
数据库系统参数调优方法综述
2023-03-27 13:39崔江涛
计算机研究与发展 2023年3期
曹 蓉 鲍 亮 崔江涛 李 辉 周 恒
1(西安电子科技大学计算机科学与技术学院 西安 710071)
2(浪潮集团有限公司 济南 250014)
万维网、电子商务、物联网和其他应用的持续发展产生了大量且不断增长的原始数据,因此需要一类软件系统来处理海量的原始数据,并通过分析数据从中提取有用信息.为了满足数据处理的需要,数据库系统应运而生,它不仅是存储介质、处理对象和管理系统的集合体,也是一个为应用系统提供数据的软件系统,是数据基础设施中必不可少的关键组成部分.在这种背景下,实现良好且健壮的数据库系统性能是高效执行数据存储、分析和管理的基础.然而,数据库系统性能与大量的配置参数直接相关,这些参数控制着系统运行时操作的各个方面,并极大地影响了数据库的性能[1].数据库的配置参数主要分为3 类:1)资源类;2)策略类;3)位置类[2].资源类参数指定系统为某项任务分配多少资源,包括固定组件(例如垃圾收集线程数)和动态活动(例如每个查询的内存使用量).策略类参数决定数据库系统如何处理特定任务.例如,通过设置特定参数可以控制数据库系统在事务提交时是否将预写日志刷新到磁盘.最后,位置类参数指定数据库系统在哪里找到需要的资源(例如文件路径),以及如何与外部进行交互(例如网络端口号).其中,资源类和策略类参数对数据库系统的性能影响较大,数据库性能优化应重点考虑这些参数在特定环境下的调优.
数据库参数优化是一项维持或提升数据库性能的重要工作.通过调整数据库系统配置参数实现性能优化的一类技术统称为数据库参数优化技术.参数优化产生的性能优势在业界是众所周知的,合适的参数配置可以实现数据库数量级的性能提升[3],而不合适的参数配置则会导致其系统性能大幅度降低[4].然而,由于数据库的性能受到多个参数共同影响,再加上可调参数数量、数据库体量和业务量的剧增,导致传统基于人力的参数优化越来越困难.另一种直观的方式则是通过测量数据库系统所有参数配置的性能,来确定最佳的参数配置.但由于高维配置空间的复杂性,这种方法通常是不可行的.例如,若对1个仅具有5 个可调参数的系统进行所有实验,假设每个参数有6 种不同的取值,且每个实验的平均运行时间为10 min,则进行所有实验需要60 d,这通常是不可接受的[5].因此,数据库自动参数优化技术是解决这一难题的主要选择之一,是一种很有前景且具有挑战性的系统性能优化方法.具体来说,数据库系统参数优化有3 个主要的挑战:
1)复杂性.数据库系统通常存在数百个可调的参数[2],参数具有连续型、离散型和枚举型等多种类型和不同的取值范围,而且参数之间存在复杂的隐性依赖关系.例如,某些参数可能会以不同的方式影响查询性能,而某些参数组合可能会产生不同的效果.有研究工作表明在复杂的参数空间中找到最优的系统参数配置是一个NP-hard 问题[6].
2)样本不足.数据库参数优化通常需要大量数据样本来获得良好的结果,而收集这些数据是昂贵和耗时的.为了不干扰生产系统的运行,数据库管理员(database administrator,DBA)首先需要部署1 个数据库副本,并获取1 个具有代表性的工作负载示例,调优工具将在单独的测试系统上运行该工作负载的实验.根据工作负载示例运行时间的不同,收集足够的数据样本可能需要几天甚至几周的时间,而实际的调优过程往往有严格的时间限制,这将导致样本不足的问题.
3)动态变化性.随着数据库系统的规模不断增大,复杂性增加,繁复多变的工作负载以及灵活的云基础设施使数据库系统的参数优化变得更具挑战性.当环境发生变化时(包括工作负载变化、硬件配置变化和软件版本变更),现有的最优参数配置将不再适用.在这种情况下,如何利用现有的优化知识,对新环境快速地进行参数优化也是亟待解决的问题.
目前,大量研究工作通过在数据库系统中引入自配置特性来解决性能优化问题.值得一提的是,软件系统参数优化领域也存在大量的研究成果.数据库管理系统是软件系统的一个类别.因此,一部分软件系统参数优化的工作也适用于数据库管理系统,在实验部分也会选取部分数据库管理系统对方案有效性进行验证.这部分工作通常满足2 个条件:1)参数优化工作视系统性能模型为黑盒模型,无需对系统内部进行深入理解与分析;2)参数优化工作能够处理连续型、离散型和枚举型等多种类型的配置参数,与数据库系统的参数类型一致.在后续的文献综述中也会包含一部分满足上述2 个条件且对数据库系统进行实验验证的软件系统参数优化工作,并在相应位置进行说明.
本文对现有的数据库参数优化方法进行了全面的研究,总结出针对不同挑战和场景提出的不同方法或策略.本文将这些方法按照问题场景的不同分为2 类:固定环境下的数据库参数优化方法和变化环境下的数据库参数优化方法.其中,针对固定环境下的数据库参数优化方法的研究工作较多,按照方法的特点进一步分为传统的数据库参数优化方法(包括手工参数优化方法、基于规则的参数优化方法、基于模型的参数优化方法和基于搜索的参数优化方法)和基于机器学习的数据库参数优化方法(包括基于传统机器学习的参数优化方法和基于深度强化学习的参数优化方法).下面对各种方法进行简要介绍.
1)手工参数优化方法是专家通过手工反复实验得到的数据和经验来确定最终参数配置的方案.
2)基于规则的参数优化方法能帮助用户根据专家的经验、在线教程或调优说明进行参数优化.
3)基于模型的参数优化方法通过深入了解系统内部建立有效的性能模型,建立模型需要大量专家知识,不需要或仅需要少量的性能样本.
4)基于搜索的参数优化方法基于搜索算法和当前系统性能反馈的指导,在不同的参数配置下反复执行某一工作负载,从而找到最佳性能下的参数配置.
5)基于传统机器学习的参数优化方法把数据库系统视为黑盒,不需要对系统内部深入理解,通过性能样本和机器学习方法构建性能预测模型.
6)基于深度强化学习的参数优化方法通过将数据库参数优化场景映射到强化学习中,来寻找最优的参数配置,这种方式既不需要先验知识,也无需对复杂的性能曲面进行拟合.
7)变化环境下的数据库参数优化方法将迁移学习的概念引入数据库系统的参数优化中,可以随着环境的变化调整性能预测模型或推荐最优参数配置.
下文将对数据库系统的各种参数优化方法进行深入分析和比较,并对每种方法的优缺点进行归纳总结.通过对数据库系统中具有代表性的参数优化技术进行全面的回顾和分析,本文有益于启发新的参数优化技术及其实际应用,并且可以作为选择和比较现有参数优化方法的技术参考资料.具体来说,本文的主要贡献有3 个方面:
1)对数据库参数优化进行了问题定义,并提供了相关方法的一般分类.
2)对现有代表性参数优化方法的关键特性进行了详细描述.
3)介绍了未来的研究问题与挑战,并展示了参数优化是一个具有挑战性的研究领域,其解决方案将广泛应用于现实世界用例中.
通过对相关综述工作进行搜索整理,目前已有一些研究数据库系统查询优化的综述论文[7-9].查询优化是一个较为成熟的研究领域,但关注点主要集中在优化查询执行计划,或索引和物化视图的创建,忽略了配置参数的优化.本文关注的参数优化问题可以优化整个数据库系统的性能,进而优化查询性能.同时,也存在一些对自动参数优化方法进行研究的综述文章[10-11],它们的研究对象是大数据处理系统和启发式算法,而不是本文关注的数据库系统.此外,机器学习技术在数据库系统和数据管理技术中的应用也是目前的研究热点之一[6,12-15],数据库系统的参数优化问题是其中关心的问题之一,在这部分综述中的相关讨论还不够详细和深入.文献[6,12-15]所述的工作着重综述了固定环境下的数据库参数优化方案,本文添加了对变化环境下数据库参数优化和性能预测方案的讨论.文献[16]中也有对变化环境下数据库参数优化方法的介绍,但主要集中于工作负载变化场景,即自适应参数优化方法.文献[17]同样关注于工作负载变化场景,并将工作负载感知的数据库性能优化分为3 个方向:工作负载分类、工作负载预测和基于工作负载的调优.本文则对3 种不同类型的环境变化场景下的参数优化工作进行了分类介绍.此外,Van Aken 等人[18]也针对数据库管理系统的参数优化问题进行了研究,但重点关注基于机器学习方法的自动参数调优服务在实际生产环境中进行应用的效果,并没有对相关工作进行全面的总结分析.本文着眼于数据库系统的参数优化问题,对相关工作进行归纳总结,并进行了详细和深入的分析,从而帮助广大研究人员充分了解当前数据库参数优化技术的发展情况.
1 研究问题
图1 是数据库系统参数优化问题的示意图.给定待优化数据库系统、系统的工作环境和优化过程中的资源约束,参数优化问题的目标是通过调节该系统的可配置参数来优化系统的性能指标.具体来说,该问题包含待优化数据库系统、工作环境、优化约束、配置参数和系统性能5 个概念,下面分别进行定义.
