
基于条件增强和注意力机制的文本生成图像方法
2023-04-06 04:38张丽红
测试技术学报 2023年2期
张 佳,张丽红
(山西大学 物理电子工程学院,山西 太原 030006)
0 引 言
文本生成图像是将融合噪声向量的文本描述信息输入到生成对抗网络,生成相应图像。传统方法主要基于基本生成对抗网络(Generative Adversarial Networks, GAN)[1],由生成器和判别器两部分组成,通常采用浅层卷积神经网络(Convolutional Neural Networks, CNN)构成,虽然可以基本完成图像生成任务,但生成图像质量较低。
目前,国内外对文本生成图像的研究主要通过增加网络深度和改进生成器网络提高图像生成质量。Scott Reed等[2]首次提出将循环神经网络(Recurrent Neural Network,RNN)作为文本编码器,以CNN组成生成对抗网络,作为主干网络的网络模型,能够基本实现文本生成图像;Han Zhang等[3]提出StackGAN模型,其主干网络是将生成对抗网络基本模块进行两次堆叠,使图像生成过程分为两阶段进行,第一阶段生成低分辨率图像,第二阶段以第一阶段为基础生成高分辨率图像。Dunlu Peng等[4]提出新的文本视觉特征融合方法,分别将词语特征、语句特征与视觉特征进行融合,通过3次堆叠生成对抗网络模块进行图像生成。
由于上述方法生成的图像分辨率较低,分阶段生成图像训练过程繁琐,计算量过大。因此,受文献[3]中条件增强模块和文献[5]中卷积注意力机制的启发,本文采用注意力机制和条件增强模块改进生成器网络,在文本特征和视觉特征的融合过程中,加强生成图像和给定文本描述之间的语义一致性,不需要进行多次文本视觉特征融合,训练过程简洁,在相关数据集上得到优良的实验结果。
