
大运维体系浙江建设实践
2023-03-27 09:57数字浙江技术运营有限公司大运维业务负责人王森
中国信息化 2023年2期
文 |数字浙江技术运营有限公司大运维业务负责人 王森
随着数字化进程向纵深推进,以“综合集成、多跨协同、多方参与”为特征的“大平台”“大应用”形态不断涌现,复杂巨系统内系统模块相互引用,运行环境相互依赖造成的系统脆弱性愈加凸显。传统分散、割裂的运维服务已无法满足新时代数字化转型的需要,亟待解决三大类问题:一是运维组织管理不在线。各系统开发商散落在不同建设单位且不在线,需将跨厂商、跨系统、跨业务的运维工作连成网,首先需实现组织在线;二是规划阶段运维空缺。面临复杂多样的部署架构、技术栈选型,运维需从规划阶段就介入,从而实现覆盖规划、建设、运营运维的全周期运维管理;三是数字化运维工具欠缺。目前各运维工具和运维要素分散在各建设方,当系统出现不可用情形时无法实现运维要素“一张图”汇聚、运行态势即时感知,需依托数字化运维工具建设,提升事前预警与应急处置预案能力,实现运维工作的全方位、自动化、智能化。
一、定义
所谓“大运维”,是指基于“数字孪生、未雨绸缪、态势感知、全链快响”理念,构建多跨协同的大运维体系,实现运维工作“整体、健康、智治”。
“数字浙江”建设经历了“最多跑一次”改革、政府数字化转型以及数字化改革等多个阶段。初期运维工作较为独立、离散,部分系统应用采用自主更新维护方式或委托第三方公司施行运维,各自系统运维体系相对独立,包括架构、组织、技术、指标与标准等,一般而言只需基本满足单系统应用运维需求即可。自2018年以来,为有效推动党建统领、经济发展、便民惠企、市场监管、应急管理等领域治理能力提升,重大应用综合集成程度大大提升,多方参与、场景多跨的平台与应用涌现,众多系统之间相互嵌套,风险触发因素愈发复杂,建设一套整体运维体系的意识逐步形成,因此适应新阶段、满足新要求的大运维体系应运而生。
大运维主要包含三个特点:一是整体,将人员构成复杂的运维团队打造成一支整体队伍,执行统一的运维标准规范,运维目标一致,效能评价标准统一;二是健康,通过定义健康指标体系,“运维体检”预测并整改风险,建立检查清单、监测工具,实现对效率、效能等运维态势的全局监测,及时发现并处置故障,保障业务安全稳定;三是智治,基于本体建模和知识建模,对各类运维主体进行数字孪生,通过智能规则配置、风险识别、任务流转、考核评价等服务,掌握当下状态,知晓未来趋势。
二、方法步骤
“大运维”建设总体思路要做好“三段三责”。首先,从架构、设计、开发阶段就要围绕稳定性、安全性做好明确的转维规范清单,不能让应用、系统带“病”进场;其次,测试阶段从性能、功能以及漏洞扫描等方面要把“病”检查出来,推动整改,消除风险;再次,生产阶段则要对所有的生产环境、资产、人员、行为等各类对象情况清晰掌握,一旦“流血”则快速“止血”。三段主体都要推动对事件、风险的举一反三,从制度、技术、能力上进行全面整改,才能全链路确保稳定、安全。
大运维体系按照“组织、制度、流程、评价、工具”一体化建设理念,以“一屏、一仓、N工具”为总体架构,建设运维大脑(DMS),统筹环境管理,融合运维要素,集成专家知识,强化态势研判,精准问题定因,为运维人员提供全方位、智能化的运维管理工具,实现“数字孪生、未雨绸缪、态势感知、全链快响”。
依据大运维的业务属性,下面按照平时和战时两条业务主线展开介绍(见图1)。

图1 大运维一体化建设理念
(一)平时做好健康管理
大运维平时业务的核心在于做好健康管理,强化上线前的规定动作,避免系统带“病”上线;做好上线系统的“体检”,保障业务健康稳定。健康管理涉及流程标准、组织保障、制度规范、综合评价、生态管理五个关键环节。
1、建立覆盖重要场景的接入流程:明确大运维、小运维、系统建设、业务单位等4类主体7个角色在运维初始化、系统转维、日常运维、战时处置等阶段的工作要求,提升运维工作规范程度和整体水平。
环境、权限初始化。通过环境管理中心规范应用发布与变更流程,实现对开发、测试、预发、生产环境的准入管理。
资产、日志接入。建设运维对象管理中心,按照统一规范接入应用、服务、组件、数据、云资产等对象要素,建立对象之间的关系,构建动态本体数据仓(见图2)。