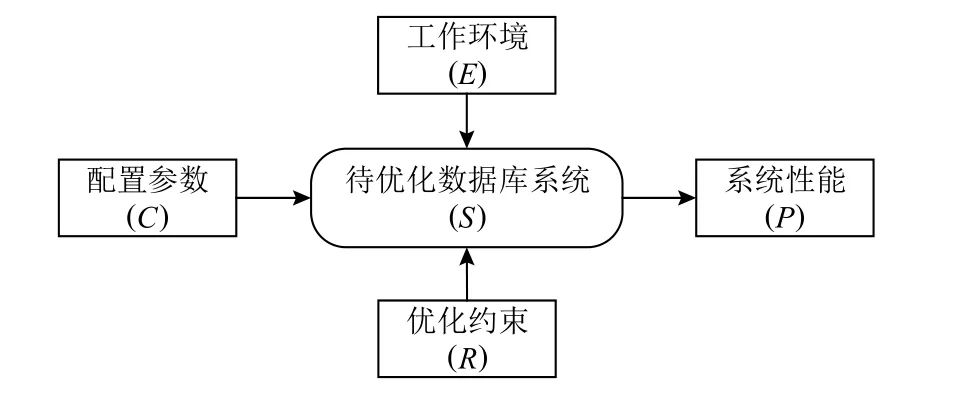
Fig.1 Overview of parameter tuning problem for database systems图1 数据库系统参数优化问题示意图
1)待优化数据库系统(system under tune,S).待优化数据库系统是需要进行参数优化的数据库系统,通常具有大量的可配置参数.
2)工作环境(environment,E).数据库系统部署和使用的不同方式被称为工作环境.数据库的工作环境主要包括3 个因素:1)工作负载(workload,W);2)硬件配置(hardware,H);3)软件版本(version,V).上述3 个因素分别对应的是系统运行的输入、系统的硬件配置和软件的版本状态.其中,工作负载是指数据库系统需要完成的业务或查询任务,例如,需要执行的事务集合、需要完成的查询请求等.在参数优化问题中,优化人员通常无法事先了解工作负载的内部细节,仅可以通过实验的方法测量数据库系统在该工作负载下的性能,而不进一步考虑其内部结构.本文将一个工作环境形式化地表示为e=(w,h,v),w∈W,h∈H,v∈V,其中W,H,V分别表示所有可能的工作负载变化W、所有可能的硬件变化空间H,以及所有可能的软件版本V.因此,环境空间可以定义为E=W×H×V,且e∈E.
3)配置参数(configuration,C).为了提高性能和灵活性,待优化数据库系统通常会提供大量的参数,鼓励使用者根据不同的工作环境进行个性化配置,以获得最佳的系统性能体验.本文将待优化数据库系统S的所有可配置参数记为集合c={c1,c2,…,cn},其中ci表示某个具体的参数,n表示参数的总数量,c∈C.为了避免混淆,本文使用术语“配置参数”表示所有可配置的参数构成的集合,用“配置”表示配置参数的一组完整取值,用“参数”表示配置参数集合中某个具体的参数,用“参数值”表示该参数的具体取值.
4)系统性能(performance,P).数据库的系统性能是用来度量待优化系统优化效果的指标,常见的性能指标包括响应时间、吞吐量、每秒处理的事务数量等.系统性能通常与系统需要完成的业务相关,由用户与系统设计人员共同确定,并具有可测量、可量化、可比较等重要特征.本文将系统性能记做函数P(·),并用P(s,e,c)表示某个待优化数据库系统s在工作环境e和配置参数c下的具体性能取值,s∈S.
5)优化约束(constraint,R).由于待优化数据库系统通常会成为承载企业实际应用的系统,需要快速上线并长期运行,因此对参数优化过程有着较为严格的限制和约束,其中最常见的约束条件是优化时间.由于待优化系统在不同参数配置下运行时间可能差异较大,为了简化并确定约束条件,本文将优化时间约束转换为系统测试次数约束(记作T),即严格限制系统在不同参数配置下的性能测量次数,记做T≤N,N表示限制最大系统测试次数.
基于上述5 个定义,数据库系统参数优化问题定义为:
其中式(1)表示优化问题的目标是通过在合法的配置参数空间中进行探索,找到在特定工作环境e下,能够使得某个待优化目标系统s取得最优性能的配置c.式(2)表明该问题有着非常严格的约束条件,即能够对待优化数据库系统进行测试的次数T不能大于预先设定的上限值N.
在对研究问题进行形式化定义的基础上,本文从问题层面出发,根据参数优化过程是否涉及环境变化,分别从2 个角度对数据库参数优化技术进行了综述:首先总结分析在固定工作环境下进行参数优化的方法;随后,介绍变化环境下的数据库参数优化方法;最后,对研究现状进行总结,并指出未来的研究方向与挑战.
2 固定环境下的数据库参数优化方法
近年来,随着物联网、云计算、大数据等技术的兴起,对不同环境下快速进行数据库系统自动参数优化的需求日益迫切,目前已经有很多相关研究成果.根据数据库参数优化方法本身是否具有学习能力,本文可以将这些方法大体分成传统的参数优化方法和基于机器学习的参数优化方法2 类.其中,传统的参数优化方法可进一步细分为手工参数优化方法、基于规则的参数优化方法、基于模型的参数优化方法和基于搜索的参数优化方法;基于机器学习的参数优化方法可根据采用的机器学习技术进一步分为基于传统机器学习的参数优化方法和基于深度强化学习的参数优化方法.
2.1 传统的数据库参数优化方法
2.1.1 手工参数优化方法
传统的手工参数优化方法完全依赖于DBA 的经验.通过不断地进行手工实验获取专家经验,再根据这些专家经验确定最终的参数配置.这种手工参数优化方法虽然能够在一定程度上解决问题,但在有效性方面存在严重问题.一方面,数据库的参数空间通常具有高维且复杂的特点,通过少量的手工实验来获取足够的专家知识对DBA 是一项非常艰巨的任务;另一方面,DBA 需要根据应用程序的操作调整数据库参数,然而这需要进行大量的实验迭代.这种不断试错的方法是非常耗时的,因此DBA 往往需要数天甚至数周的时间来进行数据库参数优化,这将造成大量的人力、资源成本开销.
2.1.2 基于规则的参数优化方法
DBA 负责执行监控或维护数据库环境相关的任务,典型的参数优化是以他们的专业知识和经验为基础的,根据规则和指南配置参数也是常用的辅助决策方法.这种方法通常是数据库厂商针对某种数据库进行设计的,通过获取数据库状态、性能以及部分配置参数对数据库性能的影响,为参数的设置提供建议.举例来说,MySQLTuner[19]是一款用于分析MySQL 配置和性能的工具,通过在数据库运行时获取数据库的状态数据和当前的配置参数,并基于规则给出一些参数调整的基本建议.类似的针对特定版本和类型的数据库参数优化指南还有Oracle 数据库性能调优指南[20]、IBM 调优指南[21]、Azure SQL 数据库的自动调优指南[22].此外,当数据库成为主要的企业级瓶颈时,WebLogic[23]提供的调优指导能够配置数据库以获得最佳性能,包括一些通用的数据库调优建议和适用于Oracle,SQL Server,Sybase 数据库的调优建议,其中给出了一些重要参数及其推荐值.
错误的参数配置是许多开源数据库系统查询失败的主要原因之一.针对这一问题,SPEX[4]通过软件源代码推断配置需求,并进一步揭露错误配置漏洞,诊断容易出错的配置.SPEX 将不同类型的错误配置漏洞进行分类,并在此基础上检测和预防某些易出错配置.具体来说,SPEX 引入配置约束来帮助定义配置需求,这种约束包含参数的数据类型和取值范围,以及与其他参数的依赖关系或相关性.SPEX 通过这些约束可以自动分析参数配置是否合理,并帮助实现参数的正确配置.
Xu 等人[24]还研究了一个与参数相关的基本问题,即筛选出对于系统性能优化和可靠性任务而言最重要的参数.该研究针对这一问题提出了一些具体而有效的指导方针,能够显著降低参数配置空间.指导方针包括:1)理解实践中使用的配置参数;2)降低过度设计带来的配置复杂性.对于指导方针1,Xu 等人[24]认为:①许多参数既没有必要也没有价值;②简化枚举类型的参数可以简化配置,且不会显著降低系统灵活性;③过多的参数使寻找最优参数配置变得非常复杂;④大量用户仅设置具有显式外部影响的参数.对于指导方针2,Xu 等人[24]展示了可以在对用户影响很小的情况下简化参数配置.此外,还研究了关键字搜索、基于自然语言处理(NLP)的导引、谷歌搜索[25]等配置导引方法,并提供了配置导引相关的经验法则.上述2 个指导方针均针对不同类别的软件系统进行了深入分析,包括数据库系统在内,例如MySQL 和PostgreSQL.
基于规则的参数优化方法能够帮助用户根据专家经验、在线教程或参数优化说明对系统参数进行调优.这类方法通常不需要模型,适合快速引导系统,但是基于规则的方法也具有较多的局限性,例如通常面向特定的数据库类型,甚至是特定的版本,应用的场景受限,同时也无法应对变化的数据库环境,因此通常无法在复杂的配置空间中取得很好的优化效果.
2.1.3 基于模型的参数优化方法
基于模型的参数优化方法通常基于对系统组件的深入理解来建立性能模型,需要大量使用专家知识,不需要或仅需要少量的性能样本.