1 系统框架
基于条件增强和注意力机制的深度融合生成对抗网络的整体网络架构如图1 所示,整个网络模型由文本处理网络和生成对抗网络组成。
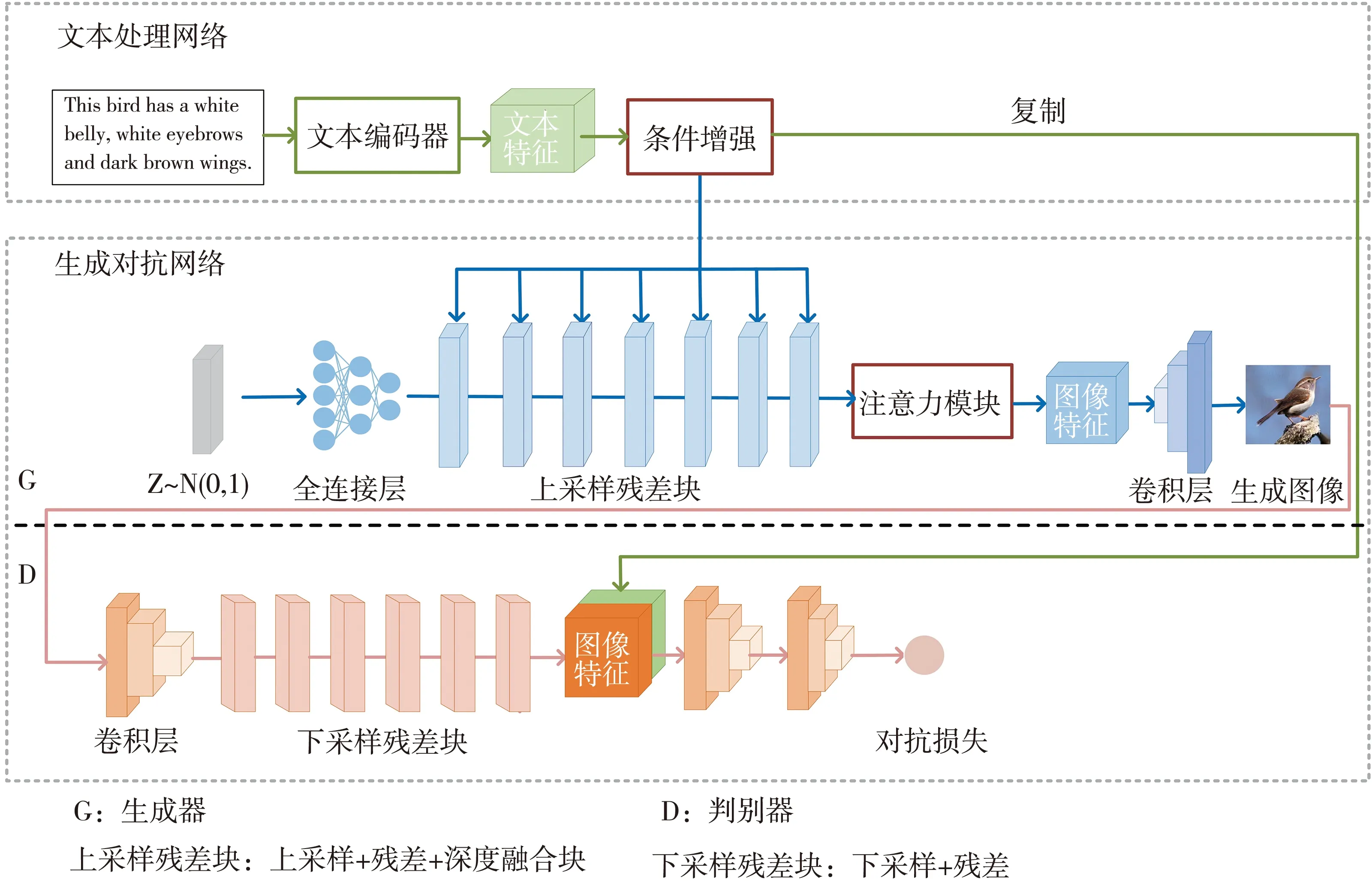
图1 基于条件增强和注意力机制的深度融合生成对抗网络结构
文本处理网络由文本编码器和条件增强模块组成。文本编码器采用双向长短期记忆网络(Bidirectional Long Short-Term Memory,BiLSTM)[5]对文本进行特征提取,条件增强模块(Conditioning Augmentation,CA)[6]进一步丰富文本语义信息。
生成对抗网络由生成器G和判别器D组成。生成器由上采样残差块、注意力机制和卷积层组成。该网络有两个输入,一是文本处理网络所得文本特征,二是服从高斯分布的随机噪声向量Z~N(0,1)。两者在上采样残差块中逐步融合得到高分辨率图像特征,输入注意力机制中对文本描述的关键信息进行处理,再通过卷积层生成图像。判别器由卷积层和下采样残差块组成,将生成器所得生成图像通过卷积层进行特征提取,下采样残差块对特征进行下采样并融合文本特征,判别生成图像与真实图像,结合MA-GP损失设计对抗损失函数进行网络评估,反馈更新生成器参数生成更高质量的图像。
2 基本原理
2.1 文本处理网络
2.1.1 BiLSTM网络
文本处理网络采用双向长短期记忆网络作为文本编码器,其目标是从语句中学习文本特征表示,将语句中的单词依次输入BiLSTM网络。该网络由若干长短期记忆模块(Long short-term memory,LSTM)组成,该模块能够捕捉双向语义信息,丢弃需要遗忘的信息并记忆新的信息,使有效信息得以传递。LSTM网络结构如图2 所示,主要由遗忘门ft、记忆门it、输出门ot组成。

