
基于知识图谱WordNet实现多数据集合并及其在YOLO9000中的应用
2023-03-24 14:35褚云飞陈业红吴朝军
电脑知识与技术 2023年4期
褚云飞 陈业红 吴朝军
关键词:WordNet;WordTree;深度学习;目标检测;YOLO9000;Softmax
1 概述
在如今的生活中,人脸识别、自动驾驶、车辆检测、行人检测等视觉技术早已得到了普遍应用,为人们众多工作生活带来了便利。这些检测识别技术背后依靠的是目标检测算法的产生和发展。社会生活要求目标检测系统足够快速、足够准确、有足够的能力检测更多对象。从传统到深度学习,目标检测算法不断地更新换代,不断改进先前的不足并提出更加强大和富有创意的方法。
2014年,Ross Girshick极具创造性地提出Region-CNN算法,目标检测的实现从此拥有了卷积神经网络(CNN) 的支持,继之以Fast R-CNN、Faster R-CNN,目标检测算法在深度学习的强大动力下不断改进[1-2]。由于R-CNN的网络是two-stage雙阶段结构,也就是将候选区域的检测和分类识别分成两个阶段执行,它的系列算法检测精确度高,但缺点是检测速度慢,无法满足实时性。2016年,Joseph Redmon提出YOLO算法,将候选区域检测和分类识别合为一个,成为Onestage单阶段结构的开山之作,大大提高了目标检测的速度。然而YOLO也有不足之处,与Fast R-CNN等基于Region proposal 的方法相比,YOLO存在更大的定位误差和更低的召回率[3]。为了解决这些问题,一年后,Joseph Redmon 与导师Ali Farhadi 对YOLOv1 进行改进,发表了论文《YOLO9000: Better, Faster, Stron?ger》,也就是YOLOv2,提高了YOLO的召回率,并对目标精确定位改进,同时保持了分类准确性。YOLO9000使用了World Tree整合COCO和ImageNet 数据集,并在其上进行联合训练,能够检测9000多个目标类别,这是联合检测数据集和分类数据集实施共同训练突破数据集瓶颈的重要一步[4]。因此,笔者认为World Tree的构建,在整合数据以识别更多对象的工作中起到了关键作用。众所周知,深度学习的主要局限来自它对训练数据的规模和质量的极高要求,而基于WordTree的数据集合并策略无疑是解决此类问题的一般性方法,所以明晰YOLO中构建WordTree的基本原理和实现方法就具有非常重要的意义。
2 相关工作
2.1 知识图谱工具:WordNet
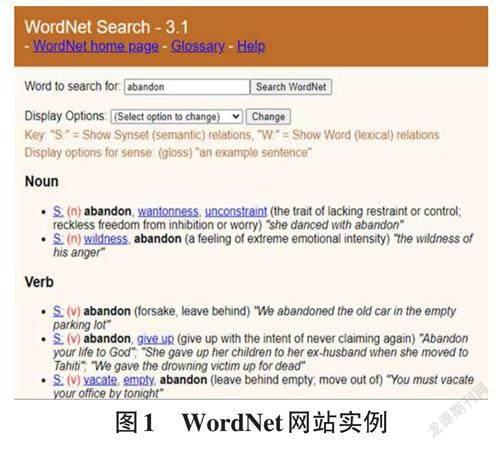
内在的意义类似于一个最常见的依靠语言学整合而成的英语词典,但更加具体的描述在于它还是一种知识谱图应用实例,即这本词典中的所有单词根据它们彼此间的意义联系组成了一个庞大的网络,所以我们常常将WordNet称作“单词的网络”。WordNet不仅提供了每个概念的含义,而且给出了单词的近义词或反义词,同时阐释出一义多词、一词多义、类别归属等问题,使用WordNet的基本功能可以参见文献[5]。作为知识图谱的应用工具,在数据标注上有重要语义作用[6]。图1是WordNet的一个应用网页,在检索栏中输入一个预检索的单词,选择检索的选项(同义、反义,关联等),可以输出相对应的所有单词义集以及例句。
2.2 大型视觉数据库
2.2.1 ImageNet
ImageNet是根据WordNet中的语义关系构建的图像数据集,其不仅数据量大而且带有数据标签。Ima?geNet数据集拥有1500万左右张图片,涉及2.2万类视觉对象。其中有超过103万张图像。ImageNet中虽然图片量大,但是全部经过了人工挑选、整理和标记,带有边框批注,是庞大的基于图像分类的数据集,类似于一个图像引擎[7]。ImageNet依据WordNet具有层次结构的英语词典设计标注名字空间,因而可以描述基于已有知识的不同概念间的语义关系[6]。
2.2.2 VOC
VOC数据集是著名的基于视觉目标检测任务的大型数据集,为目标检测模型监督学习训练提供的标注数据,共涉及20个类别[8]。
2.2.3 COCO