图2 运维对象管理
监控配置。建设监控管理中心,依据预警告警规则,采用主动探测、日志监控等技术手段,通过消息订阅,将预警告警结果精准通知相应负责人,推动快速响应及闭环处置(见图3)。
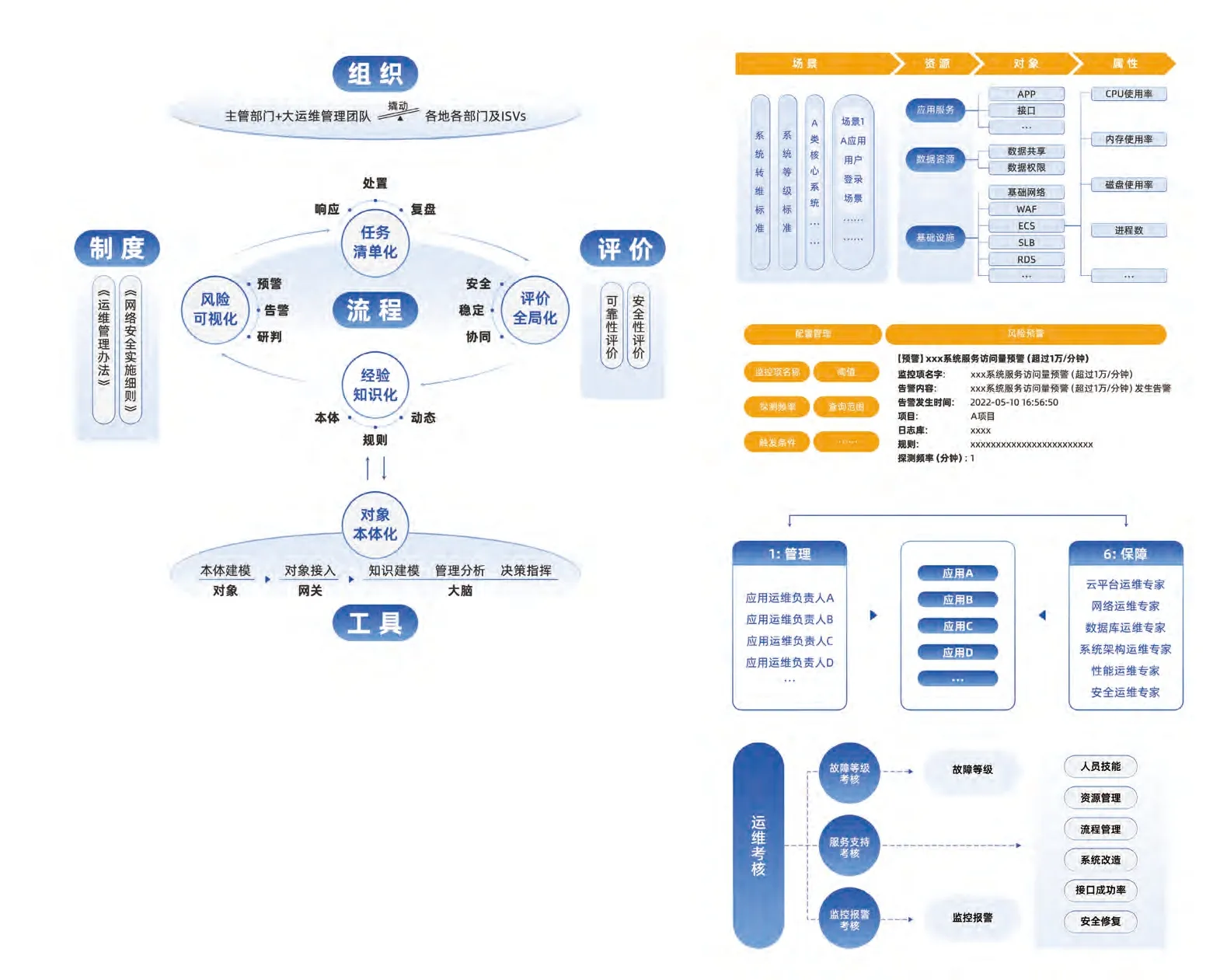
图3 运维监控告警
预案配置。统筹各类预警告警规则和应急预案,通过规则预案管理中心对运维知识进行集中管理,为各类风险提供处置方案,支持监控配置关联预案,指导运维工作高效有序进行,助力应用系统报警项的快速处置。
运维数据分析研判。建设分析研判中心,对应用健康度、预警告警质量、预案执行时效、故障处置效率等多维度进行数据分析,判断运维工作整体效果。
2、建立矩阵式组织保障:以主管单位及大运维管理团队,共同撬动各地各部门和开发商组成“一支队伍”,并在组织中建立“1+6”的矩阵式管理结构。“1”是大应用的应用运维负责人,“6”是平台各领域的运维技术专家,包括云平台、网络、数据库、系统架构、性能、安全六大类。由“1+6”联合各应用开发单位运维人员,共同形成长期保障团队(见图4)。