图2 长短期记忆网络模型结构
遗忘门
ft=σ(wf×[ht-1,xt]+bf).
(1)
记忆门
it=σ(wi×[ht-1,xt]+bi).
(2)
记忆内容更新单元
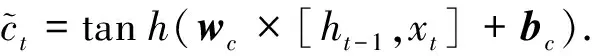
(3)
当前时刻记忆单元
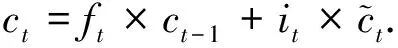
(4)
输出门
ot=σ(wo×[ht-1,xt]+bo).
(5)
当前记忆单元输出
ht=ot×tanh(ct),
(6)
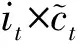
LSTM模块数量由单词数决定,如图3 所示,以3个单词为例,由3个前向LSTM模块和3个后向LSTM模块构成BiLSTM模型。由LSTML得到前向隐向量特征{hL0,hL1,hL2},由LSTMR得到后向隐向量特征{hR0,hR1,hR2},两者拼接为{[hL0,hR0],[hL1,hR1],[hL2,hR2]},即文本特征φt={h0,h1,h2}。

图3 双向长短期记忆网络模型结构
2.1.2 条件增强模块
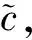

图4 条件增强模块

(7)
式中:⊗表示按元素相乘;ε表示服从数学期望为μ;方差为σ2的正态分布,记为ε~N(μ,σ2)。取μ=0,σ=1时,该分布为标准正态分布ε~N(0,1),并且此随机噪声维度为100×1×1。
2.2 生成对抗网络
生成对抗网络由生成器和判别器组成,二者交替训练以相互竞争。生成器不断优化生成判别器难以区分的图像,尽可能再现真实数据分布,同时促使判别器不断优化以区分真实图像和生成图像。总体而言,训练过程类似于二者交替进行最小、最大博弈。
2.2.1 生成器G
生成器有两个输入。一是文本处理网络所得文本特征,二是从与ε相同的标准正态分布中取样,得到维度同为100×1×1的随机噪声向量Z~N(0,1),通过全连接层输出尺寸为(ngf*8)×4×4的特征张量,其中ngf为生成器的特征数目,初始大小为64。生成器由上采样残差块、卷积注意力模块(Convolutional Block Attention Module,CBAM)和卷积层(卷积核大小为3×3)组成。
上采样残差块设置为7层,在该模块中逐步加深文本特征与视觉特征融合以得到高分辨率图像特征。上采样残差块由上采样、残差网络和深度融合块(Deep Fusion Blocks,DFBlocks)组成,模块结构如图5(a)所示。上采样采用紧邻插值法,放大倍率设置为2,逐步将分辨率从4×4上采样至256×256。使用残差网络可以缓解由于网络层数加深而导致的梯度消失问题。DFBlock的模型结构如图5(b)所示。该模型由两个仿射层和ReLU层依次堆叠组成,文本特征作为条件作用于仿射层,使该模块可以更好地发挥作用,有助于充分利用文本信息,实现更有效的特征融合。

图5 上采样残差块
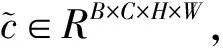

图6 仿射层原理图

(8)

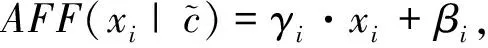
(9)
式中:AFF表示仿射变换;xi表示视觉特征通道数。
将经过上采样残差块的高分辨率图像特征输入到CBAM注意力模块,该模块是一种有效而简单的前馈卷积神经网络注意力机制。给定输入特征,通过卷积运算可以使得该特征在通道和空间两个维度上进行特征细化。CBAM总体模型如图7 所示,该模块有两个顺序子模块:通道注意力机制和空间注意力机制,通过顺序连接方式将二者结合。实验结果表明,将通道注意力模块置于空间注意力模块之前效果更好。将输入特征F∈RC×H×W输入CBAM模块,依次输出一维通道注意特征F′∈RC×1×1和二维空间注意特征F″∈R1×H×W。总过程如式(10)

图7 CBAM模块
F′=MC(F)⊗F,F″=MS(F′)⊗F′,
(10)
式中: ⊗表示按元素相乘;F′是经过通道注意力机制MC的中间特征;F″是经过空间注意力机制MS的细化特征。
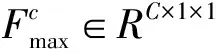

图8 通道注意力机制模块
Mc(F)=σ(MLP(AvgPool(F))+
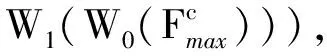
(11)
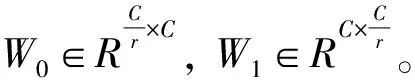


图9 空间注意力机制模块
MS(F″)=
σ(f7×7([AvgPool(F′);MaxPool(F′)]))=

(12)
式中:σ表示sigmoid激活函数;f7×7表示滤波器大小为7×7的卷积运算;[;]表示特征融合。
2.2.2 判别器D
判别器的输入为生成器的生成图像。判别器由下采样残差块和二维卷积层(3×3)组成。下采样残差块将下采样嵌入到残差网络中。图像通过卷积层(3×3)进行特征提取,所得图像特征分辨率为128×128,下采样残差块设置为6层,在残差网络中通过一个二维的平均池化下采样操作得到分辨率为4×4的图像特征,在此基础上融合文本特征,输入判别器中得到对抗损失,并融合匹配感知零中心梯度损失(Matching-Aware zero-centered Gradient Penalty,MA-GP)对网络进行评估,判定文本图像语义一致性,调整生成器参数得到更高质量的图像。
在二维数据空间中有4种数据对:文本匹配的生成图像、文本不匹配的生成图像、文本匹配的真实图像、文本不匹配的真实图像。为从给定文本描述中生成文本匹配的真实图像,判别器应将该数据点放在损失函数最小点,并将其他数据点置于高点。为更好地区分生成图像和真实图像,在原本损失函数的基础上,引入MA-GP损失。该损失函数应用的数据点为文本匹配的真实图像,即

