
融合多尺度卷积的端到端宫颈细胞分割
2023-03-30 08:52王文涛王嘉鑫陈大江
现代计算机 2023年2期
王文涛,王嘉鑫,张 根,陈大江
(1.中南民族大学计算机科学学院,武汉 430074;2.湖北省制造企业智能管理工程技术研究中心,武汉 430074)
0 引言
宫颈癌是女性最常见的恶性肿瘤之一,据世界卫生组织估计,目前全世界约有100万妇女患有宫颈癌。幸运的是,宫颈癌是目前唯一明确病因、可预防、早发现可治疗的癌症[1]。宫颈细胞涂片筛查是早期检测宫颈癌的重要细胞学筛查方法之一,但传统的细胞涂片需要专业病理学家进行手动筛查,分析过程繁琐、耗时,长时间工作下容易出错,因此,计算机辅助筛查在该领域有着重大意义。
细胞学筛查需要观察细胞形态特征,如形状、颜色、尺寸等,分辨是否为异常细胞[1],计算机辅助筛查系统通过自动分割核质边界、特征提取和自动分类等方式来自动筛查异常细胞。而细胞分割作为首要任务,其精确度决定了后续分类筛查的准确率,但细胞涂片中的细胞形态极其不规则,染色质不均匀导致细胞边界不清晰,想要在涂片中准确分割出核质是非常困难的。目前对细胞进行语义分割的方法主要有以下两类:
(1)基于形态学的传统细胞语义分割方法。2011年,Plissiti等[2]使用分水岭与基于形态学先验的方法,先对图像核质区域进行粗分割,再使用距离相关规则以及支持向量机(support vec‑tor machine,SVM)的像素分类方法进行分割的细化。2015年,Chalfoun 等[3]通过计算局部对比度来检测像素强度变化较大的区域,即可能是细胞主体的区域,再使用局部对比度阈值来分割出细胞边界,并且使用了一种迭代算法将细胞边缘的光晕去除。但传统的分割方法只分析了底层特征,无法提取高级的结构特征,存在精确率低、泛化能力差、效率低等问题。
(2)基于深度学习的细胞语义分割方法。随着深度学习的快速发展,其在细胞分割领域中的运用越来越广泛,深度学习避免了人工提取特征的局限,并提供更高的精确度和更快的速度,其中卷积神经网络(convolutional neural net‑works,CNN)是最常用的模型之一。