上的时空特征注意力模块(ST-Joint Attention,ST-ATT),增强前后帧时间维度上的表达能力,能有效提高识别的准确率。
针对上述问题,本文提出了以SGN(Semantics-Guided Neural Network)为骨干网络模型的骨架动作识别网络(Attention and topology-A with Semantics-Guided Neural Networks,AA-GCN),在保证模型性能的前提下,对现有网络进行研究,主要贡献如下:① 对数据流的输入进行了研究,提出二阶的骨骼信息和运动信息同时作为输入,高效利用数据信息; ② 将动态非拓扑的网络结构变为可学习的动态拓扑结构网络,提出CTFC-GCN模块; ③ 为增强时间维度的信息利用,探索注意力机制在图卷积网络的应用,提出ST-ATT模块。实验表明,本文所提AA-GCN能有效识别骨架动作。
1 融合注意力机制和拓扑结构的语义图卷积网络
1.1 整体网络设计
本文以SGN为baseline网络,提出一种结合二阶骨骼信息及运动信息,注意力机制和通道拓扑细化模块的骨架动作识别网络AA-SGN,网络结构如图1 所示,分别为B-V模块,拓扑细化图卷积特征融合模块CTFC-GCN,时空特征增强注意力模块ST-ATT和时间流模块。

图1 AA-GCN网络结构
2-V模块为数据处理模块,将原始的关节信息处理成二阶的骨骼信息(Bone)和运动流信息(Velocity),利用两层卷积网络,把3通道的骨骼信息和运动流信息转换成64通道,将其相加融合后的特征与对原始关节编码后的高级特征进行cat操作,送入3层通道拓扑细化图卷积CTR-GC中进行通道的学习,并在每一个CTR-GC后加入1X1和1X3的卷积聚合通道的特征,组成CTFC-GCN模块,在空间流模块后加入ST-ATT注意力机制来关联图卷积学习到的位置及时间特征,强化对关节点特征的通道表述,为时间流模块的特征学习提取更多信息。
在时间流模块融入时序特征的编码,利用全局最大池化进行全局时间特征的提取,只剩余时间特征,送入两层卷积网络进行时间特征的学习,然后,再次进行全局最大池化,利用全连接层对学习到的通道特征进行人体动作的识别。以下对每一模块进行细化分析。
1.2 B-V模块
基于先前的研究,输入网络的数据预处理是十分重要的,一阶关节信息(Joint)作为输入,网络提取到的特征有限,这极大地限制了模型的表达。二阶信息为一阶关节信息处理后的信息,如骨骼信息(Bone),不仅包含了关节点信息,更是包含了关节之间的连接关系以及长度,二阶运动信息(Velocity)包含了输入的每一帧运动信息,其中第一帧的运动信息为0,将每一关节点的细微变化建模,输入网络,使网络学习到细微的关节运动特征,本文将二阶特征进行通道的特征转换,经过两层CNN,提取为高级特征,再将其相加融合。
假定输入网络的初始关节坐标X= {x∈Rn,c,t,v},其中N,C,T,V分别代表输入批次的大小batch_size、输入的通道数、输入的帧数以及输入的三维关节点的数目,通过式(1)、式(2)分别得到骨架数据的二阶骨骼信息和二阶运动信息。
Bi1=x[:,:,i1,:]-x[:,:,i2,:],
(1)
i1,i2分别代表相连接的关键点
V=x[:,:,:,1:]-x[:,:,:,0:-1].
(2)
由于最后一个维度为关节点维度,运动信息的获取主要是从第二帧到最后一帧,减去第一帧到最后一帧的关节点位置,所以在式(2)之后需要在第一帧处补0(即第一帧运动信息为0),得到完整的运动信息。
1.3 拓扑细化图卷积特征融合模块
通道拓扑图卷积(Channel-wise Topology Refinement Graph Convolution,CTR-GC)如图2 所示,主要分为通道细化拓扑模型、特征转换以及通道细化聚合模块3部分。通道拓扑细化模型中首先对输入的特征进行转换,使用Φ和Ψ函数进行通道维度的转换,M表示对两个函数转换后的特征进行激活(本文使用的激活函数为tanh函数),使其成为N×N的矩阵,隐式的建模学习关节之间的相关性。本文构建3个拓扑非共享的A矩阵,分别为每一关节不同帧的自我连接、同一帧不同关节与中心关节的连接、同一帧相连接的关节。R矩阵由式(3)得到,其中α设定为可训练的参数。
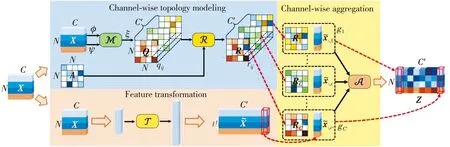
图2 CTR-GC
R=A+αQ.
(3)
特征转换部分通过二维卷积,将输入的特征转换成高级特征。在通道聚合部分,每一个通道的R矩阵与通道转换后的特征使用enisum函数即爱因斯坦求和运算,得到最终的输出。
CTFC-GCN由上述3个拓扑结构的CTR-GC及1×1和3×3的特征聚合卷积模块组成,并加入残差连接使网络的训练更加稳定,如图3 所示。

