
一种改进DeepLabV3+的岩屑图像语义分割算法
2023-03-30 08:52罗崇兴师明元王正勇滕奇志
现代计算机 2023年2期
罗崇兴,师明元,王正勇*,滕奇志
(1.四川大学电子信息学院,成都 610065;2.河北省地质矿产勘查开发局第六地质大队,石家庄 050080)
0 引言
在矿产资源勘探和开发工作中,岩屑录井是非常重要的一步工作,对岩屑进行准确识别是地质勘探人员研究地层特征和地质建模的重要基础和保障。在岩屑采集现场,多种因素的影响,使得采集过程中获取到的岩屑并不只是一种岩性,而是混合着多种岩性。为更好地分析岩屑岩性,需要对岩屑图像进行语义分割。随着科学技术的发展,深度学习开始广泛应用于岩屑图像语义分割,深度学习的引入加快了岩屑图像处理速度,提高了岩屑识别的准确率。
自2012 年,AlexNet 模型[1]在ImageNet 比赛上大放光彩,在那之后,深度学习网络模型层出不穷。2014年,Simonyan 等[2]提出VGG 网络,采用连续的小尺寸卷积核代替了较大卷积核,却存在需要计算更多的参数,对内存和时间要求高的问题。之后,Long 等[3]在VGG‑16 网络原有结构基础上提出全卷积网络(fully convolu‑tional networks,FCN),采用卷积层代替了传统卷积中的全连接层,使图像能进行像素级别的语义分割,但是还存在分割结果粗糙等问题。Chen 等[4]针对语义分割中存在的池化导致信息丢失,标签之间的概率关系未利用的问题,基于FCN 网络提出了DeepLab V1 网络,在该网络中引入了全连接条件随机场(conditional random field,CRF),以改善原始分割结果不精细的问题,同时利用空洞卷积使网络在不改变参数量和计算量的情况下扩大网络感受野,获取图像更多的信息。在那之后,DeepLab 系列不断发展,衍生出DeepLab V2[5],DeepLab V3[6]等网络模型。2015 年,Ronneberger 等[7]基于对称的编码器-解码器结构提出了U‑Net 网络,以方便融合分辨率相同的特征。2015 年,剑桥大学团队借鉴FCN 网络和U‑Net 网络,提出SegNet 模型[8],该模型的编码结构构建了最大池化层索引存储,以内存为代价换取轻微的精度损失,解决边界信息丢失问题。2017 年,香港大学和商汤科技联合提出PSPNet 网络[9],提出了金字塔池化模型,融合不同尺度和不同区域之间的信息,通过全局先验信息有效获取高质量的语义分类结果。