
基于深度学习的对抗攻击技术综述*
2023-03-29 05:33蒋玲玲罗娟娟朱玉鹏周东青
航天电子对抗 2023年1期
蒋玲玲,罗娟娟,朱玉鹏,周东青
(1.北京邮电大学计算机学院,北京 100089; 2.军事科学院系统工程研究院,北京 100089)
0 引言
在大数据时代下,人工智能飞速发展,在计算机视觉[1]、自然语言处理[2]、语音[3]等领域都取得了很大的成就。2012年Krizhevsky 等人[1]提出AlexNet,并且在ImageNet[4]数据集上取得非常突出的表现,此后卷积神经网络(CNN)成为图像识别领域的标准结构。随着硬件设备的发展、对海量数据算力的提升,计算机视觉领域涌现了更多更好的深度神经网络(DNN),如VGG[5]、GoogleNet[6]、ResNet[7]等,然而一旦面对蓄意攻击,深度学习系统往往会崩溃。比如,在路标上张贴攻击者精心制作的贴纸即可误导自动驾驶系统将停止路标识别为限速路标[8],带上对抗眼镜框即可欺骗人脸识别系统[9]。这严重危胁了社会公共秩序和财产安全。深度学习模型给人类的生活带来巨大便利的同时,也带来了不容忽视的安全隐患问题。
为了构建安全可靠的深度学习系统,减少其在实际部署应用时潜在问题的出现,保证深度学习模型的安全性、鲁棒性、可靠性,许多学者研究深度学习模型的安全与隐私问题,并提出了一系列对抗攻击方法。本文对现有的对抗攻击方法进行归纳和总结,第1 节介绍对抗攻击的定义、分类标准和发展;第2、3 节分别介绍白盒和黑盒攻击方法;第4 节通过实验验证对比分析经典的攻击算法;最后总结并展望。
1 相关概念简介
1.1 对抗攻击的定义
对抗攻击是指在干净样本上添加精心设计的人眼不可见、或人眼可见的不影响整体的扰动以欺骗人工智能技术(AI),使得原样本不能被正确分类的过程。对抗样本是指以很高置信度使AI 误分类,然而人类依旧能够正确分类的样本[10]。
1.2 对抗攻击的分类
攻击者会根据不同的攻击场景提出不同的攻击方法,通过归纳、总结现有的攻击方法,对抗攻击可以按照攻击环境、有无目标、迭代次数、扰动来源等标准分类,分类情况如表1 所示。

表1 对抗攻击的分类
1.3 对抗攻击的发展
自2014年Goodfellow 提出:一种快速产生对抗样本方法——FGSM 后,对抗样本生成算法不断涌现,白盒攻击和黑盒攻击的发展历程如图1—2 所示。在黑盒场景下,攻击者因其对模型了解的信息比白盒场景少,攻击难度更大,初始阶段发展缓慢,但黑盒攻击方法更贴近现实、挑战难度更大,后续研究较多。
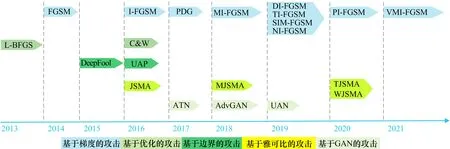
图1 白盒攻击的发展