在21 世纪初,IBM 发布了DB2 性能向导工具[26],该工具询问DBA 关于应用程序的问题,例如工作负载是联机事务处理(on-line transaction processing,OLTP)还是联机分析处理(on-line analytical processing,OLAP)类型,然后根据DBA 的答案提供参数设置.该性能向导工具基于DB2 工程师手工创建的模型,因此可能无法精确地反映实际的工作负载或操作环境.IBM后来发布了带有自调优内存管理器的DB2 版本,用来确定如何分配数据库管理系统(database management systems,DBMS)的内存[27-28].
自调优内存管理器(self-tuning memory management,STMM)[27]通过运行时建模、成本效益分析和系统级资源分析,可以实现对数据库内存分配的自动调优.具体来说,STMM 包含1 个内存控制器,在每个调优周期中评估不同组件的内存分布,并确定是否可以通过数据库内存重新分配来提高系统性能.此外,调优周期的频率会根据工作负载复杂性或资源可用性的变化而发生改变,从而实现自适应的性能调优.
Tian 等人[28]则研究了缓冲池大小的配置问题.DB2 将缓冲区域划分为许多独立的缓冲池,为每个缓冲池设置适当的大小对于实现最佳性能至关重要.Tian 等人[28]提出了2 种成本模型,分别基于页面错误和数据访问时间,并通过贪心算法来寻找最优解.最后,通过实验验证了文献[28]所提方案的有效性,结果表明,基于数据访问时间的成本模型在优化缓冲池大小方面比基于页面错误的成本模型更有效.
Oracle 开发了类似的内部监控系统[29],用来识别DBMS 内部组件配置错误造成的性能瓶颈,并通过向DBA 提供可操作的建议来缓解性能瓶颈.自动数据库诊断监视器(automatic database diagnostic monitor,ADDM)[29]通过自动化诊断性能问题,并提出适当的调优建议,从而最大限度地提高数据库吞吐量.为了对比不同数据库组件对性能的影响,ADDM 定义了一种新的度量方法——数据库时间,为数据库中任何资源或活动对性能的影响提供了一个通用的衡量标准.该度量方法可以用于识别需要实验的数据库组件,并量化数据库性能的瓶颈.最后,ADDM 通过为数据库组件构建有向无环图来识别产生性能问题的根本原因.通过对各种可能的替代方案进行仿真来估计对数据库的特定组件或功能的影响.例如,当研究内存参数设置的问题时,ADDM 将对不同缓冲区大小的运行时间进行仿真,并推荐合适的参数值.
与IBM 的工具一样,Oracle 系统采用基于性能度量的启发式方法来管理内存分配,因此无法对所有参数进行优化.Oracle 的后续版本包含SQL analyzer工具,可以评估DBMS 的不同变体对性能的影响,例如升级到某一新版本或更改系统的配置[30-31].微软的SQL Server[32]也采用了这种方法.但是对于DBMS 来说,这些工具仍然需要DBA 的参与,如提供需要更改的参数设置,然后这些工具对该更改执行实验.最终DBA 根据工具报告的结果进行决策.
Tran 等人[33]提出了一种基于buffer miss 的缓冲池调优方法.通过基于分析模型推导得出的公式拟合可用数据,然后利用公式指导调优.Sullivan 等人[34]通过影响图来建模配置参数之间的概率相关性,用参数之间的条件独立性来推断特定DBMS 配置的预期结果.然而,这些影响图必须由领域专家手动创建,因此该方法每次只能调优少量参数.DBSherlock[35]工具通过比较DBMS 性能时间序列数据中运行缓慢的区域和运行正常的区域来帮助DBA 诊断数据库中的性能问题.与此同时,DBA 诊断的根本原因将被纳入算法作为新的因果模型,从而改善未来的性能诊断.
Wei 等人[36]则提出一种基于模糊规则的数据库参数优化方法.首先,根据数据库的自动负载仓库报表获取数据库系统的关键参数和性能指标.其次,通过识别参数和性能指标之间的关系来构造调优相关的模糊规则.最后,开发了一种基于模糊规则的自适应参数优化算法,可以通过调优多个参数提升性能,为DBA 推荐满足性能需求的参数配置.
基于模型的参数优化方法在实际工程中得到大量应用,但仍然存在一些问题:1)构建的性能模型通用性较差,对于不同的数据库类型或不同的应用场景都无法直接应用,需要重新构建;2)每次分析建模过程都需要从零开始,无法利用过往的参数优化经验.
2.1.4 基于搜索的参数优化方法
基于搜索的参数优化方法将数据库系统的参数优化建模为一个黑盒优化问题,并试图采用搜索算法解决该问题,搜索的目的是为了评估不同的参数配置,并找到获取最优性能的参数配置.
Zhu 等人[37]提出一个针对多种系统的参数优化框架BestConfig,该框架在指定优化时间约束、待优化系统和资源配置的条件下,采用划分和分支采样方法、递归界限搜索算法自动对该系统的配置参数进行优化.在方法评估部分对包括MySQL 和Cassandra数据库在内的6 种软件系统进行了实验验证.
基于搜索的参数优化方法能够直接在参数空间中进行搜索,无需深入系统内部的先验知识,方法的适应性较强.然而,这类方法难以利用优化过程中已有的知识和规律,优化效果通常不佳.
通过对比和分析可以看出,传统的方法在给定的优化约束条件下往往不能得到最优的效果,因此并不是解决数据库参数优化问题时的最好选择.另一方面,传统方法对于每次参数优化任务都需要重新进行整个参数优化过程,不能充分利用过往调优任务中已获取的数据和知识来进一步提升调优效果.这一问题不仅会浪费大量的时间和资源成本,也大大限制了参数优化能力的提升.
2.2 基于机器学习的数据库参数优化方法
随着机器学习技术的不断发展与成熟,目前机器学习已经作为一种基础服务技术,在医疗、汽车等不同领域中进行应用,具备了一定的解决实际问题的能力.因此,许多研究人员试图通过机器学习技术来解决传统数据库参数优化方法中的不足与限制.
传统的参数优化方法通常需要大量专家知识去制定有效的规则和建立可靠的模型,或者通过不断采样对参数空间进行搜索的方式寻找最优参数配置.不同于传统参数优化方法,机器学习可以通过在大量数据中学习获取输入空间到输出空间的映射关系,从而能对任意输入的输出进行较为准确的预测.在参数优化问题中,由于参数空间巨大且复杂,收集训练样本费时费力,获取大量的有标签样本是非常困难的.因此,进行有效的参数选择(特征选择)以及选用合适的机器学习模型是至关重要的.
2.2.1 参数选择方法
在参数选择方面,尽管数据库系统中存在数百个配置参数,但并不是每个配置参数都会对系统性能产生显著影响.为了避免时间和精力被浪费在调整那些可能对性能没有影响或影响较小的参数上,识别影响最大的参数对数据库参数优化任务是至关重要的.目前,最常用的方法是根据专家经验来选择参数,同时也有一些研究人员尝试使用机器学习或其他技术来排序或识别与性能相关性较强的重要参数,例如Lasso[3]和方差分析(analysis of variance,ANOVA)[38]等.
SARD[39]是一种基于Plackett &Burman 统计设计方法的数据库参数排序统计方法.SARD 将查询工作负载和配置参数的数量作为输入,仅需要进行线性数量的实验,就可以获得数据库参数对DBMS 性能产生影响大小的排序列表.
Lima 等人[40]则采用了一种包裹式特征选择方法——递归特征消除(recursive feature elimination,RFE),通过有监督学习方法来评估参数子集的质量,迭代地减少数据库参数集.该监督学习算法在这个过程中扮演2 个角色:1)通过评估预测的性能指标来评估一组参数的质量;2)利用线性回归(给变量赋权)或决策树(计算每个变量的基尼系数)等方法,对参数的重要性进行排序.并在此基础上进行性能预测模型构建,根据数据库和工作负载参数的值对性能指标进行预测.构建性能预测模型采用了3 种不同的机器学习模型:梯度提升机(gradient boosting machine,GBM)、随机森林(random forest,RF)和决策树(decision tree,DT),这些非线性模型也可以评估参数子集的质量.实验结果表明用参数子集训练的模型比用整个参数集训练的模型更准确,证明了进行参数选择的必要性.
根据参数优化方法中使用的不同机器学习模型,本文可以将现有研究成果分为基于传统机器学习的参数优化方法和基于深度强化学习的参数优化方法2 类,如表1 所示.表1 中罗列了基于机器学习的数据库参数优化和性能预测方法,以及方法中所使用的机器学习技术、训练难度以及实现目标.其中,训练难度通过综合考量机器学习模型复杂度、技术难易度以及训练时长进行评价,星号越多表示训练难度较高.
2.2.2 基于传统机器学习的参数优化方法
针对某个数据库系统,基于机器学习的参数优化方法首先需要对不同配置参数取值下的系统性能进行采样,然后基于训练样本构建性能预测模型,最后基于性能预测模型,采用某种搜索算法寻找最优配置.由于性能预测模型是参数优化的基础,本文中也考虑了部分与参数优化相关的性能预测方法.