Lu 等[10]首次将图卷积模型应用于分类,通过卷积特征图构建图结构,并将其转化为图节点分类问题,解决了卷积神经网络在提取特征的过程中局部位置信息损失的问题。北京大学联合商汤科技基于类的动态图卷积自适应提出CDGCNet模型[11],利用构造图的动态图卷积结果学习特征聚集和权重分配,融合原始特征和精炼特征获取最终预测。He等[12]提出了一种基于协作学习的多源领域框架,将多标记源模型适应到无标记源中,并用于语义分类。
在岩屑分割领域,2020年,万川等[13]对U‑Net模型进行了改进,并应用于岩屑图像分割中,运用金字塔池化模块聚合不同区域的上下文特征信息,更好地利用了全局信息。2022年,严良平等[14]在VGG16的基础上提出了一种深度图像引导的岩石颗粒分割算法,利用深度图像的三维距离信息,提高了岩石图像的分割精度。
为更好地对岩屑图像进行语义分割,本文在DeepLabV3+算法上进行改进,并提出了一种改进DeepLabV3+的岩屑图像语义分割算法。
1 相关算法原理
DeepLabV3+算法采用编码器-解码器结构。编码器主要用于岩屑图像特征提取,解码器是将编码器提取的特征映射到高维空间,以实现图像像素级别的语义分类,通过反卷积操作不断恢复图像的空间维度,从而实现图像语义分割。
DeepLabV3+的网络结构如图1(a)所示,其编码器部分由Xception[15]和ASPP 模块[5]组成,Xception是利用若干个大小不同的卷积提取输入特征,在减小计算量的同时获取不同感受野,经过Xception 模型,图像分辨率降低为原始图像的1/16,之后再送入ASPP 模块。ASPP 模块如图1(b)所示,由不同采样率的空洞卷积并联组成,将结果融合在一起之后,利用1 × 1 的卷积降低输出的通道数,以实现用多个比例捕捉图像上下文信息的目的。DeepLabV3+网络的解码部分,首先是将输出的特征图进行上采样操作,将特征图尺寸扩大四倍,之后将该特征图和低级特征进行拼接融合,最后再进行上采样,实现图像语义分割,得到最终预测结果。

图1 DeepLabV3+网络结构及ASPP模块图
2 改进的DeepLabV3+
2.1 MobileNetV3