2 白盒攻击
白盒攻击可以分为基于梯度的攻击、基于优化的攻击、基于决策边界的攻击、基于生成式模型的攻击、基于雅可比显著图的攻击。常见的白盒攻击方法的对比如表2 所示。下文具体分析经典的白盒攻击方法。

表2 白盒攻击方法对比
2.1 基于梯度的攻击
Goodfellow 等人[11]提出FGSM 攻击方法,该方法使得目标模型的损失函数增大,即模型预测中真实标签对应的概率减小,因此沿着梯度生成方向攻击最合适。基于梯度的攻击以FGSM 为基础,演变出其他攻击方法,FGSM 及其变体之间的关系如图3 所示。图中,I-FGSM[13]引入步长,提出迭代的攻击方法;MIFGSM[15]在梯度下降的过程中引入动量;PI-FGSM[18]使用放大因子来计算每步的步长,一方面可以避免在迭代过程中陷入目标模型的局部最优点,另一方面也为块级别扰动的产生提供了基础;NI-FGSM[27]在IFGSM 基础上使用Nesterov 加速梯度;VMI-FGSM[28]在I-FGSM 基础上进一步考虑上一次迭代的梯度方差来调整当前梯度,以稳定梯度更新方向,避免陷入局部最优;DI2-FGSM[16]受到数据增强的启发,对输入的图片以固定的概率应用随机翻转、缩放;TI-FGSM[17]利用卷积神经网络平移不变性的思想。
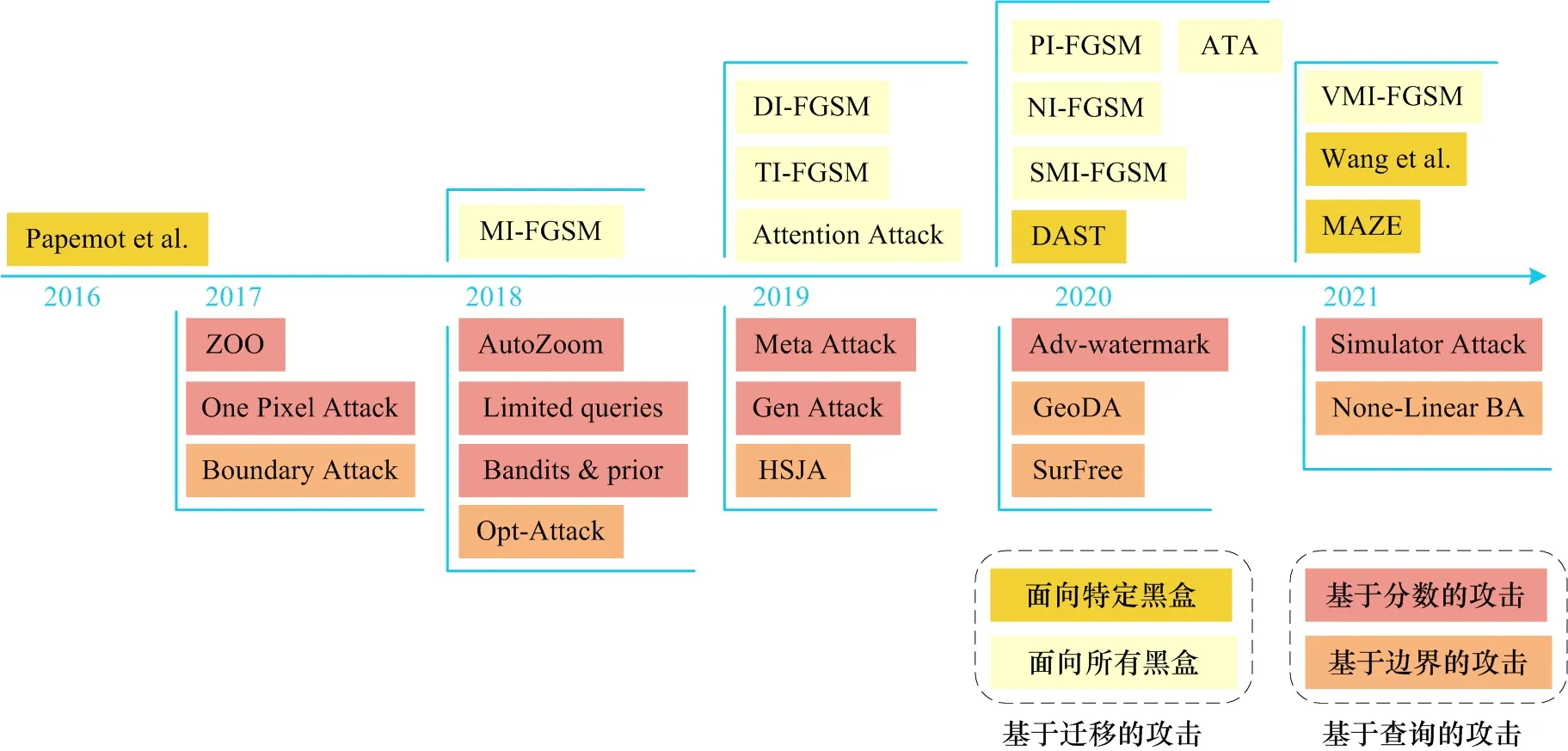
图2 黑盒攻击的发展
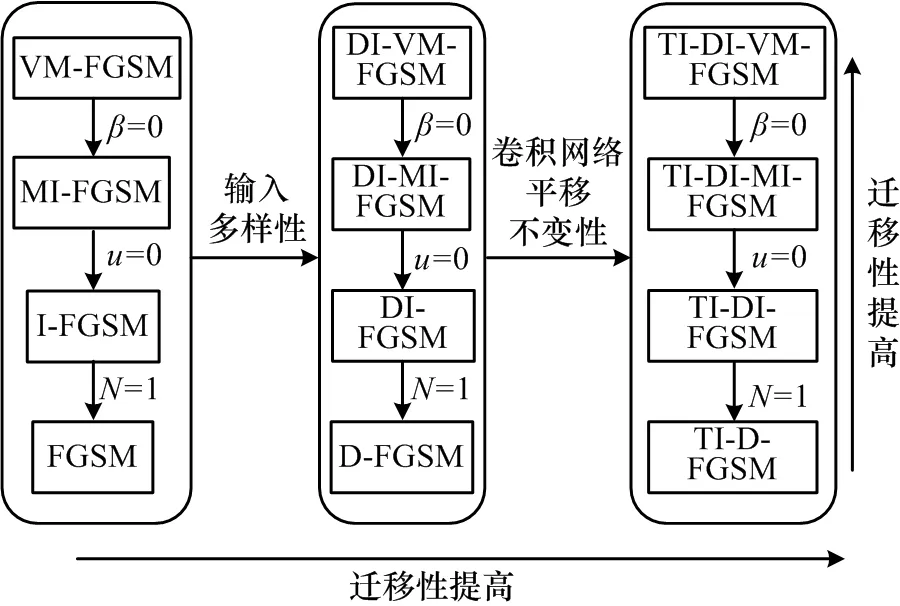
图3 FGSM 及其变体之间的关系
2.2 基于优化的攻击
寻找对抗样本是一个逐步优化的过程。一方面要确保添加的对抗扰动足够小,人眼无法察觉;另一方面,要确保模型要能够误分类对抗样本。因此,基于优化的攻击方法目标函数如下:
式中,DNN 定义为f( · ),输入干净图片x,对应DNN的预测结果为f(x),δ为添加的全局扰动,ytar为目标标签。常见的基于优化的攻击方法有2 种:
1) L-BFGS
Szegedy 等人[12]提出的L-BFGS 攻击方法是对抗样本领域的开山之作。在公式(1)中满足条件的δ值不唯一,用D(x,ytar)来表示一个最小的δ。因为找到扰动D是十分困难的,所以可转换为求解以下问题得到对抗样本。
式中,L 为损失函数。通过线性搜索找到满足c>0 的参数c,转化为求解盒约束的L-BFGS 从而找到D(x,ytar)的近似值,后续基于优化的攻击都是基于公式(2)改进的,但是对抗样本的质量依赖于参数c的选择,寻找满足条件的c需要消耗大量时间。
2) C&W
Carlini 和Wagner 等人[20]提 出基于最 优化目 标的攻击方法C&W 与L-BFGS 相似,优化目标为公式(2)。C&W 中对抗扰动定义如下:
则x+δ=(tanh (θ)+1)/2 ∈[0,1],可以确保对抗样本始终在图片有效范围内。对于目标攻击而言,目标类别为ytar,损失函数L(xadv)可以定义为:
式中,Z(x)是神经网络未经过Softmax 层之前的值。
C&W 与L-BFGS、FGSM 等攻击方法相比攻击效果、视觉效果更好,同时能以很高置信度攻击防御性的蒸馏模型。但是C&W 是基于优化的攻击,大量的时间消耗在常数c的搜索上,攻击效率低。
2.3 基于边界的攻击
基于决策边界的攻击方法是基于分类模型中高维超平面分类的思想,即为了改变某个样本x的分类,可以将x迭代式地朝着模型决策边界移动,直到越过模型决策边界,从而被模型误分类。基于决策边界的攻击方法有2 种:
1) DeepFool
基于解析几何原理,Moosavi-Dezfooli 等人[21]提出了DeepFool 攻击方法。在多分类问题中,分类边界和样本的距离即为改变样本分类标签的最小扰动;在二分类问题中,计算对抗扰动相当于计算样本到分类边界的距离。DeepFool 在每次迭代中修改扰动将原始样本推向决策边界直到跨越边界。DeepFool 使用的距离衡量标准是L2范数,在相同攻击成功率下,与FGSM 相比,图像需要改变的扰动量更小。
2) UAP
Moosavi-Dezfooli 等人[22]在DeepFool 基础上进一步改进提出通用对抗扰动计算方法UAP,与Deep-Fool 方法相比,该方法生成的扰动迁移能力强,不仅是针对一张图片有效,而是针对某个数据集有效。通用对抗扰动的存在揭示了DNN 在高维决策边界之间的几何相似性。
2.4 基于生成式模型的攻击
Xiao 等人[23]提出基于生成对抗网络(GAN)的攻击框架AdvGAN,如图4 所示,该框架包括生成器G、鉴别器D和目标模型f。G的输入是原始样本x,输出为对抗扰动G(x)。将对抗样本x+G(x)送到D中判断是否真实。作者使用对抗损失使对抗样本更接近原始样本和训练生成式模型,此外还引入使对抗样本被误识别为目标类别的攻击损失和限制扰动大小合页损失训练GAN。
2.5 小结
白盒攻击方法的优缺点总结如表2 所示。

表2 白盒攻击方法优缺点总结
3 黑盒攻击
黑盒攻击可以分为基于迁移的攻击和基于查询的攻击,详细分类如图5 所示。基于迁移的攻击训练替代模型代替目标黑盒,在替代模型上使用白盒攻击方法生成对抗样本,利用对抗样本的迁移性攻击目标模型。基于迁移的攻击无需目标模型的反馈,但需要数据集训练替代模型。基于查询的攻击通过输入样本到目标模型得到反馈信息(如硬标签或者分数),然后利用目标模型的反馈信息进行攻击。