Common Objects in Context数据集可以用来完成图像物体检测、语义分割和字幕生成,主要对目标之间的上下文关系和目标的2维精确定位问题提供数据支持,是最重要的物体检测数据集之一[9]。MicrosoftCOCO是一个大型的数据集,包含有150万个对象实例,80个object类别,91个Stuff类别,超过33万张图片,其中20万张带有标注,分为训练、验证和测试三种数据集。
2.3 Softmax ()多分类输出层
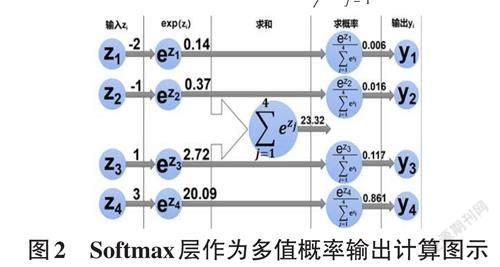
使用跨越所有可能类别的Softmax层来输出最终的目标类别的概率分布,是构造多分类器常使用的方法。Softmax() 函数输出的是每个分类的概率值,而不是输出一个整数的类别编码。通过Softmax() 函数可以将多分类的输出值转换为范围在[0, 1],和为1的概率分布,将多分类的结果以概率形式展示出来。使用Softmax() 要求同组输入Softmax层运算的元素应该是互斥的,结果输出为每个元素的条件概率。在机器学习尤其是深度学习中,Softmax() 函数在多分类的场景中使用广泛[10]。公式(1) 中, Softmax(zi) 表示输出分类类别为i 的概率,其中n为类别总数。
其中,输入的分类特征变量z1,z2,z3经Softmax() 映射为0~1之间的实数y1,y2,y3,y4并且能保证其归一化和为1。
3 为什么要构建Word Tree
图像分类任务一般只要求确定图像包含哪一种类别的目标,而目标检测不仅要确定图像类别,还需要确定目标的位置和大小,由此可见,检测数据集同时包含了分类信息和定位信息。用于检测任务的数据集标注工作代价更大,所以带标注的检测数据集的体量比起面向分类任务的数据集要小很多[11-12]。
YOLO9000若想要检测更多的对象,但缺少对象检测训练的样本,于是联合ImageNet 大量的分类样本和COCO的对象检测数据集一起训练,用仅带有分类标注的数据集来扩展可检测类别的数量,实现对更多种类的图像目标进行定位和分类。YOLO9000同样使用跨所有可能类别的Softmax() 输出层映射目标类别的概率分布,这也是多分类常常使用的方法。最直接的方法可以把ImageNet 中的9000种类别的数据合并到COCO数据集中,并将Soft?max() 分类层改成9000维。然而,通过Softmax函数预测各个类别的概率分布的前提条件是:待检测的类别之间应该是互斥的,即不同输出类别对应的实例集合之间的交集应该是空。然而,ImageNet的对象类别与COCO的对象类别存在大量重叠,并不满足类别互斥的要求。COCO是检测数据集,一般只标注了常见目标而图像分类数据集ImageNet具有更广泛的标签范围。比如COCO数据集中有“貓”这个类别,ImageNet 中同样有此类别,并且又细分多个不同品种的猫,显然猫与不同品种的猫是包含关系,并不相互独立,所以无法用单个Softmax来做对象分类。
YOLO9000作者选择将ImageNet和COCO数据集结合起来共同训练。如何整合数据,需要解决哪些问题以及如何解决这些问题是成功的关键。首先,针对具体实施中遇到的COCO和ImageNet数据集中类别不完全互斥的问题,作者提出了将两个数据集按照一定的框架整合到一起,形成一个具有多层分类结构的方法,即层级分类(Hierarchical classi?fication) 的方法[4]。两个数据集中类别依据的从属关系框架来自Word?Net这个表示单词内部关系的知识图谱工具。最后,解决完所有问题,YOLO9000 的作者根据设想建立出一种树型结构—WordTree,提供能解决标签互斥的多标签标注机制。比如COCO 对象类别有“狗”,而Ima?geNet 细分成100 多个品种的狗,狗与100多个狗的品种是包含关系,而不是互斥关系。一个“Norfolk ter?rier”标签同时也是“dog”,就可以采用“dog”和“Norfolk terrier”两个标签来标注。
YOLO9000没有直接使用Word?Net对图像分类而是重新建立树的结构,原因在于WordNet是一个有向图结构,一种对象可以同时从属于多种属性,比如:dog 既是一种canine (犬),也是一种domestic animal(家畜),它们都是WordNet中的同义词。语言的复杂性限制了数据集训练的可行性,YOLO9000并不使用完整的图结构,而是要通过ImageNet构建分层树来简化问题,使对象间的从属关系直接简洁,方便对象分类。