原始的DeepLabV3+模型使用Xception 特征提取网络作为主干网络,但Xception 对模型的参数规模和运算速度控制不佳,使得在进行岩屑图像语义分割的过程中存在参数量大、推理速度慢的问题,所以本文采用MobileNetV3[5]代替原网络中的Xception 模块来提取岩屑图像特征,在不降低模型精度的同时提高模型的速度。该模型借鉴了MobileNetV1[16]的深度可分离卷积、MobileNetV2[17]的具有线性瓶颈的逆残差结构,并且引入了Squeeze and excitation[18]的轻量级注意力结构,采用了一种新的非线性激活函数h‑swish,计算公式如下:
该函数能减少运算量并提高模型性能。
MobileNetV3 网络模型的基本模块bneck 结构如图2 所示,首先利用1 × 1 的卷积进行升维操作,之后经过5 × 5 的深度可分离卷积提取图像特征,然后利用注意力机制调整每个通道的权重,最后再通过1 × 1的卷积降维。
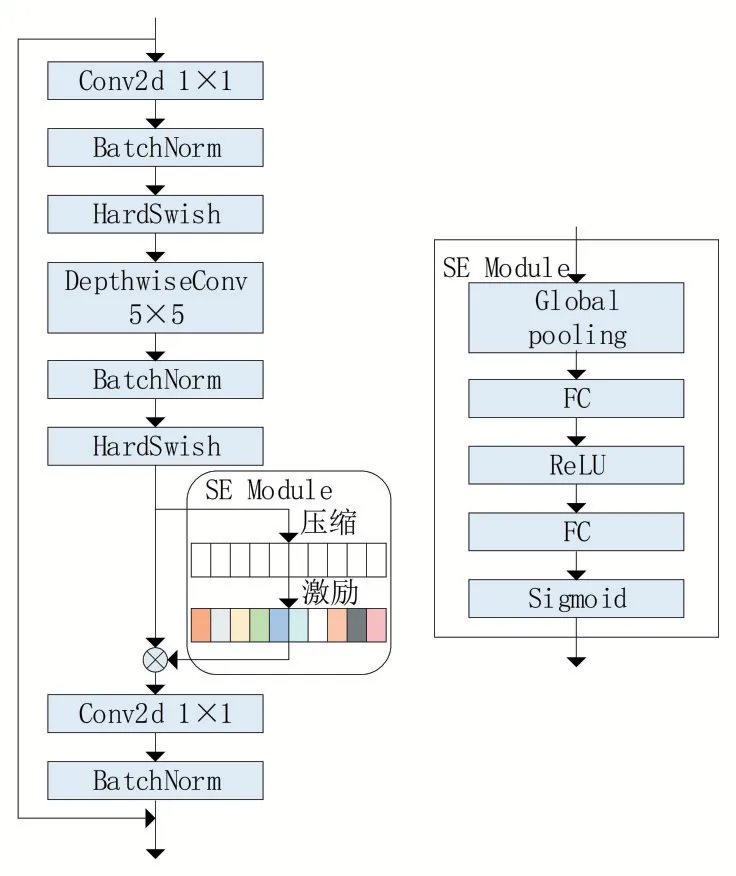
图2 bneck结构
2.2 注意力机制EPSANet
在神经网络中,模型学习能力越强,需要存储的信息也就越大,这会引起信息超载。为了更好地引导模型聚焦于岩屑图像中的重要信息,本文在ASPP 模块引入了注意力机制EPSANet[19]。如图3所示,EPSANet能够有效捕获不同尺度特征图的空间信息,同时丰富特征空间,建立长期依赖关系,进而学习更丰富的特征表示。
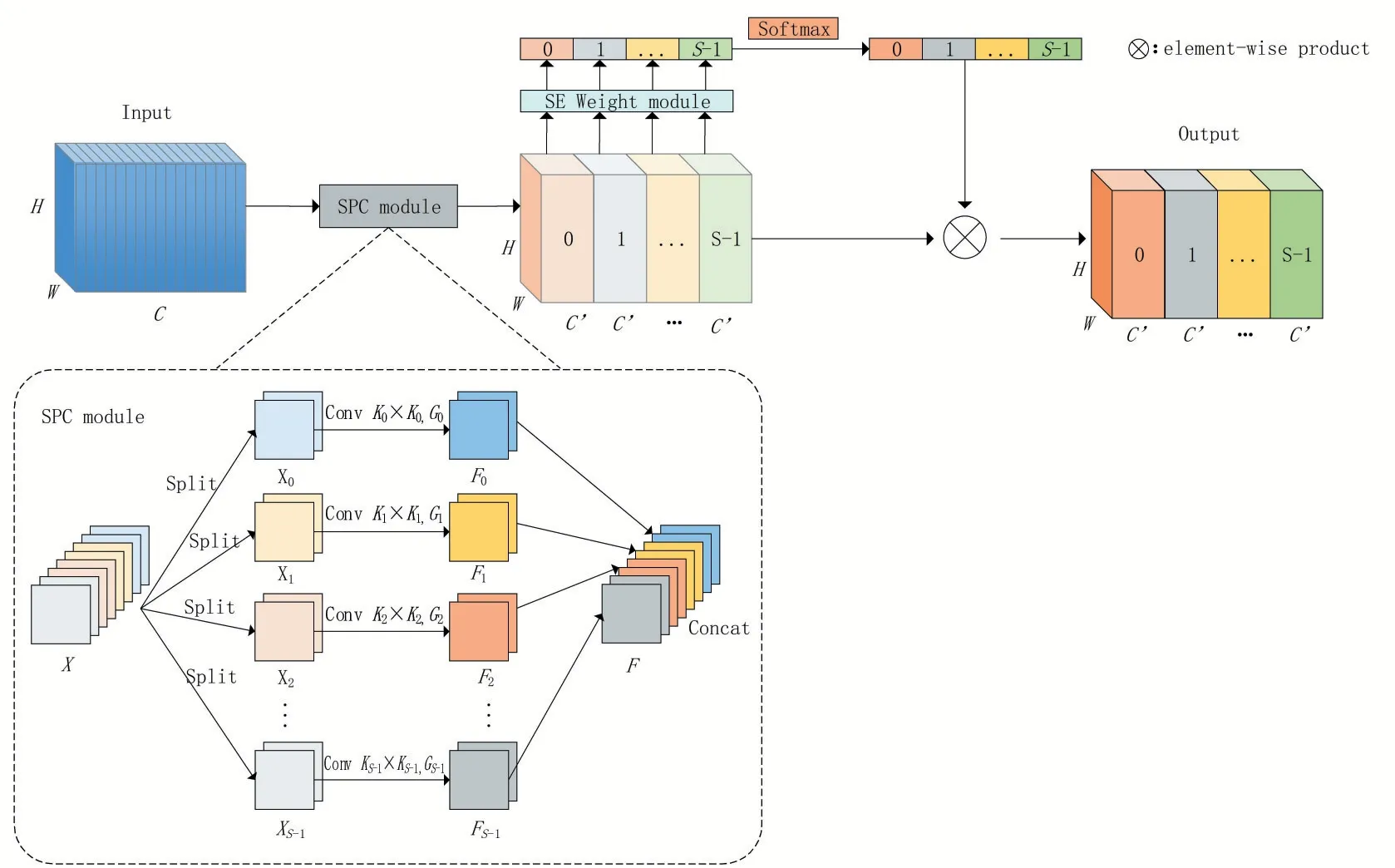
图3 EPSANet
EPSANet 首先将输入特征图X拆分为S个部分(X0,X1,…,XS-1),然后利用多尺度卷积核分组卷积提取不同尺度特征图的空间信息,计算公式如下:
然后将这些特征图拼接起来,计算公式如下:
最后对这些拥有不同尺度信息的特征图进行通道注意力权重加权,计算公式如下:
为更好地交互多尺度通道信息,利用Softmax进一步标定权重信息,计算公式如下:
这本书内容很丰富,有人体之谜、宇宙之谜、地理之谜、天文之谜、生物之谜、科技之谜、动物之谜、历史之谜等,让我知道了很多我想知道的问题。
最后将对应的权重和特征图进行通道级别的相乘,计算公式如下:
在ASPP模块中引入EPSANet得到EPSANet‑ASPP 模块,如图4 所示,能够引导模型在融合特征时更好地聚焦于岩屑图像中的重要信息,降低对无关信息的关注。

图4 EPSANet⁃ASPP模块
2.3 改进后的网络模型