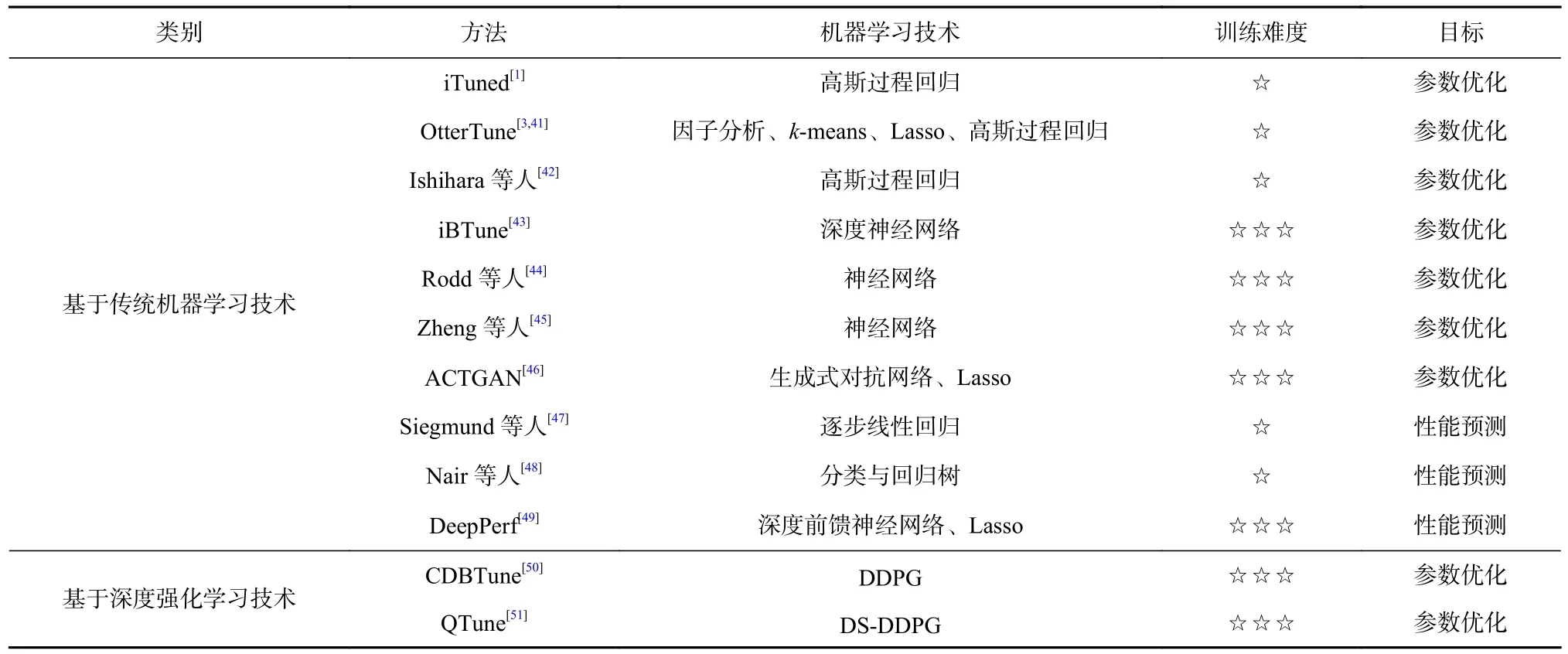
Table 1 Machine Learning-Based Parameter Tuning and Performance Prediction Approaches for Database Systems表1 基于机器学习的数据库系统参数优化与性能预测方法
iTuned[1]是一个基于机器学习方法自动识别最优数据库参数配置的工具,通过2 个步骤搜索参数空间.首先,通过拉丁超立方体采样(latin hypercube sampling,LHS)在备份环境中选择初始样本.接下来,iTuned 基于上一步获取的样本构建了基于高斯过程模型的性能曲面,并根据预期改进函数选择下一个采样点,在该采样点对应的参数配置下再次进行实验,得到实验结果后更新性能曲面.之后不断循环迭代,直到取得满意的性能值后终止这一过程.在这一过程中,基于高斯过程模型的性能曲面将与实际性能曲面不断接近,iTuned 也可以尽快寻找到最佳参数配置.
与iTuned 类似,OtterTune[3,41]也提出了一种自动数据库参数优化策略,它的创新之处在于可以利用以前参数优化的经验,并结合新的样本来优化数据库参数.为了实现这一目标,OtterTune 综合使用了有监督和无监督的机器学习方法.图2 显示了整个流程,包括3 个阶段:1)工作负载特性描述(删除冗余度量指标);2)重要参数识别;3)自动调优.在阶段1 中,OtterTune 首先利用因子分析将高维度量数据降维成为低维度量数据,然后使用k-means 将低维数据聚类成有意义的分组.通过这2 种降维技术能够有效地去除冗余度量指标,并进一步使用这些内部运行时的度量对工作负载的行为进行描述,以便识别数据储存库中相似的工作负载.这使得OtterTune 能够利用从以前的调优任务中收集到的信息,帮助在新的应用程序下搜索表现良好的参数配置.在阶段2 中,Otter-Tune 选择对目标性能影响最大的重要参数集,减少调优参数的数量能够有效降低需要考虑的参数配置的总数,从而减少机器学习算法的搜索空间.因此,本阶段使用Lasso[52]来筛选与系统整体性能相关性最强的参数,并确定参数的重要性顺序.在阶段3 中,OtterTune 的目标是推荐性能最优的配置.OtterTune首先根据阶段1 选择的工作负载特征,将数据储存库中最相似的工作负载与当前工作负载进行匹配,最后使用高斯过程回归[53]推荐具有最佳性能的参数配置.数据储存库中保存了之前工作负载下的样本及对应的性能曲面,在新的调优任务中可以使用加噪声的旧性能曲面作为初始性能曲面,再通过与iTuned一样的采样更新迭代方式寻找最优参数配置.这种方式可以缓解对大量初始样本的需求,并且有效提升搜索寻优的效率.Ishihara 等人[42]提出的参数调优系统也是采用高斯过程回归来寻找最优的DBMS 参数配置,并应用于工作中的数据库管理系统.
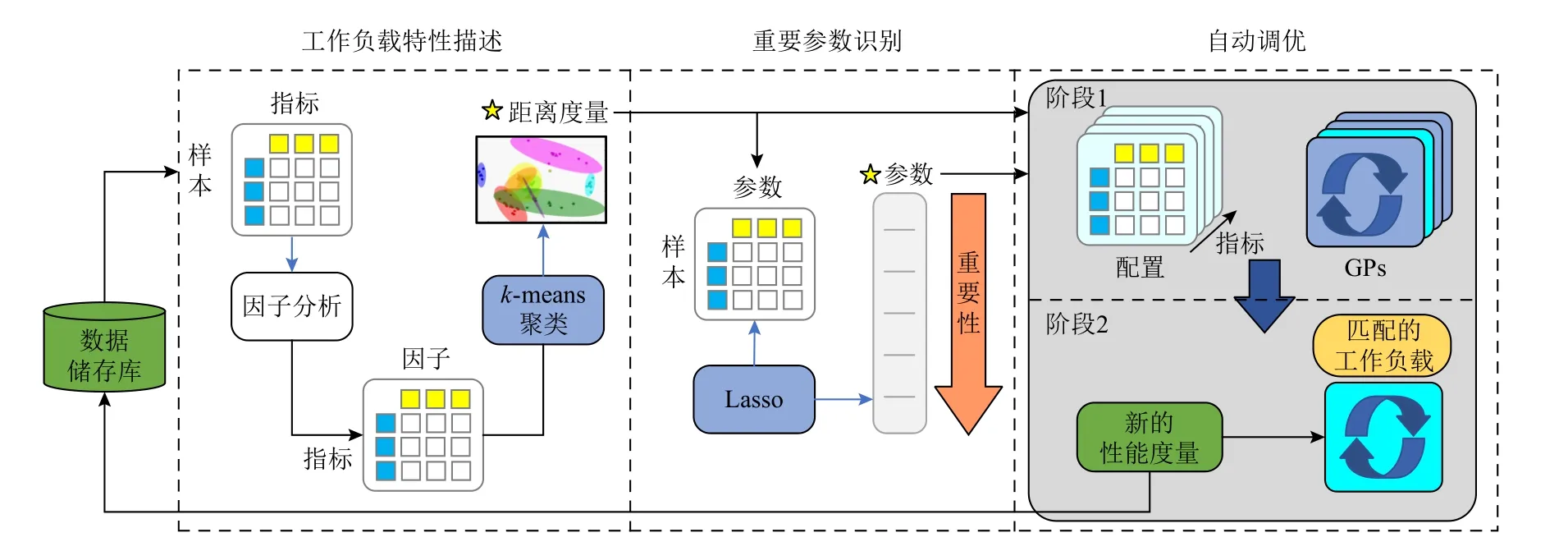
Fig.2 OtterTune machine learning pipeline[3]图2 OtterTune 机器学习流程[3]
针对云数据库缓冲池调优问题,Tan 等人[43]设计了iBTune.利用来自相似工作负载的信息来找出每个数据库实例的可容忍错误率,之后利用错误率和分配的内存大小之间的关系来分别优化目标缓冲池大小.同时,iBTune 还通过一个成对的深度神经网络来预测请求响应时间的上限.缓冲池大小调优只能在预测的响应时间上限处于安全限制的条件下执行.