(13)
该损失是一种基于判别器的正则化策略。实验证明,在对抗损失的基础上融合MA-GP损失,可以使得判别器提高图像判别能力。与其他模型方法相比,MA-GP没有引入额外网络计算文本图像的语义一致性,因此,不会增加文本生成图像过程中的网络复杂度和训练参数。
3 训练过程与网络损失函数
使用Adam[7]优化网络,β1=0.0,β2=0.9,生成器的学习率设置为0.000 1,判别器的学习率设置为0.000 4。对CUB birds 200数据集进行500个轮次的训练,批量处理数量为24,对MSCOCO数据集进行300个轮次的训练,批量处理数量为12。
该网络损失函数为
LD=L文本匹配真实图像+L文本匹配生成图像+L文本不匹配损失+
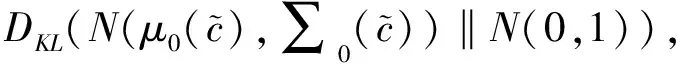
(14)
4 实验结果及分析
4.1 数据集
实验在MSCOCO和CUB birds 200两个数据集进行。CUB birds 200数据集包含200种鸟类,11 788幅图像,每幅图像有10种语言描述,将150种鸟类图像共8 855幅图像作为训练集,50种鸟类图像共2 933幅图像作为测试集。MSCOCO 2017数据集包含91种类别,每幅图像有5种语言描述,其中117 266 幅图像作为训练集,40 670 幅图像作为测试集。
4.2 评价指标
采用图像分数(Image Score,IS)和弗雷歇初始距离(Fréchet Inception Distance,FID)评估文本生成图像模型的性能。
IS计算生成图像的清晰度,更高的IS意味着生成图像质量更高。
IS=exp(Ex~PgDKL((y|x)‖p(y))),
(15)
式中:x表示从生成图像数据分布中采样的数据;y是预训练网络预测的图像标签;IS计算条件分布p(y|x)和边缘分布p(y)之间的KL散度。如果模型能够生成多样化和真实的图像,那么两个分布之间的KL差异将很大。
FID计算生成图像的特征向量和真实图像的特征向量之间的距离。该距离越近,表明模型的多样性越好。

(16)

4.3 实验结果
对基于条件增强和注意力机制的深度融合生成网络进行训练和测试。部分实验结果如图10、表1~表3 所示。
图10 中(a),(b)为本文网络在CUB birds 200数据集的实验结果图,图(c),(d)为在MSCOCO数据集的实验结果图,(e),(f),(g),(h)分别为基础生成对抗网络、stackGAN,DM-GAN,AttnGAN对于鸟类数据集的生成效果,可以观察到本文网络模型生成图像细节效果最优。

图10 深度融合网络运行结果图
表1 为其他方法与本文方法在鸟类数据集上的IS指标,通过对模型的改进,IS指标提升了0.6,体现出本文模型的优势。

表1 本文方法与其他模型的评价指标比较
表2 为其他方法与本文方法在鸟类数据集和COCO数据集的FID指标,通过对模型的改进,对于CUB birds 200数据集FID指标提升了0.59,对于COCO数据集FID指标提升了2.05,体现出本文模型的优势。

表2 本文方法与其他模型的评价指标比较
表3 为MA-GP损失的消融研究结果对比。Baseline表示不引入该损失的网络模型,Baseline+MA-GP表示引入该损失的网络模型。实验结果表明,该损失函数的引入有助于提升图像生成效果。