改进DeepLabV3+的岩屑图像语义分割算法的网络结构如图5(a)所示,该模型的编码器部分 由MobileNetV3 和EPSANet‑ASPP 模 块 组 成,首先经过MobileNetV3 提取岩屑图像特征,在不降低模型精度的同时提高模型的速度,以得到不同尺度的图像特征;然后将最小尺寸的图像特征送入EPSANet‑ASPP模块,EPSANet‑ASPP模块如图5(b)所示,引入EPSANet机制的EPSANet‑ASPP 模块能够帮助网络更好地提取出特征中的重要信息,从而更高效地捕获岩屑图像中不同尺度信息。

图5 改进后的DeepLabV3+模型及ERSANet⁃ASPP模块图
由于在特征提取的过程中,低层次的特征包含较多的细节信息,更容易反映图像特征,同时目标位置更加准确,但是缺乏语义特征信息。高层次特征具有更多的语义信息,却只有较少的细节信息和位置信息。有效融合低级特征和高级特征能更有助于岩屑图像语义分割,因此,在解码器部分,本文借鉴FPN[20]的多尺度特征融合思想,在编码器和解码器之间构建横向连接,使模型在对特征图进行上采样时能够融合编码器中MobileNetV3 提取的不同尺度特征,进而获取更多的图像细节信息和更准确的目标位置信息,得到更精细的岩屑图像语义分割结果,实现岩屑图像语义分割。
3 实验结果及分析
为更好地评估本文算法性能,本文介绍了几种常用的语义分割评价指标,在相同的实验配置条件下,对比分析了7种不同的语义分割网络在岩屑图像语义分割数据集上的表现,分别为Danet[21]、FCN[3]、DeepLabV3+[22]、PSPNet[9]、UNet[7]、UPerNet[23]、HRNet[24]。实验证明,本文算法具有更高的语义分割精度,优于其他对比网络。
3.1 实验环境
本实验在Linux 操作系统下进行,实验使用显卡型号为NVIDIA GeForce RTX 2080 Ti,处理器为Inter(R)Core(TM)i7‑9700 CPU,使用的编程语言是Python3.8.0,深度学习框架为PyTorch1.8.0,CUDA Version为11.1,内存为32 GB。
3.2 实验数据集
为验证本文算法的有效性,首先利用岩屑图像采集设备采集岩屑图像,得到尺寸为4000×3750的原始岩屑图像,部分原始岩屑图像如图6所示,共采集岩屑图像126张,然后通过图像裁剪、数据增强等方法将原始岩屑图像制作成512×512 的岩屑图像语义分割数据集共9682 张,其中7746 张用于训练模型,1936 张用于测试模型。实验数据集共有20个类别,其中包含背景和19种岩屑样本,岩屑种类分别是油斑粉砂岩、紫红色安山岩、深灰色安山岩、灰绿色安山岩、褐色流纹岩、灰绿色砂岩、含砾粗砂岩、紫灰色泥质粉砂岩、灰色粉砂岩、褐色粉砂岩、灰绿色凝灰岩、方解石、石灰岩、页岩、石英、灰泥岩、灰黑色泥岩、深灰黑色泥岩、棕红泥岩,部分岩屑样本展示如图7所示。