Rodd 等人[44]提出了一种基于神经网络的参数优化算法.通过主动监测数据库的关键性能指标并作为神经网络的输入,经过训练的神经网络能够为所需的缓冲区大小估算出合适的数值.Zheng 等人[45]也提出了一种基于神经网络的性能自调优算法.首先通过提取自动工作负载存储库报告,识别关键的系统参数和性能指标;然后利用收集的数据构建一个神经网络模型,最后采用一个自调优算法对这些参数进行优化.
ACTGAN[46]则是一种基于生成式对抗网络(generative adversarial network,GAN)的系统参数优化方法.该方法首先采用随机采样得到初始样本,并从中挑选性能较好的参数配置作为GAN 的训练样本,通过对抗学习推荐潜在的、具有更好性能的参数配置.Siegmund 等人[47]通过结合机器学习和抽样启发方法,为可配置系统生成性能影响模型.Nair 等人[48]针对建立精确性能模型所需成本高的问题,提出了一种基于排序的性能预测模型,实验结果表明这种精度较差的模型可用于对配置进行排序,并进一步确定最优参数配置.Ha 等人[49]提出了一种结合深度前馈神经网络和L1 正则化的系统性能预测方法DeepPerf,可以对具有二进制和/或数值型参数的系统性能进行预测.文献[46-49]所述的4 个工作虽然研究对象为软件系统,但均适用于数据库管理系统,并通过实验对方案有效性进行了验证.其中包含了1 个参数优化方案[46]和3 个性能预测方案[47-49].性能预测方案能够实现对不同配置的系统性能预测,从而进一步实现性能优化等数据库系统管理任务.
文献[1,3,41-49]所述方法的区别不仅在于使用模型的不同,在整个调优框架中也有所不同.基于传统机器学习的方法往往采用“参数选择—采样—预测模型建立—最优参数配置搜索”这种管道式框架进行参数调优.对于参数选择,多数方法利用专家知识进行人工选择[1,46,48],一部分工作通过Lasso[3,49]和ANOVA[38]等方法进行,也存在少量针对数据库的缓冲区大小进行研究的工作[43-44].采样方法的选择多数为随机采样和LHS,这2 种采样方法在实际应用中均取得较好的结果.预测模型的不同选择在表1 中进行罗列,使用较多的机器学习模型包括高斯过程回归和神经网络.高斯过程回归计算速度高,但无法精确拟合性能曲面;神经网络学习能力较强,适用于非线性函数拟合,然而训练难度较高.最后,最优参数配置搜索方法的选择与性能预测模型的类型息息相关,例如对高斯过程回归大多使用贝叶斯优化来确定最优参数配置[1,3],也有少部分工作无需进行这一搜索过程,如ACTGAN[46]直接通过GAN 来推荐性能较好的参数配置.
综上所述,基于传统机器学习的方法能够较好地解决数据库参数优化问题,通过利用过往参数优化任务的数据,加快调优任务的进程,且具有较强的普适性,能应用于不同类型的数据库参数优化任务中.但是,这种方法仍存在一些局限性.首先,机器学习方法需要大规模高质量的训练样本,这在数据库系统中往往是难以获取的.其次,基于传统机器学习的方法往往采用上述管道式框架进行参数调优,然而在每个阶段获得的最优解并不能保障在下一阶段仍是最优解,在前面的阶段中获得的结果将直接影响最终的参数优化结果.最后,由于数据库系统具有高维连续且复杂的参数空间,通过简单的机器学习模型(如高斯过程模型)往往很难拟合出精确的性能变化曲面.即使能够拟合出精确的性能变化曲面,寻找该复杂曲面上的最优解仍是NP-hard 问题.考虑到上述问题,一些研究人员开始尝试引入功能更加强大的强化学习来解决数据库参数优化问题.
2.2.3 基于深度强化学习的参数优化方法
为了解决基于传统机器学习的参数优化学习方法中存在的问题,一些研究人员开始尝试使用强化学习对数据库参数进行优化,这种方式既不需要先验知识,也无需对复杂的性能曲面进行拟合.参数优化可以抽象为马尔可夫决策过程,在执行工作负载的过程中,数据库的状态也不断发生变化,在每一个时刻策略算法根据当前数据库状态进行动作,即选择要调整的参数及其数值;完成调整后,数据库将更新状态,并根据更新后的状态进行下一步动作,如此反复迭代直至负载执行结束.使用强化学习多次重复上述过程,就可以找到最适合该负载的数据库参数配置.
针对云数据库的参数优化问题,Zhang 等人[50]利用深度强化学习方法提出了一种端到端的参数优化系统CDBTune.该系统采用试错策略,通过有限的样本进行学习,降低了对大量高质量样本采集的需求.并且通过奖励反馈机制实现了端到端学习,能够在高维连续空间中寻找最优参数配置,加快模型的收敛速度,提高了在线调优的效率.CDBTune 使用强化学习的主要挑战是将数据库参数优化场景映射到强化学习中的适当操作.图3 描述了强化学习中6 个关键元素的交互关系,并展示了CDBTune 中6 个元素与数据库参数优化之间的对应关系.
1)智能体.智能体可以看作是调优系统CDBTune,它接收来自云数据库的奖励(即性能差异)和状态,并更新策略来指导如何调整参数以获得更高的奖励(更高的性能).
2)环境.环境是调优对象,具体来说是一个云数据库实例.
3)状态.状态表示智能体当前的状态.当CDBTune推荐一组参数配置并由云数据库执行时,内部指标可以用来表示云数据库的当前状态,例如在一段时间内从磁盘读取或写入页面的计数器.
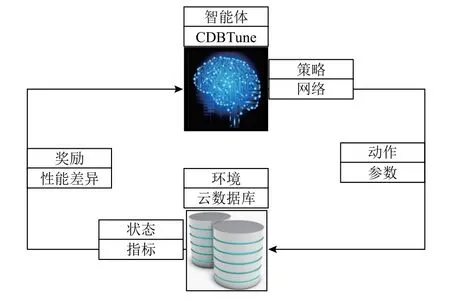
Fig.3 The correspondence between reinforcement learning elements and parameter tuning[50]图3 强化学习元素与参数优化的对应关系[50]
4)奖励.奖励是一个标量,表示当前时刻的性能与前一时刻或初始设置时的性能差异,即在云数据库执行当前时刻CDBTune 推荐的新参数配置后产生的性能变化.
5)动作.动作来自参数配置空间,相当于参数调节操作.云数据库在相应的状态下根据最新的政策执行对应的动作.1 次动作代表1 次增加或减少所有可调参数值.
6)策略.策略定义了CDBTune 在特定时间和环境中的行为,它是从状态到动作的映射.给定一个云数据库状态,如果一个动作(即参数调优)被调用,策略通过在原始状态上应用该动作来维持下一个状态.这里的策略指的是深度神经网络,它保存输入(数据库状态)、输出(参数)和不同状态之间的转换.强化学习的目标是学习最佳策略.
强化学习工作过程中,云数据库是目标调优系统,可以被视为强化学习的环境.CDBTune 中的深度强化学习模型则是强化学习中的智能体,主要由深度神经网络(策略)组成,其输入是数据库状态,输出是状态对应的推荐参数配置.
当CDBTune 系统收到用户的在线调优请求后,首先会从用户处收集查询工作负载,获取当前参数配置并执行获取对应性能;然后使用离线训练的模型进行在线参数优化;最后给出参数配置.若优化过程终止,系统还会更新强化学习模型和内存池.
此外,Li 等人[51]提出了一种基于深度强化学习的查询感知数据库参数调优系统QTune.QTune 考虑了SQL 查询的丰富特性(包括查询类型和查询成本等),并将查询特性提供给深度强化学习模型,从而动态选择合适的参数配置.与传统的深度强化学习方法不同[54-55],QTune 采用了一种使用Actor-Critic 网络的双态深度确定性策略梯度(double-state deep deterministic policy gradient,DS-DDPG)模 型.DSDDPG 模型可以根据数据库状态和查询信息自动学习Actor-Critic 策略来解决调优问题.此外,QTune 提供了3 种数据库调优粒度:1)查询级调优;2)工作负载级调优;3)集群级调优.查询级调优为每个SQL查询搜索良好的参数配置,这种方法可以实现低时延,但由于不能并行运行SQL 查询,吞吐量较低.工作负载级调优能够为查询工作负载推荐良好的参数配置,这种方法可以实现高吞吐量,但不能为每个SQL查询找到良好的参数配置,因此时延较高.集群级调优则将查询进行聚类分组,并为每个组中的查询找到良好的数据库参数配置.为了实现查询聚类,QTune采用了一种基于深度学习的查询聚类方法,能够根据查询所适用参数配置的相似性对查询进行分类.这种方法可以实现高吞吐量和低时延,因为它可以为一组查询找到良好的参数配置,并在每个组中并行运行查询.因此,QTune 可以根据给定的需求在时延和吞吐量之间进行权衡,并同时提供粗粒度和细粒度调优.
在深度强化学习技术的支持下,CDBTune 和QTune 这类基于深度强化学习的参数优化方法能够高效地完成数据库参数优化任务,同时不需要大量的有标签数据.其中CDBTune 可用于云数据库,支持粗粒度的参数优化(例如工作负载级别的参数优化),但不能提供细粒度的参数优化(例如查询级别的参数优化).Qtune 能够提供不同粒度的调优,但目前仍基于单机数据库,没有解决在分布式集群上为多个数据库实例进行参数优化的问题[6].