图5 黑盒攻击分类
3.1 基于迁移的攻击
在黑盒环境下,模型内部参数不可知,因此无法获取目标模型的梯度,无法利用基于梯度的方法来生成对抗样本。Goodfellow 等人[11]研究表明,对抗样本具有迁移性,即白盒上生成的对抗样本在未知结构的黑盒模型上也可以攻击成功。
基于迁移的攻击具体流程可分为3 个步骤:攻击者获取训练数据集;攻击者设计替代模型的结构,使用训练集训练替代模型; 攻击者在替代模型上使用白盒攻击方法攻击黑盒模型。
基于迁移的攻击方法可分为2 类:
一是面向所有黑盒。通过提高对抗样本的迁移性,使得对抗样本在任意黑盒上的攻击成功率提高。
二是面向特定黑盒。训练替代模型尽可能复制目标黑盒的功能或者决策边界,在替代模型上使用白盒攻击方法生成对抗样本。
3.1.1 面向所有黑盒
面向所有黑盒提高对抗样本迁移性的方法有基于梯度、基于注意力的黑盒攻击方法等。
1) 基于梯度的黑盒攻击
许多研究者不断改进基于梯度的攻击方法,主要通过优化梯度计算和输入变换提高对抗样本的迁移性,在2.1 小节中已经做具体介绍。
2) 基于注意力的黑盒攻击
Selvaraju 等 人[29]提出梯度加权类激活映射图(Grad-CAM)将模型感兴趣的区域以热力图的方式可视化。图6 为用于猫预测的三种代表性的模型的热力图。红色区域在模型做出决策的时候贡献较大。基于注意力的攻击方法的基本思想是转移模型的关注区域,当模型的注意力不再关注重要区域的时候,模型误判。
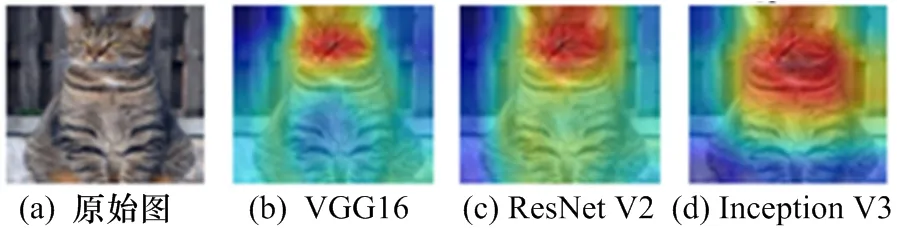
图6 用于猫预测的3 种代表性模型的热力图
除上述方法外,许多学者研究了其他方法提高对抗样本的迁移性,如表3 所示。
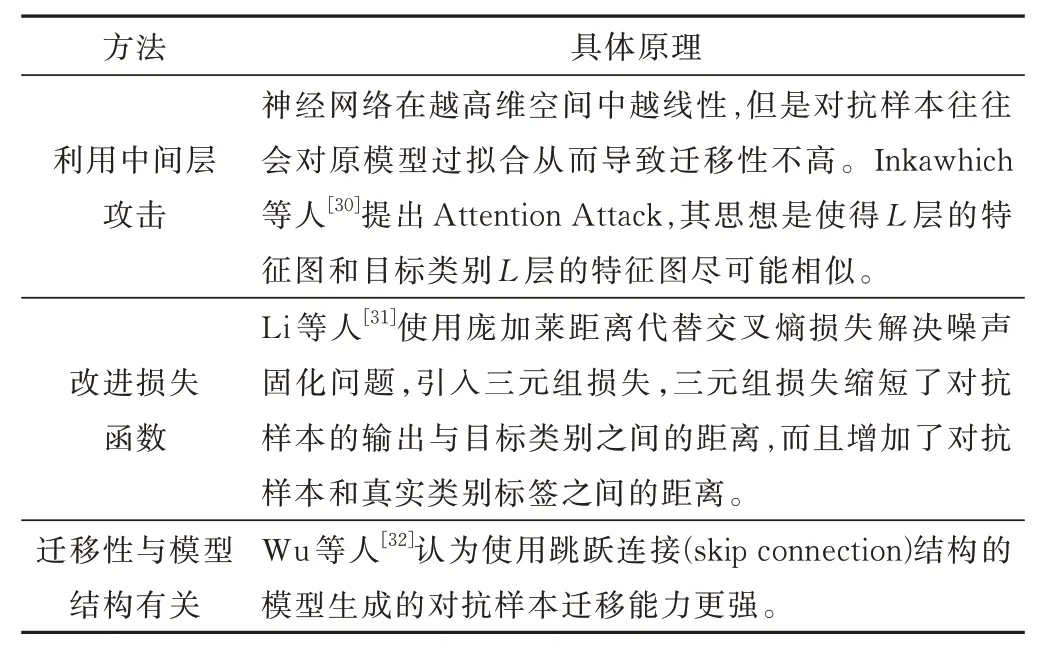
表3 提高迁移性的其他方法
3.1.2 面向特定黑盒
面向特定黑盒提高对抗样本迁移性主要采取模型窃取(MS)的方法。MS 允许攻击者拥有黑盒访问目标模型的权力,通过获取不同输入在目标模型中的预测结果训练替代(克隆)模型,从而复制目标模型功能[33]。
模型窃取的过程是首先通过查询目标模型构造数据集,若目标模型的训练数据集未知,则训练克隆模型的难度更大。然后根据不同的任务选择克隆模型的结构,使用构造的训练集训练克隆模型。最后在克隆模型的基础上生成对抗样本,过程如图7 所示。
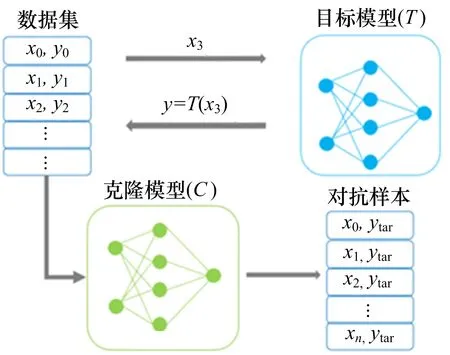
图7 模型窃取生成对抗样本