表3 MA-GP损失消融结果对比
4.4 损失函数曲线
本文网络在CUB birds 200数据集上生成器和判别器的损失函数曲线如图11、图12 所示。其中生成器的损失函数值趋向于2,判别器的损失函数值趋向于1.1,网络收敛。
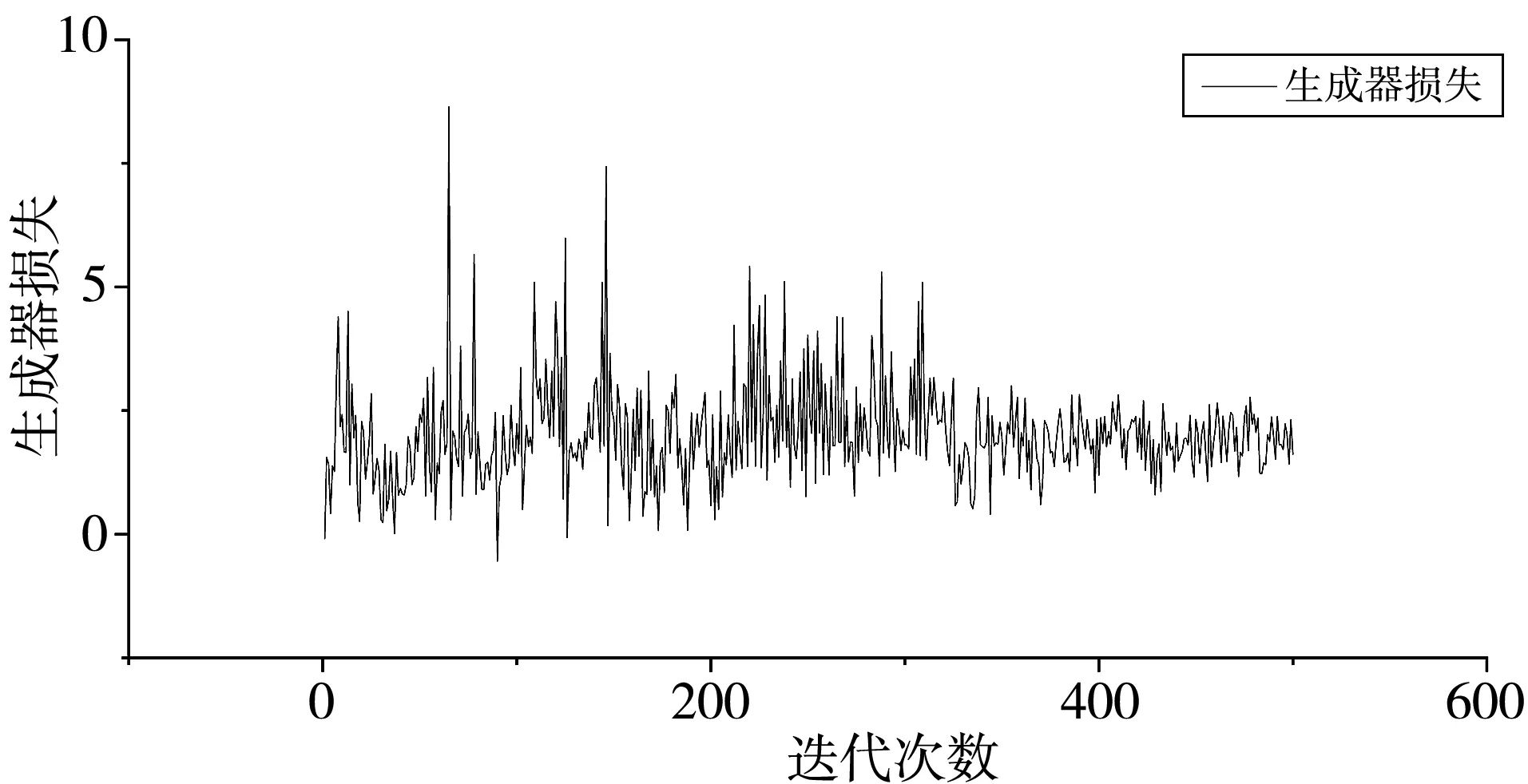
图11 生成器损失函数曲线
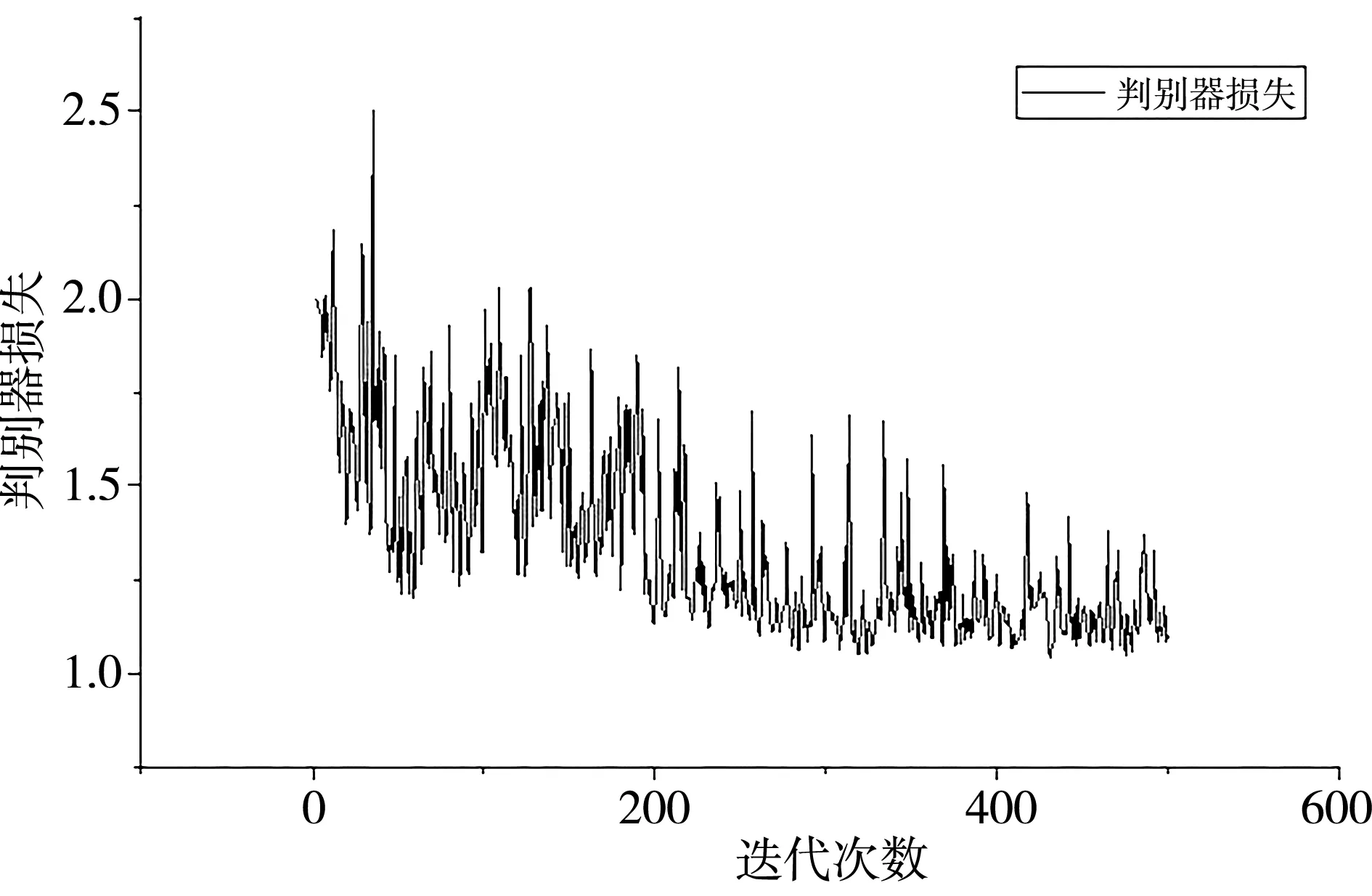
图12 判别器损失函数曲线
5 结 论
本文设计了一种基于条件增强和注意力机制的深度融合生成对抗网络用于文本生成图像的方法。对于文本处理网络,通过BiLSTM网络进行文本特征提取,然后,使用条件增强模块丰富文本语义信息。对于生成器,将所得文本特征融合噪声向量输入上采样残差块得到高分辨率图像特征。使用注意力机制对特征进行调整,之后通过卷积层得到生成图像。对于判别器,对生成图像进行特征提取,通过下采样残差块降低特征分辨率,将对抗损失与MA-GP损失相结合,对模型进行优化。实验结果表明,该网络模型的IS和FID指标均优于其他网络模型。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
河南科技(2015年8期)2015-03-11