图6 原始岩屑图像

图7 部分岩屑样本展示
3.3 实验结果及分析
语义分割是对图像进行像素级别的分类,常用的评价指标有像素准确率(pixel accuracy,PA)、类别平均像素准确率(mean pixel accuracy,mPA)、交并比(intersection over union,IoU)和平均交并比(mean intersection over union,mIoU)。PA是指类别预测正确的像素数目占总像素的比例,计算公式如下:
mPA是每个类别的PA的求和再平均的值,计算公式如下:
IoU是类别预测结果和真实结果的交集与并集的比值,计算公式如下:
mIoU是每个类别IoU的和再平均的结果,计算公式如下:
其中,Cij代表在岩屑图像中预测分类为i类、真实分类为j类的总像素数,如当i=j,代表在岩屑图像中像素点的预测为i类,同时实际值也是i类,这类结果表示为真;当i!=j,代表在岩屑图像中像素点的预测是j类,但是实际分类值为i类,这类结果为假。
3.3.2 消融实验结果与分析
为验证改进的DeepLabV3+岩屑图像语义分割模型的有效性,分别对MoblieNetV3 模块,注意力机制EPSANet 模块和编解码联系模块进行消融实验。选取DeepLabV3+网络模型作为基线模型。在自制的岩屑数据集上性能对比结果如表1所示。
从表1 可以看出,原始的DeepLabV3+网络在自制岩屑数据集上的评价指标mPA为0.68,mIoU仅有0.57;用MoblieNetV3 替换Xception 进行特征提取后,mPA比基线模型提升了0.05,mIoU比基线模型提升了0.03,参数量减少了10.17 M,速度提升了1.75 s;在ASPP 中加入注意力机制EPSANet 后,mPA比基线模型提升了0.02,mIoU比基线模型提升了0.04;在改进了编解码联系模块后,mPA比基线模型提升了0.03,mIoU比基线模型提升了0.06。实验表明,本文所提出的几个改进方法在性能上相较于原始的DeepLabV3+网络均有不同程度的提高。

表1 消融实验的mPA、mIoU、参数量、单张图像处理时间对比
3.3.3 与其他模型的比较