Papernot 等人[34]将攻击过程分为2 个阶段,第一阶段仅使用训练数据集的部分数据或者与目标模型的训练数据集不一定具有相同分布的真实数据,使用Jacobian-based Dataset Augmentation 方法生成数据集训练替代模型,以拟合目标模型的决策边界。第二阶段在替代模型上生成对抗样本。
Zhou[35]等人首次提出无需任何真实数据训练替代模型的攻击方法DAST,对传统的GAN 进行了改进,为生成模型设计了多分支架构和标签控制损失以解决合成样本不均匀分布的问题,利用合成的样本来训练替代模型。该方法中替代模型输出与目标模型相同的预测结果而不是拟合目标模型的决策边界,而且没有恢复训练数据集的数据分布。Wang 等人[36]提出多样数据生成模块和对抗替代训练策略,保证合成的数据训练的替代模型的边界和目标模型的边界更相似,提高了攻击的成功率。Kariyappa 等人[37]提出MAZE 攻击方法,将无数据的知识蒸馏方法和零阶优化(ZOO)相结合,训练合成数据的生成器,使得目标模型的边界和克隆模型的边界对齐,获得高精度的克隆模型。
3.2 基于查询的攻击
查询目标黑盒可以得到反馈信息,攻击者可以利用反馈信息攻击.基于查询的黑盒攻击可以描述为:
式中,Q为单个图像的最大查询次数,ytrue是干净图像x的真实标签,Mtar为要攻击的目标模型,Mtar(xadv)是输入xadv到目标模型中输出的概率,L 为损失函数。
根据从目标模型得到的反馈信息不同,基于查询的攻击可以分为基于分数的攻击和基于边界的攻击。基于分数的攻击从目标模型得到的反馈信息是分数或者概率,基于边界的攻击则是硬标签。
3.2.1 基于分数的攻击
1) 基于梯度估计的黑盒攻击
基于梯度估计主要通过查询目标模型得到的反馈信息估计目标模型的梯度,Chen 等人[38]提出零阶梯度估计攻击方法。在黑盒环境下,网络的参数、结构未知,因此无法通过反向传播知道梯度更新对抗样本,该方法使用对称商差来估计一阶梯度和二阶梯度。获得梯度后,使用随机坐标下降方法即ZOO-Adam 和ZOO-Netwon 更新对抗样本。该方法需要查询目标模型2p次,其中p为一张图片的总像素数目,对于高分辨率的图片必然导致查询次数过多,因此提出使用双线性插值的方法减少攻击空间的维度。此外还采取了坐标采样,即根据坐标的重要性选取重要坐标更新梯度。该方法的缺点是所需查询次数较多,容易引起目标模型的注意。在梯度估计方法的基础上,研究者提出如表4 所示的改进方法。
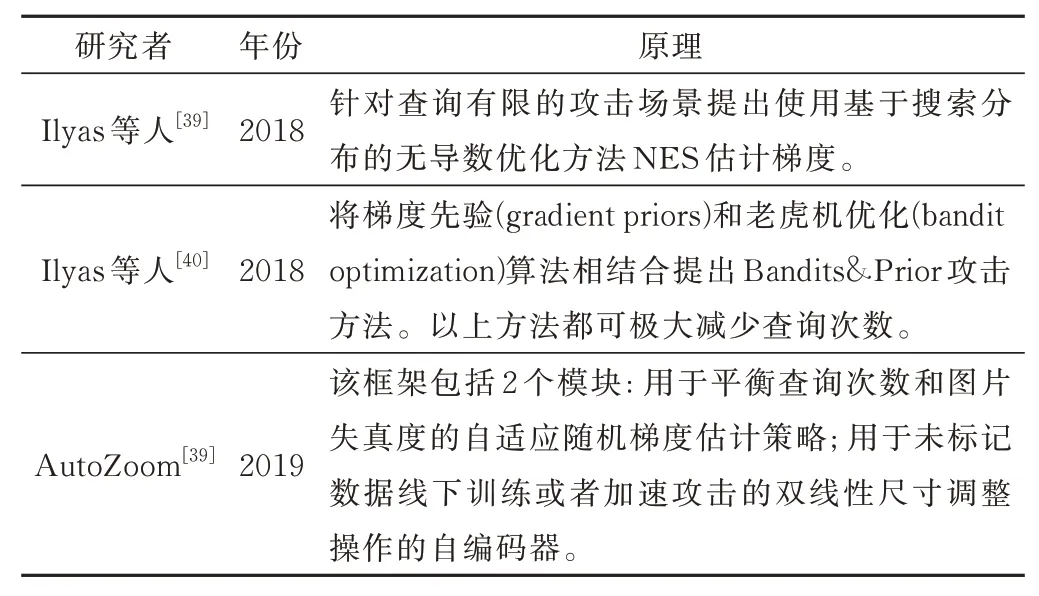
表4 基于梯度估计的方法的改进
2) 基于模型窃取的黑盒攻击