4 如何构建WorldTree
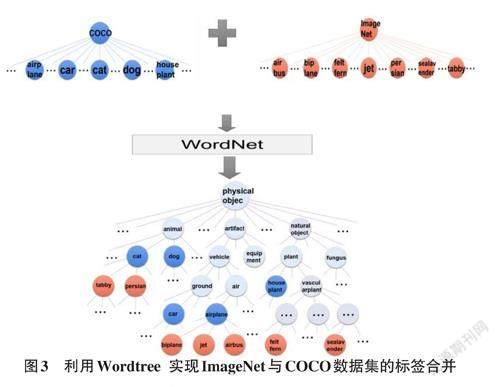
构建好的WordTree有9418个节点(对象类型),包括ImageNet 的Top 9000个对象,COCO 对象,以及ImageNet对象检测挑战数据集中的对象,以及为了添加这些对象,从WordNet路径中提取出的中间对象。结合COCO和ImageNet建立的WordTree如图3所示。World Tree以physical object为根节点,各名词依据相互间的关系构建树枝、树叶,节点间的连接,表达对象概念之间蕴含的上下位关系。
构建World Tree的步骤是:
1) 建立WordTree根节点(Physical object) ;2) 首先检查ImagenNet和COCO中的所有欲加入的对象Oi;3) 然后在WordNet中找Oi到对应的节点Ni;4) 如果该节点Ni 到WordTree 根节点R(Physicalobject) 的路径只有一条,就将该路径以及路径上的所有节点添加到WrodTree,转6(大部分对象都只有一条路径);5) 否则,反复检查路径不唯一的对象所有的想要添加到已有的WordTree的路径长度,从中选择一条尽可能短的路径添加到已有WordTree中,转6;6) 如果所有节点已加入,结束,否则转2。
如图4所示,金毛狗的路径可以是金毛属于狗,狗属于动物,动物属于根节点object;也可以是金毛属于宠物,宠物又同时属于狗和豢养动物,豢养动物和狗都属于动物,最后找到根节点object。找到金毛在WordNet中的三条路径,发现后述两条路径都有四条边,而第一条所述路径有三条边,为最短路径,于是舍弃其他路径,将最短路径加入到已有WordTree中。
依此方法,YOLO2 根据WordNet,将ImageNet 和COCO中的名词对象一起构建了一个WordTree,并且Wordtree中每个对象只有唯一路径连接到根目录。以Physical object为根节点,各名词依据相互间的关系构建树枝、树叶,节点间的连接,表达了对象概念之间蕴含的上位/下位关系。至此,虽然整个WordTree中的对象之间不是互斥的关系,但对于单个节点,属于它的所有子节点之间是互斥关系,这样就可以针对从属于同一层级对象的子节点使用Softmax操作来预测该层级下所有平行类别之间的概率分布。这样使用有限多的softmax函数,就可以实现无线扩展对象的检测。为了评估此方法,还添加了ImageNet检测挑战中未包含的类。最终World Tree中的节点共对应9418个类别。在样本的选取上,由于ImageNet比COCO大得多,所以YOLO9000通过对COCO进行过度采样来平衡数据集,使得ImageNet与COCO采样的比例为4:1。
5 如何利用WorldTree 确定识别对象
在所有对象互斥的情况下,采用softmax() 预测n个类别的对象,输出可以采用n维向量表达,对象被预测到的类别对应的那一维数值接近1,其他维数值接近0。
在World Tree中,采用softmax() 层对对象进行分类的方法是:首先将World Tree中的所属于同一父类的叶子节点以及向上遍历所有可继续细分的属于同一父类的中间节点分组进行线性排列,然后对每一行属于同一父类的对象分别进行softmax() 计算。这样计算得到的是每个节点对象的条件概率,也就是同义词集合中它们的每个下义词预测到的概率。例如:object根节点包含的子节点有动物、人工制品,……,动物包含的子节点有猫、狗,……,狗包含的子节点有金毛、哈士奇、泰迪,……,如图5:
对不同对象求得的各自Softmax 值即为条件概率,例如:对第一层对象求条件概率:Pr(object) =1;对第二层对象求条件概率:Pr(动物|object)=a1,Pr(人工制品|object)=a2,...对第三层对象求条件概率:Pr(猫|动物)=b1,Pr(狗|动物)=b2,...对第四层对象求条件概率:Pr(金毛|狗)=c1,Pr(哈士奇|狗)=c2,Pr(泰迪|狗)=c3,... 对以上计算有:a1+a2+...=1,b1+b2+...=1,c1+c2+c3+...=1,...以此类推,直到叶子结点层。