图4 大运维组织保障
3、建立标准的运维制度规范:围绕工作体系、指标体系、政策体系、评价体系要求,制定运维管理制度规范,形成统一的运维准则,从系统转维、人员管理、变更管理、故障管理、考核管理等方面进行规范管控与闭环管理。
4、建立综合评价机制:建设考核指标体系,通过考核评价中心对已转维的应用进行评价,从监控报警覆盖度、准确率、响应度、系统服务可用度、安全修复及时性及人员技术能力等多维度进行运维服务质量的综合评价,定期对运维服务能力、质量进行考核晾晒,及时发现短板并整改,提升整体运维服务质量(见图5)。

图5 大运维评价体系
5、建立可持续发展的生态管理机制:通过开发商管理中心对所有应用系统的开发商进行编目,并对相关人员进行动态管理,实现开发商单位、人员与应用系统的关联,确保风险处理时的组织环节无缺口。对开发商开展培训,针对运维工作的开展思路、方法路径、工具使用等进行全方位指导,为开发商提供专业的赋能支撑和工具保障。

(二)战时做好风险应急
大运维战时业务的核心在于做好风险应急,为应急协同开展、故障有效处置提供数字化保障,提高应急处置效率,为业务系统的可用性恢复提供有力支撑。
建立一屏统览的指挥调度中心:通过“数字孪生、态势感知、全链快响、资源优化、综合评价”五大板块,一屏统览整体服务实时运行状态,为运维单位、建设单位、开发单位的各级指挥员提供统筹管理、分析决策、指挥调度的能力。
数字孪生:对基础设施、数据、组件、应用、端运行进行数字孪生,详尽掌握各类资产运行状态,清晰展现故障原因及影响范围(见图6)。
图6 指挥调度大屏数字孪生模块
态势感知:建立动态拓扑关系,生成应用图谱,展示应用间相互调用关系和应用内部各层级资源调用状态,统计当前应用范围的运维质量,实现服务预警告警态势实时感知(见图7)。
全链快响:支持对各类异常风险状态的处置,并在风险发现时快速调度各方主体,第一时间通知责任单位及责任人,并明确责任分工。同时,对风险进行全视角跟踪,支撑指挥员掌控处置进度,响应处置复盘情况实现全程留痕(见图8)。
图8 指挥调度大屏全链快响模块
资源优化:聚焦CPU、内存、存储等要素负载情况,提出相应策略实现资源成本优化(见图9)。

图9 指挥调度大屏资源优化模块
综合评价:制定多维度运维服务核心指标,对各类主体进行综合评价排行,对运维工作成效开展晾晒(见图10)。
图10 指挥调度大屏综合评价模块
2、建立“五快”风险处置中心:针对预警、告警、故障三种风险状况形成任务清单,按照通知与处置双线流程执行风险处置任务并跟踪整改进展。在故障发生时,依据以“故障响应快、应急止血快、原因定位快、故障恢复快、故障复盘快”为核心的“五快”闭环处置模型,明确各环节负责人及责任边界,高效处置故障并形成故障报告(见图11)。