Du 等人[42]将元学习和对抗攻击结合起来提出Meta Attack,Aθ是模拟黑盒的梯度轻量级的自编码器,利用元学习的方法训练攻击器Aθ。该方法仅在Aθ的微调时使用到需要查询密集的梯度估计方法,因此保证了梯度生成质量的同时大幅减少了查询次数。但如果图片分辨率高,Aθ无法准确预测梯度矩阵。因此,Meta Attack 方法从梯度矩阵中选择最大梯度值的125 个元素进行回归,但攻击高分辨率图片时仍效果不佳。
Ma 等人[43]提出Simulator Attack,利用元 学习的方法训练模拟器M,与Aθ不同的是,M 模拟目标黑盒的输出。M 只需要查询少量的数据微调即可精确地模拟任何未知黑盒的输出,生成对抗样本时将大量的查询转移到M 上,有效减少查询次数。
3) 基于进化算法的黑盒攻击
Su 等人[44]提出One-Pixel 攻击方法,该方法只改变一个像素点的值,不限制其改变大小,对扰动像素的位置信息和扰动强度进行优化生成对抗样本。该方法针对分辨率较低的数据集如MNIST、CIFAR10效果较好,但是图片分辨率较高时,一个像素点的改变很难影响分类结果。此外,基于进化的算法依赖于种群规模和迭代次数,为了获得全局最优解,种群规模和迭代次数设置很大。因此,One-Pixel 攻击需要消耗的时间长,攻击效率低。
Jia 等人[45]提出了结合了图像水印技术的对抗水印生成算法Adv-watermark,提出基于种群的全局搜索策略BHE(Basin Hopping Evolution)来搜索水印的位置和透明度生成对抗样本。
3.2.2 基于边界的攻击
基于边界的攻击在一个更加严格的黑盒环境下,将样本输入到目标模型中,仅能获取到模型预测类别即硬标签,而不能获取概率或者置信度,获取的信息更少,攻击难度更高。
Brendel 等人[46]提出仅能获取目标模型输出的硬标签的Boundary Attack 攻击方法。对于非定向攻击,在图片有效范围[0,255]内通过最大熵分布采样得到初始对抗样本。对于定向攻击,选择目标类别的图片作为初始对抗样本。每次迭代产生一个扰动,产生的扰动满足:1) 对抗样本在图片有效范围内;2) 扰动和对抗样本与原始样本之间的距离成正比,且尽量减少对抗样本和原始样本之间的差异,在不断迭代靠近原始样本的基础上生成对抗样本。Boundary Attack 是基于边界的攻击方法的开山之作,可以攻破防御性蒸馏,缺点是需要大量的查询,且无法保证一定能收敛。
3.2.3 小结