表2是不同算法在自制的岩屑图像语义分割数据集下性能对比结果,其中加粗数字是横向比较最优结果。从表2可以看出本文算法在岩屑图像数据集上的mPA为0.78,mIoU为0.68,分割的整体性能优于其他对比网络,具有更高的分割精度。
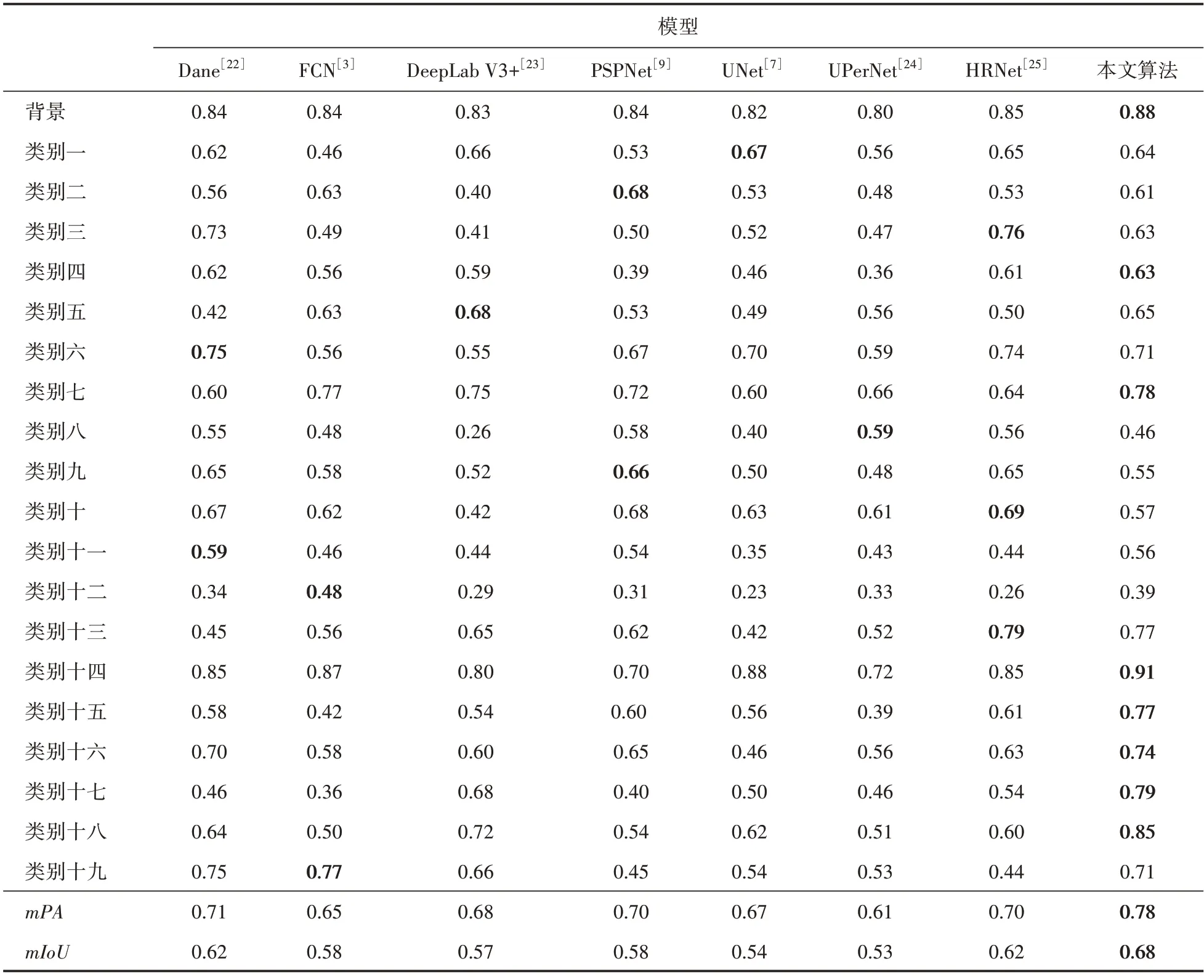
表2 不同算法的性能对比
为更直观地比较不同算法的性能表现,图8展示了不同算法在岩屑图像上语义分割结果。对比了7种不同的语义分割算法,图中左上方框中的岩屑是灰绿色砂岩,从图中可以看出Deep‑LabV3+、UNet、UperNet、HRNet 算法将其错误识别为灰绿色安山岩。右下方框中的岩屑是深灰色安山岩,Danet、FCN、DeepLabV3+、UNet、UperNet 算法未能很好地区分该岩屑和背景。从图8 可以看出,本文改进的DeepLabV3+算法语义分割结果优于对比算法。

图8 不同模型的语义分割对比图组1
图9展示了不同算法在密集岩屑图像上的语义分割结果,图中方框中的岩屑是灰绿色凝灰岩,Danet、DeepLabV3+、PSPNet、UNet、Uper‑Net、HRNet 算法将该岩屑的部分像素错误分类为灰绿色安山岩。从图中可以看出,本文算法性能优于其他对比算法。

图9 不同模型的语义分割对比图组2
4 结语
本文针对岩屑图像语义分割问题,利用岩屑采集设备采集岩屑图像制成数据集,并提出了基于DeepLabV3+算法的改进方法。本文算法首先采用MobileNetV3 作为主干网络,以快速提取岩屑图像不同尺度的特征,接着采用融合了EPSANet 的ASPP 网络,用于有效获取岩屑图像的重要信息并更好地融合图像特征,最后借鉴FPN 思想,在解码过程中融合编码提取的不同尺度特征,从而得到更精准的岩屑图像语义分割结果。实验表明,本文算法在自制的岩屑数据集上mPA为0.78,mIoU为0.68,分割的整体效果优于其他对比网络,岩屑颗粒的边缘分割也更加精确。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
工程设计学报(2020年5期)2020-11-25
工程技术与管理(2020年8期)2020-08-26
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
录井工程(2017年1期)2017-07-31
录井工程(2017年1期)2017-07-31
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