3 变化环境下的数据库参数优化方法
针对数据库参数优化问题,研究人员进行了一系列工作来试图理解配置参数与系统性能之间的关系,并进一步推荐好的参数配置.然而,现有的方法通常关注于固定的环境,得到的最优参数配置也是针对某一特定环境的.如果这些环境因素中的任何一个发生改变时,就必须重新进行参数优化.这就意味着在当环境发生变化时,在之前环境中进行参数调优中花费的精力不能重用,必须从头进行新的参数优化任务,这将造成巨大的资源和时间浪费.例如,基于传统机器学习的数据库参数优化方法中往往需要建立一个性能预测模型,并利用该模型寻优.在实际系统中,由于环境的改变,之前的性能预测模型往往不再有效,因此需要建立新的性能预测模型以满足数据库系统管理的需求.然而,机器学习方法对样本的高要求和用户对快速获得新系统性能预测模型的需求产生了矛盾.构建良好的系统性能预测模型往往需要大量的样本,但是收集样本需要大量的时间成本,这使得新环境下的系统性能预测模型建立费时又费力.
为了避免上述问题,研究人员将迁移学习的概念引入到数据库系统的参数优化中.利用其他环境中的知识(例如性能度量样本或性能预测模型)来辅助进行性能建模和优化任务,已成为近年来的研究热点.目前关于这一问题的研究工作相对较少,其中一些研究工作集中于应对3 类环境变化中的某一种,也有一部分研究工作可应用于多种不同的环境变化场景中,如表2 所示.本文对这些研究工作进行分类介绍.
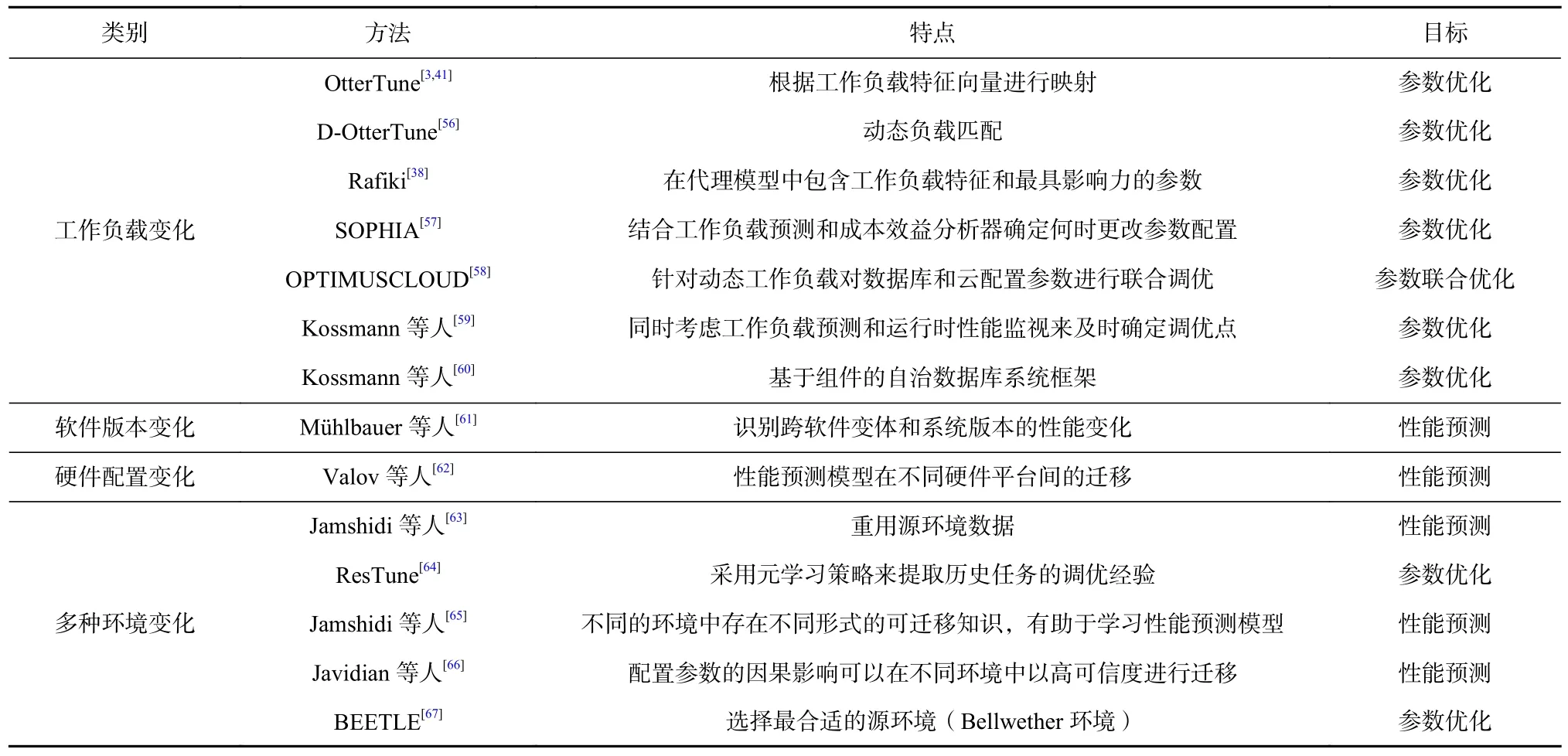
Table 2 Parameter Tuning and Performance Prediction Approaches for Database Systems Under Environmental Changes表2 变化环境下的数据库系统参数优化与性能预测方法
3.1 针对工作负载变化的参数优化方法
工作负载的变化将对配置参数与系统性能的关系产生影响,进而对参数优化的结果产生影响[38,41,57].一方面,配置参数的选择可以对系统性能产生较大的影响;另一方面,在不同的工作负载条件下,配置参数对系统性能产生的影响会发生较大的改变.当工作负载变化后,如果继续采用在之前工作负载下选定的最优参数配置,可能会造成较大的性能下降.因此,自动参数优化方法需要根据工作负载的变化调整数据库的参数配置推荐,从而达到最优的性能表现.
为了重用过去参数优化的经验,OtterTune[3,41]筛选部分运行时统计信息来描述工作负载,并根据工作负载特征向量之间的欧氏距离,将目标工作负载映射到一个之前进行过参数调优且相似性较高的工作负载.然后,OtterTune 重用类似工作负载中的数据来训练高斯过程模型,并通过添加来自目标工作负载的性能度量样本来更新模型.在这个过程中,OtterTune 可以降低为新工作负载进行参数优化所需要的时间和资源.
针对OtterTune 等自动参数调优方法中采用的静态负载描述不够准确的问题,沈忱等人[56]提出了一种动态负载的时序描述方式和动态负载匹配算法.首先通过动态负载描述方法来更准确地刻画负载变化;然后,对于负载匹配中序列不规则、欧氏距离算法不再适用等问题,基于动态时间规整算法提出了一种使用数据对齐思想的动态负载匹配算法;最后,将所提出的方法应用于OtterTune 中,形成了基于动态负载的调优工具D-OtterTune.
Rafiki[38]是一个能够在动态工作负载下实现数据库参数优化的中间件.Rafiki 将待优化数据库系统视为黑盒,通过与OtterTune 类似的工作流程进行参数推荐.首先,通过ANOVA 从所有参数集合中识别关键参数,以便减少计算复杂度和模型训练的数据收集开销;其次,训练神经网络作为代理模型来预测数据库吞吐量;最后,基于代理模型通过遗传算法进行参数优化,从而最大化系统性能.文献[3,41,56]所述的方法能够适用于各种类型的数据库,但考虑到非关系型数据库能够更好地满足高性能计算应用中海量半结构化数据的存储和分析需求,该研究选取非关系型数据库作为研究对象进行了深入探究.为了应对动态工作负载变化,Rafiki 在代理模型中直接包含了工作负载特征和最具影响力的参数,这种方式可以通过参数配置的较大变化来快速地应对工作负载的较大变化.当工作负载发生变化时,应用Rafiki 提供参数推荐进行重新配置需要同时关闭所有服务器实例,更改它们的参数配置,并重新启动所有服务器实例.
虽然Rafiki 可以为静态工作负载自动识别接近最优的配置,但忽略了3 个问题:1)在重新配置过程中,数据库重新启动会造成性能下降;2)需要预测新的工作负载模式持续的时间;3)在重新配置期间是否能够满足应用程序的可用性需求.SOPHIA[57]通过结合工作负载预测和成本效益分析器的优化技术来解决上述3 个问题.SOPHIA 计算每个重新配置步骤的相对成本和收益,并为未来的时间窗确定一个最佳的参数配置.该方法能够指定何时更改参数配置,以及更改的参数和其相应数值,从而在不降低数据可用性的情况下获得最佳性能.
SOPHIA 针对集群非关系型数据库进行数据库配置参数优化,能够处理动态工作负载.然而SOPHIA的设计只关注参数优化调优,没有考虑云虚拟机(virtual machine,VM)配置,以及VM 和数据库配置之间的依赖关系.OPTIMUSCLOUD[58]考虑了数据库级和VM 配置之间的依赖关系,针对动态工作负载对数据库和云配置参数进行联合调优.OPTIMUSCLOUD将性能模型与工作负载预测器和成本效益分析器结合起来,当工作负载发生较大变化时将采用新配置,并决定应该重新配置哪些服务器.首先,OPTIMUSCLOUD 使用待调优数据库的历史数据来训练工作负载预测模型.其次,训练第1 个基于随机森林(RF)的性能预测模型,能够预测任意给定配置参数集(包括数据库和VM)下单个服务器的性能.之后,训练第2 个RF 模型作为集群级别的性能预测模型来预测异构服务器集群的吞吐量.最后,在线阶段中,OPTIMUSCLOUD 优化器利用上述预测模型来评估不同VM/应用程序配置的适用性,搜索最佳配置,在给定的预算内提供最佳性能.