2018 年,Liu 等[4]使用了一种利用像素先验信息的神经网络Mask R‑CNN(mask regional convolutional neural network),先通过基于残差网络(residual net‑work)和特征金字塔(feature pyramid network)的特征提取网络确定细胞的感兴趣区域,再进行区域卷积获得粗分割的掩膜图,最后通过一个局部全连通条件随机场对分割图进行细化,得到了更高的准确度。2021年,Roy等[5]利用一个基于编码器-解码器的语义分割模型DeepLabv3进行细胞分割,编码器包含了空洞卷积与多尺度并行的空间金字塔池化模块,可以提取丰富的语义信息,通过简单有效的双线性上采样解码器模块进行空间信息的恢复,有效地提高了精度与运行效率。此外,DenseNet[6]、D‑MEM[7]、ICPN[8]等模型也被用来提高分割性能。虽然这些算法在一定程度上提高了准确率,但通常具有适应特定任务或是数据的网络结构特点,且数据不平衡时模型性能较差。
在众多卷积神经网络模型中,全卷积网络(fully convolutional networks)[9]是医学图像分割领域中的研究热点之一,在各种全卷积网络体系中,U‑Net[10]模型是其中应用最为泛用的模型之一。U‑Net模型是一个像素到像素、端到端的网络,编码器与解码器之间有跳跃连接层,只需要较少的训练数据就保留很多特征信息,然而,向标准的U‑Net结构中直接添加更多层,会使网络太深,导致梯度消失,难以收敛。
本文受U‑Net 模型的启发,结合Inception‑Res[11]结构的优点,采用了一个改进的端到端模型IR U‑Net(Inception‑Res U‑Net),主要贡献如下:①通过Inception‑Res 结构增加网络宽度的同时减少了冗余计算,并能提取多尺度特征,提高网络精确度;②通过使用Leaky‑ReLU 减少“神经元死亡”导致的网络稀疏特征多、难以收敛的问题;③采用改进的损失函数Focal‑Dice Loss 来解决细胞图像部分边界模糊、目标区域大小差异大、学习困难的问题。
1 IR U⁃Net模型
本节将介绍模型的整体结构以及内部模块的具体结构,整个网络以U‑Net作为主干网络模型,内部多尺度特征提取与特征融合模块为In‑ceptioni‑Res 结构,模型为不包含全连接层的端到端模型,输入输出为分辨率相同的图像。
1.1 模型整体结构