面向特定黑盒的攻击主要是采用模型窃取的攻击方法,其缺点是当目标模型的结构发生改变后,在替代模型基础上生成的对抗样本攻击成功率会明显下降。如果目标模型结构发生很大变化,则会导致基于替代模型产生的对抗样本无法攻击成功。面向特定黑盒需要根据攻击场景选择替代模型结构,如攻击场景为分类场景,选择替代模型一般为VGG 系列或者ResNet 系列等。面向所有黑盒的攻击利用对抗样本的迁移性,针对任意未知结构的黑盒迁移性都略有提高。与基于分数和迁移的攻击相比,基于边界的攻击更贴近真实场景,不需要依赖替代模型,但也带来了挑战:首先分类标签对基于梯度的小扰动不是很敏感;其次输入样本到目标模型中,只能获取到硬标签,所以攻击目标函数是不连续的,因此难以优化。基于迁移的攻击方法虽然无需查询目标模型但是有2 个缺点:1) 一般都需要训练数据集训练替代模型;2) 攻击成功率特别是定向攻击的成功率不高。基于查询的攻击方法缺点在于查询次数多,容易被目标黑盒防御和检测,且攻击效率低。因此,基于查询的攻击方法的改进目标在于如何减少查询次数。
4 实验对比和分析
4.1 常见的攻击方法对比
实验利用MNIST 数据集对分类器LeNet-5 卷积神经网络进行训练和测试,epoch 设为10,经历过10 次epoch 训练和测试后,分类器准确率可达98.14%。基于梯度的方法产生的对抗样本识别准确率如表5 所示,其他攻击方法对抗样本识别准确率如表6 所示。
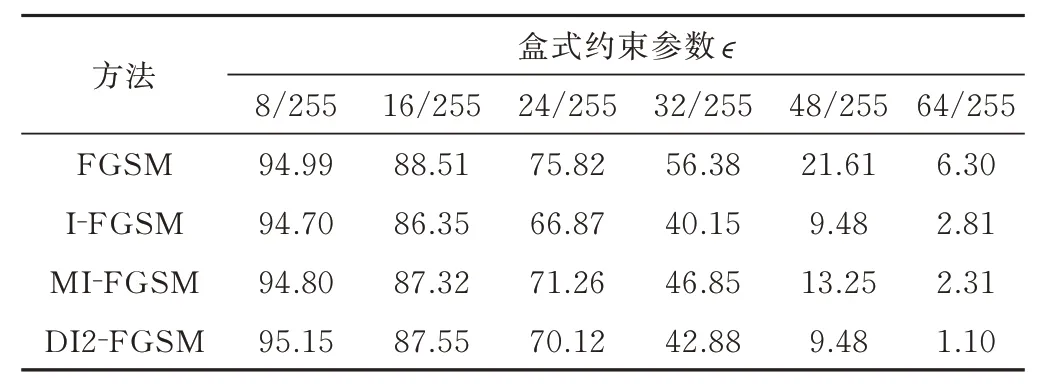
表5 FGSM 系列对抗样本识别准确率%

表6 其他攻击方法对抗样本识别准确率
由表5—6 分析可知:
1) I-FGSM 和FGSM 相比,对抗样本识别准确率降低,说明迭代攻击的效果比单步攻击效果好;
2)∊越大,攻击强度越大,肉眼可见的噪声越多,对抗样本识别准确率越低,攻击成功率越高;
3) C&W 攻击识别准确率最低,是最强的白盒攻击方法之一,但是比FGSM 系列的算法攻击时间长;
4) 黑盒攻击方法One-Pixel 仅仅修改一个像素,攻击成功率低,生成对抗样本时间长。
4.2 黑盒迁移性对比
实验利用CIFAR10 数据集对白盒模型VGG19 和黑盒模型ResNet18 进行训练和测试,经历过250 次epoch 训练和测试后,VGG19 的分类准确率可达93.53%,ResNet18 的分类准确率可达95.01%。
通过实验,常见的几种攻击方法黑盒迁移性对比如表7 所示。由表7 分析可知:
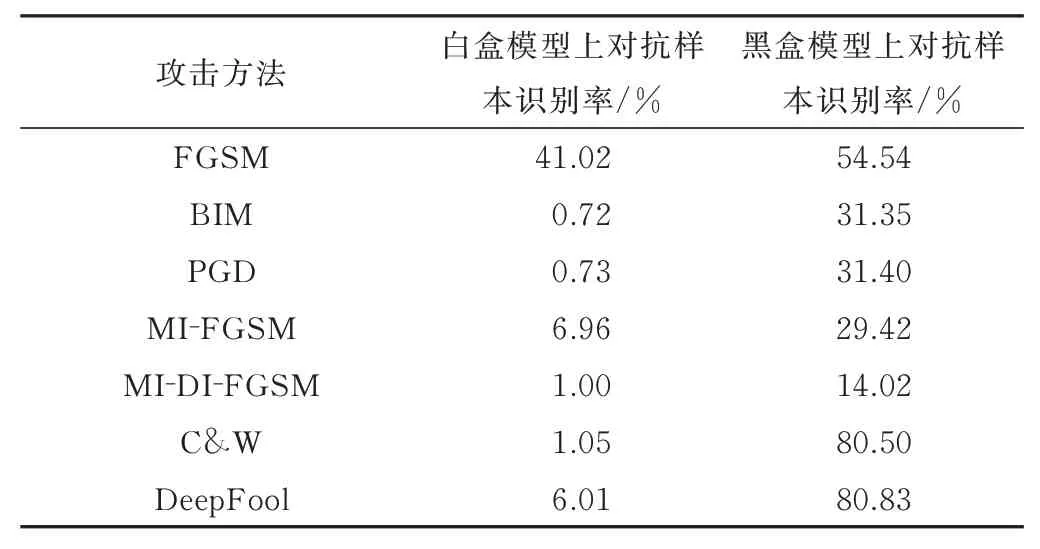
表7 常见的几种攻击方法黑盒迁移性对比
1) 黑盒模型识别干净样本的准确率为95.010%,在黑盒模型上对抗样本的识别率均小于95%,说明对抗样本存在迁移性。
2) 基于梯度的攻击方法生成的对抗样本在黑盒模型上的识别准确率明显低于非梯度的方法,与其他白盒攻击方法相比,基于梯度的攻击方法生成的对抗样本的迁移性高。
3) 对抗样本识别准确率:MI-DI-FGSM<MIFGSM<BIM,说明利用输入多样性、动量等方法可以与其他方法相结合,提高对抗样本的迁移性。