图11 大运维风险处置流程
三、技术创新
业务变革引领技术创新,技术创新驱动业务创新。大运维体系实现了三大技术创新,有效解决了传统运维工作中风险阈值预估不精准、故障范围判断不全面、故障定因分析不高效等典型问题。
一是基于业务变化自动、动态调整各类风险阈值。如浙江省某考试报名期间,“浙里办”日访问量时刻可能激增、告警处置数据持续变动,原先的运维风险阈值、主动探测、日志监控等配置都需要及时调整与管理,针对传统运维方式的这些痛难点、风险点,现在可通过运维大脑(DMS)取代人工手动变更,实现自动化、智能化阈值变更。
二是基于动态协同关系,智能化判断故障影响范围。在复杂巨系统内部互相嵌套、调用关系复杂的情形下,如需判定因法人单点登录服务不可用而影响的系统、应用数量及严重程度,可通过运维大脑(DMS)数据可视化手段,将应用内部的各层级资源和调用关系以数字孪生的形式展现,一目了然,清晰明确(见图12)。
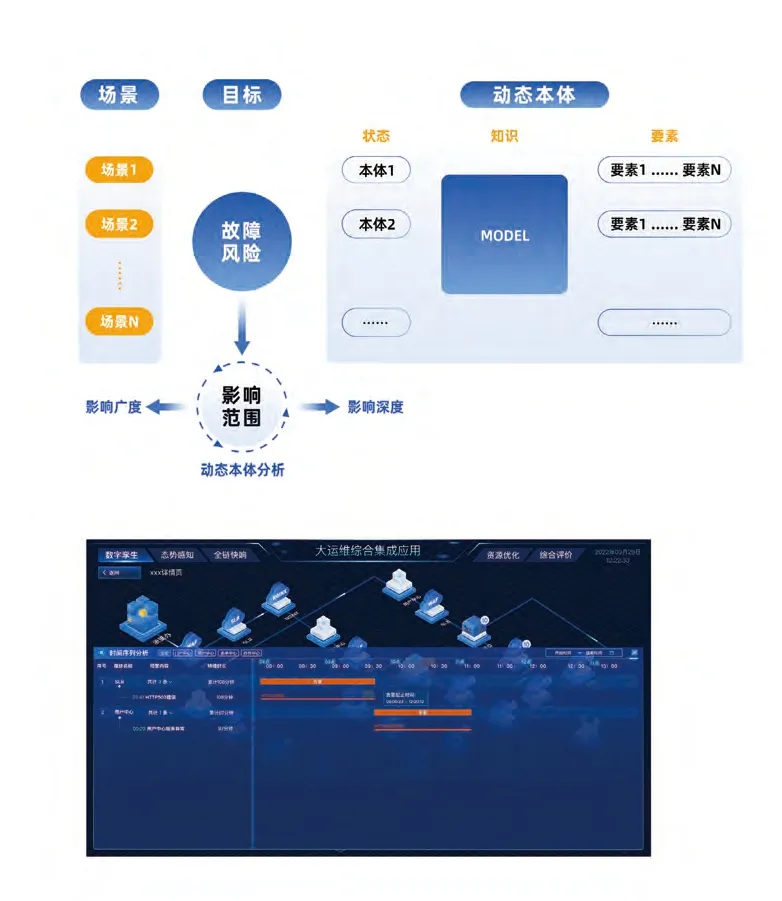
图12 影响范围判断示意图
三是基于时间序列提供快速定因分析服务。发生全局性故障时,在大量压迫性告警中快速找到有价值的线索非常重要。运维大脑(DMS)有效整合碎片化的开发商和运维信息,将故障引发的众多预警信息按模块聚合、按时间排序,找到因果关系从而定位出最先引起问题的“第一片雪花”(见图13)。

图13 告警时间序列示意图
四、结束语
安全是开展一切技术运营工作的基础,是一项贯穿数字化全生命周期的专业服务,要坚持业务与安全并重发展,在业务规划阶段,就审慎考虑系统上线后的可靠性,各个阶段围绕统一思想,落实各自使命职责。通过运维工作浙江实践,大运维体系可对海量运维数据进行融合建模与智能分析,实现要素多维接入、知识动态管理、预警全面覆盖、问题精准定位、评价客观真实、故障举一反三,有效保障大平台、大应用安全健康运行。本文总结的大运维体系建设方法及浙江实践,积极践行落实了“三融五跨”系统健康运行的要求,可为数字化运维管理者提供参考借鉴。
猜你喜欢
红领巾·成长(2022年6期)2022-07-23
青年歌声(2020年1期)2020-01-14
汽车维修与保养(2019年7期)2020-01-06
中国交通信息化(2019年5期)2019-08-30
能源(2018年8期)2018-09-21
能源(2017年11期)2017-12-13
汽车维护与修理(2016年10期)2016-07-10
现代工业经济和信息化(2016年8期)2016-05-17
汽车维修与保养(2015年6期)2015-04-17
汽车维护与修理(2015年2期)2015-02-28