图1展示了模型的整体结构,模型上半部分为编码器,用于特征提取;下半部分为解码器,用于像素还原。解码器中上采样的输出将与相应编码器同层特征图进行拼接,作为解码器下一层输入,将原始模型中编解码器部分的3 × 3卷积模块替换为Inception‑Res模块。
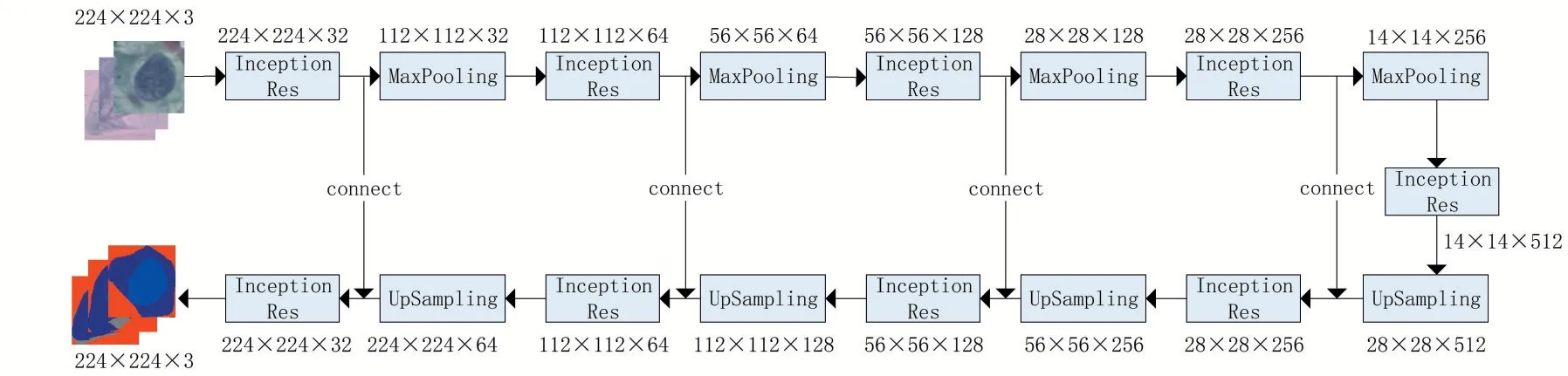
图1 模型结构图
模型的输入图像分辨率为224 × 224,通道数为3,编码器中最大池化层(MaxPooling)对特征图进行下采样,使特征图分辨率缩小一半,经过四个Inception 模块和池化层后,特征图缩小至14 × 14 的大小。解码器部分的上采样层(UpSampling)将特征图分辨率还原至原来的一倍,经过四个Inception 模块和上采样层后,图像将恢复到与输入分辨率相同,其中四次跳跃连接加强了浅层与深层特征的融合,使得分割结果更为精细。最后经过一个包含1 × 1 卷积层与sigmod 激活层的分类器,对像素进行分类,输出一个三通道的语义分割结果。
1.2 Inceptioni⁃Res 模块
本文采用了一种改进的Inceptioni‑Res 结构,如图2所示,该结构与原始卷积结构不同,使用了三个不同分支结合的卷积核,主要目的是使用不同分支不同大小的卷积核输出一个聚合特征图,多分支的优点主要在于网络能够灵活调整出对训练有益的卷积核大小,并形成密集的聚合特征图,配合残差结构,使学习效率增加。结构中多个1 × 1 卷积核能够改变输入维度以减少训练参数,使得学习更加容易。
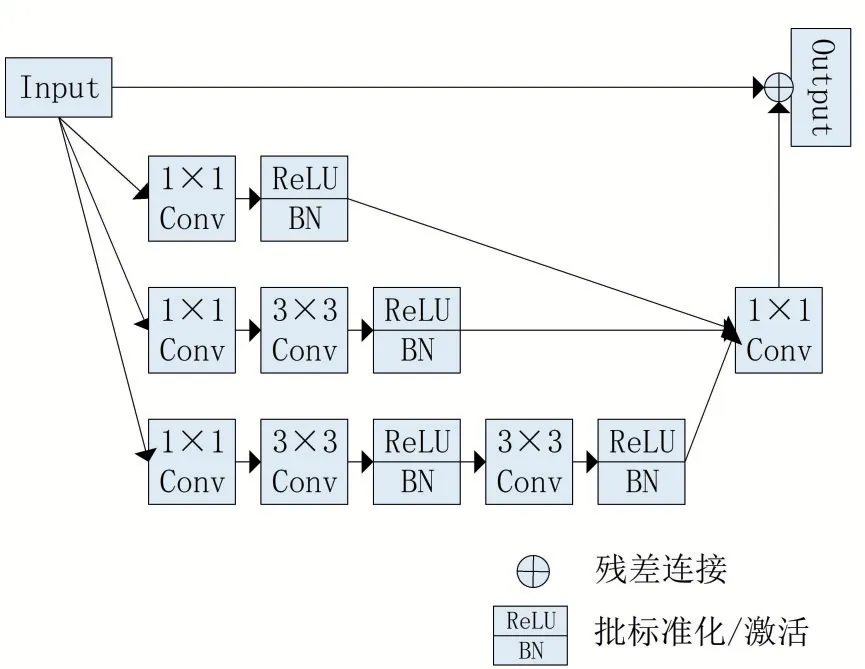
图2 改进的Inceptioni⁃Res结构
2 结构与损失函数优化
2.1 批标准化模块
在本文模型中,每个卷积层后加入了批标准化模块(batch‑normalization)[12],当数据通过卷积层后,其特征分布可能会发生偏移,当卷积层增加时,偏移会加重,这会产生梯度消失等现象,批标准化可以在保留卷积层的同时,使得数据始终保持标准正态分布,加快训练速度。批标准化的计算首先是对输入数据B={x1,x2,…,xi}进行标准化:
式(2)将标准化后的数据再进行一个线性变换,虽然这里重新对数据进行偏移,但神经网络可以学习变换参数γ与β来自动衡量标准化操作是否对优化产生效果。