5 研究展望
深度学习领域对抗攻击技术的发展历程主要分为:1) 攻击方法由刚开始简单的白盒攻击到黑盒攻击、攻击模型由分类模型到目标检测模型和图像检索模型等;2) 由数字世界的攻击转变为物理世界的攻击;3) 攻击的领域由图像领域逐渐应用到自然语言处理、语音识别、隐私保护等各个领域。
总的来说,目前深度学习对抗攻击领域仍处于研究探索阶段,提出以下展望:
1) 提高对抗样本泛化性能
对抗样本的泛化性能,指对抗扰动的通用性,即对抗扰动对整个数据集或者其他未知结构模型都有效。在现实世界中,大部分是黑盒环境,面对模型结构未知、参数未知的黑盒模型,提高对抗扰动泛化性意味着对抗样本对多种结构不同的黑盒模型都依然保持攻击成功率。在攻击时,直接添加通用扰动,无需大量访问被攻击网络,不容易暴露攻击,攻击过程变得简单高效。
2) 拓展对抗攻击技术应用领域
目前对抗攻击技术已经拓展到文本、语音等领域,未来可探索发挥对抗攻击积极的作用。诸如,对抗攻击可应用在隐私保护领域,将隐私数据添加对抗扰动相当于进行加密操作,即使上传到网络后蓄意收集隐私者也无法利用数据训练;将对抗攻击应用到军事作战领域中,可以欺骗敌方的无人车或者无人机目标检测系统,从而达到隐藏装备的目的。
3) 关注模型鲁棒性
对抗样本的存在使研究者意识到模型的高识别准确率并不等于鲁棒性。当模型仅追求更高的分类准确度时,往往会牺牲在对抗攻击下的鲁棒性。当分类器具有非常低的分类错误率的时候,在对抗攻击下它将变得非常脆弱。因此,模型的设计要重视模型的对抗鲁棒性。未来模型的结构设计可以多关注于图片的整体形状,减少对纹理的依赖。
6 结束语
本文首先介绍对抗攻击的定义、分类标准和发展历程,对比分析白盒攻击方法和黑盒攻击方法,然后使用MNIST、CIFAR-10 数据集对经典的攻击方法进行实验验证,最后总结对抗攻击技术,分析其发展前景。未来不仅要围绕对抗攻击的技术深度展开研究,还要拓宽对抗攻击技术的应用领域,提高深度学习系统的安全性和鲁棒性。■
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
网络安全与数据管理(2022年3期)2022-05-23
通信学报(2021年2期)2021-03-09
福建中学数学(2021年2期)2021-02-28
通信世界(2018年29期)2018-11-21
科教导刊·电子版(2016年35期)2017-04-20
科学与财富(2016年32期)2017-03-04
信息记录材料(2016年4期)2016-03-11
电测与仪表(2014年3期)2014-04-04