图3 CTFC-GCN
1.4 时空注意力模块
先前基于骨架的注意力模块主要有SENet中的SE注意力机制,Channel注意力,Joint注意力以及Song等[6]提出的Part注意力,许多论文的研究充分证明了注意力机制在骨架动作识别的有效性。本文的ST-Joint Attention将关节维度及时间维度分别用二维卷积来提取特征,为各通道获得不同的权重,如式(4),式(5)所示。
x_t_att=W2(relu(BN(W1V1+b1)))+b2,
(4)
x_v_att=W2(relu(BN(W1V2+b1)))+b2,
(5)
式中:V1,V2分别为压缩关节维度和时间维度得到的N×C×T和N×C×V的矩阵。
x_att=x_t_att×x_v_att.
(6)
通过式(6)得到ST-Joint Attention的注意力权重,注意力机制ST-ATT模块如图4 所示。

图4 ST-ATT
2 实验结果与分析
2.1 实验数据集及评估标准
NTU RGB+D Dataset[10](NTU60)是一个大规模的骨架动作数据集,该数据集是由Kinect摄像机收集,包含56 880个3D骨架序列动作,共有60个类。此数据集的数据划分方式主要有两种。一种为Cross Subject(CS)设定,按演员的不同,其中20个演员的动作用来训练网络,剩余的用来测试;另一种为Cross-View(CV)设定,该数据集有3个摄像机拍摄,把2,3号摄像机的数据集用来训练,1号的数据集用来测试。
NTU120 RGB+D Dataset[11](NTU120)在NTU60的基础上,作者进行了数据的扩充,增加到120个动作类,增加57 600个视频动作,共114 480个视频,为了减小演员的干扰,把人数增加到106人。对于Cross Subject(CSub)设定,一半人数的视频用来训练,其余人的视频用于测试;对于Cross Setup(CSet)设定,把一半拍摄的数据用来训练,其余用于测试。
2.2 实验细节
网络设定:B-V模块通道时C1设定为64;把时间和空间的语义信息分别编码成256和64通道;3层图卷积的通道时分别设定为128,128,256;时间模块的两层卷积通道设定256和512。本文选取的激活函数均为Relu。
训练设定:本文实验基于python3.6,pytorch1.3,CUDA10.2,GPU2080Ti,优化器选择Adam,初始的学习率设定为0.001,训练策略为共90epoch,分别在第60,80epoch学习率减半,权重衰减为0.0001,bitch size大小设定为64。
数据处理:将每一个完整的视频数据处理成20个片段,每次训练随机选取一帧组成20帧的序列,使网络的鲁棒性更强,较其他网络的数据处理方式,此方法极大降低了网络训练的难度,并且使用更少的图卷积就可使网络达到很好的效果,在训练时间上优于目前所提出的基线网络。
2.3 消融实验
本文在3D骨架数据集NTU60数据集上的CS设定上进行消融实验,其中A表示B-V模块,B表示拓扑细化图卷积特征融合模块CTFC-GCN,C表示本文的时间维度和空间维度注意力机制ST-ATT模块。
由表1 可以看出,通道细化级的图卷积网络对网络的提升较为明显,合适的数据处理方式能够在原网络上有所提升,注意力机制的使用使本文所提网络对动作的识别分类有很好的聚合作用。对每一模块的缺失比较如表2 所示。