2.2 激活函数
批标准化后,使用了ReLU(rectified linear unit)激活函数的变体Leaky‑ReLU[13]进行一个输入端到输出端的非线性映射。原始ReLU 激活函数在训练时,值小于0的神经元的梯度会一直为0,容易产生“神经元死亡”的问题,这样会导致网络稀疏特征多,难以收敛。而Leaky‑ReLU函数会给负轴微小的斜率,使得神经元的梯度不会完全消失,如图3所示。

图3 ReLU函数与Leaky⁃ReLu函数
Leaky‑ReLU函数的表达式如下:
其中:k为一个固定参数且k∈(0,1),一般取0.01[13]。
2.3 改进损失函数
语义分割常用的损失函数为交叉熵损失函数(cross entropy loss)与Dice 系数损失函数[14],公式如下:
其中:M为类别数量,当样本i的真实类别为c,则yic取1,否则取0,pic为样本i属于类别c的预测概率。
其中:y为真实标签;p为预测概率;c为类别;ε为平滑系数。
何凯明等[15]提出了改进的交叉熵损失函数焦点损失(Focal Loss),公式如下:
其中:
α、γ均为调节因子,且α∈[0,1],γ>0,α用来调节正样本损失的重要程度,γ用来调节难样本损失的重要程度。
交叉熵损失会对图像中所有的像素点进行平等地计算,若图像中存在区域非常小的像素类别,则容易被大范围的背景区域干扰,导致分割不准确。Dice 损失函数是一个区域相关的损失函数,损失值不受背景区域大小的影响,所以Dice 损失函数善于挖掘前景区域,相比于交叉熵损失函数,更适用于类别不平衡的情况。本文通过焦点损失与Dice 损失函数结合解决数据不平衡的问题。改良的损失函数公式如下:
其中:wc为c类别的权重;β为调节因子,且β∈(0,1),使得模型更加关注Dice 损失较小的样本,本文中β一般取0.5。
3 实验结果及分析
本节将介绍实验数据、预处理过程、评价指标、与其他分割算法的性能对比实验分析以及展示模型各模块影响的消融实验分析。
3.1 实验数据与预处理
本文的实验均在公开的Herlev 宫颈细胞数据集[16]上进行,该数据集是由丹麦赫列夫大学医院(Herlev university hospital)采集的样本制作而成,其具体组成如表1所示。
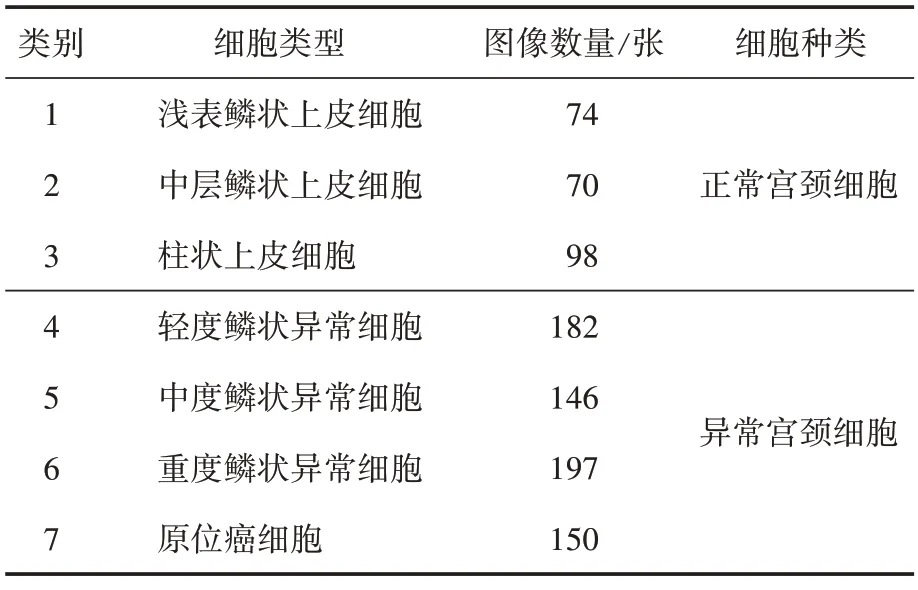