注意,此处每一个softmax() 得到的分布表达只是边缘分布,求得softmax() 值为在父节点条件下的相对概率。也就是说,每个对象输出的概率值只与和它并列的属于同一父类的所有节点有关,与其父类的父类以及继续向上层遍历的祖先的概率值无关。若需要计算某一节点的绝对分布,只需要计算从该节点到根节点一系列条件概率的连乘积,即其par(node)表示节点node的父节点。
p(nodei) =p(nodei|par(nodei)) ...p(par(nodei) |par(par(nodei))) ...p(object) (2) 当然节点的条件概率并不能很好地对检测的对象进行预测分类,例如:同属于动物类别的狗和猫假定它们求得的softmax() 值分别为0.3和0.6,同属于狗这个类别的金毛和哈士奇求得的softmax() 值分别为0.7和0.1,同属于与狗并列的猫这个类别的波斯猫和波斯猫求得的softmax() 值分别为0.2和0.5,显然所有叶子节点条件概率的最大值为金毛的0.7,但是无法说检测的对象预测为金毛,因为金毛的父类狗比和它并列的猫的条件概率值小得多,也就是说检测到的对象首先更有可能是猫而非狗,最终结果更大可能是从属于猫的某一类别。
通过例子可以看出,想要得到的是某一特定节点的绝对概率,也就是与这个节点相关的所有并列节点以及所有祖先都对该节点的概率起到影响,所以需要计算特定节点的绝对概率:沿着WordTree上根节点到达特定节点的路径,将所有经过的节点的条件概率相乘。例如想要知道一张图片是否为金毛,应该计算:Pr (金毛)=Pr(金毛|狗)*Pr(狗|动物)*Pr(动物|object)。通过WordTree求绝对概率的一个好处是:在新的或未知的目标类别上YOLO9000模型的性能没有下降太多。例如,如果检测一张狗的图片,但不确定它是什么类型的狗,YOLO9000仍然会高度自信地预测“狗”,只是扩展到狗的子节点可能会有更低的置信度[4]。
理论上讲,预测对象时,应该对所有节点求绝对概率,最终比较大小。而在实际预测过程中,并不计算出所有节点的绝对概率,而是采用一种比较简便的算法:从根节点开始向下遍历,对每一个节点,在它的所有子节点中,选择概率最大的那个继续向下遍历和计算概率值,其他非最大值的对象被舍弃,无须再计算它们的子节点的概率,到达每一层级都采取相同做法,一直遍历到某个节点的子节点概率低于设定的阈值,也就是该节点的概率值过小导致较难再取到,分类器无法明显分辨类别,或达到叶子节点时,取该节点在WordTree 中对应的对象为输出的预测结果。就好比想要分辨一张图片为哈士奇还是波斯猫,首先要分辨这是狗还是猫,因为大多数狗和猫都有各自相同的特征,如果这张图片首先被判定大概率是狗,那它是波斯猫的概率就很小,便可以忽略对猫的概率计算。
6 结论与展望
Word Tree是YOLO9000中为了解决Image Net和COCO数据集合并所遇到的标注不互斥的问题而构建的词集之间的树形结构。根据WordNet中的层级关系,WordTree以层级分类的方式将ImageNet和COCO 数据集组合在一起,将数据集中的类别映射到树中的同义词集上,实现了在两个数据集上分类和检测的联合训练。借助WordTree进行联合训练后,YOLO9000 利用COCO数据集中的数据检测图像中目标的位置和大小,利用ImageNet数据集中的数据对检测的目标进行分类[13]。
WordTree为图像识别提供了更丰富、更详细的输出空间,使用分层分类的数据集组合在分类、检测和分割领域大有益处。此方法能根据知识图谱WordNet 中的从属关系结合不同来源的图像数据及标注词汇,从而大大扩大了模型训练数据的规模,并实现对更多对象的预测。
Word Tree的构建为扩充检测类别提供了新的思路,树形结构对复杂问题的简化梳理提供了很好的工具。未来图像视觉检测任务可以运用WordTree整合更多不同来源的独立数据集,建立更庞大的数据集,为深度学习目标检测系统提供强有力的支持,能够检测更多对象,在一些无監督的检测目标学习场合有可能做得更好。
猜你喜欢
江苏教育·中学教学版(2016年11期)2016-12-21
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
科学与财富(2016年28期)2016-10-14
现代电子技术(2015年14期)2015-07-22