表1 各模块的实验对比
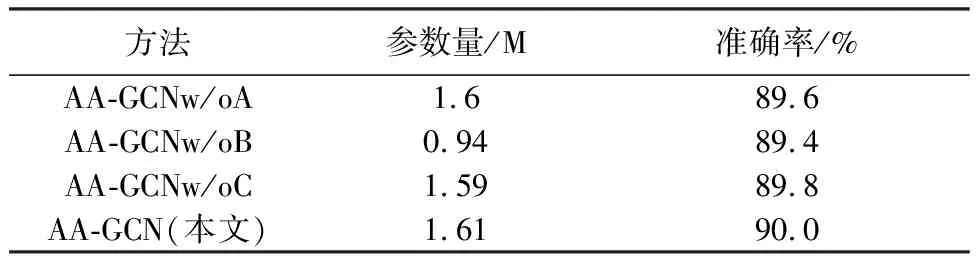
表2 移除各模块的实验对比
表2 表示每一模块缺失对本文模型的影响。其中w/o A表示移除了B-V模块;w/o B表示移除了拓扑细化图卷积特征融合模块;w/o C表示移除了本文的注意力机制模块。由表1 和表2 综合比较可得,每一模块的改动均对网络有一定的影响,其中+B+C会有0.4%的提升,+A会有0.1%的提升,但3个综合也即本文的模型会有1%的提升,每个模块的综合价值会更高。
2.4 实验结果与分析
本文在NTU60,NTU120两个大数据集上进行实验,与近年来提出的网络进行对比,从而证明本文所提模型的有效性,如图5、表3、表4 所示。
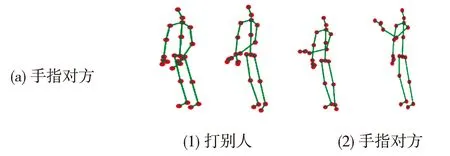
图5 NTU60数据集的可视化结果

表3 NTU60数据集的实验精度对比

表4 NTU120数据集的实验精度对比
在这些方法中,文献[3]提出时空图卷积网络用于骨架动作识别;文献[6]提出使用多流的数据来提升网络的准确率;文献[11]提出动作结构图卷积网络(Actional-Structural Graph Convolutional Network,AS-GCN); 文献[12]提出自适应网络(View Adaptive Neural Network, VA-NN)探索了角度对动作识别结果的影响,对视频视角进行调整;文献[13]提出预测编码图卷积网络(Predictively Encoded Graph Convolutional Network,PE-GCN)噪声的大小对网络的影响,作者人为地引入不同等级的噪声,旨在训练鲁棒性更强的模型;文献[14]首次使用提取视频中的某些帧来进行一次的训练,多个epoch能使网络获得较为满意的性能,且网络易于训练;文献[15]提出高效图卷积(Efficient Graph Convolutional Network,EFFICIENTGCN)探索了多种注意力机制在时空图卷积网络上的应用,提出更加轻量稳定的基线网络;文献[17]提出扩展的分层时态卷积网络(Dilated Hierarchical Temporal Convolutional Network,DH-TCN)对时许和骨骼点编码,提取短期和长期依赖关系。
表3 展示了本文提出的AA-GCN网络与SGN网络的预测结果对比,4种不同的动作可视化包括(a)手指对方、(b)拥抱、(c)给别人东西和(d)吃饭,图5 中(1),(2)分别为SGN和AA-GCN的预测结果,本文模型对这4类易错的动作识别有较好的准确度,可以看出(d)吃饭与摘眼睛由于手臂的细微动作,两种模型均不能有较好的结果,在(a)手指对方、(c)给别人东西两种动作上,本文效果更好,证明本文模型准确度高于SGN网络模型。
由表3 可以看出,对准确率影响最高的是拓扑细化图卷积特征融合模块,这也是本文主要的图卷积特征学习模块,充分表现了其有效性。
通过表3 和 表4 的实验结果可知,二阶特征的提出使模型获得了更加丰富的信息,通道化拓扑卷积使模型在多类动作识别上表现优异,在NTU120数据集上提升效果更加明显,与目前先进的基线如EFFICIENT相比,其准确率更高,并且训练难度大大降低,训练时间更短。
3 结束语
本文以语义引导图网络SGN为基线,对原始关节信息的特征信息进行多流的处理,得到骨骼数据流和运动信息流,有效地利用了数据。针对网络特征学习的不足,对SGN的自注意图卷积模块进行改进,提出通道细化图卷积特征融合模块,使网络可以针对动作类的不同,动态地学习与其相符的拓扑矩阵,在多类动作数据集上提升较为明显,在NTU120数据集的CSub,CSet上达到了84.9%和86.1%的准确率,提升了5.7%和4.6%的准确率。在真实场景下,动作的遮掩和动作的复杂性,使得到准确的关节点数据往往依赖于高效的姿态估计模型或姿态采集设备。对姿态估计算法有较为深入的研究,并将其与该模型结合,才能更好地发挥本文模型的作用,实现其应用价值。
猜你喜欢
电子乐园·上旬刊(2022年5期)2022-04-09
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
中国新技术新产品(2020年5期)2020-05-06
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
中国煤层气(2014年3期)2014-08-07
电视技术(2014年19期)2014-03-11