表1 Herlev宫颈细胞数据集组成
该数据集由917 张单个宫颈细胞图像组成,共有七类细胞,每一张图像都对应着一张语义标注GT(groud truth)图像,如图4 所示,所有的类别以及GT 图都是由权威专家人工标注得来,GT 图像中浅蓝色区域代表细胞核,深蓝色区域代表细胞质,灰色区域代表细胞ROI(region of interest),红色区域为背景区域。图像的分辨率为0.201微米/像素,平均大小为156 × 140像素。其中最长边达到768 像素,而最短边仅有32 像素,尺寸差异范围较大。
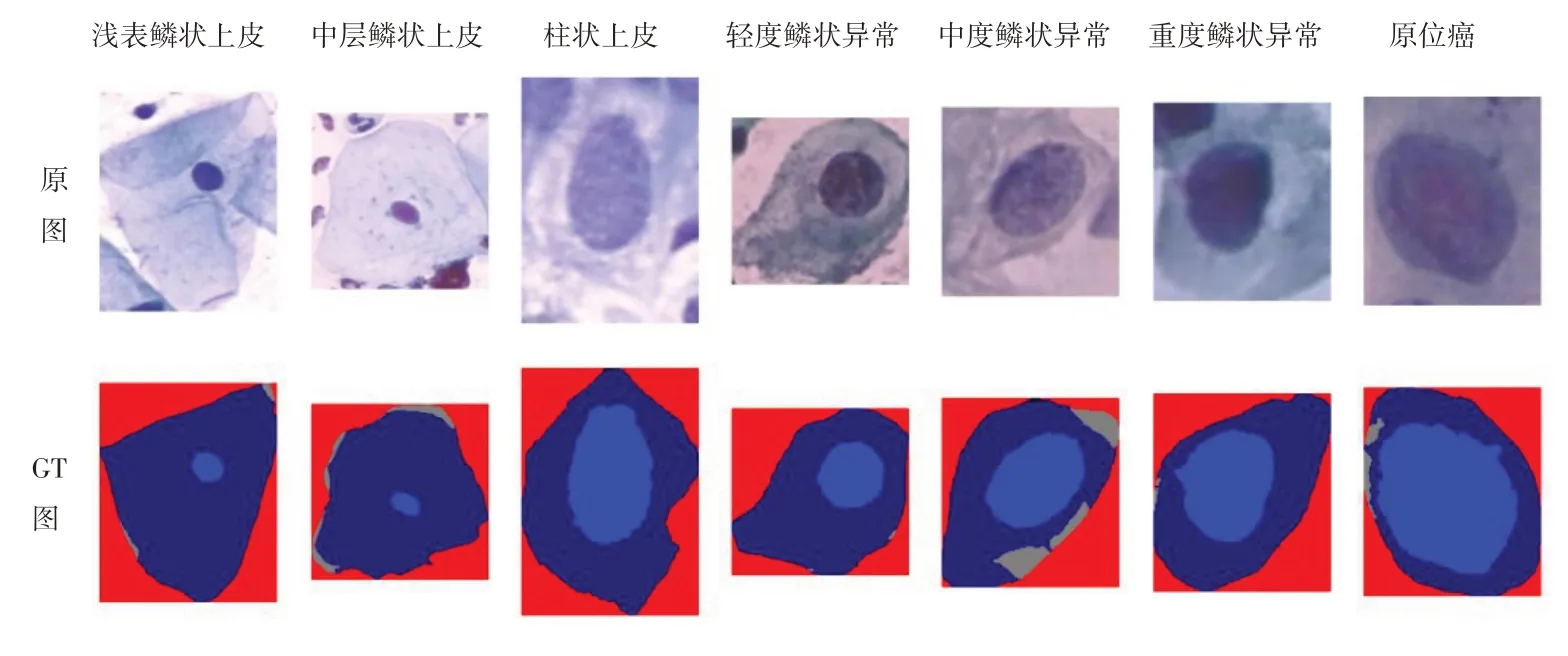
图4 Herlev数据集部分图像
由于数据集每张图像大小形状不一,为了在统一输入尺寸的同时不改变分割区域的相对位置,在输入模型前对图像进行零填充,并将分辨率大小统一调整为224 × 224 像素。同时,本文采用基于像素的语义分割,GT 图中的细胞主体都在其ROI内,无需先确定细胞的ROI,所以将ROI 并入背景中,最终的语义图像共有三类像素,分别为细胞核、细胞质与背景区域,图5为数据处理前后对比。
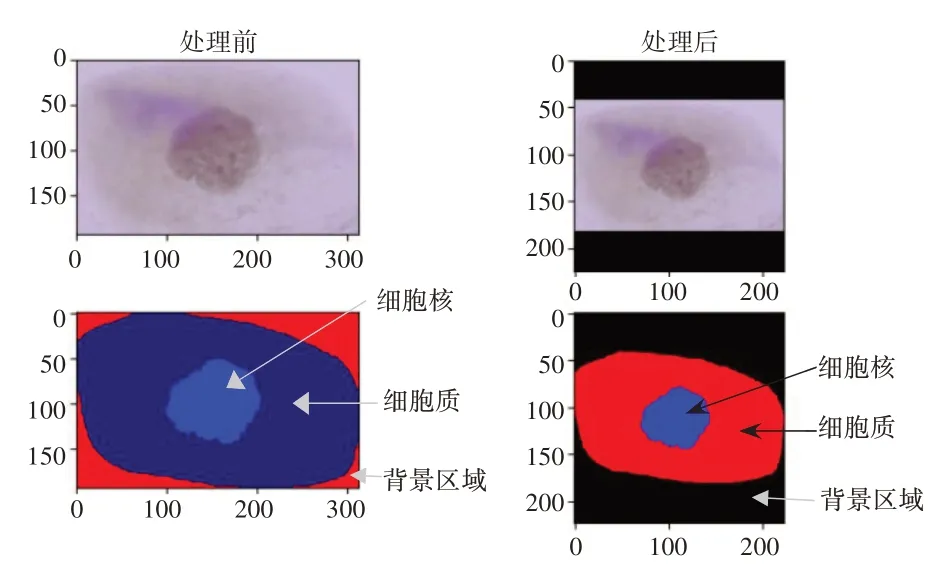
图5 图像处理前后对比
为了便于训练,将像素进行编码,表2为本文训练所使用的像素类别索引。
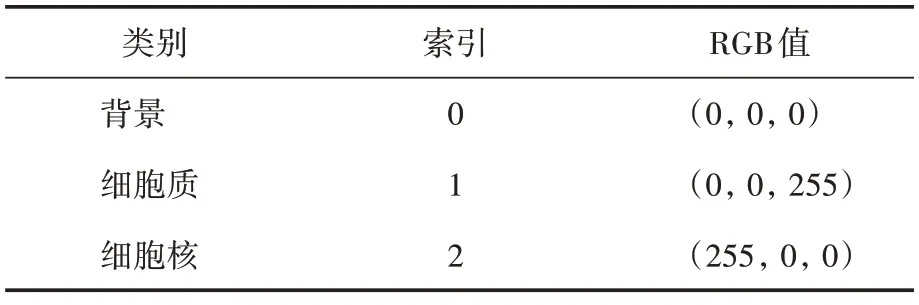
表2 像素类别索引
深层网络的训练通常需要大量数据进行学习,否则容易产生过拟合,但医学图像数据难以获取,本文使用的公开数据集仅有917 张图像,因此本文对现有数据集进行旋转、水平或垂直翻转等仿射变换,将数据量扩充至原来的六倍,使得模型具有更好的泛化能力。
3.2 评价指标
为了对语义分割结果进行评估,本文采用平均像素精度(mean pixel accuracy,MPA)与平均交并比(mean intersection over union,MIoU)作为评价指标,公式如下:
其中,假设共有k+1 个类别(0,1,…,k),pii表示类别为i的像素预测正确的数目,pij表示类别为i的像素被预测为j的数目,pji代表类别为j的像素被预测为i的数目。平均像素精度为每个类别中分类正确的像素总数与每个类别的像素总数之比的均值,平均交并比为每个类别真实标签与预测结果之间交集与并集像素数量比值的均值,上述指标在用于评价分割模型性能时,值越大代表性能越好。