Kossmann 等人[59]提出了一种自管理数据库系统,通过同时考虑工作负载预测和运行时性能监视来及时确定调优点.一旦调整了配置参数,之前的配置参数实例就被存储起来,以便为过去的决策建立反馈循环,帮助从过去的自管理决策中学习.Kossmann 等人[60]还提出了一种基于组件的自治数据库系统框架,自治数据库系统需要自动调整其物理设计和配置,因此面临多方面的挑战:系统必须预测未来的工作负载,有效地找到健壮的配置,并不断从决策中学习知识并应用于之后的决策中.该框架通过关注点分离,以低开销实现数据库集成和自管理功能的开发,并通过一种基于线性规划的算法为多个相互依赖参数的优化提供有效的调优命令.
3.2 针对软件版本变化的性能预测方法
Mühlbauer 等人[61]将软件配置和版本变化2 个视角结合在一起,提出一种可以识别跨软件变体和系统版本的性能变化的方法.通过迭代地对配置和版本进行采样并测量各自的性能,不断更新性能变化可能性模型,从而实现对可配置软件系统的性能变化进行回顾性检测,并将其定位到特定的选项或交互.
3.3 针对硬件配置变化的性能预测方法
Valov 等人[62]研究了如何利用迁移学习来增强系统性能预测模型的通用性.性能预测模型在不同硬件平台间的迁移主要分为3 个步骤:1)性能预测模型的训练,采用分类与回归树构建性能预测模型;2)线性迁移模型的训练,通过简单的线性回归模型将知识从相关环境转移到目标环境;3)预测结果的迁移.
3.4 针对多种环境变化的参数优化方法
与文献[62]所述的直接迁移模型的方法不同,目前还有另一种重用源环境数据的方法DataReuseTL[63],该方法通过高斯过程模型等学习器来捕获不同环境之间的相关性.DataReuseTL 只需要从目标环境中采样少量样本,并通过其他相关环境的样本学习到准确的性能模型,并进一步调优.该方法涵盖了不同类型的环境变化场景,包括工作负载、硬件环境和数据集的变化.
ResTune[64]将面向资源的数据库参数优化问题定义为一个约束贝叶斯优化问题.为了加速优化过程,ResTune 采用一种元学习策略来提取历史任务的调优经验,通过多个模型(基学习器)来表示先验知识,并通过一个集成模型(元学习器)来有效联合利用过往的调优经验.元学习器通过元特征和模型预测来衡量各个基学习器对目标工作负载的有用性.通过这种方式,ResTune 可以相应地利用现有数据并加速参数优化过程.该方法可以在不同的工作负载和异构的硬件环境中迁移知识.
近年来的研究表明,迁移学习可以通过跨环境迁移关于性能表现的知识,来降低在目标环境中构建性能预测模型的成本.然而,值得探讨的是迁移学习为何有效,以及何时对性能建模任务有效.Jamshidi等人[65]使用了多种统计和机器学习技术对这一问题进行研究,并得出关键结论:在不同的环境中存在不同形式的可迁移知识,这有助于性能预测模型的学习.在较小的环境变化中,迁移学习可以采用简单的线性形式;而对于较大的环境变化,可迁移的知识可以用于更有效的采样.
在文献[65]所述的探索性分析的基础上,Javidian等人[66]利用因果分析来识别迁移学习可用的关键知识内容.因果分析证实配置参数的因果影响可以在不同环境中以高可信度进行迁移.文献[65-66]的2个研究工作都可以为性能预测的知识迁移提供新的见解,这些见解有助于在跨环境条件(工作负载、硬件和软件版本改变)下快速且低成本地学习到更准确的性能模型.
此外,迁移学习仅在源环境与目标环境相似的情况下才有效.因此,BEETLE[67]研究了从何处进行学习的问题.首先,通过竞赛算法对候选环境进行顺序评估,确定哪一个可用环境最适合作为源环境,即Bellwether 环境.一旦确定了Bellwether 环境,就可以通过重用源环境的性能度量样本来构建目标环境预测模型,并基于该模型寻找目标环境中的最优参数配置.该研究考虑了3 种环境变化场景:工作负载、硬件环境和软件版本变化.
目前环境变化下的数据库参数优化方法中,针对工作负载变化的参数优化方法研究较多,主要研究了如何在工作负载变化场景下动态进行最优参数推荐[3,38],以及讨论何时进行上述操作的研究[58-59].然而,针对软件版本变化、硬件配置变化以及多种环境变化场景的参数优化还有待进一步研究,现存的研究着重关注这些环境变化下软件系统性能模型之间存在的关联性和可迁移知识,并试图通过迁移学习利用不同环境间存在的可迁移知识来加速新环境下性能预测模型的建立,为下一步的参数优化工作奠定基础.针对环境变化的性能预测研究均适用于数据库管理系统,并通过实验进行了验证.
4 研究现状总结
数据库管理系统有大量配置参数,这些参数控制了系统的内存分配、I/O 优化、备份与恢复等诸多方面,对数据库的性能具有极大影响.因此这些参数需要进行优化以提升系统性能.但是由于数据库配置参数数量众多,而且不标准(即不同数据库系统对同一个参数设置使用不同的名称)、不独立(即更改1 项参数会影响其他参数的效果)、且不通用(即最佳配置取决于目标环境),所以对参数进行优化十分困难.随着数据库和应用程序的规模和复杂性的不断增长,手动配置系统参数来满足应用程序的需求己经超过了DBA 的能力.此外,调优得到的最优参数配置是特定于工作环境的,如果环境发生了改变,就必须重新进行参数调优过程.目前工业界和学术界针对数据库参数优化问题进行了大量相关研究,这些研究工作通过不同的方法解决这些问题,一些工作试图在不同参数配置下准确预测系统的性能,还有一些工作尝试在不同场景下找到接近最优的参数配置.
本文对这些研究工作进行了对比总结,根据不同的应用场景分为固定环境下的数据库参数优化方法和变化环境下的数据库参数优化方法.目前大量的研究工作主要集中于固定环境下的数据库参数优化方法,对变化环境下的数据库参数优化方法的研究工作相对较少,并且不够深入.其中,固定环境下的数据库参数优化方法分为传统的参数优化方法和基于机器学习的参数优化方法2 类,并针对不同类别进行介绍;变化环境下的数据库参数优化方法则根据不同的环境变化场景进行分类介绍.
本文通过对比分析,对每种方法的优势和不足进行了总结.在6 种固定环境下的数据库参数优化方法中:1)手工参数优化方法能够在一定程度上解决参数优化问题,但会产生大量的人力、资源成本开销;2)基于规则的参数优化方法可以进行辅助决策,易于实现部分参数优化,然而该方法不具有通用性,且仅能优化少量特定的参数;3)基于模型的参数优化方法在部分场景下具有良好的准确性,但需要深入了解系统内部结构,构建好的模型也不具有复用性;4)基于搜索的参数优化方法无需深入系统内部,是一种适应性较强的方法,但是由于无法利用过往的调优经验,优化效果通常不佳;5)基于传统机器学习的参数优化方法也无需深入了解系统内部,通过对系统性能的实际观察进行学习,但它的缺点是机器学习方法需要大规模高质量的训练集,此外,该方法采用管道式优化框架,每一步的效果都会对后续优化过程产生影响;6)基于深度强化学习的参数优化优化需要适应环境的动态变化性.本文对各种方法在3 种不同维度的能力进行了评估,包括处理复杂参数空间的能力、对样本的需求和不同工作环境下的动态变化性,如表3 所示.例如,基于传统机器学习的参数优化方法处理复杂参数空间的能力中等,对样本的需求量较大,在不同工作环境下的动态变化性较差;而变化环境下的参数优化方法处理复杂参数空间的能力较强,对样本的需求中等,在不同工作环境下具有较高的动态变化性.方法则对样本的需求量较小,可实现端到端的参数优化,但是训练时间较长;7)变化环境下的数据库参数优化方法能够适应动态运行环境,并且利用其他环境下参数优化的经验,然而这类方法目前的研究不足,且只适用于长时间运行的查询/应用程序.
针对数据库参数优化的三大挑战包括:1)参数数量、种类较多且存在依赖关系导致的参数空间复杂性;2)收集样本数据成本高昂且耗时导致的样本不足;3)最优参数配置在不同环境下并不通用,参数

Table 3 Comparative Evaluation of the Various Approaches for Parameter Tuning表3 各种参数优化方法的对比评估
除了将各类参数优化方法在应对数据库参数优化三大挑战时的能力进行对比之外,本文根据每种方法的优缺点及目前研究工作中展示的实验结果[3,50-51,64],对各种参数优化方法的精确性和通用性进行了对比分析,结果如表3 所示.
1)手工参数优化方法虽然能够获得不错的优化效果,但对专家知识的要求非常高,不仅会耗费大量的人力、资源成本,也需要提供大量时间给DBA 来进行不断试错以达到预期的系统性能优化效果.因此,实现自动参数优化是未来数据库参数优化发展的必然趋势.