3.3 实验结果分析
本文仿真实验平台为Windows 10,处理器为Intel i3‑8100 CPU,12 GB 内 存,显 卡 为NVIDIA GeForce RTX 2070,8 GB 显存,在机器学习平台Tensorflow 1.13.1 上进行网络训练,优化方法采用的是Adam 优化器(adaptive moment estimate optimizer),迭代次数为100 次,批量大小为4,初始学习率为0.001,数据集按照3∶1划分为训练集和测试集,使用扩充后的数据集进行训练,输入训练图像为4126张。
图6 对比了FCN、U‑Net 以及本文模型的损失值情况,其中FCN 模型稳定性差,U‑Net模型收敛后的Loss 值比本文模型更大,本文模型收敛速度更快、更稳定,其精确度有一定的提升。
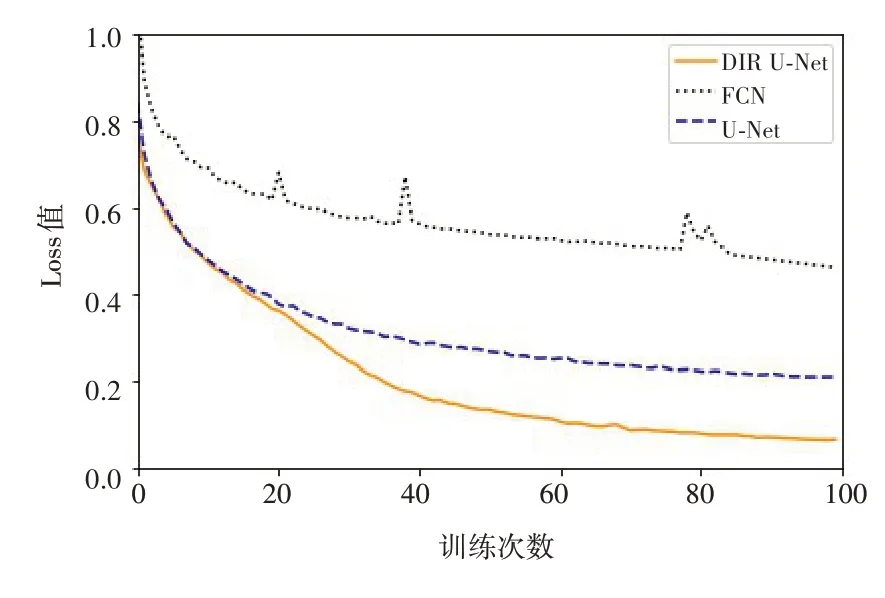
图6 三种模型训练过程中的Loss值对比
本文选择了FCN[9]、U‑Net[10]、Attention U‑Net[17]、U‑Net++[18]这几种分割网络与本文的改进模型进行对比,探究改进模型的优越性。表3展示了各个模型使用不同激活函数时,在测试集中的精度指标与完成整个测试集所用的时间。本组实验使用的是改进的Focal‑Dice 损失函数。从表3 结果可以看出,本文改进的模型相比于FCN 和U‑Net,精确度分别提高了34.2%和13.7%,这是因为FCN 与U‑Net 的特征提取与特征融合能力不足,无法有效利用编码器提取到的特征。相比于另外两种流行的U‑Net改进网络也提升了3.1%和0.6%。本文模型在测试时间上,虽相较FCN 与U‑Net 模型多出了21.2%和12.7%,但其精确度却提高了34.1%和13.6%,具有更好的性能。
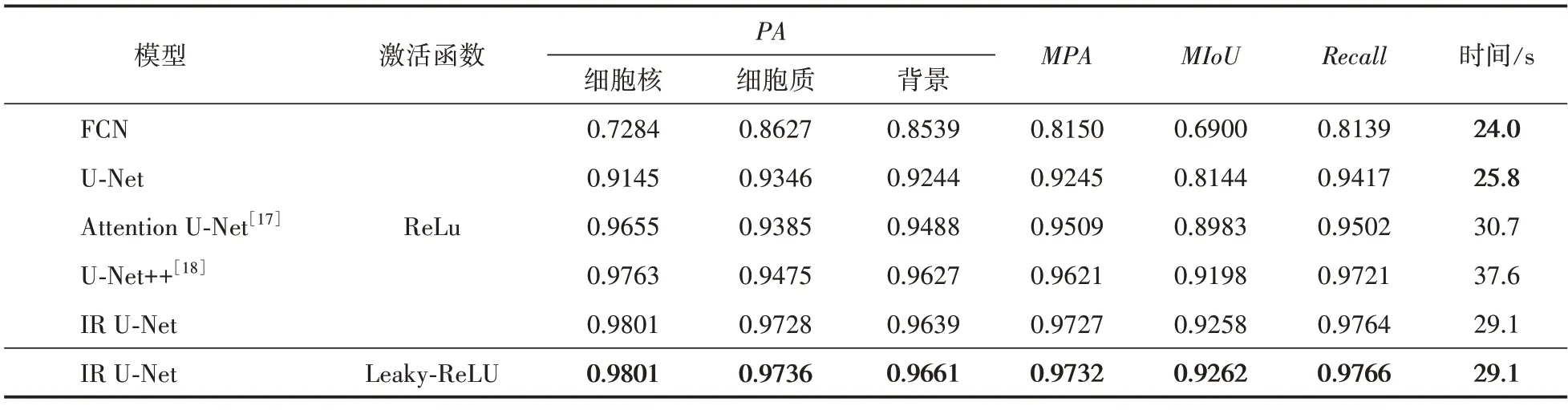
表3 多种模型分割指标对比
另外,细胞核的特征中往往包含着更多可用信息[1],能将细胞核准确地分割出来具有一定的意义。本文在细胞核的分割上与近年来一些相关研究进行横向比较(见表4),发现本文在细胞核这一类像素的分割上也提升了0.1%~1.5%。
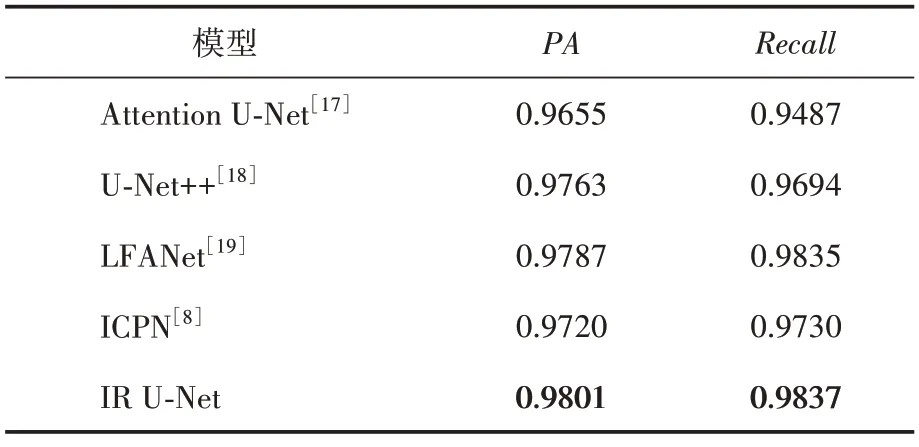
表4 多种模型的细胞核分割指标对比
本文改进的损失函数中,权重因子的变化也会导致分割结果的变化,通过设置不同的权重因子来探究其对分割结果的影响。首先是类别权重,图7展示了数据集中各个类别像素个数的均值,细胞核、细胞质、背景的比值接近于1∶2∶3,所以本文将类别权重设置为w0∶w1∶w2=1∶2∶3。
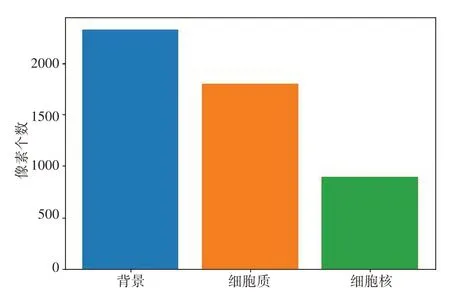
图7 数据集每个类别像素的平均数量
表5 展示了不同w与β值下本文模型的指标。从结果来看,将w比值设置为1∶2∶3 时,相比于均衡的权值,仅在β取0.25时精确度有所下降,β取0.5 与0.75 时,精确度分别提升了0.1%和0.6%。当β取0.5 时模型效果稍好,相比于另外两个取值所对应的精确度提升了0.1%和0.4%,所以本文将默认设置β为0.5。
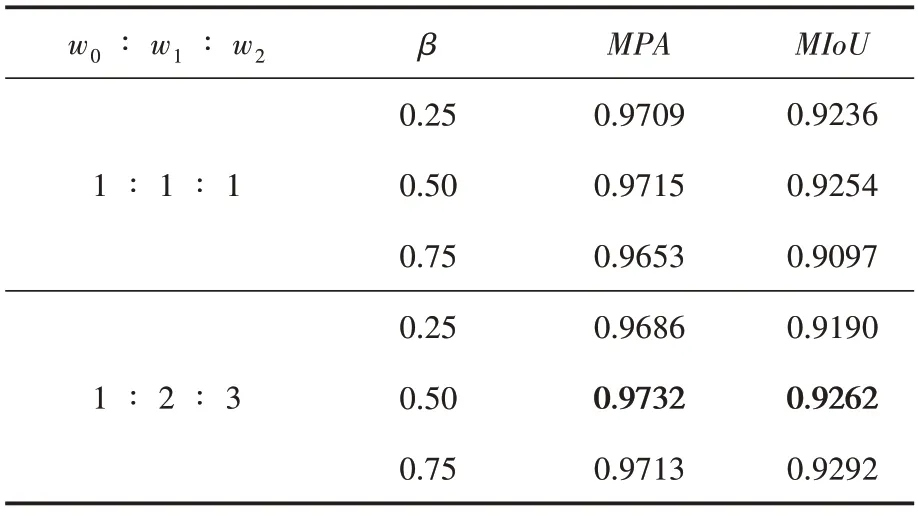
表5 不同w和β值对模型的影响
为探究不同损失函数对模型性能的影响,本文在不同模型分别使用交叉熵损失、Dice 损失、Focal 损失以及本文改进的损失函数之间进行对比试验。表6 展示了各个模型在不同损失函数下的分割效果,结果表明改进的Focal‑Dice 损失函数相比交叉熵损失精确率提升了0.5%~3.5%,相比Dice 损失精确率提升了0.2%~5.6%,相比Focal 损失精确率提升了0.4%~1.4%。由于本文数据集的类别不平衡,单一损失函数很难衡量训练时类别的重要性,当训练细胞核这类数量较少的类别时,很容易被其他类别所影响,改进的损失函数针对这一点进行优化,使模型能够更好地关注于类别少且难分类的像素点。
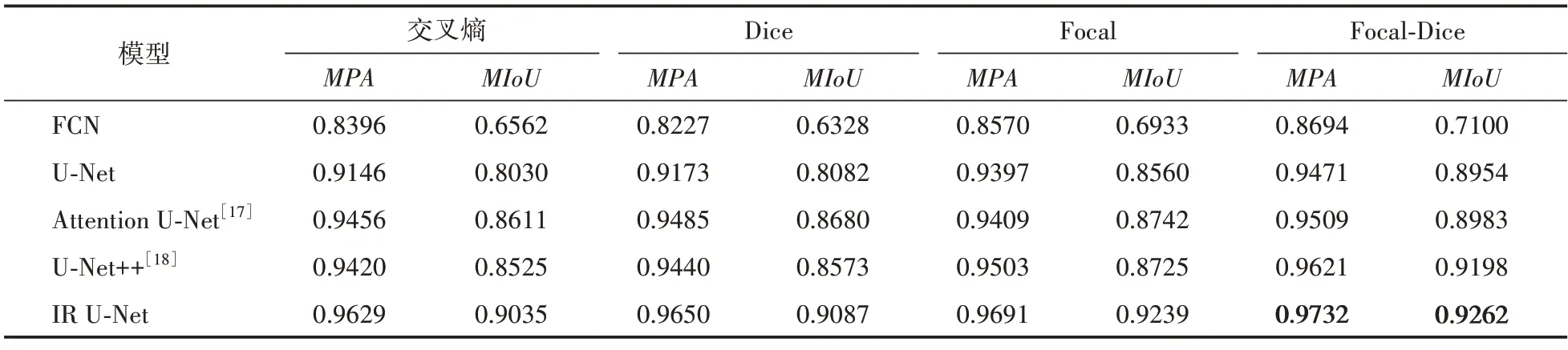
表6 不同损失函数对多种模型的影响
3.4 消融实验分析
为了验证本文改进方法的可行性,将三个改进模块进行单独实验,探究每个模块各自对模型性能的影响,在相同数据集上进行相应的消融实验。