2)基于规则的参数优化方法精确性和通用性都较差,可以用于帮助用户根据专家经验、在线教程或参数优化说明进行参数优化辅助决策.
3)基于模型的参数优化方法也对专家知识有较高的需求,对性能样本的需求较低.这类方法在特定场景下具有良好的精确性,是目前在实际工程中大量应用的方法,但通用性较差,对于不同的数据库类型或应用场景都需要重新构建模型.
4)基于搜索的参数优化方法无需对数据库系统深入理解,通用性较强.然而,由于需要多次实际运行,该方法比较耗时,且难以利用优化过程中已有的知识和规律,优化效果有待提升.
5)基于传统机器学习的参数优化方法也视数据库系统为黑盒,具有较强的通用性,且具有从历史任务中学习的能力.然而,这种方法对训练样本的质量和数量都有较高的要求,优化效果会因训练样本的差异和方法的管道式框架而不稳定.基于搜索的方法和基于传统机器学习的方法更适合对系统内部没有深入了解的用户使用,为了获得更好的调优效果,应允许多次实际运行系统以搜索最优解或收集训练样本.
6)基于深度强化学习的参数优化方法引入了功能更为强大的深度强化学习,降低了对样本的需求,获得更优的优化效果,且对环境的变化具有一定的适应能力.然而,该方法训练时间较长,且需要获取内部指标来表示数据库的当前状态,因此通用性较上面2 种黑盒优化方法稍弱.
7)变化环境下的数据库参数优化方法能够迁移其他环境中的性能优化知识来帮助进行性能建模和优化任务,在降低样本需求的同时提升了精确性.但是使用该方法的前提是已有其他环境中参数优化经验的记录,例如性能度量样本或性能预测模型,否则算法将面临冷启动问题.
不同参数优化算法的适用场合应该综合考虑表3中5 个维度的表现进行选择,重点是动态变化性和通用性2 个方面.其中,动态变化性用于衡量一个参数优化算法在某一特定的数据库系统中是否具有适应环境的改变的能力;而通用性则表示该参数优化算法在不同的数据库系统中是否具有普适性.
5 未来研究方向与挑战
针对数据库参数优化问题,目前的研究成果还存在诸多不足,不能有效指导参数优化过程.归纳起来,主要的研究方向与挑战有3 个方面:
1)基于机器学习的数据库参数优化
在机器学习蓬勃发展的背景下,将机器学习应用于数据库系统中来改进系统性能是目前的研究热点之一.通过对现有研究工作进行分析,可以看出基于机器学习的数据库系统参数优化方法的研究力度最大,是目前的主流研究方向.然而机器学习方法对样本数量和质量有较高的要求,这在实际应用场景中是难以提供的.
针对样本数量有限这一问题,基于机器学习的参数优化工作可以从2 个角度进行解决.首先是研究如何对数据库系统的高维参数空间进行自动降维,包括高效的参数选择和采样方法,以较低成本构建少量的、能够有效刻画系统性能分布的高质量样本,为基于机器学习的数据库参数优化方法提供有效的支撑与保障.同时,如何在少量样本情况下对系统进行性能建模与参数优化还需要进行系统性研究.一方面,通过学习能力强的模型对少量样本提供的先验知识进行学习和利用,进一步提升优化效率;另一方面,考虑引入迁移学习的概念,利用其他环境性能建模或参数优化取得的经验,来帮助在新环境中通过少量样本进行建模或优化工作.这种方法不仅能帮助解决样本数量有限的问题,还能在变化环境的场景下进行参数优化,适用于动态运行环境.
2)基于迁移学习的数据库参数优化
大数据时代下,随着数据库系统更多地部署在云服务器中,工作负载的规模不断增大,工作负载的类型也不断丰富,异构性突出.工作负载的快速变化及其多样性要求数据库系统能够智能且动态地调整系统参数以达到最佳运行时状态.在云环境下,计算和存储资源可以视为是无限的,理论上数据库系统可以立即执行对资源的配置,进行灵活地缩减或扩张.针对不同的预算、应用和负载特性等,人们往往会为数据库配置不同的硬件环境和软件版本.而不同的硬件环境和软件版本将对参数优化的实际表现产生很大的影响.例如,很多参数与硬件强相关,且随着版本变迁会增减,参数的取值范围也会有一定差异.在这种情况下,传统的固定环境下的数据库参数优化已不能处理新应用场景下对系统性能的优化.当环境发生变化时,现有的样本、系统性能模型和优化参数配置均会失效.在这种情况下,如何利用现有的优化知识,快速生成针对新环境的性能预测模型和优化参数配置是亟待解决的一个重要问题.
针对这一问题,Jamshidi 等人[65]对可配置系统在环境变化场景下系统性能模型的变化情况进行了初步研究,经过大量实验发现,对于较小的环境改变,可以直接对现有的预测模型进行线性变换调整,而对于较为剧烈的环境变化,在源域和目标域之间仍然可以进行一定的知识迁移.经过调研现有研究工作可知,迁移学习方法在系统性能建模和参数优化方面是有效的,值得深入研究,但现有的相关研究工作数量还很少,研究不成熟,尚未有效解决该问题.因此,通过基于迁移学习思想的数据库参数优化方法在发生环境变化时充分利用现有系统的优化知识,是未来的一个重要研究方向.
3)自治数据库
由于数据库的性能受到多个参数的共同影响,再加上可调参数数量、数据库体量和业务量的剧增,导致传统的参数优化方法无法再满足用户的需求.随着自治数据库技术的发展,自适应的数据库参数调优技术成为了解决这一难题的主要方法之一.
Pavlo 等人[68]认为真正的自治DBMS 需要具备3 种能力:
①自动选择进行何种操作以改进某项性能指标,如吞吐量、时延、成本.上述的操作主要包括改变数据库的物理设计、改变DBMS 的参数配置,或改变DBMS 的物理资源.该选择还需要考虑进行这一操作产生的资源消耗.
② 自动选择何时进行这些操作.
③从上述行为中自动学习,并在没有人工干预的情况下将过去决策的知识纳入未来决策.
目前大多数的研究工作都专注于解决第1 个问题,也有一些工作试图解决第2 个问题的一部分,但几乎没有最后一个问题的工作.这也正是自治DBMS最为困难的一个要求,DBMS 必须知道何时部署某一操作,以及这个操作是否有帮助.这就要求系统必须能够预测未来的工作负载,并进行相应的计划.目前的自治数据库系统由于预测能力不足,通常是在问题发生后才做出反应,这种情况类似于一辆只能查看身后道路的自动驾驶汽车.然而,实现预测最大的挑战在于环境在不断发生变化,例如:硬件会根据操作而改变,工作负载也会随着时间发生变化.
对应到自适应的数据库参数调优问题,根据历史负载信息,预测工作负载未来的变化趋势是动态调优数据库配置参数的基础.根据预测信息,可以选择适应当前环境的最优数据库参数配置,并确定如何进行重新配置操作,从而保持或提升系统性能.这一过程中比较困难的问题是如何确定一次行动(即一次参数调整)的性能收益.这是由于环境不断发生变化,因此必须研究如何从性能监测中分离出该调整产生的性能影响.最后,从上述根据预测进行调整的行动中进行学习,并将从过去决策中学习的知识应用于未来的决策之中.通过这些研究可以提高数据库系统的易用性,使得数据库系统面对多样的环境变化能够更加智能地动态调整数据库系统的参数配置,实现数据库系统的自动化.
6 总结
本文对数据库参数优化方法的研究现状进行了综述.首先对背景知识和研究问题进行了介绍,并给出数据库参数优化问题所面临的挑战;然后对现有参数优化方法进行分类介绍.从问题层面出发,根据参数优化过程是否涉及环境变化,将现有工作分为固定环境下的参数优化方法和变化环境下的参数优化方法2 类,介绍现有方法如何解决数据库参数优化问题.在固定环境下的数据库参数优化方面,根据方法本身是否有从历史任务中学习的能力,将现有方法分为传统的参数优化方法和基于机器学习的参数优化方法2 类.其中,传统的参数优化方法可细分为手工参数优化方法、基于规则的参数优化方法、基于模型的参数优化方法和基于搜索的参数优化方法;基于机器学习的参数优化方法可通过使用的机器学习技术进一步分为基于传统机器学习的参数优化方法和基于深度强化学习的参数优化方法.在变化环境下的数据库参数优化方面,本文根据每个方法应对的变化场景,将现有工作分为针对工作负载变化、针对软件版本变化、针对硬件变化和针对多种环境变化4 个场景进行讨论.最后,本文对研究现状进行总结,对比分析了各种方法的优势和不足,并给出了未来的研究方向与挑战.
作者贡献声明:曹蓉负责相关文献资料的收集、分析和论文初稿的撰写;鲍亮提出综述思路并指导写作;崔江涛提出整体指导意见并修改论文;李辉针对研究现状总结与讨论提出指导意见并修改论文;周恒针对未来研究方向与挑战提出指导意见并修改论文.
猜你喜欢
家庭影院技术(2019年8期)2019-08-27
电子测试(2018年14期)2018-09-26
制造技术与机床(2017年4期)2017-06-22
财经(2017年2期)2017-03-10
电信科学(2016年10期)2016-11-23
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
财经(2016年6期)2016-02-24
核科学与工程(2016年3期)2016-01-03
燕山大学学报(2015年4期)2015-12-25