表7 中第一行实验数据为原U‑Net 模型下的分割精度,其效果达不到期望。第二行实验数据表明,在加入Inception‑Res 模块后,各项指标分别提升了3.8%、11.6%和1.0%,结果优于原模型,这表明该模块对模型性能提升有所帮助。第三、四行实验数据中,分别再加上Leaky‑ReLU 与Focal‑Dice模块,两者使得模型的MPA分别提升了1.8%和2.3%,MIoU分别提升了1.3%和3.2%,由此证明了这两个模块对模型性能提升的有效性。
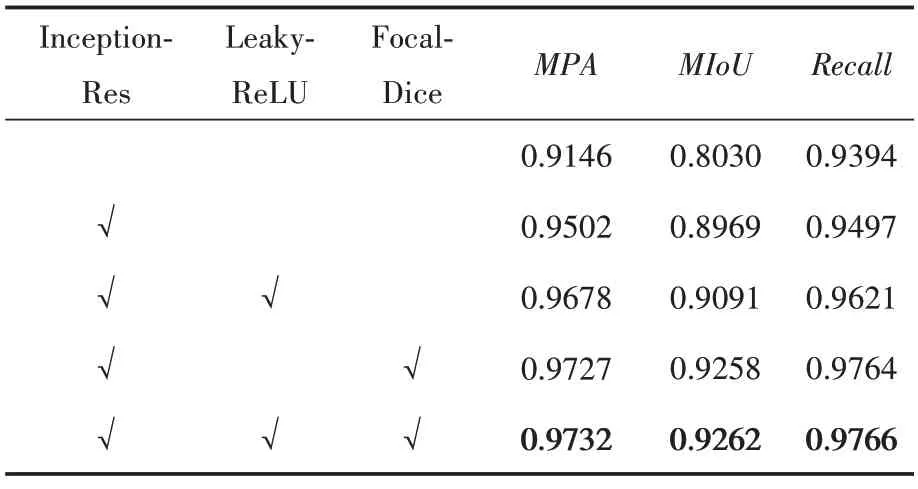
表7 不同模块对网络性能的影响
3.5 结果可视化
本文使用的所有网络分割结果的可视化如图8所示,结果表明,FCN模型由于特征提取与像素还原能力低,细胞边缘细节刻画效果不佳,细胞核尚未完全分割出来,整体效果非常粗糙,U‑Net 模型存在同样问题,虽然在细胞核分割上优于FCN,但其边缘细节仍然未划分出来,受背景影响严重。Attention U‑Net 与U‑Net++模型在细胞核刻画上效果与本文模型相差不大,但细胞质边缘区域分割效果仍然不佳。相比之下,本文的改进模型能够有效地分割出细胞核质区域,对细胞主体的刻画优于其他几种模型,具有较好的效果,分割能力明显提升,且在样本不均衡,即细胞区域较小时也能达到较好的分割效果。

图8 各模型分割可视化结果
4 结语
目前宫颈细胞分割领域存在一定的问题,本文在U‑Net结构的基础上,结合了多尺度卷积与残差连接的Inception 结构,加宽网络的同时避免了梯度消失,并使用改进的损失函数获得了较好的分割效果。结果表明改进的模型相比于目前常用模型均有精度提升,改进的损失函数相比原始损失函数在对模型精度提升方面更为优越,模型整体的分割结果与专业人员标记接近,具有一定的现实意义。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
电子制作(2019年11期)2019-07-04
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
新校长(2016年8期)2016-01-10
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
商事法论集(2014年1期)2014-06-27
电视技术(2014年19期)2014-03-11
